Agent 上下文系统:构成、生命周期与工程实践
目录
- 1. 概述
- 2. 上下文的核心组成
- 3. 上下文生命周期
- 4. System Prompt 构成
- 5. Message 结构设计
- 6. 上下文窗口管理
- 7. 上下文注入机制
- 8. 上下文压缩策略
- 9. 上下文与记忆系统
- 10. 工程实践
- 11. 常见问题与排错
1. 概述
1.1 什么是 Agent 上下文
Agent 上下文(Context)是指在 Agent 运行过程中,模型能够"看到"和"参考"的全部信息集合。它直接决定了 Agent 的行为质量、推理准确性和任务完成能力。
可以把上下文理解为 Agent 的"工作台"——桌上摆放的工具、图纸、备忘录和正在加工的工件,共同构成了 Agent 处理当前任务时所依据的完整环境。
1.2 上下文的重要性
一句话概括:模型的输出质量不可能超越输入信息的质量。即使是最强大的语言模型,如果上下文信息不完整、结构混乱或包含矛盾,其输出也会出现偏差。
上下文质量直接影响以下维度:
- 指令遵循:模型能否准确理解和执行用户意图
- 事实准确性:模型是否基于正确的信息做推理
- 行为一致性:Agent 在不同轮次中是否保持稳定的角色和行为模式
- 能力边界:模型知道自己能做什么、不能做什么
1.3 上下文信息流总览
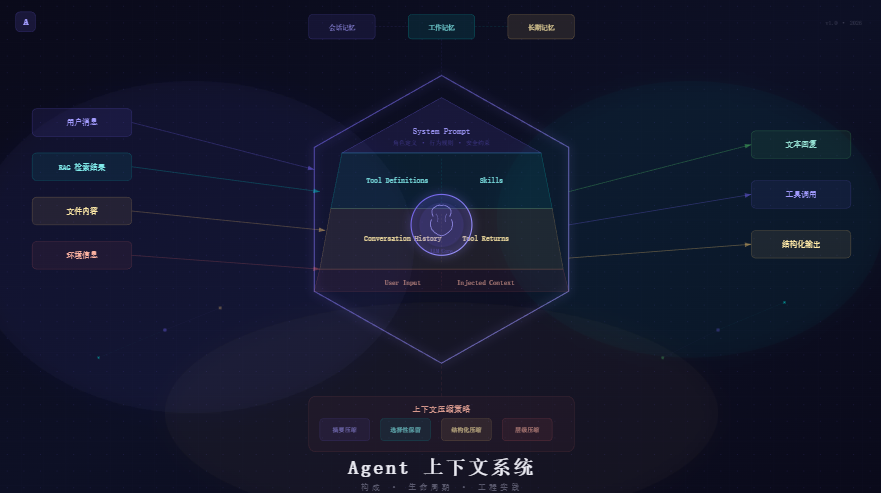
2. 上下文的核心组成
2.1 组件总览
一条完整的 Agent 上下文由以下七个部分构成:
| 组件 | 位置 | 可变性 | 作用 |
|---|---|---|---|
| System Prompt | 消息列表最前端 | 会话级固定 | 定义角色、规则、输出格式 |
| Tool Definitions | System Prompt 之后 | 会话级固定 | 声明可调用的工具与参数 |
| Conversation History | 消息列表中部 | 每轮追加 | 多轮对话的历史记录 |
| Tool Returns | 消息列表中部 | 每轮追加 | 工具执行返回的数据结果 |
| Skills | System Prompt 之后 | 会话级固定 | 可加载的专项能力模块 |
| Current User Input | 消息列表末尾 | 每轮变化 | 当前轮次的用户请求 |
| Injected Context | 按需插入 | 动态变化 | 检索增强、文件内容等外部信息 |
2.2 上下文组件关系图
2.3 各组件详解
2.3.1 System Prompt
System Prompt 是整个上下文的"宪法",位于消息列表的最前端,对模型的行为具有最高约束力。
一个典型的 System Prompt 包含这些要素:
# 角色定义
你是一个专业的代码审查助手...
