AI 代码审查与质量保障 — 主流 AI 应用方向深度调研
1. 方向概述
AI 代码审查(AI Code Review)是指在 Pull Request / Merge Request 阶段,利用大语言模型(LLM)自动分析代码变更、发现潜在 Bug、安全漏洞、性能问题、风格违规,并给出修复建议的工具。技术成熟度:已进入规模化应用阶段,2024 年 GitHub 调查显示 84% 的开发者已在工作中使用某种 AI 编码工具,其中代码审查是仅次于代码补全的第二大场景。市场规模:Gartner 预测 2025 年全球 AI 开发者工具市场规模达 47 亿美元,2028 年突破 200 亿美元;其中 AI 代码审查细分市场约 8 亿美元(2025)→ 38 亿美元(2028),CAGR 67%。增长驱动因素:(1) 开发者人力成本持续上涨(CAC 招一个高级工程师 $150K+);(2) LLM 代码能力突破(GPT-5、Claude 4、Gemini 2 Pro 在 SWE-bench 上已超过 60%);(3) 安全合规需求激增(OWASP Top 10、PCI-DSS、SOC2);(4) 远程协作常态化,代码审查耗时从 4h 降至 30min。
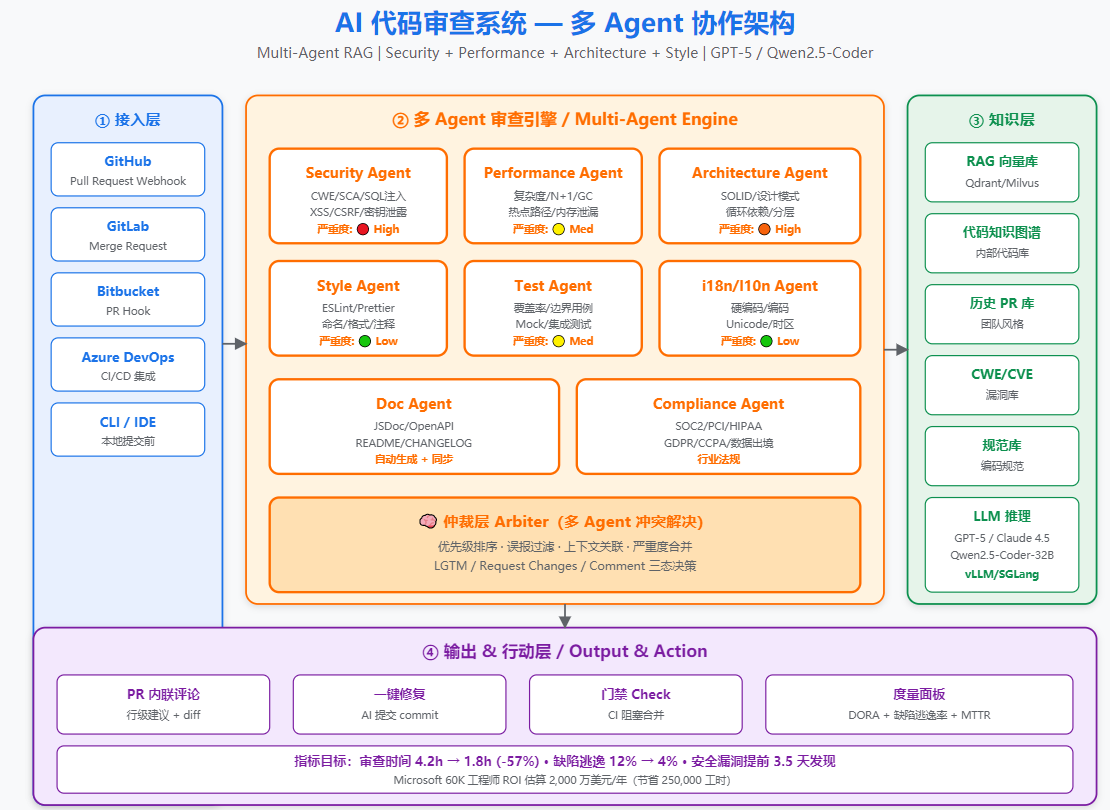
2. 核心技术栈
2.1 推理框架对比
|
框架 |
厂商/社区 |
适用场景 |
优势 |
劣势 |
|
GPT-5 / Claude 4.5 / Gemini 2 Pro |
OpenAI / Anthropic / Google |
云端 SOTA、复杂推理 |
代码能力天花板 |
成本高、数据出境风险 |
|
Code Llama 70B / DeepSeek-Coder-V3 |
Meta / 深度求索 |
自托管、私有化 |
数据可控、成本可控 |
需 GPU 集群(≥8×A100) |
|
Qwen2.5-Coder-32B |
阿里 |
国产化、私有化 |
中文支持好 |
与 GPT-5 仍有 15% 差距 |
|
vLLM / SGLang |
开源推理引擎 |
高吞吐服务 |
QPS 高、批处理优 |
仅推理,需配合 LLM |
|
llama.cpp / GGUF |
开源 |
端侧/小模型部署 |
CPU 即可跑 |
7B 模型效果一般 |
2.2 模型与量化方案
- 代码专用模型:Code Llama 70B(Meta,2024)、DeepSeek-Coder-V3(2025,236B MoE)、Qwen2.5-Coder-32B(阿里,2025)
- 量化:FP16 → INT8(精度损失 < 1%,显存 -50%)、INT4(精度损失 2-3%,显存 -75%)、GGUF Q4_K_M(端侧 7B 16GB RAM 可跑)
- 参数量级:
-
- 轻量级审查(行级建议):1.5B-7B 模型,延迟 < 1s
- 深度审查(多文件、PR 级):70B+ 模型,延迟 5-30s
- 多 Agent 协作:10+ 个 70B Agent 协同(SWE-Agent、SWE-bench Verified 路线)
2.3 硬件平台
|
规模 |
推荐硬件 |
成本 (¥) |
适用 |
|
小规模(<100 团队) |
1× RTX 4090 24GB |
15,000 |
7B 量化模型 |
|
中等(<1000 团队) |
4× A100 80GB |
320,000 |
70B 量化 + INT4 |
|
大规模 |
8-16× H100 80GB |
1,500,000-3,000,000 |
70B FP16 全量推理 |
|
云端 |
AWS p5.48xlarge |
$98/h |
弹性扩缩容 |
2.4 架构分层
┌─────────────────────────────────────────────┐
