Sklearn 实现 KNN 分类算法,鸢尾花数据集手把手教程
前言
在机器学习众多经典算法中,K 近邻算法(KNN,K-Nearest Neighbors) 是最简单、最容易理解且实用性极强的惰性监督学习算法。它无需复杂的模型训练过程,核心逻辑源于生活常识:物以类聚,人以群分。
无论是分类任务还是回归任务,KNN 都能快速上手实现,常作为机器学习初学者入门的第一个实战算法。
一、KNN算法简单介绍
KNN(K-Nearest Neighbors,K 最近邻)是一种基础且常用的机器学习算法,可用于分类和回归任务,实际应用中更多用于分类。它的核心思路很直观:对一个待预测样本,先在训练集中找出距离它最近的 K 个样本,再依据这 K 个 “邻居” 的信息给出结果。分类时采用多数投票原则,选择邻居中数量最多的类别作为预测结果;回归时则对邻居的数值取平均值,得到最终预测值。
二、KNN 核心工作流程
首先要完成数据集与超参数的基础准备工作,搭建起 KNN 算法运行的前置条件。
我们需要提前整理好带有明确标签的训练数据,每一条样本都由多维特征和对应的分类类别、回归数值标签组成,为后续距离计算和近邻筛选提供数据支撑。
同时人为设定好超参数 K 值,敲定最终参与决策的最近邻样本数量,K 值的选取也会直接影响模型预测结果。
其次进入算法核心运算与结果判定环节,依次完成距离计算、样本筛选和结果预测。选定合适的距离度量公式后,逐一求解待测样本和全体训练样本在特征空间里的距离,再对所有距离进行升序排序,截取距离最小的前 K 个样本构成近邻集。
针对不同任务场景采用不同决策逻辑,分类场景依靠多数投票机制选出占比最高的类别作为预测标签,回归场景则对 K 个近邻的数值标签求取平均,以此得到最终的连续型预测结果。
三、 KNN 算法特点
- KNN算法原理易于理解、代码实现简单;
- 属于惰性学习,没有显式训练过程,只需保存全部训练集,等测试样本到来再做计算预测;
- 同时它是无参数算法,仅需确定K值即可;
但缺点也很明显,需要存储所有训练数据,样本量大时占用存储空间与计算资源高,且算法对距离度量方式和K值选取都十分敏感,会直接影响最终预测效果与准确率。
四、KNN算法的应用场景
KNN算法更适配样本规模偏小、类别数量有限的分类场景,也可应用在样本量偏大的回归任务中,只是回归方向的实际落地场景相对稀少。同时该算法通用性较强,在文本分类、图像识别、个性化推荐系统等多个领域都有着广泛的应用价值。
但KNN也存在明显短板,算法运行时需要逐一计算待测样本与全部训练样本的距离,不仅计算开销大,还需要占用大量内存来存储完整的训练数据集。正因如此,面对海量级的大规模数据时,KNN很容易出现运行速度变慢、资源占用过高的性能瓶颈,不太适合超大数据集的建模任务。
总结来说就是KNN算法适用于样本量较小且类别较少的分类问题。
四、KNN算法代码实例详解
本次案例选用经典的鸢尾花分类任务,通过完整的训练与预测流程帮助大家快速掌握 KNN 的实际用法。案例中使用 1000 组标注好的训练数据进行模型学习,搭配 9 组测试数据验证分类效果,流程清晰、易于理解,非常适合作为 KNN 算法的入门实战。
完整代码如下:
import pandas as pd
train_data = pd.read_excel('鸢尾花训练数据.xlsx')
test_data = pd.read_excel('鸢尾花测试数据.xlsx')
train_X = train_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
train_y = train_data[['类型_num']]
from sklearn.preprocessing import scale
data = pd.DataFrame()
data['萼片长(cm)'] = scale(train_X['萼片长(cm)'])
data['萼片宽(cm)'] = scale(train_X['萼片宽(cm)'])
data['花瓣长(cm)'] = scale(train_X['花瓣长(cm)'])
data['花瓣宽(cm)'] = scale(train_X['花瓣宽(cm)'])
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(data, train_y)
test_X = test_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
test_y = test_data[['类型_num']]
from sklearn.preprocessing import scale
data_test = pd.DataFrame()
data_test['萼片长(cm)'] = scale(test_X['萼片长(cm)'])
data_test['萼片宽(cm)'] = scale(test_X['萼片宽(cm)'])
data_test['花瓣长(cm)'] = scale(test_X['花瓣长(cm)'])
data_test['花瓣宽(cm)'] = scale(test_X['花瓣宽(cm)'])
test_predicted = knn.predict(data_test)
score = knn.score(test_X, test_y)
