超越Scaling!千分之一的数据,省几百倍算力的类脑模型来了
还记的中国国际大学生创新大赛(2025)夺得冠军的清华学霸吗:0.027B手机AI模型,估值2亿美金,三个清华学霸如何获得国际大学生创新大赛冠军。

当时,团队仅用27M参数和1000个训练样本,就在ARC-AGI-2基准上超过了OpenAI o3-mini-high和DeepSeek R1。

如今,他们将这条技术路线向语言建模的延伸,HRM-Text诞生了。

类脑架构和训练目标的联合设计,把预训练的算力门槛砍掉两个数量级,实现了超越Scaling的高效预训练。

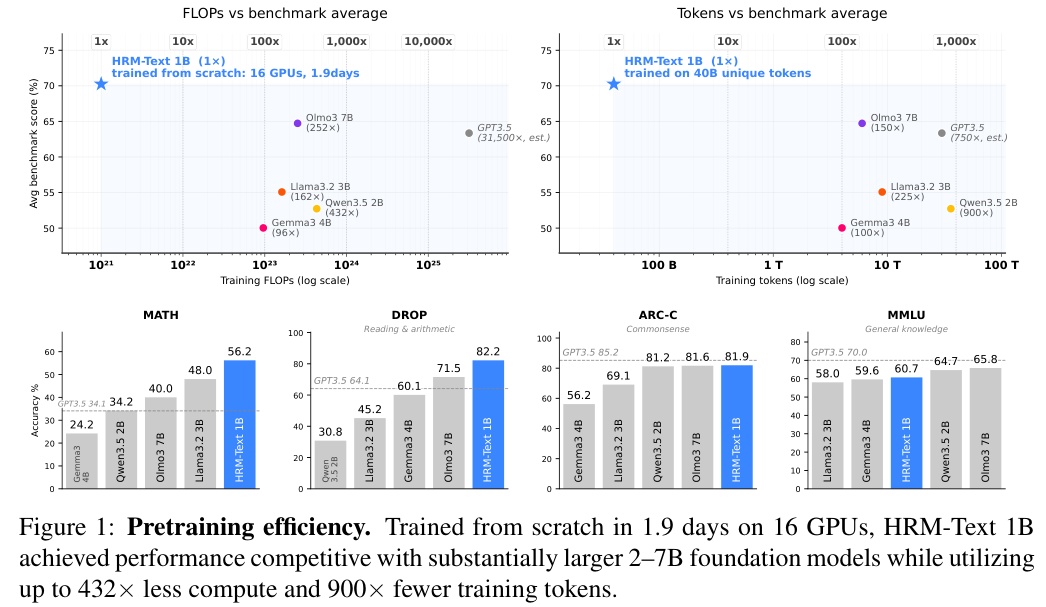
一个1B参数的模型,训练token只有同级别模型的百分之一到千分之一,算力消耗低了96到432倍,却在MMLU上拿到60.7%,GSM8K上84.5%,MATH上56.2%。
大脑借灵感的创新之路
两个清华学霸,王冠(Guan Wang)和陈威廉(William Chen)于2024年创立Sapient Intelligence。总部位于新加坡,并在北京和硅谷设有研发中心。

核心团队由来自Google DeepMind、DeepSeek、Anthropic和xAI的前研究人员,以及清华大学、北京大学、UC伯克利和剑桥大学的顶尖学者组成。
2025年,两位年轻的创始人因拒绝了埃隆·马斯克旗下xAI数百万美元的收购要约、坚持独立从零构建全新AI架构而引发创投圈和科技界的广泛关注。