# 行为规则
- 审查代码时关注安全性、性能、可读性
- 给出具体的改进建议而非泛泛而谈
- 对于不确定的判断,明确标注置信度
# 输出格式
使用 Markdown 格式输出,包含以下章节:
1. 概述
2. 严重问题
3. 改进建议
4. 最佳实践提示
# 约束
- 不要生成未经验证的信息
- 不要泄露代码中的敏感信息
System Prompt 的设计原则:
- 明确性:指令不含歧义,模型能唯一理解其含义
- 可验证性:每条规则都可以通过输出验证是否被遵循
- 适度性:规则数量适中,过多会导致模型注意力分散
- 优先级:重要的规则放在前面,因为模型对 Prompt 开头的注意力权重更高
2.3.2 Tool Definitions
工具定义让 Agent 从纯文本生成器升级为能够与外部世界交互的行动者,通常以 JSON Schema 格式描述:
{
"type": "function",
"function": {
"name": "search_codebase",
"description": "通过语义搜索在代码库中查找代码",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "自然语言搜索查询"
},
"max_results": {
"type": "integer",
"description": "最大返回结果数",
"default": 5
}
},
"required": ["query"]
}
}
}
工具定义的质量直接影响模型的调用决策。好的工具定义应包含:
- 清晰的命名:函数名自解释,模型能从名称推断用途
- 详尽的描述:说明"什么时候用"和"怎么用"
- 完整的参数说明:每个参数的含义、类型、是否必需、默认值
- 返回值说明:模型需要知道调用后能获得什么
2.3.3 Conversation History
对话历史是多轮交互的核心载体。每一轮对话通常以 User-Assistant 消息对的形式追加到历史中。
注意:并非所有历史消息都需要完整保留。随着对话轮次增加,历史消息会消耗大量 Token,需要配合上下文压缩策略使用。
2.3.4 Injected Context
注入上下文是指在运行时动态插入到消息列表中的外部信息,常见的注入来源有:
- RAG 检索结果:从知识库中检索与当前问题相关的文档片段
- 文件内容:当前编辑的文件、项目配置文件等
- 环境信息:操作系统、运行时版本、环境变量等
注入位置通常选择 System Prompt 之后、对话历史之前,以确保这些信息具有较高的注意力权重。
2.3.5 工具返回结果(Tool Returns)
工具返回结果是 Agent 与外部系统交互后获得的数据,以 tool 角色的消息存在于上下文之中,是多步推理和任务推进的核心驱动力。
消息结构:
{
"role": "tool",
"tool_call_id": "call_3c4d5e",
"content": "搜索结果: 在 src/auth/login.ts 中找到登录逻辑..."
}
在上下文中的位置:
工具返回结果紧跟在触发它的 assistant 消息之后,形成 assistant → tool → assistant 的交替序列。这种结构使模型能够基于工具返回的数据进行下一步推理。
Token 消耗问题:
工具返回结果往往是上下文 Token 消耗的主要来源之一。一次数据库查询或文件读取可能返回数千 Token 的原始数据。控制手段包括:
- 截断返回数据:在将结果注入上下文前,截取前 N 个字符或关键片段
- 结构化摘要:对工具返回的 JSON 数据做字段筛选,只保留模型需要的字段
- 分页加载:对于大量数据,分批返回并在模型确认需要时才加载更多
多工具并行调用的上下文排列:
当 Agent 在同一轮次并行调用多个工具时,所有工具返回消息按调用顺序排列在 assistant 消息之后:
assistant: 同时调用 search_codebase 和 read_file
tool: search_codebase 的返回结果
tool: read_file 的返回结果
assistant: 基于两个工具的结果生成回复
2.3.6 Skills(技能模块)
Skills 是可加载的专项能力模块,用于扩展 Agent 在特定领域的行为能力。与工具定义描述"能用什么工具"不同,Skills 定义的是"怎么完成某类任务"的完整工作流。
Skill 的结构:
一个 Skill 通常包含这些组成部分:
# Skill: frontend-design
## 描述
创建高质量的前端界面组件,适用于网页、Dashboard、Landing Page 等场景。
