【Agentic RL / 强化学习框架】Miles 项目技术分析---(2)--- 关键技术
【Agentic RL / 强化学习框架】Miles 项目技术分析—(2)— 关键技术
文章目录
- 【Agentic RL / 强化学习框架】Miles 项目技术分析---(2)--- 关键技术
-
- 0x00 概要
- 0x01 agentic_tool_call
- 0x02 TITO
- 0x03 Session Server:TITO 的产品化外壳
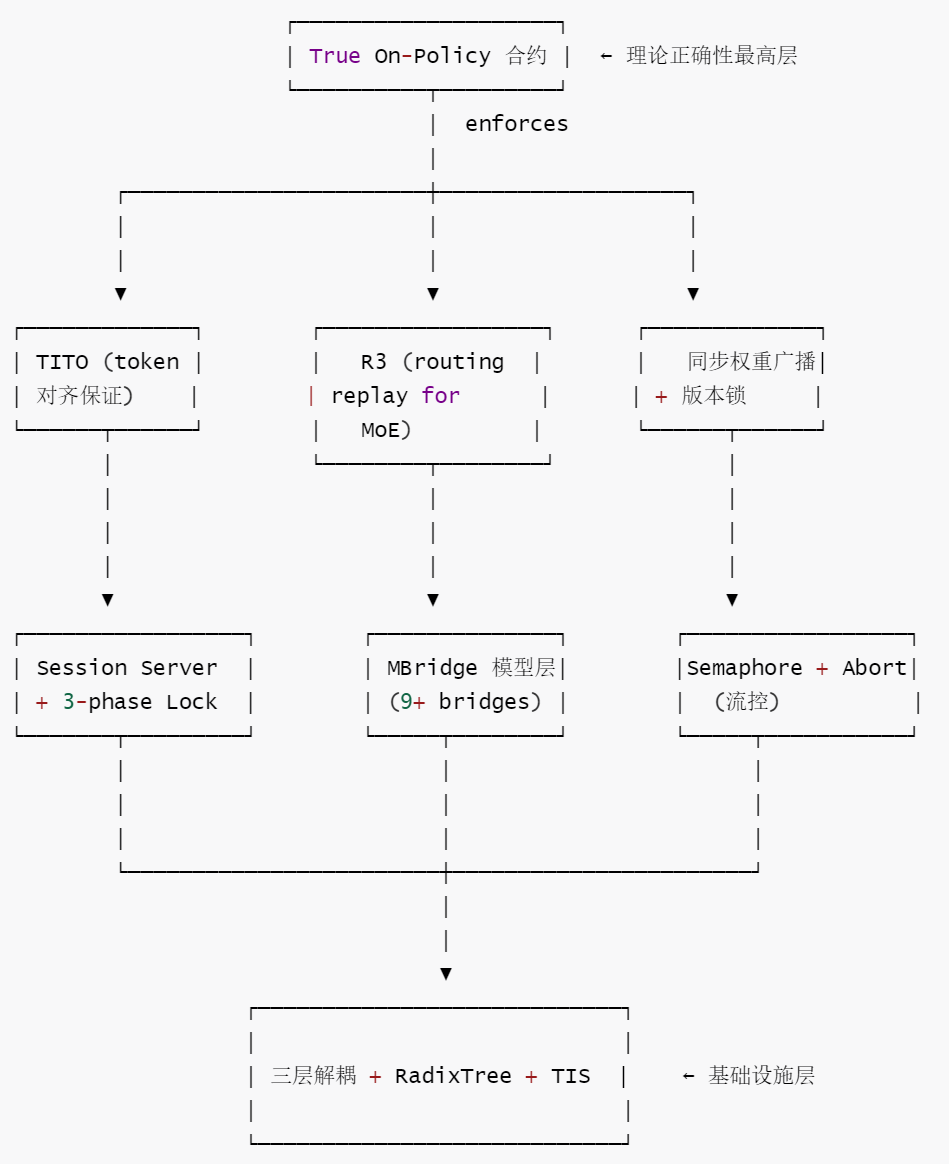
- 0x04 训推一致性频谱:从全异步到比特级一致的逐层递进
- 0x05 Multi-Agent 协同训练:从共享模型的角色分工到跨集群的异步协同进化
- 0x06 环境
- 0x07 MBridge 模型抽象层
- 0x08 RadixTree 前缀复用中间件
- 0xEE 个人信息
- 0xFF 参考
0x00 概要
Miles 将 Slime 的"研究级 RL 框架"升级为"Agentic-first 的企业级生产系统",核心创新在于用 Session/TITO 解决多轮 tokenization 正确性,用全异步+staleness 解决性能,用 R3+True On-Policy 解决稳定性。
Miles 的技术特色总结如下:
| 特色 | 核心理念 | 关键实现 |
|---|---|---|
| Agentic-First | Agent 开发像写普通应用 / 多轮 RL 的正确性不是"附加功能",而是设计的起点 | Session Server + TITO + agentic_tool_call → miles/rollout/session/ + miles/rollout/generate_hub/ |
| 正确性优先 | 尽力消除训推不一致源,通过多个逐步严格的层次渐进逼近 | R3 → 统一 FP8 → True On-Policy(dense 模型) → TIS/MIS |
| 性能极致 | 推理是瓶颈,在同步/异步/零拷贝/投机解码多维度榨取吞吐 / GPU永不空闲 | 全异步 train_async.py + 投机解码 + 零拷贝 + P2P RDMA + 部分 rollout |
| 渐进式保证 | 用户可以根据场景在 “速度” 和 “正确性” 之间自主选择 | 频谱:全异步 → Staleness 过滤 → TIS → R3 → True On-Policy |
| 工程纪律 | 静默错误→显式断言 / Chat template 正确性是 Agentic RL 的基石,必须验证 | Chat template 验证+运行时prefix校验 / CI 断言 tito_session_mismatch_rate == 0 |
| 插件化扩展 | 模型/桥接/converter 从核心代码剥离 | miles_plugins/ 包 + middleware_hub + megatron_to_hf/ |
| Multi-Agent | 从简单协同(同模型不同 prompt)到复杂异步(MrlX)的全频谱支持 | 内置 Solver-Rewriter-Selector + MrlX 框架 |
主要关键技术如下:
| # | 技术 | 一句话价值 |
|---|---|---|
| 1 | TITO | token↔logprob 1:1 对齐, 多轮 RL 的前提 |
| 2 | True On-Policy 合约 | 声明式消除 off-policy bias |
| 3 | R3 路由重放 | MoE 推理↔训练路由一致性 |
| 4 | 三层解耦架构 | 训练/缓冲/推理物理隔离可独立扩缩 |
| 5 | Session Server + 3-phase Lock | 有状态 Agent 多轮管理 |
| 6 | RadixTree 前缀复用 | KV-cache 命中率最大化 |
| 7 | 同步权重广播 + 版本锁 | on-policy 的物理保障 |
| 8 | Semaphore + FIRST_COMPLETED | 精确匹配 engine 容量的并发控制 |
| 9 | MBridge 模型抽象层 | 9+ bridge 支持异构架构 |
| 10 | TIS + Batch Abort | 过时样本修正 + GPU 资源回收 |
本篇会选择部分(其中部分功能是miles在slime基础之上直接增强的)进行分析。
0x01 agentic_tool_call
在 Agentic RL 中,Agent 开发者需要处理的不只是"如何调用工具、如何解析结果",还有一连串的训练基础设施问题,而agentic_tool_call 是将 Agent 业务逻辑与 RL 训练基础设施解耦的适配器。
1.1 问题
agentic_tool_call 要解决的问题是:Agent 逻辑与训练基础设施的深度耦合。
在 Miles 之前,如果你想做 Agentic RL 训练——即让 Agent 进行多轮工具调用,并从交互中学习——你需要自己处理以下全部问题:
- 管理多轮会话状态(Session 创建、状态追踪、销毁)
- 处理增量 tokenization(保证 pretokenized prefix 复用,即 TITO)
- 收集每轮的 token IDs 和 log probs
- 将多轮对话转换为训练样本(正确的 loss mask——哪些 token 该训练、哪些不该)
- 处理 trailing token 边界问题(stop token 去重——这个尤其容易出错)
- 处理截断和异常(session 超长、Agent 执行失败)
- 合并多轮 samples 为一个训练 batch
每开发一个新 Agent 就要重新实现数百行 boilerplate。这些不是"写得好一点可以避免"的麻烦——它们是 Agentic RL 的固有复杂度。任何一个没处理好,训练就会在某个不可预测的时刻崩溃。
更深层的问题是:Agent 逻辑与 RL 训练基础设施高度耦合。每换一个新 Agent(从数学推理换到代码生成、从单轮对话换到多轮工具调用),你都要重新实现上述全部逻辑。Agent 开发者被迫成为 RL 基础设施专家——这违背了"关注点分离"的基本工程原则。
1.2 解决方案
agentic_tool_call 的解决方案是一个清晰的分层架构,其核心设计是:关注点分离的适配器模式。即, agentic_tool_call 框架用一个适配器模式将两者完全解耦:Agent 只需像调用 OpenAI API 一样写业务逻辑,框架透明完成所有训练数据生产。
────────────────── 用户的 Agent 函数 (纯业务逻辑) ──────────────────
async def my_agent(base_url, prompt, request_kwargs, metadata):
# 只关心: 调用 API、解析结果、执行工具
response = await openai_call(base_url, messages=[...], ...)
tool_result = await execute_tool(response.tool_calls)
response2 = await openai_call(base_url, messages + [tool_result], ...)