Sapient Intelligence坚信依靠无限制缩放定律(Scaling Law)的GPT模式存在结构瓶颈。
模仿人类大脑的快慢系统协同机制,他们提出用分层架构(Hierarchical Architecture)代替传统链式思考(Chain-of-Thought, CoT)。
Sapient Intelligence在2024年12月完成2200万美元种子轮,由Vertex Ventures和CMBC International领投,JAFCO、住友集团等跟投,估值超过2亿美元。据PitchBook数据,公司累计融资约3310万美元。
公司的目标是构建自进化(self-evolving)的AI架构,解决长时域推理(long-horizon reasoning)难题。
团队之前的HRM(Hierarchical Reasoning Model,层级推理模型)已经在符号推理任务上,展示了用27M参数和1000个训练样本,就能达到近完美准确率的能力,在ARC-AGI-2基准上甚至超过了OpenAI o3-mini-high和DeepSeek R1。
刚刚发布的HRM-Text模型,是这条技术路线向语言建模的延伸。
两层循环,一个目标
HRM-Text的核心思路来自一个神经科学观察:人类大脑的额顶回路(frontoparietal loop)采用多时间尺度的组织方式,慢速的“战略层”负责规划和把控方向,快速的“执行层”负责局部迭代和精修。HRM-Text把这套逻辑搬进了模型架构。
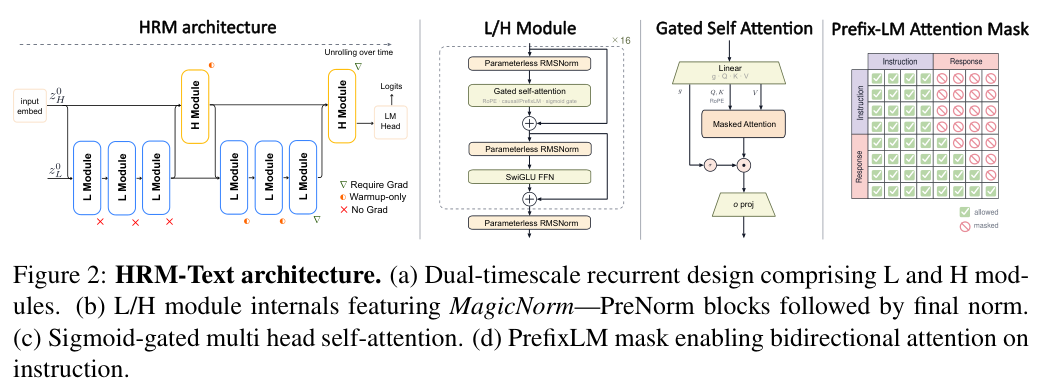
具体来说,HRM-Text用两个模块替换了标准Transformer:H模块(慢速战略层)和L模块(快速执行层)。
前向传播的过程是这样的,初始状态由输入token嵌入得到一个高层状态,然后进入两个H循环,每个H循环内部先跑3次L模块更新,再跑1次H模块更新。整个过程相当于8个H/L模块步骤,但因为参数共享,实际参数量只有1B。
这种循环结构带来了一个关键优势:有效深度(effective depth)。标准Transformer和Looped Transformer在深层会出现表征趋同的问题,越深的层贡献越小。HRM-Text通过层间差异分析和logit lens KL散度分析都证明了,它的每一层都在持续做出有意义的表征变化,深层依然在干活,没有躺平。
但循环结构也带来了一个老大难问题:梯度不稳定。同一个变换被反复应用,梯度要么爆炸要么消失。HRM-Text用了两招来稳住局面。
第一招是MagicNorm。Transformer里归一化层放哪儿一直是个两难:PostNorm能限制激活方差,但梯度路不通;PreNorm梯度路通畅,但残差累积会让方差失控。循环模型把这个矛盾放大了N倍。MagicNorm的做法是:每个循环模块内部用L个PreNorm块,模块出口加一个归一化层。前向传播时,状态每经过一个循环步骤就被归一化一次,方差被稳住。反向传播时,由于截断反向传播(TBPTT)的梯度窗口K远小于总循环步数N,梯度只穿过K次模块级归一化,同时通过L个内部PreNorm的恒等连接直流通路,整体表现接近PreNorm的优化稳定性。前向像PostNorm,反向像PreNorm,各取所需。
第二招是warmup deep credit assignment(预热深度信用分配)。训练初期,梯度只回传最后2个循环步骤,随训练推进线性扩展到5个。先学短程依赖,等模型稳定了再引入长程依赖。附带好处是,前期反向传播计算量更少,训练更快。
架构解决的是怎么算的问题,训练目标解决的是算什么的问题。HRM-Text在这里做了一个违背行业惯例的选择:不用原始文本做自回归预训练,而是从零开始只用指令-响应对(instruction-response pairs)训练,优化目标只算响应部分的负对数似然。
标准预训练在整个序列P(x)上算loss,大量算力花在预测指令文本上,但推理时指令是已知的,预测指令完全不需要。HRM-Text只让模型学习在给定指令的条件下生成响应,把每一条训练数据的信号密度拉满。
这个条件生成目标还天然适配PrefixLM(前缀语言模型)注意力掩码。指令部分的token之间可以双向注意,像编码器一样充分理解指令;响应部分保持因果掩码,像解码器一样自回归生成。标准因果注意力中,指令token只能看到自己之前的token,注意力模式偏局部。PrefixLM让指令段的注意力熵更高、覆盖更广,模型对指令的理解更充分。
少即是多
HRM-Text 1B从头训练,只用了400亿(40B)独立token,总训练时长600亿token,在两个8xH100节点上跑46小时,费用约1472美元。
作为对比,Qwen 3.5 2B用了36万亿token训练,算力是HRM-Text的432倍;Llama 3.2 3B用了9万亿token,算力是162倍;Gemma 3 4B用了4万亿token,算力是96倍。
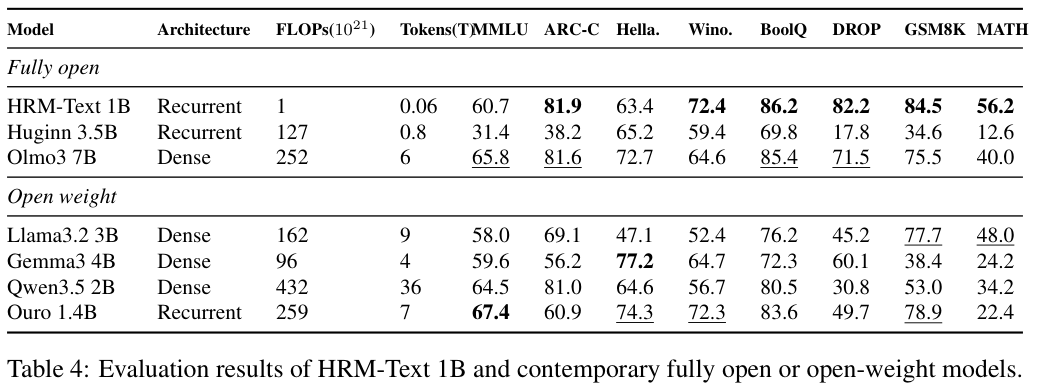
HRM-Text在推理密集型基准上表现突出。
GSM8K的84.5%比7B的OLMo高出9个百分点,MATH的56.2%比所有对比模型都高。在DROP上82.2%一骑绝尘,ARC-C上81.9%仅次于OLMo。在MMLU这种广谱知识基准上,60.7%的成绩虽然不及大模型,但考虑到它只看了400亿token,已经够让人惊讶了。
团队也坦诚指出,HRM-Text在知识广度上依然受限于数据规模和模型体量。MMLU上的表现说明,事实性知识覆盖对数据量和参数量更敏感,而推理和任务执行能力可以通过架构和目标的设计来弥补。
这指向一个有趣的未来方向:把推理和知识解耦。一个紧凑的循环推理核心,搭配外部检索或学习型记忆模块来补充事实性知识。团队提到了Engram等条件记忆方法作为可能的技术路线。
“我们没有把HRM-Text呈现为最终或最优的语言模型,而是把它当作一个存在性证明(existence proof),特定的结构先验和针对性训练目标可以彻底改变算力到性能的转化比。”
代码和模型权重已经开源,邀请社区一起探索这条路能走多远。
参考资料:
https://arxiv.org/pdf/2605.20613
https://github.com/sapientinc/HRM-Text
https://huggingface.co/sapientinc/HRM-Text-1B

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献163条内容
已为社区贡献163条内容

所有评论(0)