41台巡检机器人、5大高危场景、7种感知模态——清华发布全球首个工业安全多模态大模型评测基准

导读
工业巡检现场环境复杂——强光照变化、遮挡、镜面反射、传感器噪声,加上火灾、烟雾、人员闯入、设备过热等高危事件,现有AI系统难以可靠感知和推理。
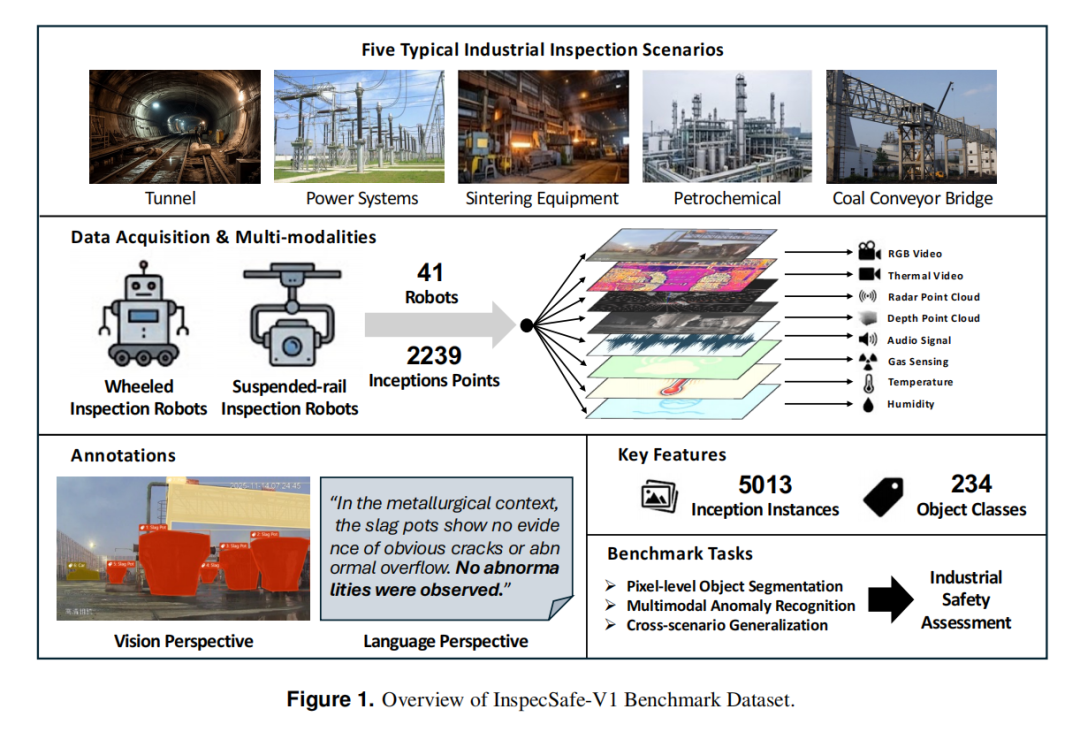
清华大学自动化系等机构联合发布InspecSafe-V1,这是首个面向工业巡检安全评估的真实场景多模态数据集。数据来自41台轮式和轨式巡检机器人、2,239个有效巡检点,涵盖隧道、电力、烧结、油化、煤炭5类工业场景,共5,013个巡检实例。每个实例提供RGB视频、红外热像、音频、深度点云、雷达点云、气体浓度、温湿度7种同步感知模态,并配以像素级分割标注(234类工业对象)、场景描述和安全等级标签(四级)。基准测试显示,即使是最先进的视觉语言模型(VLM)在复杂工业环境下仍面临挑战——推理增强模型准确率比纯指令模型高出约8个百分点,但误报率高达30%以上,暴露了工业安全AI的巨大提升空间。
文章信息
-
标题:InspecSafe-V1: A Multimodal Benchmark Dataset for Industrial Inspection Safety Assessment
-
机构:清华大学、阿里达摩院、东南大学等
-
数据集:https://huggingface.co/datasets/Tetrabot2026/InspecSafe-V1
一、背景与挑战:工业巡检AI缺乏真实多模态安全数据
工业巡检环境具有高噪声、严重遮挡、大范围光照变化、镜面反射、复杂设备布局等特点,同时可能出现明火、烟雾、人员违规闯入、设备过热、异常气体等高危事件。巡检机器人需要长期自主运行,亟需具备场景理解和安全推理能力的AI系统。
当前工业视觉数据集主要面向质量检测和缺陷识别(如MVTec AD、VisA、Real-IAD等),存在三大局限:
-
场景过于理想化:在静态、可控背景下采集,缺乏光照变化、遮挡、传感器噪声等真实扰动。
-
模态单一:大多仅提供RGB图像,缺少红外、音频、点云、气体检测等多模态数据。
-
缺乏安全标注:没有场景级语义描述和安全等级标签,无法支撑安全推理。
自动驾驶数据集(KITTI、nuScenes)虽有多模态,但语义系统面向道路环境(车辆、行人、交通标志),与工业巡检设备、安全因素不匹配。
InspecSafe-V1填补了这一空白:完全来自真实巡检机器人在一线作业中采集的数据,涵盖5类典型工业场景,提供7种同步感知模态和细粒度安全标注,为工业具身智能安全评估建立了标准化基准。
图片来源于原论文
二、方法:多平台、多模态、多级标注的工业巡检数据集
2.1 机器人平台与采集场景
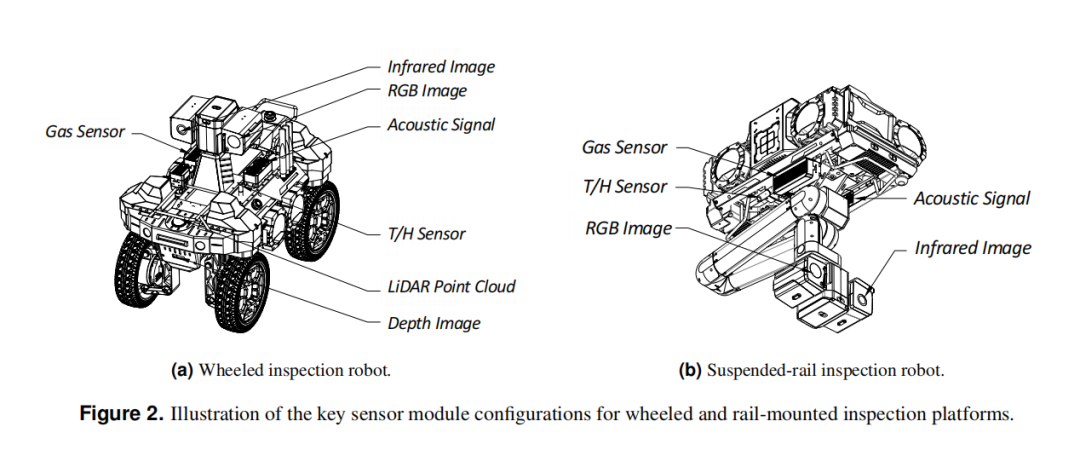
数据来自41台轮式和轨式巡检机器人,覆盖2,239个有效巡检点。机器人配置了多模态感知系统:
-
RGB相机:2560×1440或1920×1080,25fps
-
红外热像仪:1280×1024或640×480,25fps
-
深度相机(Orbbec TM265-E1):0.05m-5m
-
3D LiDAR(LeiShen MID360):40m(10%反射率)/70m(80%反射率)
-
麦克风阵列:8000Hz,双声道
-
气体传感器(可燃气体、有毒气体等)、温湿度传感器
采集覆盖5类工业场景:
-
隧道
-
电力设施
-
烧结设备(冶金)
-
油化工厂
-
煤炭输送栈桥
每个巡检点停留约10-15秒,同步采集视频、音频、点云、环境数据。点云采集时长约3秒(15Hz),视频全程录制。数据集包含白天和夜间时段,部分关键点每天最多采集两次(00:00-12:00和12:00-24:00),以捕捉光照和运行节律变化。
图片来源于原论文
2.2 标注体系
视觉标注:
-
从视频中每隔5帧抽取候选帧,基于深度特征过滤冗余,保留高多样性样本。
-
采用LabelStudio手动标注像素级实例分割多边形,覆盖234个对象类别(工业设备、基础设施、安全相关目标如人员、消防设施、安全帽等)。
-
两类平台(轮式/轨式)各有不同的传感器配置,但所有实例统一提供RGB图像和对应的像素级分割掩码,确保语义一致性。
语义标注:
-
场景描述:自然语言描述环境上下文、关键对象和可见事件。
-
安全等级:根据工业场景安全标准分为四级(表3):
-
Level I:高安全威胁(明火、烟雾、人员昏倒、油泄漏、未戴安全帽/手套/口罩等)
-
Level II:中等安全威胁(使用手机、积水、油污、异物、缺少个人防护装备等)
-
Level III:低安全威胁(水坑、小异物、未戴口罩等)
-
Level IV:无异常
-
-
多级标注经两轮独立验证(每轮随机抽5%,准确率>95%方可通过)。
2.3 数据规模与分布
|
统计项 |
数值 |
|---|---|
|
巡检机器人 |
41台 |
|
有效巡检点 |
2,239个 |
|
巡检实例 |
5,013个 |
|
训练集帧数 |
3,763(正常3,014,异常749) |
|
测试集帧数 |
1,250(正常999,异常251) |
|
对象类别 |
234类 |
|
同步模态 |
7种 |
对象类别呈现长尾分布:前五类(管道、交通锥、支架、托辊、螺栓)占39.3%,前十类占52.0%。
不同场景的正常/异常比例差异显著:
-
油化场景异常比例最高(34.9%)
-
电力场景异常比例最低(11.8%)
-
冶金场景异常比例仅0.1%
三、实验结果:VLM在工业安全评估中的表现与短板
3.1 基准评测设置
采用固定提示模板(附录S1),输入RGB图像,要求模型输出:
-
场景描述(自由文本)
-
安全等级(Level I-IV)
评估指标:
-
准确率(Acc):安全等级预测与真实标签的匹配率
-
语义相似度(SemSim):生成描述与标注描述的余弦相似度(BGE-M编码器)
评测模型包括:GPT-5.2、Claude 4.5 Sonnet、Qwen3-VL系列(指令版/推理版)、Doubao-SEED、GLM-4.6等。
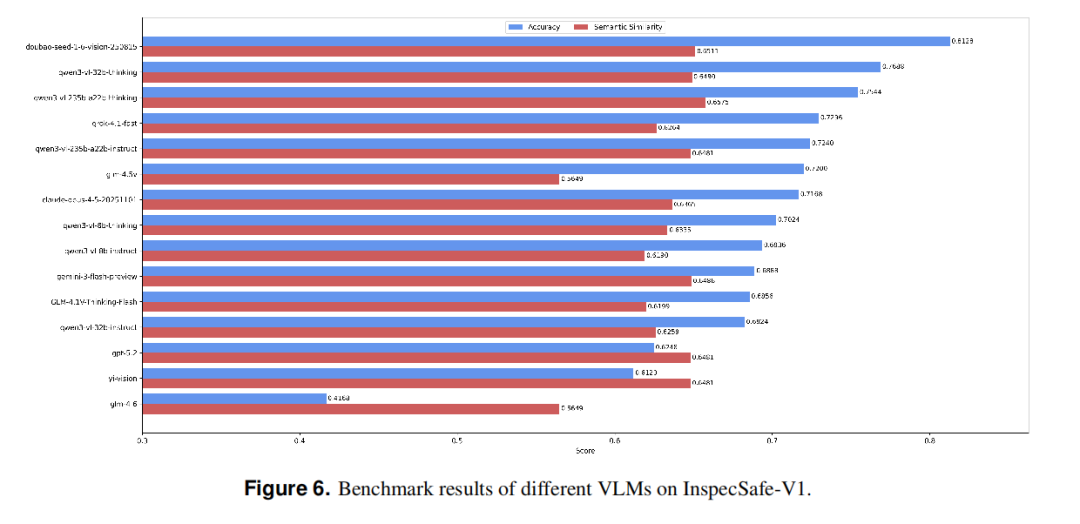
3.2 主要结果
-
推理增强模型显著优于指令模型:Qwen3-VL推理版比指令版准确率高出约8个百分点,同时误报更少。
-
模型大小与性能不严格正相关:部分小参数模型表现优于大参数模型,说明感知鲁棒性和推理能力的对齐更为关键。
-
误报率差异显著:GPT-5.2等模型将超过30%的正常内容误判为异常,可能导致部署中报警负载过大。
图片来源于原论文
3.3 典型错误模式
-
场景识别错误导致级联失败:GLM-4.6将煤炭环境误判为油气化工设施,由于安全标准高度依赖场景,导致后续推理全部错误。
-
细粒度违规检测缺失:使用手机、未戴安全手套/安全帽等明显违规行为被漏检,主因是小物体尺寸、遮挡或训练覆盖不足。
3.4 定性分析
示例显示,某些模型在强光照、反光、背光、高对比阴影等视觉干扰下误判正常场景为异常,而推理增强模型更善于整合证据做出一致判断。

图片来源于原论文
四、数据特点与挑战分析
4.1 多模态融合的复杂性
7种同步感知模态(RGB、热像、音频、深度、雷达、气体、温湿度)提供了丰富信息,但模态间的时空对齐(点云3秒窗口 vs 视频10-15秒窗口)和传感器差异(轮式/轨式平台配置不同)对算法设计提出挑战。数据集以“巡检点”为单位组织,确保跨模态对齐。
4.2 类别长尾与现实不平衡
管道(12.9%)、交通锥(8.9%)等头部类别与尾部类别(如某些特定设备)差距悬殊,反映了真实巡检中的出现频率。异常样本比例因场景而异(0.1%~34.9%),为不平衡学习和少样本学习提供了天然测试平台。
4.3 安全等级的工程化设计
四级安全标签依据具体工业标准制定(表3),例如油气场景Level I包括明火、烟雾、无安全帽、人员昏倒、油泄漏等;Level II包括积水、使用手机;Level III包括异物。这种结构化标签可被直接用于训练和评估,且与场景描述形成互补。
4.4 当前VLM的共性不足
-
对恶劣视觉条件(强光、反射、遮挡)的鲁棒性不足,误报率高。
-
跨场景推理能力弱,易将A场景的安全规则误用于B场景。
-
小目标(如手机、手套)和细粒度行为(如违规操作)检测能力有限。
五、总结与展望
核心贡献:
-
首个工业巡检安全评估多模态真实场景数据集:5类场景、41台机器人、2,239个巡检点、5,013个实例、7种同步感知模态。
-
多层级精细化标注:像素级实例分割(234类)、场景描述、四级安全标签,经两轮独立验证确保质量。
-
基准评测揭示VLM短板:推理增强模型优于指令模型,但误报率高达30%以上,场景错认和细粒度违规检测仍是大问题。
-
促进工业具身智能安全评估:为多模态感知、跨模态融合、视觉语言联合建模、跨域泛化等研究提供标准化平台。
局限与未来方向:
-
数据规模和场景多样性仍有扩展空间(极端工况、罕见危害类型、长时序数据)。
-
未来版本将增加更多巡检点、更多机器人平台、更细粒度的多危害并行标注,以及时序安全等级演化。
InspecSafe-V1以真实、多模态、细粒度的标注填补了工业安全AI评估的关键空白,为推动具身智能在复杂工业环境中的可靠部署提供了重要基石。数据集已公开,欢迎研究社区使用。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)