return {"reward_info": ...}
─────────────────────────────────────────────────────────────────
↓
↓ 完全不需要知道训练细节
↓
─────────────── agentic_tool_call.generate() - 框架层 ─────────────
自动处理:
① Session 创建 & TITO tracing
② 调用用户 Agent 函数
③ 收集 Session Records (token IDs + log probs)
④ 转换为训练 Samples (正确的 loss mask + token 对齐)
⑤ 处理 trailing token trim (stop token 去重)
⑥ 截断超长序列
⑦ 合并/拆分多轮 samples
⑧ 异常处理 (Agent 失败 → ABORTED 状态)
─────────────────────────────────────────────────────────────────
Agent 函数不需要 import miles 的任何模块。它只需要接收 base_url(指向 Session Server),像调用标准 OpenAI API 一样发起请求。框架层在 Agent 函数的"下方"透明完成所有训练基础设施工作。
1.3 框架自动化的主要流水线
框架在 generate() 函数中自动完成从 Session 创建到训练 Sample 产出的主要流程如下:
| 步骤 | 操作 | 说明 |
|---|---|---|
| 1. Session 创建 | OpenAIEndpointTracer.create() → POST /sessions |
建立新的 TITO 追踪会话 |
| 2. 调用 Agent | await custom_agent_function(base_url, prompt, ...) |
执行用户业务逻辑,Agent 通过 base_url 与 Session Server 交互 |
| 3. 收集 Records | tracer.collect_records() → GET /sessions/{id} + DELETE |
获取完整的多轮 token/logprob 记录并清理 |
| 4. TITO 对齐 | compute_samples_from_openai_records() |
trailing token trim,确保 token 序列精确对齐 |
| 5. 转 Sample | 每轮转为一个 Sample,合并 metadata |
构建正确的 loss mask 和 token 边界 |
| 6. 异常处理 | try/except → ABORTED status |
任何环节失败都优雅降级,不阻塞训练 |
每一步都封装了复杂的内部逻辑。Agent 开发者看到的是一个 generate(agent_function, prompt) 的简单接口——传入业务函数和 prompt,拿到训练就绪的 Sample 列表。
1.4 深入三个关键设计
1.4.1 Trailing Token Trim:多轮对话中最容易出错的边界问题
我们思考下这样一个场景。第 N 轮,模型生成 assistant 回复,最后一个 token 是 <|im_end|>(stop token)。第 N+1 轮,Chat Template 渲染 tool 消息时,也会在边界处追加 <|im_end|>——这是模板自动添加的,不是模型生成的。
问题:如果不去重,同一个 <|im_end|> token 会被计算两次——一次作为第 N 轮 assistant 输出的末尾,一次作为第 N+1 轮 tool 消息的边界 token。这会导致 loss 计算错误(把不属于任何一轮的 token 纳入训练)和 token 序列膨胀(每次拼接都多一个 token)。
Miles 的解决方案是一个贪婪匹配 + 裁剪算法:
accumulated_token_ids = [P1, A1, T1, A2, T2, ...] (TITO 累积的完整序列)
output_ids = A1_model_output (SGLang 实际输出的 token)
Step 1: cursor = len(prompt_ids) → 定位到当前轮 assistant 开始位置
Step 2: 贪婪匹配 output_ids[j] == accumulated[cursor + j]
Step 3: 不匹配的 trailing token = trim_count → 从 sample 中裁剪
Step 4: cursor += matched → 指向下一轮起始
Step 5: 验证 cursor == len(accumulated) → 整个序列被完整消费
核心思路是:用 TITO 累积的完整序列作为"ground truth",将 SGLang 实际输出的 token 序列与之对齐,裁剪掉被下一轮模板"消费"掉的尾部 token。第五步的验证是关键——如果 cursor 不等于 accumulated 长度,说明对齐失败,框架会抛出异常而非静默产生错误数据。
1.4.2 两种 Sample 模式:合并 vs 独立
不同的 RL 算法对训练数据的粒度有不同需求。agentic_tool_call 提供两种模式:
| 模式 | 说明 | 适用场景 |
|---|---|---|
merge_samples(默认) |
多轮合并为一个 Sample | 标准 GRPO/PPO——整个 trajectory 一个 reward |
generate_multi_samples |
每轮独立 Sample | 需要 per-turn reward 的场景(如 PRM 逐轮打分) |
选择合并模式时,所有轮次的 token 拼接为一个完整序列,loss mask 正确标记了每一段 assistant 回复的位置。选择独立模式时,每一轮产出独立的 Sample,可以分别打分、分别计算 advantage。框架处理所有拼接和对齐细节,Agent 开发者只需在配置中切换模式。
1.4.3 五层异常处理:不让任何一个 Agent 失败阻塞训练
Agentic RL 训练中,Agent 执行失败是常态而非异常——工具调用超时、模型生成格式错误、网络抖动,任何一个都可能导致单次 Agent 执行失败。如果每次失败都让训练崩溃,Agentic RL 根本无法实用化。
agentic_tool_call 实现了五层递进的异常处理:
| 层 | 异常类型 | 处理方式 |
|---|---|---|
| Agent 异常 | 用户函数内任意 Exception | sample.status = ABORTED,返回空 records |
| 空 records | Agent 未调用任何模型 | 返回单个 ABORTED sample |
| 超长序列 | tokens 超过 max_seq_len |
truncate_samples_by_total_tokens() |
| 全部截断 | prompt 本身就超过 max_seq_len |
返回 ABORTED |
| Session 收集超时 | asyncio.TimeoutError |
返回空 records + 清理 session |
核心原则:任何一层失败都优雅降级为 ABORTED 状态,不抛异常到训练循环。ABORTED 样本在后续的 data filter 中被自动丢弃或 loss_mask 置零——训练继续,不受单次 Agent 失败影响。这使得 Agentic RL 训练可以像普通 RL 训练一样稳定运行,即使 Agent 的失败率在高难任务上可能达到 30-50%。
1.5 有框架 vs 无框架
将上文所有自动化的维度汇总在一起,有无 agentic_tool_call 的差异是数量级的:
| 维度 | 无 agentic_tool_call | 有 agentic_tool_call |
|---|---|---|
| Agent 开发 | 需了解 Miles 内部 token 格式 | 像写普通 Agent(OpenAI API 风格) |
| Session 管理 | 手动创建/销毁 | 自动 |
| Token 对齐 | 手动实现 TITO 逻辑 | 自动(含 trailing token trim) |
| Loss Mask | 手动计算边界 | 自动 |
| 异常处理 | 自行处理(失败=训练崩溃) | 自动降级为 ABORTED |
| 新 Agent 开发成本 | 数百行 boilerplate | 只写业务逻辑 |
1.6 总结
agentic_tool_call 的本质是一个适配器模式——它将"Agent 多轮交互"(业务关注点)与"RL 训练数据生产"(基础设施关注点)完全解耦。
这条解耦线画在了 generate() 函数上。线以上是 Agent 开发者的世界——OpenAI API、工具调用、业务逻辑。线以下是 RL 基础设施的世界——Session Server、TITO、token 对齐、loss mask、异常降级。Agent 开发者不需要知道线以下的存在,框架也不需要知道 Agent 在做什么业务。这正是好的抽象应该达到的效果。
0x02 TITO
TITO (Token-In, Token-Out) 是多轮 Agent RL 的 Tokenization 一致性基础设施
在多轮 Agent RL 中,每轮对话后的"重新 tokenize"是一个隐形的训练杀手——它让前缀漂移、log prob 发散、loss mask 错位,最终导致梯度崩溃。本节从 Chat Template 的 loop.last 问题出发,拆解 TITO 增量 tokenization 的完整设计,说明 Miles 如何通过三道防线根治这个问题。
2.1 问题:多轮 Agent RL 中的 Tokenization 漂移
在 Agentic RL 中, 每轮对话需要精确的 token 级 log prob 用于 policy gradient 计算。传统方法对完整对话重新 tokenize 会因 BPE 合并边界变化导致 token 序列不一致, 进而破坏 token↔logprob 的 1:1 对应关系。
没有 TITO, 多轮 RL 的 reward 归因完全失效。这是 Miles 区别于所有竞品的基础前提。
2.1.1 一个具体的场景
假设一个 Agent 正在执行多轮工具调用。第 1 轮,它收到用户请求后生成了一个 tool call;第 2 轮,工具返回结果,Agent 需要继续生成。
在标准做法中,每轮对话结束时,框架会把完整的消息历史(system + user + assistant + tool + …)作为一个整体,调用 tokenizer.apply_chat_template() 重新渲染并 tokenize。
# 第 1 轮: 3 条消息
messages = [system, user, assistant]
tokens_A = tokenizer.apply_chat_template(messages) # 1000 个 token
# 第 2 轮: 4 条消息 (加了 tool)
messages = [system, user, assistant, tool]
tokens_B = tokenizer.apply_chat_template(messages) # 重新 tokenize 全部
问题:tokens_B 的前 1000 个 token 不等于 tokens_A。
为什么会这样?答案藏在 HuggingFace 的 Chat Template 机制里。
2.1.2 根因:Chat Template 中的 loop.last
HuggingFace 模型的 chat template 是一个 Jinja2 模板,它将 messages 列表渲染为模型能理解的文本(带 <|im_start|> / <|im_end|> 等特殊 token)。在这个渲染过程中,模板经常使用 loop.last 来判断"当前消息是不是最后一条",然后决定是否追加某个结束符。
以 Qwen3 的原始模板为例,tool 消息的渲染逻辑大致如下:
{%- elif message.role == "tool" %}
{%- if loop.first or (messages[loop.index0 - 1].role != "tool") %}
{{- '<|im_start|>user' }}
{%- endif %}
{{- '\n<tool_response>\n' + content + '\n</tool_response>' }}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }} ← 只在"最后一条"时加结束符
{%- endif %}
{%- endfor %}
让我们追踪两次渲染之间的差异:
第 2 轮结束时(tool 是最后一条消息):
messages = [..., tool_msg] ← loop.last = True
渲染结果: ...<|im_end|>\n ← 加了结束符
第 3 轮开始时(tool 后面又加了 assistant):
messages = [..., tool_msg, assistant_msg]
← loop.last = False 了!