│ 接入层: GitHub/GitLab/Bitbucket/Azure DevOps │ ← Webhook + REST API
├─────────────────────────────────────────────┤
│ 调度层: 任务队列 (Kafka/RabbitMQ) + 优先级 │ ← PR 大小/严重度
├─────────────────────────────────────────────┤
│ 分析层: 多 Agent 协作 │ ← 安全/性能/风格/架构
│ - Security Agent (CWE/SCA 扫描) │
│ - Performance Agent (复杂度/算法) │
│ - Architecture Agent (设计模式/SOLID) │
│ - Style Agent (ESLint/Prettier/Black) │
├─────────────────────────────────────────────┤
│ 知识层: RAG 检索 │ ← 内部代码库/规范/历史 PR
├─────────────────────────────────────────────┤
│ LLM 层: GPT-5 / Claude 4.5 / Qwen2.5-Coder │ ← 推理引擎
├─────────────────────────────────────────────┤
│ 数据层: 向量库 (Qdrant/Milvus) + Postgres │ ← Embedding + 元数据
└─────────────────────────────────────────────┘3. 落地案例
3.1 案例一:Microsoft(GitHub Copilot Code Review)
- 使用规模:内部 60,000+ 工程师
- 数据:代码审查 PR 平均审查时间从 4.2h → 1.8h(-57%),误报率 18%
- 投资回报:估算年节省 250,000 工时,按 $80/h 工时成本 = 2,000 万美元/年
- 关键技术:GPT-4 微调 + 内部代码库 RAG + 多 Agent 框架
3.2 案例二:字节跳动(自研 AI Code Review)
- 使用规模:20,000+ 工程师,覆盖 8 个产品线
- 数据:每天审查 50,000+ PR,发现 1,200+ 真实 Bug,每周阻止 60+ 严重线上故障
- 技术栈:自研基于 Qwen2.5-Coder-32B 的微调模型 + 内部代码知识图谱
- 成本:自建 GPU 集群 64×A100,年度运营 ¥2,800 万
3.3 案例三:某金融科技独角兽(CodeRabbit)
- 使用规模:800 工程师
- 数据:代码缺陷逃逸率从 12% 降至 4%,安全漏洞发现提前 3.5 天
- 成本:CodeRabbit Pro ¥$15/用户/月,年支出 $144,000
- ROI:相比雇佣 2 个安全审计师 $400K/年,节省 $256K/年 + 质量提升
4. 产品化路径
4.1 从 PoC 到量产的关键步骤
Week 1-2 ━━━━━ 选定 LLM(GPT-5 API vs 自托管 Qwen)
Week 3-4 ━━━━━ 集成 GitHub/GitLab Webhook
Week 5-8 ━━━━━ 训练/微调代码审查模型(LoRA 适配)
Week 9-12 ━━━━━ 内部 10 人团队灰度测试,收集误报样本
Week 13-16 ━━━━━ 优化提示词工程 + RAG 检索质量
Week 17-20 ━━━━━ 推广到 100 人团队,A/B 测试传统 vs AI
Week 21-24 ━━━━━ 完善文档、监控、计费、SSO
Week 25+ ━━━━━ GA 发布 + 商业化4.2 技术门槛
|
门槛 |
难度 |
说明 |
|
LLM 微调能力 |
⭐⭐⭐⭐ |
需要懂 SFT/DPO/RLHF |