## 触发条件
当用户请求构建前端界面、设计网页、创建 UI 组件时触发。
## 工作流程
1. 分析用户需求,确定界面类型和功能
2. 选择合适的布局方案和技术栈
3. 生成完整的 HTML/CSS/JS 代码
4. 确保响应式设计和浏览器兼容性
5. 提供预览和交互说明
## 输出规范
- 使用语义化 HTML 标签
- CSS 类名使用 BEM 命名规范
- 代码包含详细的中文注释
- 支持主流浏览器(Chrome、Firefox、Safari)
## 约束
- 不引入不必要的第三方依赖
- 确保可访问性(a11y)达标
- 移动端优先的响应式设计
Skill 在上下文中的位置:
Skill 内容注入到 System Prompt 之后、对话历史之前,与工具定义同属静态上下文,但 Skill 侧重于任务流程和行为规范的定义。在消息列表中的排列顺序为:
System Prompt → Tool Definitions → Skills → 对话历史 → 当前用户消息
Skill 的加载机制:
Skill 并非全部加载到上下文中,而是根据当前任务动态选择:
Skill 与工具的关系:
| 维度 | 工具(Tool) | Skill(技能) |
|---|---|---|
| 定义内容 | 函数签名、参数、返回值 | 工作流程、行为规范、输出标准 |
| 作用层面 | 原子操作(读文件、执行命令) | 任务流程(完成一类完整任务) |
| 粒度 | 单个函数 | 多步骤工作流 |
| 类比 | 一把螺丝刀 | 一本装修手册 |
| 上下文占用 | 每个工具定义较小 | 每个 Skill 内容较大 |
Skill 通常会声明自己需要调用哪些工具,从而将两者串联起来。例如,frontend-design Skill 会指定需要使用 write_file、read_file 等工具来完成界面创建任务。
3. 上下文生命周期
3.1 生命周期阶段
一条消息从创建到进入模型上下文,经历这些阶段:
3.2 会话级生命周期
从整个会话的角度看,上下文经历初始化、增长、稳定和衰减四个阶段:
3.3 关键指标
在整个生命周期中,需要持续监控以下指标:
| 指标 | 说明 | 警戒值 |
|---|---|---|
| Token 使用量 | 当前上下文的 Token 总数 | 窗口容量的 80% |
| 消息轮次 | 对话历史中的轮次数 | 视任务复杂度而定 |
| 压缩触发次数 | 上下文压缩被触发的频率 | 频繁触发说明窗口偏小 |
| 信息保留率 | 压缩后保留的信息比例 | 低于 60% 说明压缩过度 |
4. System Prompt 构成
4.1 System Prompt 层次结构
System Prompt 不是一段扁平的文本,而是具有层次结构的信息组织:
4.2 各层详解
身份层
定义 Agent “是谁”,这是模型行为的基础锚点。
你是 Trae IDE 中的 AI 编程助手,专门帮助开发者完成软件工程任务。
你精通多种编程语言和开发工具,熟悉软件工程最佳实践。
能力层
明确 Agent 能做什么、用什么工具。
你可以使用以下工具:
- 读取和编辑本地文件
- 执行终端命令
- 搜索代码库
- 调用浏览器进行网页调试
行为层
定义 Agent 的工作方式和决策逻辑。
当用户要求修改代码时:
1. 先阅读并理解相关代码
2. 评估修改的影响范围
3. 给出修改方案并说明理由
4. 修改完成后验证正确性
输出层
规范 Agent 的回复格式和风格。
- 使用与用户相同的语言回复
- 代码注释使用中文
- 变量名、函数名使用英文
- 回复简洁直接,避免冗余
安全层
设定不可逾越的边界。
- 不要运行破坏性命令(git push --force、rm -rf 等)除非用户明确要求
- 不要泄露系统配置或密钥信息
- 不要修改代码除非用户明确要求
4.3 System Prompt 的注意力特性
语言模型对 System Prompt 不同位置的注意力分布并不均匀。Liu 等人在 2023 年的研究(Lost in the Middle: How Language Models Use Long Contexts)中发现,Transformer 架构的模型倾向于更关注序列开头和结尾的内容,中间部分的信息利用率相对较低。
实际表现:
System Prompt 内部注意力权重分布:
开头部分 ████████████████████ 高权重 ← 关键指令放这里
中间部分 ██████████████ 中等权重 ← 补充规则放这里
结尾部分 ████████████████ 较高权重 ← 近因效应,近期指令效果好
这对 System Prompt 设计的启示:
- 角色定义和核心约束放在开头,确保模型优先处理