渲染结果: ... ← 没有 <|im_end|>\n 了!
前缀不再一致。第 2 轮的 token 序列包含 <|im_end|> token,第 3 轮却没有——TITO 的 pretokenized prefix 复用完全失效。
2.1.3 后果:从性能浪费到训练崩溃
这不仅是"多算了几次 tokenization"的问题。我们逐层来看:
第一层:性能浪费。 不能复用 prefix 意味着每轮都要对整个历史重新 tokenize。10 轮对话 × 32K 上下文,计算开销从 O(N) 变成 O(N²)。
第二层:Log Probability 发散。 第 2 轮推理时,位置 100 是 <|im_end|> token,模型给它算出了 log_prob = -0.01。第 3 轮重算时,位置 100 的 token 变了——<|im_end|> 不存在了,被下一个 token 替代。同一位置、不同 log prob → importance ratio ≠ 1.0 → 虚假的策略梯度。
第三层:Loss Mask 错位。 训练时需要精确标记"哪些 token 是模型生成的(需要计算 loss)、哪些是环境返回的(不需要)"。一旦 token 序列漂移,loss mask 的边界就错位了——可能把 tool response 的 token 也纳入 loss 计算,让模型被迫预测工具输出。训练信号被污染。
第四层:梯度崩溃。 每轮的微小偏移 × 多轮对话 × 大 batch × 数千训练步 → 策略梯度持续偏差 → reward hacking 或 loss 不降反升 → 最终训练 collapse。
2.2 TITO:增量 Tokenization 的原理
2.2.1 核心思想
TITO(Token-Incremental Tokenization for pretokenized prefix reuse)的核心思路只有一句话:只 tokenize 新增部分,复用已有前缀的 token IDs, 保证多轮对话 token 前缀严格一致。
多轮 Agent 交互中,token 只有两个来源:
- 环境/用户输入(tool/user/system 消息):需要 TITO 增量 tokenize
- 模型输出(assistant 消息):SGLang 生成时直接产出 token IDs 和 logprobs——它们在生成瞬间就是确定的,不应、也不能重新 tokenize
因此,TITO 的做法是:
- 只 tokenize 非 assistant 消息 (tool/user/system)
- Assistant tokens 直接从 SGLang engine 获取, 已天然绑定 logprobs
- 保证整个对话的 token 前缀在多轮追加时位级一致
具体如下:
第 1 轮: [system] [user] [assistant]
├─ 完整 render + tokenize → token_ids_1 (checkpoint)
第 2 轮: [system] [user] [assistant] [tool_1]
├─ 复用 checkpoint: token_ids_1
└─ 只 tokenize [tool_1] → incremental → token_ids_1 + incremental
第 3 轮: [system] [user] [assistant] [tool_1] [assistant] [tool_2]
├─ 复用 checkpoint: token_ids_2
└─ 只 tokenize [tool_2] → incremental → token_ids_2 + incremental
关键保证:每轮只向前追加,永远不重新 tokenize 已有消息。这就是"append-only 不变量"。
2.3 三道防线:Miles 的工程化方案
理解了问题本质后,我们来看看 Miles 如何系统性地解决它。
2.3.1 防线一:修复模板(根治)
修复的核心思路是:将判断条件从 loop.last(“当前是不是最后一条”)替换为基于下一条消息角色的判断:
{# 修复后 - 用"下一条消息"判断代替 loop.last #}
{%- if loop.last or (messages[loop.index0 + 1].role != "tool") %}
{{- '<|im_end|>\n' }}
{%- endif %}
这确保了:当 tool 是最后一条时依然追加结束符,因为下一轮 assistant 的起始标记会自然衔接。关键原则是 append-only 不变量:渲染 messages[0:N] 的结果必须是渲染 messages[0:N+1] 结果的严格前缀。
模型特定适配
不同模型的 chat template 有不同的边界行为。TITO 通过子类化 + 固定模板解决,Miles 为每个有问题的模型提供了 *_fixed.jinja 模板:
| 模型 | TITO 子类 | 边界处理 |
|---|---|---|
| Qwen3 | Qwen3TITOTokenizer |
<|im_end|> 后补 \n |
| Qwen3.5/3.6 | Qwen35TITOTokenizer |
同 Qwen3,使用不同的固定 jinja |
| GLM 4.7 | GLM47TITOTokenizer |
<|user|> 和 <|observation|> 歧义边界 token |
| Kimi K2.5/K2.6 | Kimi25TITOTokenizer / Kimi26TITOTokenizer |
<|im_end|> 无 trailing newline |
| MiniMax M2.5/M2.7 | MinimaxM25TITOTokenizer / MinimaxM27TITOTokenizer |
[e~[ + \n 边界处理 |
| Nemotron 3 | Nemotron3TITOTokenizer |
同 Qwen3 模式 |
工厂函数 get_tito_tokenizer() 根据 --tito-model 参数自动选择对应子类。
以 Qwen3 为例,模型实际生成时停在 <|im_end|> 而不生成紧随其后的 \n,但 chat template 渲染时又包含了这个 \n。TITO 的 merge_tokens 方法需要补回这个缺失的换行符:
def merge_tokens(self, ...):
incremental = self.tokenize_additional_non_assistant(...)
prefix = list(pretokenized_token_ids)
if prefix and prefix[-1] == self._im_end_id:
prefix.append(self._newline_id) # 补回缺失的换行符
return prefix + incremental
实现要点
代码实现上,tokenize_additional_non_assistant() 方法将新增消息按 segment 分组(连续 tool 为一组,user/system 单独一组),每组用最小合成上下文渲染后 tokenize,最后追加 generation prompt。
miles/utils/chat_template_utils/
├── tito_tokenizer.py # 增量 tokenizer 核心
├── __init__.py # 对外导出 TITO 接口
└── (由 session/linear_trajectory.py 调用)
传统做法 vs TITO:
传统做法:每轮对全部 N 条消息重新 tokenize → O(N²) 且前缀不稳定
TITO 做法:只 tokenize 第 N 轮新增消息 → O(N) 且前缀 100% 稳定
2.3.2 防线二:自动验证工具(检测)
Miles 提供了 CLI 验证脚本,在引入新模型时自动化检测模板是否为 append-only:
python scripts/tools/verify_chat_template.py --model Qwen/Qwen3-0.6B
# 输出:
# [FAIL] single_tool-N3 Prefix mismatch
# [FAIL] multi_turn-N4 Prefix mismatch
# Verdict: FAIL - template is NOT append-only
2.3.3 防线三:运行时断言(兜底)
在 LinearTrajectory.prepare_pretokenized() 中,每次 TITO 操作后都会做运行时校验:
def _tokenize_rendered_suffix(base_messages, appended_messages):
text_without = render(base_messages)
text_with = render(base_messages + appended_messages)
if not text_with.startswith(text_without):
raise ValueError("rendered suffix diff failed") # 运行时报错
如果修复模板和验证工具都没拦住某个边界情况,运行时断言会在训练开始前直接报错——阻止坏数据进入训练循环,而不是让训练在若干步后静默崩溃。
2.4 为什么这很重要:loss_mask 与训练正确性
前面的讨论聚焦于"怎么让 token 序列保持稳定"。现在我们来回答更深层的问题:为什么 token 序列的稳定性对 RL 训练如此关键?
答案在于 loss_mask——Agentic RL 中最关键的标记机制之一。
2.4.2 什么是 loss_mask
在多轮 Agent 对话中,不是所有 token 都应由模型负责。对话是由"模型生成"和"环境返回"交替组成的:
[system] [user] [assistant₁] [tool_result] [assistant₂]
↑ ↑ ↑ ↑ ↑
mask=0 mask=0 mask=1 mask=0 mask=1
(训练) (训练)
loss_mask 是一个与 token 序列等长的 0/1 列表,标记每个位置是否参与梯度计算:
| 消息角色 | loss_mask | 原因 |
|---|---|---|
| system | 0 | 系统提示,非模型生成 |
| user | 0 | 用户输入,非模型生成 |
| tool(环境返回) | 0 | 环境返回,非模型生成 |
| assistant(response 部分) | 1 | 模型生成的回答 |
| assistant(generation prompt token) | 0 | Chat template 自动添加的边界 token |
训练时的总 loss 计算为:
总 loss = Σ(loss_mask[t] × loss[t]) / Σ(loss_mask[t])
只除以 mask=1 的 token 数量(token-mean 归一化),确保 loss 量级不受对话长度影响。
2.4.2 为什么 loss_mask 必须精确
回到第一节的问题:如果 token 序列因 loop.last 漂移了,loss_mask 会怎样?