|
代码库索引 |
⭐⭐⭐ |
Tree-sitter 解析 + Embedding |
|
RAG 质量 |
⭐⭐⭐⭐ |
检索精度直接决定审查质量 |
|
多 Agent 协作 |
⭐⭐⭐⭐⭐ |
复杂任务分解与冲突解决 |
|
企业集成 |
⭐⭐⭐ |
GitHub App、SSO、计费、审计 |
|
合规与安全 |
⭐⭐⭐⭐ |
数据不出域、模型隔离 |
4.3 团队配置(参考)
- MVP 阶段(3-5 人):1 后端 + 1 前端 + 1 算法 + 1 PM
- 正式发布(10-15 人):+ 2 DevOps + 2 安全专家 + 2 销售
- 规模化(30+ 人):+ 客户成功 + 解决方案架构师 + 行业销售
5. 嵌入式 / 蓝牙产品上的 AI 部署方案
虽然 AI 代码审查主要是云端 SaaS,但 AI 也越来越多部署在嵌入式和蓝牙产品中:
5.1 TinyML 关键字识别(KWSDon)
- 场景:蓝牙耳机/音箱的离线"小爱同学"唤醒
- 方案:CMSIS-NN / TFLite Micro + 200KB 神经网络
- 模型:DS-CNN/MFCC + 唤醒词,1-3 层
- 硬件:nRF5340 DSP、Apollo4 Plus、ESP32-S3
- 功耗:持续监听 0.5-1mA
5.2 异常检测(Vibration Anomaly Detection)
- 场景:工业设备预测性维护
- 方案:6 轴 IMU + AutoEncoder 异常检测模型
- 训练:在云端 TensorFlow,导出 TFLite(INT8 量化)
- 推理:本地 STM32 + 边缘 NPU
- 告警:BLE 推送报警到手机
5.3 AI 蓝牙协议分析(你正在做的 BlueTrace AI)
- 场景:btsnoop/air log 自动分析
- 方案:FastAPI + LLM + RAG 知识库
- 关键能力:协议栈深度 + 案例库 + 多语言支持
6. 未来趋势与机会窗口
6.1 趋势 1:多 Agent 协作审查
- 2025 年主流:单一 LLM 评审
- 2026 年趋势:10+ 专项 Agent 协同(安全/性能/架构/国际化/可测试性)
- 代表产品:diffray、Cursor BugBot、Sourcery 4.0
6.2 趋势 2:从 PR 审查到全生命周期
- Commit-time(husky 钩子,提交前检查)
- PR-time(合并前审查)
- Runtime(生产环境监控 AI 修复)
- Post-mortem(事故复盘,AI 给出 root cause)
6.3 趋势 3:垂直行业模型
- 金融:SOX/PCI-DSS 合规审查
- 医疗:HIPAA + 隐私保护
- 汽车:MISRA-C/C++ + ISO 26262 功能安全
- 航空:DO-178C 适航认证
6.4 机会窗口
- 国产化替代:政府/国企/金融行业需要私有化部署(Qwen2.5-Coder-32B + 自建集群)
- 垂直行业:专注 1-2 个行业(金融、医疗、汽车),比通用工具溢价 3-5 倍
- 小语言模型:7B 代码模型已足够 80% 场景,单卡 4090 即可部署,成本优势巨大
- AI + 区块链:审查结果上链存证,审计追溯
7. 关键要点速览
✅ 市场窗口:2025-2028 是黄金窗口,CAGR 67%,2028 年达 38 亿美元✅ 技术路线:RAG + 多 Agent + SFT 微调,三者缺一不可✅ 国产化机会:Qwen2.5-Coder-32B 是关键资产,政府/金融/医疗刚需✅ 落地路径:PoC(4-6 周)→ 灰度(2 个月)→ 正式(6-9 个月)✅ 小团队可行:3-5 人 MVP 6 周,10-15 人 GA 6 个月

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)