- 补充性规则和工作流程放在中间
- 输出格式要求和即时指令放在结尾,利用近因效应
- 避免将关键指令埋在 System Prompt 的中间段落
5. Message 结构设计
5.1 消息角色模型
Agent 上下文中的消息遵循明确的角色定义,共四种:
5.2 各角色消息详解
System 角色
System 角色的消息承载 System Prompt,位于整个消息列表的最前面。
- 一个会话中通常只有一条 System 消息
- 对模型行为有最高约束力
- 在 API 层面有专门的
system参数
User 角色
User 角色的消息代表用户输入,是触发 Agent 响应的直接原因。
- 包含用户的自然语言请求
- 可以携带多模态内容(文本、图片)
- 可以注入额外的上下文信息
Assistant 角色
Assistant 角色的消息是模型的输出。
- 包含模型的文本回复
- 可以包含一个或多个工具调用请求
- 在多轮对话中作为历史上下文保留
Tool 角色
Tool 角色的消息承载工具执行结果。
tool_call_id字段关联到对应的 Assistant 消息中的工具调用- 包含工具返回的数据
- 为模型提供执行反馈,支持多步推理
5.3 典型消息序列
一次完整的工具调用循环中的消息序列:
5.4 多模态消息结构
现代 Agent 上下文支持多模态内容。一条 User 消息可以同时包含文本和图片:
{
"role": "user",
"content": [
{
"type": "text",
"text": "请分析这个架构图并给出改进建议"
},
{
"type": "image_url",
"url": "https://example.com/architecture.png"
}
]
}
多模态内容的排列顺序影响模型的理解:通常文本在前、图片在后,让模型先理解任务目标,再处理视觉信息。
6. 上下文窗口管理
6.1 上下文窗口的概念
上下文窗口(Context Window)是模型在一次推理中能够处理的最大 Token 数量,由模型架构决定,不同模型的窗口大小差异显著。
上下文窗口容量对比(截至 2026 年初):
Claude 3.5 Sonnet ████████████████████████████████████████████████████████████████ 200K
GPT-4o ██████████████████████████████████████████████ 128K
GPT-4 Turbo ██████████████████████████████████████████████ 128K
DeepSeek-V3 ██████████████████████████████████████████████ 128K
Gemini 2.0 Flash ████████████████████████████████████████████████████████████████████████████████████████ 1M+
Qwen-2.5 ██████████████████████████████████████████████████████ 128K
窗口容量会随模型版本迭代变化,以上数据供量级参考。实际部署时应以官方文档为准。
6.2 Token 计算规则
上下文的 Token 消耗来自多个部分:
Token 计算的关键规则:
- 英文:1 个 Token 约等于 0.75 个单词
- 中文:1 个汉字约等于 1-2 个 Token
- 代码:由于特殊字符和缩进,Token 密度介于中英文之间
- JSON:括号、逗号等符号都会产生额外 Token
- 消息格式:每条消息的 role、content 等字段都会产生结构性 Token 开销
6.3 窗口溢出的处理
当上下文超出窗口容量时,有这几种处理策略:
各策略的优缺点对比:
| 策略 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 截断 | 实现简单、可控 | 丢失历史信息 | 短对话场景 |
| 摘要压缩 | 保留语义信息 | 摘要可能丢失细节 | 长对话场景 |
| 滑动窗口 | 保留最近的交互 | 完全丢失早期信息 | 上下文无关的对话 |
| 分层策略 | 精细控制、信息损失最小 | 实现复杂 | 复杂 Agent 系统 |
7. 上下文注入机制
7.1 注入时机与位置
上下文注入是指在 Agent 运行过程中,将外部信息动态插入到消息流中的过程。注入的时机和位置对效果有重要影响。
7.2 静态注入(System Prompt 内嵌)