推理时,模型在第 2 轮生成了 assistant 回复,对应 token 位置 [800:1200],loss_mask 标记为 1。但训练时,由于前缀漂移,[800:1200] 可能对应的是 tool response 的 token。你把 tool response 的 token 标记为 1 去训练 → 模型被迫学习"如何生成工具返回值"→ 完全错误的训练信号。
在 Miles 的实现中,loss_mask 的构建严格遵循消息的 role:
# 模型生成 token → mask=1
sample.loss_mask += [1] * len(new_response_tokens)
# 环境观察/工具输出 token → mask=0
sample.loss_mask += [0] * len(next_obs_tokens_ids)
# 多轮合并时保持 mask 语义
loss_mask = a.loss_mask + [0] * obs_len + b.loss_mask
正是 TITO 的 append-only 不变量,保证了每次追加的 mask 不会影响已有 mask——新 token 总是在旧序列末尾追加,loss_mask 也随之递增。
2.5 总结
多轮 Agent RL 的 tokenization 一致性是一个容易被低估的问题——表面上只是"多算了几次 tokenize",但根因链是:Jinja loop.last → Chat Template 违反 append-only 不变量 → token 序列漂移 → log prob 发散 → loss mask 错位 → 梯度崩溃。
Miles 的解决方案分三层:
| 层 | 机制 | 作用 |
|---|---|---|
| 算法层 | TITO 增量 tokenization | 保证每轮只向前追加,prefix 100% 稳定 |
| 工程层 | Session Server | 透明管理多轮状态,暴露 OpenAI 兼容 API,自动追踪训练数据 |
| 质量层 | 三道防线(修复模板 + 验证工具 + 运行时断言) | 预防 → 检测 → 兜底,确保坏数据不进入训练循环 |
而整个方案的正确性最终在 loss_mask 上体现——只有 token 序列绝对稳定,loss_mask 才能精确区分"模型该学的"和"环境产生的",训练梯度才不是噪声。
0x03 Session Server:TITO 的产品化外壳
TITO 解决了 tokenization 一致性问题,但在实际 Agent RL 训练中,还需要一个完整的服务层来管理多轮对话的状态、暴露标准 API、追踪训练数据。这就是 Session Server。Session Server 的核心价值: 有状态多轮 Agent session 管理, 不牺牲并发。
Session Server 是 Miles的核心功能(位于 miles/rollout/session/ 和 miles/utils/chat_template_utils/)。Miles 在此基础上增加了:
agentic_tool_call.py—— 通用 Agent 函数框架- Chat Template 自动验证 + autofix
- 更多模型的 TITO 适配(GLM、Qwen3.5 等)
3.1 定位
Session Server 是一个独立的 FastAPI 进程,位于 Agent 代码和 SGLang Router 之间:
Agent (用户代码)
│ POST /sessions/{id}/v1/chat/completions
▼
Session Server (FastAPI)
│ 1. 管理 LinearTrajectory 状态机
│ 2. TITO 增量 tokenization
│ 3. 代理请求到 SGLang Router
▼
SGLang / Miles Router (负载均衡)
│
▼
SGLang Engine (GPU)
Agent 代码只需像调用标准 OpenAI API 一样发起请求——底层的 TITO、状态管理、prefix 复用全部由 Session Server 透明完成。
3.2 核心组件
SessionRegistry:session ID →LinearTrajectory的字典映射,管理所有活跃会话LinearTrajectory:保存每轮的消息历史 + token checkpoint,支持单步回滚(Agent 重试时回退到上一 checkpoint)- 3-phase lock:prepare(持锁快)→ SGLang 推理(释锁慢)→ update(持锁快)。推理期间释锁的设计让同一个 session 的其他请求不会被阻塞
OpenAIEndpointTracer:记录每轮的 token/logprob → 训练时构建精确的 loss mask
3.3 Session 生命周期
# 1. 创建 Session
tracer = await OpenAIEndpointTracer.create(args)
# → POST /sessions → 返回 session_id
# 2. Agent 多轮调用(每轮自动 TITO)
response = await chat_completion(messages=[...])
# → Session Server 验证 append-only
# → TITO 只 tokenize 新增部分
# → 复用 pretokenized prefix 发给 SGLang
# → 记录 SessionRecord (token_ids, logprobs)
# 3. 收集训练数据
records = await tracer.collect_records()
# → 返回所有轮次的精确 token 边界 + logprobs
# → 转换为训练 Sample
# 4. 清理
# → DELETE /sessions/{id}
一致性验证
除了运行时的 append-only 断言,Session Server 在获取 session 时还会做 tokenization 一致性校验:
def compute_session_mismatch(self, session):
# 对比 accumulated_token_ids 与 canonical chat template 输出的差异
expected_ids = self.tito_tokenizer.render_messages(session.messages, ...)
mismatches = self.comparator.compare_sequences(expected_ids, session.token_ids)
在 CI 测试中,对 tito_session_mismatch_rate 做严格断言——三种类型的 mismatch(special_token_count、special_token_type、non_assistant_text)必须为 0:
if args.ci_test:
for strict_type in ("special_token_count", "special_token_type", "non_assistant_text"):
rate = log_dict.get(f"tito_session_mismatch_rate/{strict_type}", 0)
assert rate == 0
3-Phase Lock 设计
3-Phase Lock 设计的优势在于 :
- 支持任意长度的 tool-call 链 (10+ turns)
- 永远不在高延迟操作期间持锁 → 并发度与 session 数无关
- 乐观锁语义: 如果 Phase 3 发现状态被篡改 → 重试
Phase 1: LOCK → prepare tokens (TITO tokenize) [µs 级]
Phase 2: UNLOCK → proxy to engine (model inference) [100ms-10s]
Phase 3: LOCK → validate state unchanged → commit [µs 级]
3.4 有无 Session Server 的对比
| 无 Session Server | 有 Session Server | |
|---|---|---|
| 每轮 tokenize | 重新 tokenize 全部历史 (O(N²)) | TITO 增量 (O(N)) |
| Prefix 复用 | 无法保证前缀一致 | 精确复用 |
| 状态管理 | Agent 自己管理 | 框架自动管理 |
| API 兼容 | 自定义接口 | OpenAI 格式 |
| Log prob 追踪 | 手动实现 | 自动 SessionRecord |
| 训练数据生成 | 手动拼接 | compute_samples_from_openai_records |
| 重试支持 | 丢弃重来 | 自动回滚到上个 checkpoint |
0x04 训推一致性频谱:从全异步到比特级一致的逐层递进
RL 训练中,策略梯度公式要求"生成样本的策略 = 计算梯度的策略"。但在异步架构下,rollout 和 training 天然存在时间差——样本生成时的模型权重可能已经落后训练时的权重好几个版本。这种 off-policy 偏差在 Agentic RL 中尤其严重(单次 rollout 可能持续几分钟)。Miles 提供了一条从"全异步(高吞吐)"到"True On-Policy(比特级一致)"的完整频谱,允许在不同场景下精准取舍。
4.1 问题的起点:为什么需要异步?
4.1.1 同步 RL 的"空转等待"
在传统同步 RL 训练中,每个 iteration 的 wall time 是 rollout 时间和 training 时间的简单相加:wall_time = rollout_time + train_time。对单轮数学题这种简单场景,rollout 约 10s,训练约 8s——GPU 有 44% 的时间在空转。这已经不算高效了。
但 Agentic RL 的场景要糟糕得多。我们看几个真实场景的对比:
| 场景 | Rollout 时间 | 训练时间 | GPU 空闲率 |
|---|---|---|---|
| 单轮数学 | 10s | 8s | 44% |
| 多轮工具调用 | 60s | 8s | 88% |
| SWE-Agent 代码修复 | 120s | 8s | 94% |
对于 SWE-Agent,94% 的时间训练 GPU 在等待 rollout 完成。这不仅是浪费,还会引入新问题——等待越久,先完成的样本就越"过期",与当前权重版本的距离就越远。
4.1.2 全异步架构:让 rollout 和 training 重叠
解决思路很直接:让 rollout 和 training 并行。
同步模式: |--rollout 60s--|--train 8s--|--rollout 60s--|--train 8s--|
wall_time = 136s for 2 iterations
全异步模式: |--rollout---------rollout----------rollout--------rollout---------|
| |--train--|--train--|--train--|--train--|
wall_time ≈ max(rollout_total, train_total) ≈ 68s for 2 iterations
Slime 用三大组件完全解耦(Training ↔ Data Buffer ↔ Rollout 完全物理隔离)来支持这一点:
- Training (Megatron):从 Data Buffer 读取数据训练,训练后异步同步权重
- Rollout (SGLang + Router):持续生成新数据(含 reward),存入 Data Buffer
- Data Buffer:桥接模块,管理 prompt 队列和 rollout 生成
具体如下:
核心实现是 train_async.py 中的流水线重叠——当前轮 rollout 还没结束时,已经提前启动下一轮:
# 提前启动下一轮 rollout,与当前轮训练重叠
if rollout_id + 1 < args.num_rollout:
rollout_data_next_future = rollout_manager.generate.remote(rollout_id + 1)
Miles 在此基础上进一步提供了 AsyncRolloutWorker 参考模式(位于 examples/):独立线程 + asyncio event loop、有界队列(maxsize=1000,防止 OOM)、以及 staleness 过滤机制。
另外,Miles 也通过“Semaphore + FIRST_COMPLETED 有界并发”来保证精确匹配 engine 容量的并发控制,既不过载也不闲置(max_concurrency = sglang_server_concurrency × rollout_num_gpus // rollout_num_gpus_per_engine)。这是因为静态 batch size 要么过大 (OOM / 超时) 要么过小 (GPU 闲置),而Semaphore + FIRST_COMPLETED 可以实现 “水位线” 式动态调度,配合 abort 策略: batch 达标后主动中止多余请求。
# inference_rollout_train.py:90-104
pendings: set[asyncio.Task] = set()
while not batch_complete:
done, pendings = await asyncio.wait(pendings, return_when=FIRST_COMPLETED)
# 处理完成的任务, 立即释放 semaphore 槽位给新任务
4.1.3 异步的代价:Staleness
异步解决了吞吐问题,但引入了一个根本性的新问题:off-policy 偏差。
策略梯度公式要求:
∇J(θ) = E_{τ~π_θ} [∇log π_θ(a|s) · A(s,a)]
↑ ↑
rollout 用的 θ training 用的 θ
在同步模式下,两者是同一个 θ。在全异步模式下,rollout 和 training 各自独立推进——当训练还在计算当前 batch 的梯度时,新的 rollout 已经在用更新后的权重生成了。
这在 Agentic RL 中尤其严重。一个 SWE-Agent 的 rollout 可能持续 60-600 秒,在此期间模型可能已更新 3-10 步。Rollout 开始时使用的权重版本(V_rollout)与训练时使用的权重版本(V_train)可能相差多个版本——从 V_rollout 采集的 log prob 对 V_train 来说已经是完全 off-policy 的了。
那么,如何对抗这种 staleness?Miles 给出的答案不是单一方案,而是一条从宽到严的完整频谱。
4.2 解决方案频谱:从宽松到严格
整个频谱可以这样理解:

这不是互斥的选项——它们可以组合使用。Miles 的设计哲学是:根据场景在正确的位置投入正确的成本。接下来我们逐层拆解。
4.3 Layer 1:Staleness 过滤(调度层)
4.3.1 原理
每个样本在生成时记录当前的模型权重版本号。训练时检查:如果 staleness(当前版本 - 样本生成版本)超过阈值,就回收该样本:
# 每个样本记录生成时的模型权重版本号
sample.oldest_weight_version = engine_weight_version_at_generation_time
# 训练时检查
staleness = current_engine_version - oldest_weight_version
if staleness > max_weight_staleness:
recycle(sample) # 回收, 不用于训练
4.3.2 为什么是"回收"而非"丢弃"?