print(score)
完整解析
代码执行前,下载需要的工具包。
Scikit‑learn(简称SKlearn)是基于NumPy、SciPy、Pandas和Matplotlib构建的机器学习库,它拥有设计简洁、统一的API接口,各类模型和工具的使用方式都十分规范易懂,非常适合机器学习新手快速上手实践。
在命令提示符中输入:
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple/
导入 pandas 数据分析库,该库主要用于读取 Excel 表格、处理结构化表格数据,是机器学习数据预处理常用工具。
import pandas as pd
调用 pandas 读取本地两个 Excel 文件,分别加载鸢尾花的训练数据集和测试数据集,读取后的数据以 DataFrame 表格格式存储在对应变量中.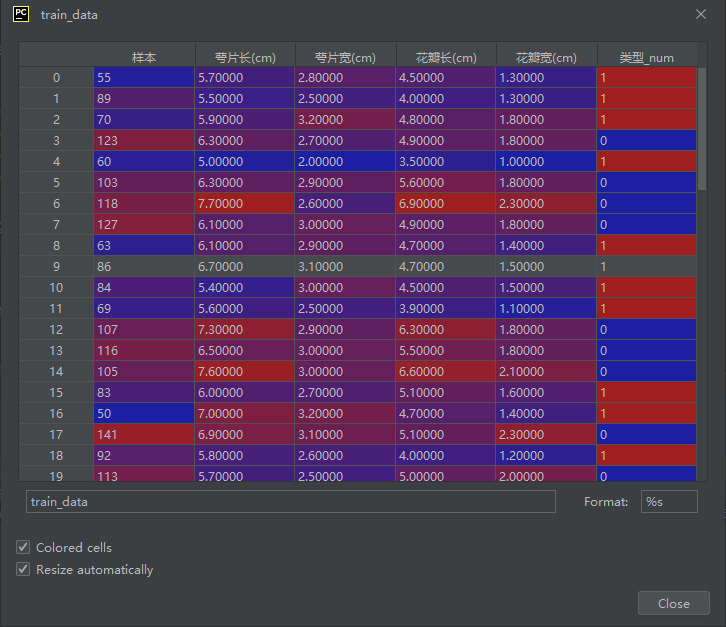

train_data = pd.read_excel('鸢尾花训练数据.xlsx')
test_data = pd.read_excel('鸢尾花测试数据.xlsx')
从训练数据集中拆分出特征变量和标签变量。选取萼片长、萼片宽、花瓣长、花瓣宽四个维度作为模型输入特征;选取类型_num 列作为鸢尾花分类的标签,也就是模型要预测的目标。
train_X = train_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
train_y = train_data[['类型_num']]
从 sklearn 机器学习库中导入 scale 标准化工具,作用是对特征数据做标准化处理,消除量纲影响,让数值尺度统一,适配 KNN 这类依赖距离计算的算法。
from sklearn.preprocessing import scale
新建一个空的DataFrame用于存储处理后的数据,随后对训练集中的萼片长、萼片宽、花瓣长、花瓣宽这四个特征列逐一进行标准化转换,并将每列标准化后的结果依次存入新DataFrame,最终构建出完成标准化处理的训练特征集合。
data = pd.DataFrame()
data['萼片长(cm)'] = scale(train_X['萼片长(cm)'])
data['萼片宽(cm)'] = scale(train_X['萼片宽(cm)'])
data['花瓣长(cm)'] = scale(train_X['花瓣长(cm)'])
data['花瓣宽(cm)'] = scale(train_X['花瓣宽(cm)'])
从 sklearn 库中导入 K 近邻分类器,创建并初始化 KNN 分类模型,将核心参数近邻数 K 设置为 5,表示在预测未知样本类别时,选取距离最近的 5 个邻居进行投票决策。
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5)
使用经过标准化处理后的训练特征与对应的鸢尾花分类标签,调用模型的拟合方法完成 KNN 模型训练,使模型自动学习特征维度与鸢尾花类别之间的对应映射关系。
至此,利用预处理完成的训练特征与标签完成模型拟合,KNN模型的训练过程就已顺利结束。
knn.fit(data, train_y)
接下来从测试数据集中拆分出测试特征与真实分类标签,整体格式与训练集保持统一,为后续验证模型分类效果、评估模型性能做好准备。
test_X = test_data[['萼片长(cm)', '萼片宽(cm)', '花瓣长(cm)', '花瓣宽(cm)']]
test_y = test_data[['类型_num']]
实际上从这一步我们就开始做重复工作
再次导入标准化工具,新建新的空DataFrame,对测试集的四个特征列分别执行标准化变换,最终生成与训练集格式一致的标准化测试特征集。
from sklearn.preprocessing import scale
data_test = pd.DataFrame()
data_test['萼片长(cm)'] = scale(test_X['萼片长(cm)'])
data_test['萼片宽(cm)'] = scale(test_X['萼片宽(cm)'])
data_test['花瓣长(cm)'] = scale(test_X['花瓣长(cm)'])
data_test['花瓣宽(cm)'] = scale(test_X['花瓣宽(cm)'])
调用训练好的 KNN 模型,用标准化测试特征做类别预测,得到预测结果;调用模型评分方法,用原始未标准化的测试特征和真实标签计算模型准确率,最后打印输出准确率数值。
test_predicted = knn.predict(data_test)
score = knn.score(test_X, test_y)
print(score)
程序运行后会输出一个 0~1 之间的数值,代表模型在测试集上的分类正确率,数值越接近 1,说明模型识别鸢尾花的准确率越高。
总结
KNN 凭借简洁的近邻投票思想,实现门槛低、易上手,是机器学习基础算法的核心代表。虽在海量高维数据下存在性能短板,但在中小数据集、快速原型验证、简单分类场景中仍有着极高的实用价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)