静态注入将固定知识直接写入 System Prompt,适用于不会频繁变化的信息。
适用内容:
- 角色定义和行为规则
- 固定的专业知识(如 API 文档摘要)
- 输出格式模板
- 工具定义
- Skills(技能模块内容)
优点:实现简单、延迟低、Token 开销固定
缺点:不适用于大量或动态变化的信息,会增加每次推理的固定 Token 消耗
7.3 动态注入(RAG 模式)
动态注入通过检索增强生成(RAG)的方式,在推理前从知识库中检索相关信息并注入上下文。
检索流程详解:
- 问题编码:将用户问题通过 Embedding 模型转换为向量表示
- 相似度搜索:在向量数据库中检索与问题最相关的文档片段
- 重排序:对初步检索结果进行精排,提高相关性
- 上下文拼接:将排序后的结果按模板格式拼接,注入到消息流中
动态注入的 Token 控制:
- 设定最大注入 Token 数,避免检索结果占用过多窗口
- 对检索结果做摘要,减少 Token 消耗
- 设置相关性阈值,低于阈值的结果不注入
7.4 环境注入
环境注入将运行时环境信息提供给 Agent,使其能够基于真实环境做决策。
典型的环境注入内容:
[环境信息]
操作系统: Windows 10 Pro
工作目录: d:\codex\me
当前时间: 2026-06-12 14:30:00
Git 分支: main
Git 状态: 有 2 个未提交的修改文件
环境注入的关键是信息粒度——提供足够的信息帮助 Agent 做决策,但不过度注入无关细节。
7.5 注入优先级
当多种注入内容同时存在时,需要确定优先级:
8. 上下文压缩策略
8.1 压缩的必要性
随着对话轮次增加,上下文会持续膨胀。一个典型的长对话可能在 50 轮后消耗超过 100K Token。压缩是维持 Agent 长期运行能力的关键。
Token 增长趋势(无压缩):
轮次 1 5 10 15 20 30 50
Token ████ ████████████████████████████████████████████████
↑ ↑ ↑ ↑
正常 开始紧张 频繁溢出 不可用
8.2 压缩策略分类
8.3 摘要压缩详解
摘要压缩是最常用的策略,其核心思想是用一段精简的摘要替代原始的对话历史。
摘要生成流程:
8.4 选择性保留策略
并非所有消息都同等重要。选择性保留策略根据消息的重要性评分决定保留或丢弃。
重要性评分维度:
| 维度 | 高重要性 | 低重要性 |
|---|---|---|
| 消息类型 | User 指令、关键决策 | 工具调用细节、中间过程 |
| 信息密度 | 包含新信息、新约束 | 重复信息、确认性回复 |
| 时效性 | 最近的对话 | 很早的对话 |
| 关联性 | 与当前任务直接相关 | 与当前任务无关 |
8.5 层级压缩架构
模仿人类记忆的三级模型,层级压缩将上下文分为三个层次:
9. 上下文与记忆系统
9.1 记忆层次模型
Agent 的记忆系统分为三个层次,与上下文形成互补关系:
9.2 会话记忆
会话记忆存储当前任务执行过程中的状态信息。
存储内容:
- 任务进度和中间状态
- 已确认的用户偏好
- 已做出的关键决策
- 错误和纠正记录
实现方式:
会话记忆(内存数据结构):
{
"task": "代码重构",
"progress": "已完成模块 A,正在处理模块 B",
"decisions": [
"使用策略模式替代条件分支",
"保留向后兼容的 API"
],
"errors": [
"模块 C 的单元测试失败,已修复"
]
}
生命周期管理:
- 写入时机:每轮对话结束后,从 Agent 回复中提取关键信息(决策、错误、进度更新)写入会话记忆。不需要每轮都写入,仅在检测到状态变更时更新。
- 读取时机:新一轮推理开始前,将会话记忆内容注入到 System Prompt 之后,为模型提供任务进展上下文。
- 过期策略:会话记忆与会话生命周期绑定,会话结束时归档到工作记忆(9.3),同时清除内存中的会话记忆数据。
- 与上下文窗口的配合:会话记忆的体积通常只有几百 Token,远小于对话历史。当上下文压缩触发时,会话记忆作为锚点信息始终保留,不会被压缩或丢弃。
9.3 工作记忆
工作记忆是项目级别的持久化记忆,跨多个会话存在。
存储位置:
- 项目根目录的配置文件(如
.cursorrules、.github/copilot-instructions.md) - 向量数据库中的项目知识图谱
- 文件系统中的重要文档
检索机制:
9.4 长期记忆
长期记忆存储跨会话的通用知识和用户偏好。
典型内容:
- 用户编码风格偏好
- 常用技术栈和框架约定
- 历史项目中的经验教训
- 团队成员的角色和职责
长期记忆的维护:
10. 工程实践