直接丢弃会浪费 prompt。Miles 的做法是:将样本放回队列,用新权重重新生成 response——prompt 不浪费,只是重新跑一次推理。
for s in group:
s.reset_for_retry()
data_buffer.add_samples([group]) # 放回队列, 用新权重重新生成
4.3.3 阈值选择
max_weight_staleness |
效果 | 适用场景 |
|---|---|---|
| 0 | 严格 on-policy,等同同步模式(无加速) | 研究对照实验 |
| 1 | 允许滞后 1 个版本 | 通常够用,兼顾吞吐和新鲜度 |
| 2-3 | 允许更大滞后 | Agentic 场景(长 rollout) |
| ∞ | 纯吞吐优先 | 初期调试,不推荐生产使用 |
4.3.4 同步权重广播 + 版本锁
核心价值: 训练→推理权重原子更新,确保没有 stale engine 参与 rollout
更新流程如下:
1. Pause all SGLang engines [lock 外]
2. Flush KV-cache [lock 外]
3. Acquire Ray Lock Actor [lock 内开始]
4. NCCL broadcast 新权重 [lock 内]
5. Release Ray Lock Actor [lock 内结束]
6. Resume engines [lock 外]
7. Version assertion check [lock 外]
为何关键?
- Ray Lock Actor 防止多 TP/PP group 的 NCCL 死锁
- 版本号检查 (
if version != expected: raise RuntimeError) 硬保证没有过期引擎 - Pause/Resume 在锁外执行 → 减少锁持有时间
4.4 Layer 2:TIS/MIS(算法层)
Staleness 过滤解决了"权重版本差距太大"的问题,但残余的 off-policy bias 仍然存在——即使 staleness=1,rollout 和 training 用的也不是完全相同的权重。TIS(Truncated Importance Sampling)和 MIS(Masked Importance Sampling)在算法层面对此进行补偿。
4.4.1 原理
核心思路是用重要性采样权重(IS weight)修正策略梯度:weight = min (clip_ratio, π_train (a|s) / π_rollout (a|s)):
tis = torch.exp(old_log_probs - rollout_log_probs) # IS weight
# 对重要性比率设置上限 C,当比率超过 C 时截断为 C,从而控制方差。
tis_weights = torch.clamp(tis, min=tis_clip_low, max=tis_clip) # 截断防止方差爆炸
pg_loss = pg_loss * tis_weights # 修正 policy gradient
截断的原因:当 rollout 和 training 策略差异太大时,IS weight 可能变得极大(>100 或 <0.01),直接使用会导致梯度方差爆炸。截断牺牲了理论无偏性,换取了训练稳定性。
4.4.2 ICEPOP 变体
ICEPOP(icepop_function)采用了更激进的策略——不在范围内的 IS weight 直接置 0(hard mask),而非 clamp。这相当于告诉训练器:“这个样本的策略已经和当前策略差异太大,完全不可信,直接跳过。”
4.5 Layer 3:R3 路由重放(MoE 模型专属)
前两层解决的是"权重版本不同"导致的 off-policy 问题。但即使权重版本完全相同,MoE 模型还有一个特有的训推不一致来源:路由翻转。
4.5.1 MoE 路由的致命问题
MoE 模型中,每个 token 由路由器选择 top-k 个专家进行处理。即使模型权重完全相同,推理(SGLang)和训练(Megatron)时的路由结果也可能不同。原因包括:
- FP8 量化的微小精度差异
- 不同 GEMM kernel 的浮点舍入路径
- 不同 batch 组装导致的 load-balancing 计算偏移
这导致的后果是:训练时 token 被分发到与推理时不同的 expert,前向 log prob 计算和反向梯度路径都是错的。对于数百层 × 数万 token × 数千步的训练,这种偏差会累积成策略发散甚至训练崩溃。
4.5.2 R3 的工作原理
R3(Rollout Routing Replay)的核心思路是:推理时记录路由决策,训练时直接重放,不重新计算路由。
三步工作流:
- 推理时记录:SGLang 推理时设置
enable_return_routed_experts=True,将每层的 top-k expert indices 记录到Sample.rollout_routed_experts - 训练时回放:通过 hook 注册到每个 MoE 层的
topk_fn,用记录的路由替代实时计算(强制回放相同的 routing, 绕过 router 网络) - 四阶段状态机:
fallthrough(正常路由)→record(记录训练引擎自己的路由,用于 CI 对比)→replay_forward(重放推理路由,计算 log prob)→replay_backward(重放推理路由,计算梯度)
代价是每个 sample 增加的 routed_experts 数据约 ~60MB(取决于层数和 top-k)。
4.5.3 何时需要 R3
| 需要 R3 | 不需要 R3 |
|---|---|
| MoE 模型(DeepSeek V3, Qwen3-MoE, GLM-4.7) | Dense 模型(Qwen3-4B, Llama) |
--advantage-estimator grpo |
已使用 --use-tis(TIS 可 mask off-policy 影响) |
| FP8 推理 + BF16 训练 | True On-Policy 模式(已对齐所有算子) |
R3 最初在 Slime 项目中实现(PR #566,由 SGLang RL Team 贡献),Miles 完整继承了此功能,并在其基础上增加了统一 FP8 pipeline(进一步减少路由翻转的根因)和更完善的 MoE 测试套件。
4.6 Layer 4:True On-Policy(系统层)
On-policy RL 要求 policy gradient 基于当前策略生成的 trajectories 计算。
目前,前三层分别对抗权重漂移(Staleness Filter)、残余偏差(TIS)和路由翻转(R3)。但它们都有一个共同的前提假设:如果权重完全一致,推理和训练的 log prob 就相同。
这个假设在现实中并不成立。
4.6.1 同一权重下的系统误差
即使模型权重比特级相同,以下因素仍会导致推理和训练产生不同的 log prob:
| 不一致来源 | 推理(SGLang) | 训练(Megatron) |
|---|---|---|
| Attention 实现 | FA2/FlashInfer | Megatron 自带 Attention |
| 精度 | FP8 | BF16 |
| RoPE | fused kernel | unfused Python |
| SwiGLU | fused bias+activation | unfused |
| Batch 大小 | 动态(continuous batch) | 固定 micro-batch |
| TP allreduce 顺序 | 不确定性 | 不确定性 |
这些微小差异在 RL 中会被放大:
importance_ratio = exp(log π_new - log π_old)
↑ 如果这里引入了系统噪声
ratio 就不是 1.0
→ 产生虚假梯度
4.6.2 True On-Policy 契约系统
Miles 的解决方案是一个声明式契约系统——通过契约强制推理和训练使用完全相同的计算路径,使 log prob 达到比特级一致,消除 off-policy bias。
三层抽象如下:
TrueOnPolicyModelProfile:描述模型的 True-On-Policy 能力(支持哪些训练后端、哪些 CP 布局等)TrueOnPolicyContract:定义达成比特级一致所需的策略(attention backend、是否禁用 RoPE fusion、是否 batch-invariant 等)TrueOnPolicyKernelPolicy:将契约参数转化为实际的 CLI 参数和环境变量
QWEN3_DENSE_TRUE_ON_POLICY_V1_SCHEMA = TrueOnPolicyContractSchema(
name="qwen3_dense_true_on_policy_v1",
model_family="qwen3_dense",
required_kernel_contracts=("qwen3_dense_sglang_math",),
logprob_contract="sglang_prefill", # 训练侧用 SGLang 的 prefill 计算 logprob
sglang_attention_backend="fa3", # 两侧都用 FA3
fsdp_attention_implementation="flash_attention_3",
disable_megatron_sequence_parallel=True, # 禁用可能引入不确定性的优化
)
契约系统在环境变量层面还强制了确定性通信和算子:
NCCL_ALGO="Ring" # 确定性通信
NVTE_ALLOW_NONDETERMINISTIC_ALGO=0 # 禁止非确定性 CUDA 算子
CUBLAS_WORKSPACE_CONFIG=":4096:8" # cuBLAS 确定性
结果:当 True On-Policy 生效时,train_rollout_logprob_abs_diff = 0。
4.6.3 代价与范围
| 获得 | 付出 |
|---|---|
| 零 importance ratio 偏差 | 禁用多项 fused kernel → 推理吞吐下降 |
| 训练完全稳定 | 仅支持 dense 模型(当前 Qwen3 dense) |
| 无需 TIS 修正 | 需禁用 Megatron sequence parallel 等优化 |
范围约束:True On-Policy 模式主要面向受支持的 dense 模型合约(如 QWEN3_DENSE_TRUE_ON_POLICY_V1)。MoE 模型依赖 R3 + FP8 统一 + TIS 的组合方案。
4.7 全景:四层互补,按场景组合
以上四层解决的是三个不同维度的不一致问题,互不替代、可以叠加:
Layer 1: Staleness Filter (调度层)
确保: 样本生成时的 θ 不会落后训练时的 θ 太远
→ 消除"权重版本漂移"
Layer 2: TIS/MIS (算法层)
确保: 残余的 off-policy bias 被重要性采样修正
→ 补偿"同一权重版本内的分布偏移"
Layer 3: R3 (MoE 专属层)
确保: MoE 路由在推理和训练时 token 到 expert 的映射完全一致
→ 消除"路由翻转"
Layer 4: True On-Policy (系统层)
确保: 同一个 θ 下, SGLang 和 Megatron 的 log_prob 比特级一致
→ 消除"系统噪声"
其中 Layer 1 和 Layer 2 互补性最强——Staleness Filter 在调度层丢弃过旧的样本(治标),TIS 在算法层修正残余偏差(治本)。两者通常组合使用,这也是为什么前面场景推荐中它们经常一起出现。
4.7.1 场景推荐
| 场景 | 推荐组合 | 理由 |
|---|---|---|
| 同步 + 小模型 | True On-Policy | 最严格,可承受性能损失 |
| 全异步 + 中模型 | Staleness=1 + TIS | 吞吐与精度的平衡点 |
| 全异步 + MoE 大模型 | Staleness=2 + R3 + FP8 统一 | MoE 路由一致性是硬需求 |
| 超长 Agentic rollout | Staleness=3 + MIS + 部分 on-policy | 长 rollout 天然 off-policy,多层补偿 |
4.7.2 为什么不总用 True On-Policy?
| 代价 | 说明 |
|---|---|
| 性能损失 | 禁用了多项 fused kernel 优化, rollout 变慢 |
| 兼容性受限 | 目前只支持 Qwen3 dense |
| 无法完全异步 | 比特一致要求权重完全同步 |
| 不支持所有并行策略 | 需禁用 Megatron sequence parallel |
这就是为什么 Miles 提供频谱式选择——不需要极致精确时用 TIS 修正即可(保留 fused kernel 性能),需要最高质量时启用 True On-Policy 契约。
4.8 总结
训推一致性不是一个"有或无"的问题,而是一个"在哪个层级投入多少成本"的工程决策。Miles 的频谱式方案让团队可以根据模型类型(Dense/MoE)、场景要求(同步/异步/Agentic)和资源预算,精准选择组合策略。
| 层 | 机制 | 解决什么问题 | 适用条件 |
|---|---|---|---|
| 调度层 | Staleness Filter | 权重版本差距太大 | 所有异步场景 |
| 算法层 | TIS/MIS | 残余 off-policy bias | 无法或不愿启用 True On-Policy |
| MoE 层 | R3 路由重放 | MoE 路由翻转 | MoE 模型专属 |
| 系统层 | True On-Policy 契约 | 同一权重下的系统误差 | Dense 模型,追求最高质量 |
核心洞察:True On-Policy 解决"同一权重下的系统误差"(精确度),Staleness Filter 解决"不同权重间的策略漂移"(新鲜度),两者正交。Miles 允许根据场景灵活组合,而不是强制所有场景一律使用最严格的方案。
0x05 Multi-Agent 协同训练:从共享模型的角色分工到跨集群的异步协同进化
单 Agent RL 有一个根本局限:一个模型既要"思考"又要"验证",容易自我欺骗,也无法利用分工协作提升复杂任务的表现。Miles 提供了两条递进的 Multi-Agent 路径——轻量级的"共享模型 + 角色分工"流水线,以及生产级的 MrlX 异步协同进化框架。本文从单 Agent 的困境出发,逐步展开两条路径的设计原理和适用场景。
5.1 单 Agent 的局限:为什么需要 Multi-Agent
在深入 Multi-Agent 之前,我们先明确问题:单 Agent RL 到底卡在哪里?
- 自我欺骗:一个模型同时充当"解题者"和"验证者"——它需要自己判断自己的答案是否正确。没有外部视角的验证,模型很容易形成自我强化的错误回路。
- 无法利用分工:复杂任务(如医疗诊断 + 患者对话、深度研究 + 事实核查)天然需要不同角色协作。单 Agent 只能串行执行所有角色,无法形成真正的"多视角碰撞"。
- 训练信号单一:只有最终 reward 一个信号。无法区分"哪一步做对了"和"谁做对了"。
Multi-Agent 协同的核心思路很简单——多个角色分工合作,共享 reward 信号联合优化。但"如何协作"有两条截然不同的路径。Miles 提供了从轻量到生产的完整选择。
5.2 两条路径:内置流水线 vs MrlX
Miles 的 Multi-Agent 支持分为两层:
| 内置 Multi-Agent | MrlX(外部框架) | |
|---|---|---|
| 定位 | 轻量级示例,快速验证 | 生产级框架,独立仓库 |
| Agent 架构 | 共享模型 + 不同 prompt | 独立模型 + 异步协同进化 |
| 训练方式 | 一个优化器统一更新 | 每个 Agent 独立训练 + 协同 |
| 通信 | 函数调用(进程内) | 消息队列(跨集群) |
| 适用场景 | 数学推理、简单协作 | Doctor-Patient、DeepResearch |
| 模型 | 同一模型,不同角色 | 不同模型(可不同规模) |
| 复杂度 | ~100 行 | 完整框架 |
两条路径的共同根基都是 agentic_tool_call 框架——Miles 的通用 Agent 函数接口。内置方案将其用于进程内的角色流转,MrlX 则将其扩展为跨集群的消息驱动。
我们先从内置方案开始,理解 Multi-Agent 的核心设计要素,再看 MrlX 如何突破内置方案的限制。
5.3 内置方案:Solver → Rewriter → Selector 流水线
5.3.1 三段式架构
内置方案将一个完整的推理任务拆解为三个阶段。我们以数学题的 Multi-Agent 求解为例:
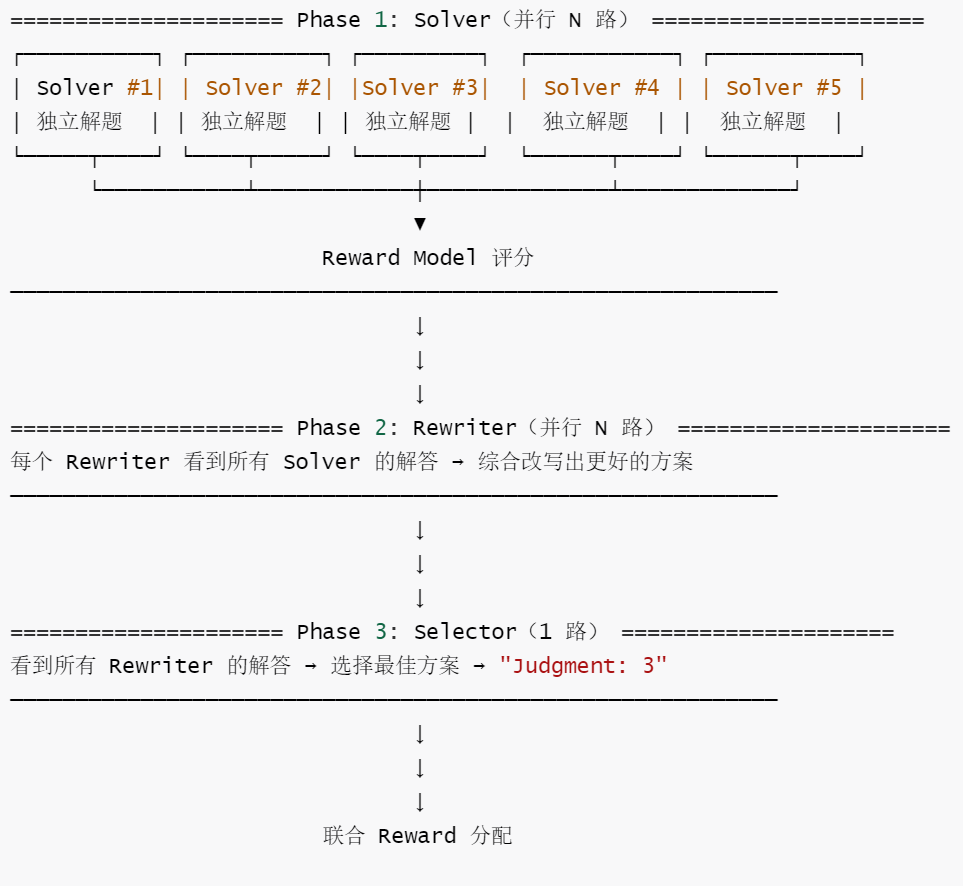
三个阶段各司其职:Solver 负责发散(N 路独立产生候选解),Rewriter 负责聚合(综合所有候选解的优点进行改进),Selector 负责裁决(在多轮改写结果中选出最优)。
5.3.2 关键设计一:共享模型,不同 Prompt(同体多灵)
这是内置方案最精妙的设计——三个角色运行在同一个 SGLang 引擎、同一套模型权重上,仅通过不同的 system prompt 切换行为模式:
同一个 SGLang 引擎
同一套模型权重
Solver prompt: "解决这道题..."
Rewriter prompt: "看了 N 个解法后改写..."
Selector prompt: "从 N 个方案中选最佳..."
→ 同一模型,不同角色行为
→ 训练时所有角色的 samples 一起更新
这意味着不需要额外的 GPU 资源、不需要部署多个模型实例。三个角色共享同一份权重,训练时所有角色产生的训练样本汇聚到同一个优化器——模型在一次更新中同时学到"如何解题"“如何改进别人的解法”“如何判断好坏”。
5.3.3 关键设计二:非对称 Reward 加权
这是内置方案区别于简单"独立训练三个 Agent"的核心机制。
在标准做法中,如果 Solver #3 答对了而其他 Solver 错了,Solver #3 获得正 reward,其他获得负 reward。但这种"个体成功"导向会鼓励 Agent 各自为战——只要我能答对,管你 Rewriter 能不能改好。
非对称 reward 的规则是:即使个别 Solver 答对了,如果整个系统最终失败(Selector 选错或 Rewriter 改写失败),所有 Agent 都受到轻微惩罚。 反之,即使个别 Solver 答错了,如果 Rewriter 修正了错误、Selector 做出了正确选择,全体获益。
效果:鼓励"系统级协作"而非"个体成功"。Agent 学会的不只是"答对题目",而是"让整个流水线成功"。
5.3.4 优雅降级
内置方案的另一设计考量是鲁棒性——每个 Agent 调用独立产生训练 Sample,如果一个 Solver 生成失败(格式错误、超时),不影响其他 Solver 的并行执行。Selector 只需要从有效的候选中做选择。
5.4 MrlX:突破单模型的异步协同进化
5.4.1 内置方案的边界
内置方案有一个根本限制:所有 Agent 共享同一个模型。这在以下场景不够用:
- 不同角色需要不同能力:如"医生"需要专业诊断能力,"患者"需要真实病情表述能力——同一个模型很难同时在这两个角色上都达到专家水平。
- 不同模型规模:医生可以用 32B 大模型做深度推理,患者用 8B 小模型生成多样化的病情描述——成本和效果同时优化。
- 独立训练节奏:简单角色训练快,复杂角色训练慢——共享优化器意味着必须等最慢的角色完成才能更新。
MrlX 的核心创新:让多个独立模型通过消息队列异步协同进化。
5.4.2 架构:消息队列 + 独立训练循环
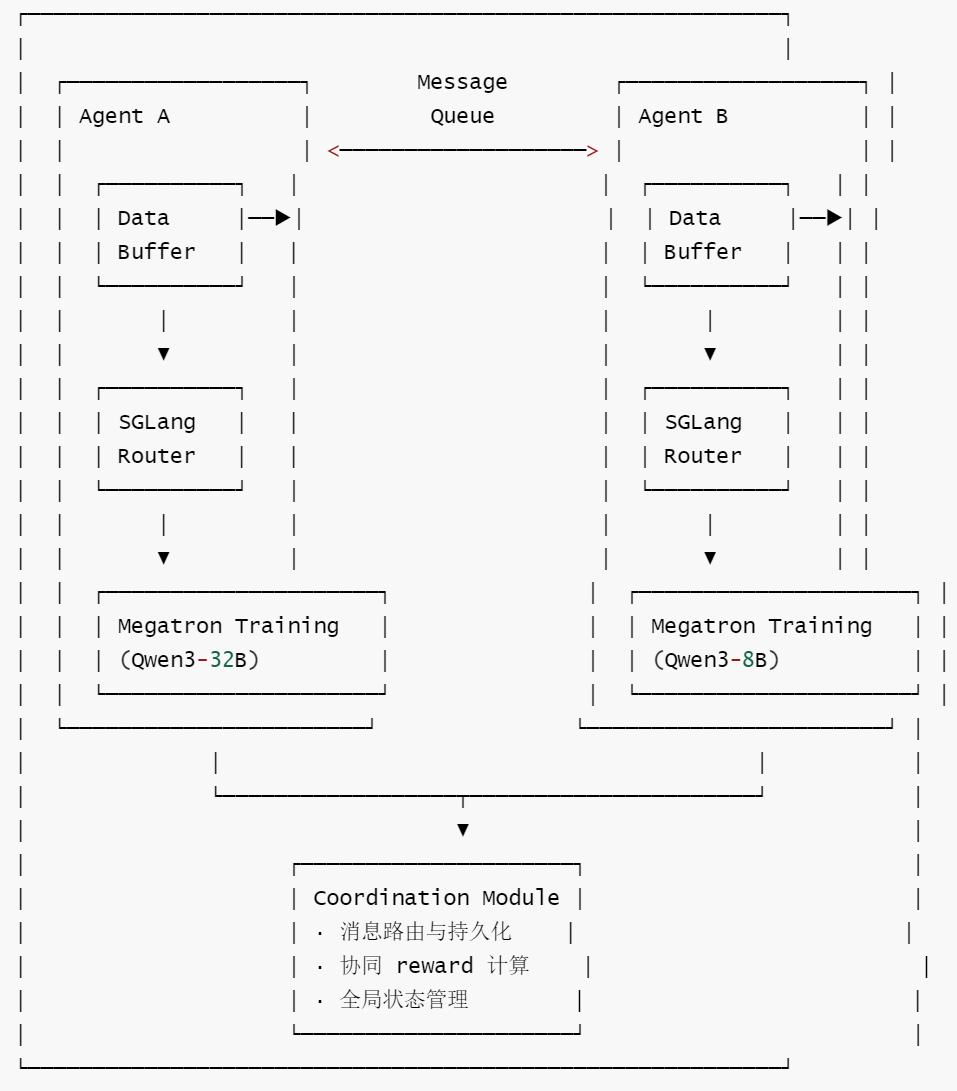
每个 Agent 拥有独立的 Data Buffer → SGLang Router → Megatron Training 全栈。Agent 之间不共享模型权重、不共享优化器、不共享 GPU。它们唯一的联系是通过消息队列交换对话内容和协同 reward。
5.4.3 协同进化的飞轮
以 Doctor-Patient 场景为例,两个 Agent 通过持续的对话交互形成正反馈循环:
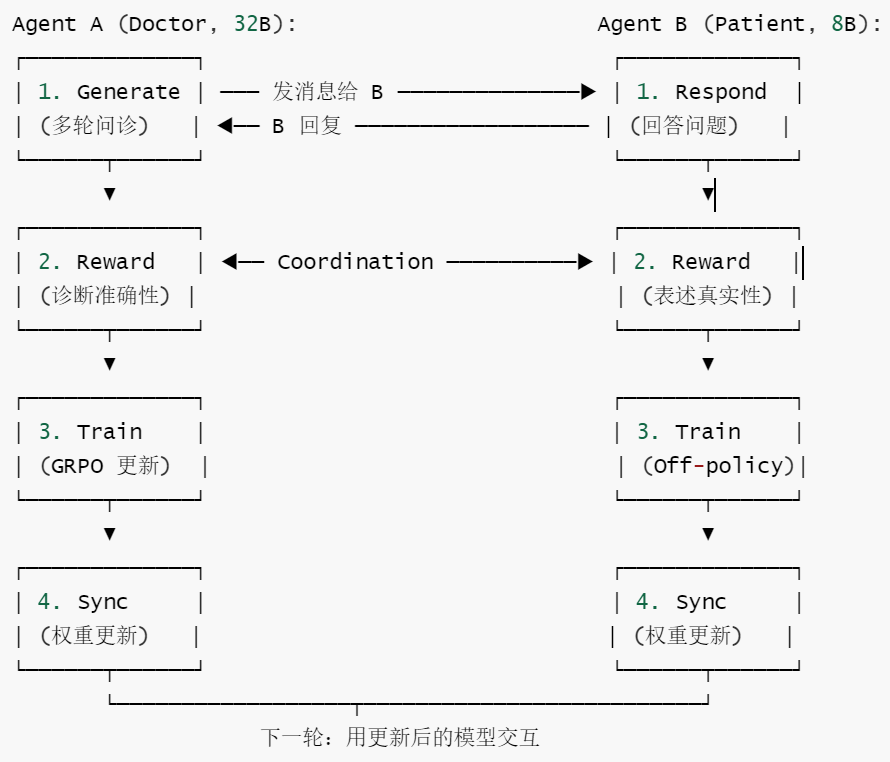
飞轮效应:Doctor 在问诊中变得更精准 → 产生更高质量的对话数据 → Patient 在回答中学到更真实的病情表述 → Doctor 接收到更有信息量的回答 → 诊断进一步提升。两个模型在相互对抗中共同进化——这正是"协同进化"(co-evolution)的含义。
5.4.4 关键差异:异步 + 非对称
MrlX 与内置方案的本质差异体现在两个"非对称"上:
部署非对称:不同 Agent 可以部署在不同集群、使用不同规模的模型、甚至采用不同的训练策略(on-policy vs off-policy)。Doctor 用 GRPO 在线学习,Patient 可以用离线 replay buffer——各自选择最适合自己角色的训练方式。
策略非对称:消息队列的异步特性意味着 Agent A 发送消息后不需要等待 Agent B 的回复就可以继续处理其他对话。这打破了内置方案中 Phase 1→Phase 2→Phase 3 的同步屏障,允许更灵活的交互模式。
5.5 对比总结:何时选哪条路
| 维度 | 内置 Multi-Agent | MrlX |
|---|---|---|
| 模型 | 同一模型 | 不同模型(可不同规模) |
| 训练 | 一个优化器统一更新 | 各自独立优化器 |
| 通信 | 函数调用(进程内) | 消息队列(跨集群) |
| 部署 | 单 Ray 集群 | 多 Ray 集群 |
| 同步性 | 同步(gather 等待所有角色) | 异步(队列驱动,不等待) |
| 策略 | 所有 Agent on-policy | 可混合 on/off-policy |
| 场景 | 数学推理、简单协作 | 医患对话、DeepResearch |
| 复杂度 | ~100 行,零额外依赖 | 完整框架,独立仓库 |
| 依赖 | 基于 Miles 基础能力 | 基于 slime/Miles,复用高性能训推基础设施 |
选择决策:
- 如果任务是单领域推理(如数学题、代码审查),不同角色只需要不同的"思考角度"而非不同的"知识体系"——选内置方案。一个模型 + 三个 prompt 足够,零额外成本。
- 如果任务需要跨领域角色协作(如医生和患者、老师和学生、研究员和事实核查员),不同角色需要不同的专业知识或模型能力——选 MrlX。异构模型 + 异步协同 + 独立训练。
两条路径都根植于 Miles 的 agentic_tool_call 框架和 Slime 的异步训推基础设施。内置方案证明了"共享模型 + 角色分工 + 非对称 reward"的可行性;MrlX 则将这一范式推到生产级——多模型、多集群、真正的异步协同进化。
0x06 环境
Miles 提供两种 generate 模式,没有内置任何真实环境实现 (代码沙箱、浏览器、API 调用等)。Miles 唯一内置的与环境相关的代码是:
- tool_call_utils.py - 解析 tool_call 格式 + 调用 execute_one 的 wrapper
- mock_tools.py (test_utils/) - 测试用的假工具
6.1 模式
模式 1: multi_turn.py - 框架管循环,用户管环境
Miles 负责: 用户负责:
├── 推理循环 (max_turns) ├── --generate-tool-specs-path (工具定义)
├── tool_call 解析 ├── --generate-execute-tool-function-path (执行函数)
├── token 拼接 + loss_mask └── async def execute_one (name, params) -> str
└── sample 构建
Miles 管 “循环骨架 + token 管理”,环境交互 (execute_one) 完全外部注入。
模式 2: agentic_tool_call.py - 全部委托给 agent function
Miles 负责: 用户负责:
├── TITO session 追踪 └── --custom-agent-function-path
├── session → training sample async def my_agent (base_url, prompt,
└── multi-turn merge request_kwargs, metadata) -> dict|None
# 用户自己管理推理 + 工具调用 + 环境交互
这个模式更彻底:连推理循环都委托了,Miles 只做 “session 录制 → 训练样本”。
6.2 为什么这样设计?
RL 环境的多样性决定了难以内置:
- 代码执行 (sandbox)
- 数学推理 (checker)
- 网页浏览 (browser)
- 多智能体对弈
- 自定义业务逻辑
Miles 的定位 = RL 训练基础设施,不是 Agent 框架。
6.3 三个环境注入点
环境 = 可插拔外部组件,通过 3 个钩子注入。
| 钩子 | 作用 | 粒度 |
|---|---|---|
--generate-execute-tool-function-path |
单次工具调用执行 | 函数级 |
--generate-tool-specs-path |
工具定义 (JSON Schema) | 配置级 |
--custom-agent-function-path |
完整 agent 逻辑 (含环境交互) | 系统级 |
0x07 MBridge 模型抽象层
MBridge 提供了统一 Dense/MoE/SSM/Hybrid 模型的 Megatron 训练适配。
- 新模型只需注册一个 Bridge 类 (实现 PP-group unwrap + model shim)
- 屏蔽了 Megatron 内部 PP/TP/EP 的复杂性
- 使得 R3、TIS、True On-Policy 等上层技术可无缝应用于新架构
7.1. 架构定位
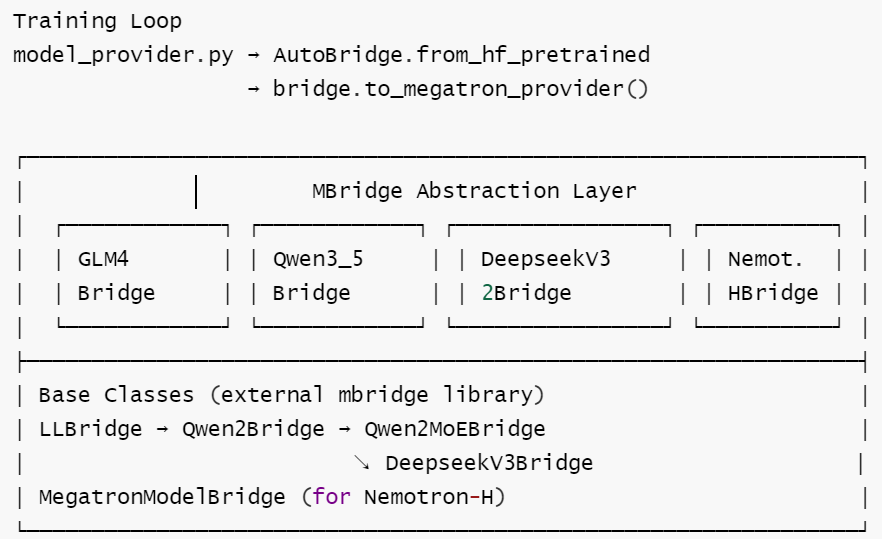
7.2 Bridge 注册机制
# 每个 bridge 使用 @register_model() 装饰器注册
@register_model("glm-4")
class GLM4Bridge(LLMBridge):
...
# Nemotron-H 使用 Megatron 原生注册
@MegatronModelBridge.register_bridge("nemotron-h")
class MilesNemotronHBridge(NemotronHBridge):
...
# __init__.py 导入所有模块触发注册
# miles_plugins/mbridge/__init__.py:1-17
7.3 训练循环选择桥接
# miles/backends/megatron_utils/model_provider.py:89-130
if args.megatron_to_hf_mode == "bridge":
bridge = AutoBridge.from_hf_pretrained(model_path)
provider = bridge.to_megatron_provider(...)
7.4 全部 Bridge 类 (9 个)
| # | 类名 | 父类 | 架构 | 特殊能力 |
|---|---|---|---|---|
| 1 | GLM4Bridge |
LLMBridge |
Dense | 标准 transformer spec |
| 2 | GLM4MoEBridge |
Qwen2MoEBridge |
MoE | expert-fused, MTP, 自定义 QKV TP-split |
| 3 | GLM4MoEEliteBridge |
DeepseekV3Bridge |
MoE/MLA | alltoall dispatch, expert bias, shared_head |
| 4 | MimoBridge |
Qwen2Bridge |
Dense+MTP | eh_proj TP split swap |
| 5 | Qwen3_5Bridge |
Qwen2MoEBridge |
Dense+MoE | shared expert gate, attention output gate |
| 6 | Qwen3NextBridge |
Qwen2MoEBridge |
MoE/Hybrid Attn | linear/gated attention QKV merge |
| 7 | DeepseekV32Bridge |
DeepseekV3Bridge |
Dense/DSA | weight-half swapping |
| 8 | GlmMoeDsaBridge |
DeepseekV32Bridge |
MoE/DSA | 继承 (空实现) |
| 9 | MilesNemotronHBridge |
NemotronHBridge |
Hybrid(Mamba+Attn) | PP-group shim, MoE injection, loss-mask shim |
7.5 Bridge 的核心职责
每个 Bridge 需要解决 HuggingFace 权重 ↔ Megatron 权重 的双向转换:
HF checkpoint (model.safetensors)
↓ _weight_to_mcore_format()
Megatron format (PP/TP/EP sharded)
↓ training ...
↓ _weight_to_hf_format()
HF checkpoint (for rollout engine update)
关键方法 (每个 bridge 按需覆盖):
| 方法 | 职责 |
|---|---|
_build_config() |
构建 Megatron TransformerConfig |
_get_transformer_layer_spec() |
定义层结构规格 |
_weight_name_mapping_mcore_to_hf() |
权重名称映射 |
_weight_to_mcore_format() |
HF→Megatron 权重变换 (TP split, QKV merge) |
_weight_to_hf_format() |
Megatron→HF 权重变换 (TP gather, split) |
_convert_mtp_param() |
Multi-Token Prediction 参数处理 |
_get_gptmodel_args() |
GPTModel 构造参数 |
7.6. 关键适配模式
7.6.1 TP (Tensor Parallel) QKV 合并
# Qwen3_5Bridge: mbridge/qwen3_5.py:304-346
# HF 存储分离的 q_proj, k_proj, v_proj
# Megatron 需要合并为单个 qkv_proj 并按 TP 切分
def _weight_to_mcore_format(self, name, tensor, config):
if "q_proj" in name:
# reshape + interleave + TP-split
tensor = merge_qkv(q, k, v, tp_size)
return tensor
7.6.2 MoE Expert 映射
# GLM4MoEBridge: mbridge/glm4moe.py:201-293
# 处理 fused expert weights (多个 expert 合并为单 tensor)
# 或 unfused (每个 expert 独立文件)
# + shared expert 特殊路径
7.6.3 PP-Group Unwrap Shim (Nemotron-H)
# miles_plugins/megatron_bridge/__init__.py:23-54
# 全局 shim: 在 PP 拆分时正确处理 Mamba + Attention 交错层
# 确保 Mamba state 不跨 PP 边界断裂
7.6.4 Hybrid Model Adaptation (Nemotron-H)
# miles_plugins/megatron_bridge/nemotron_h.py:77-132
# provider_bridge():
# - 注入 num_moe_experts, moe_router_*, moe_layer_freq
# - 条件性启用/禁用 MTP
# - Hybrid layer shims (Mamba state + Attention KV)
# - Loss-mask shim for SSM layers
7.7. 权重更新路径
# miles/backends/megatron_utils/update_weight/hf_weight_iterator_bridge.py:17-51
# 训练完成后, