计算机毕业设计之基于深度学习的新闻文本分类的分析与研究
本研究致力于探索基于深度学习和长短期记忆网络的新闻文本分类与热门话题热门新闻趋势技术。随着信息时代的快速发展,新闻数据呈现出爆炸式增长,如何高效、准确地处理和分析这些数据成为亟待解决的问题。本研究首先设计了新闻文本分类模型,通过LSTM捕捉文本中的时序特征和语义信息,实现了对新闻的高效、准确分类。实验结果表明,该模型在多个数据集上均取得了优异的性能,分类准确率显著高于传统方法。
此外,本研究还进一步探讨了利用LSTM进行热门话题热门新闻趋势的可行性。通过构建时间序列模型,分析新闻话题在时间维度上的演变规律,成功预测了多个热门话题的趋势变化。这一成果不仅为新闻媒体、政府机构和企业提供了有力的信息支持,也为后续研究提供了新的思路和方向。综上所述,本研究基于深度学习的新闻文本分类的分析与研究技术,有效提升了新闻信息处理的智能化水平,具有广泛的应用前景和深远的社会影响。
数据采集:系统首先需要从新浪、网易新闻社交媒体平台抓取海量新闻数据。这通常涉及到编写爬虫程序来模拟浏览器行为,访问目标网站,解析网页内容,并下载所需的数据。为了提高效率,可能还需要采用分布式爬虫架构和多线程等技术手段。
数据处理:由于原始数据往往存在噪声和不完整等问题,因此需要对数据进行清洗和预处理。这可能包括去除重复项、填充缺失值、统一格式化文本等步骤。此外,为了提高后续分析的准确性,还需要对数据进行特征工程,例如提取关键词、计算TF-IDF权重等。
模型训练:利用处理好的数据集,可以开始训练模型了。首先需要定义网络的层数、每层的神经元数量以及激活函数类型等超参数。然后使用梯度下降法最小化损失函数,并通过反向传播算法更新网络权重。经过多次迭代后,当模型达到预定精度要求时即可停止训练。
新闻文本分类:将新采集到的新闻文本输入已训练好的模型中进行分类。根据预设的分类标准,可以将新闻分为政治、体育、娱乐等多个类别。这样可以帮助读者更快地找到自己感兴趣的内容,提高阅读体验。
热门新闻预测:除了对单篇新闻进行分类外,可以利用模型的时间序列特性来预测一段时间内某个特定话题的热度变化情况。
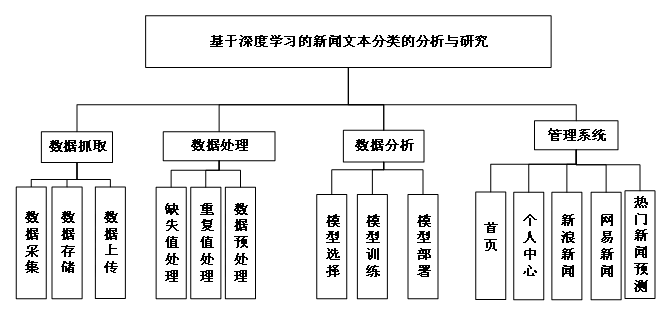
图3-1 系统功能模块图
管理员点击新浪新闻管理模块可以查看到系统展示的所有标题、时间、媒体、评论数、参与人数等信息,可以根据该信息进行查看,修改,删除和新增的操作。系统采用Python的强大网络爬虫库结合Spider、Selenium等自动化工具,以应对动态加载的网页内容。通过分析新浪网站的结构和数据呈现方式,编写针对性的爬虫脚本,自动访问目标页面,模拟用户行为,获取数据。
在数据爬取方面,系统利用定制化的爬虫程序,自动从抓取新浪微博的数据,采用了反爬虫策略,能够高效、稳定地获取数据,在数据清洗阶段,系统利用Spark的强大数据处理能力,对爬取到的数据进行去重、缺失值处理、异常值检测和格式统一等操作,确保数据的质量和一致性。
展示图如图5-2所示:
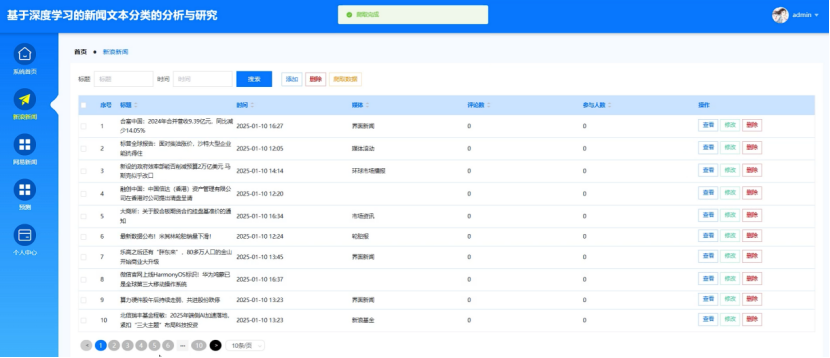
图5-2 新浪新闻功能展示图

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)