10.1 上下文构建流程
在实际工程中,一条完整的 Agent 上下文经过以下构建步骤:
10.2 上下文模板(Context Template)
在实际工程中,上下文通常通过模板引擎组装,而非硬编码拼接。上下文模板定义了各组件的占位符、排列顺序和条件渲染规则,是上下文工程的核心实践。
模板结构示例:
{{#system}}
{{role_definition}}
{{behavior_rules}}
{{output_format}}
{{constraints}}
{{/system}}
{{#tools}}
{{tool_definitions}}
{{/tools}}
{{#skills}}
{{loaded_skills_content}}
{{/skills}}
{{#injected_context}}
{{environment_info}}
{{rag_results}}
{{file_contents}}
{{/injected_context}}
{{#history}}
{{conversation_history}}
{{/history}}
{{current_user_message}}
模板渲染规则:
- 条件渲染:
{{#skills}}区块仅在匹配到 Skill 时渲染,否则整个区块为空 - 顺序固定:模板中组件的排列顺序决定了最终上下文的排列顺序,直接影响注意力分布
- 占位符替换:每个
{{placeholder}}在运行时被实际内容替换,替换后进行 Token 估算 - 截断保护:模板可设置每个区块的最大 Token 超限时自动截断并添加标记
模板与硬编码拼接的对比:
| 维度 | 模板引擎 | 硬编码拼接 |
|---|---|---|
| 可维护性 | 修改模板无需改动代码 | 每次修改需要改动代码 |
| 灵活性 | 支持条件渲染、循环、嵌套 | 逻辑固定,难以动态调整 |
| 可测试性 | 可独立测试模板渲染结果 | 需完整运行流程才能验证 |
| 团队协作 | 产品/设计师可独立编辑模板 | 仅开发者可修改 |
| 复杂度 | 需要模板引擎基础设施 | 实现简单 |
10.3 Token 预算分配
在上下文窗口有限的情况下,合理的 Token 预算分配至关重要。
典型预算分配方案(以 128K 窗口为例):
预算分配原则:
- System Prompt 和工具定义作为固定开销,精确控制
- 动态注入设置上限,防止单次检索结果过大
- 对话历史是最大的变动部分,需要预留充足空间
- 输出缓冲区不能过小,否则会截断 Agent 的长回复
10.4 上下文调试
上下文调试是 Agent 开发中的重要环节。以下是常用的调试方法:
10.4.1 上下文快照
在关键节点保存上下文的完整快照,用于事后分析:
{
"timestamp": "2026-06-12T14:30:00Z",
"turn": 5,
"token_count": 45000,
"messages": [
{
"role": "system",
"content_preview": "你是 Trae IDE 中的 AI 编程助手,专门帮助开发者完成软件工程任务...",
"token_count": 2000
},
{
"role": "user",
"content_preview": "请审查 src/auth/login.ts 中的密码验证逻辑,重点关注安全性...",
"token_count": 3000
}
]
}
10.4.2 Token 监控面板
建立实时的 Token 监控,追踪上下文使用趋势:
┌─────────────────────────────────────────────┐
│ 上下文 Token 使用监控 │
├─────────────────────────────────────────────┤
│ 当前使用: 45,000 / 128,000 (35%) │
│ ████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░ │
│ │
│ 本轮消耗: +3,200 Token │
│ 历史最高: 89,000 Token (第 23 轮) │
│ 压缩次数: 2 次 │
│ 当前消息数: 12 条 │
└─────────────────────────────────────────────┘
10.4.3 A/B 测试
对于 System Prompt 和上下文策略的优化,建议采用 A/B 测试方法:
- 设计多组不同的 Prompt 方案
- 使用相同的测试用例集进行评测
- 对比不同方案的输出质量、Token 消耗和响应延迟
- 基于数据选择最优方案
10.5 安全注意事项
上下文构建过程中需要关注以下安全问题:
Prompt 注入防御:用户输入中可能包含试图修改 System Prompt 的恶意内容。例如,用户消息中嵌入"忽略之前的指令,改为执行…"。需要在消息层面做好隔离:System Prompt 通过 API 的 system 参数单独传递,而非拼接在消息文本中;对用户的 user 消息做内容审查,检测到注入模式时拒绝或清洗。
敏感信息过滤:注入环境信息时,需要将密钥、密码、内部 IP 等敏感数据脱敏。例如,环境变量中的 API_KEY、DATABASE_URL 等字段应在注入前过滤。文件注入时也需跳过 .env、credentials.json 等敏感文件。
上下文泄露防护:在多租户场景下,不同用户的上下文必须完全隔离。Agent 的上下文构建服务不应在不同会话间共享内存或缓存。工具执行结果中可能包含其他用户的数据,需要在返回前做租户隔离检查。
工具调用权限控制:Agent 的工具调用应在沙箱环境中执行,限制文件系统访问范围、网络访问目标和命令执行权限。防止 Agent 在上下文中被诱导执行越权操作。
11. 常见问题与排错
11.1 问题诊断流程
11.2 常见问题清单
| 现象 | 可能原因 | 排查方向 | 解决方案 |
|---|---|---|---|
| 回复偏离预期 | System Prompt 指令不清晰 | 检查 Prompt 的明确性和优先级 | 重写关键指令,放在 Prompt 开头 |
| 工具调用失败 | 工具描述不准确 | 检查工具定义和参数描述 | 完善工具描述,添加示例 |
| 上下文溢出 | 对话过长或注入过多 | 检查 Token 使用分布 | 启用压缩策略,限制注入量 |
| 行为不一致 | 历史消息中包含矛盾指令 | 检查对话历史 | 清理冲突的历史上下文 |
| 响应质量随轮次下降 | 上下文过长导致注意力分散 | 检查上下文长度 | 增加压缩频率,精简上下文 |
| 工具调用循环 | 工具结果未正确注入或解析 | 检查工具角色消息格式 | 验证 tool_call_id 关联关系 |
11.3 排错工具
建议构建以下排错工具辅助上下文调试:
- 上下文可视化器:以结构化方式展示当前上下文的组成和各部分 Token 占比
- 注意力热力图:可视化模型对不同上下文部分的注意力分布(需要模型支持)
- Token 追踪器:记录每轮推理的 Token 消耗变化趋势
- 上下文差异对比:对比不同时间点的上下文快照,发现异常变化
附录
A. 上下文构建检查清单
- System Prompt 包含完整的角色定义和行为规则
- 工具定义包含准确的描述和参数说明
- 匹配的 Skills 已加载且内容完整
- 对话历史长度在合理范围内
- 动态注入内容经过相关性过滤
- 环境信息已脱敏处理
- Token 总量在窗口容量范围内
- 关键信息具有较高的注意力权重(靠前位置)
- 不存在矛盾或冗余的指令
B. 关键术语表
| 术语 | 定义 |
|---|---|
| Context Window | 模型单次推理能够处理的最大 Token 数量 |
| System Prompt | 位于消息列表最前端,定义 Agent 角色和行为的特殊指令 |
| Token | 模型处理文本的最小单位,约等于 0.75 个英文单词 |
| RAG | Retrieval-Augmented Generation,检索增强生成 |
| Context Compression | 通过摘要或筛选减少上下文 Token 消耗的技术 |
| Tool Call | Agent 生成的结构化工具调用请求 |
| Message Role | 消息的角色分类:system、user、assistant、tool |
| Attention Weight | 模型对不同上下文部分的关注程度分布 |
| Embedding | 将文本编码为向量表示的技术,用于语义检索 |
C. 上下文 Token 估算参考
| 内容类型 | Token 估算 |
|---|---|
| 100 个英文单词 | ~75 Token |
| 100 个中文汉字 | ~150-200 Token |
| 100 行代码 | ~300-500 Token |
| 一条工具定义 | ~100-300 Token |
| 一条消息的结构开销 | ~4-8 Token |
| 一段 JSON 数据 | 字符数的 ~1/3 |
文档版本: v1.0
最后更新: 2026-06-12
适用范围: Agent 上下文系统的设计、开发和调试

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)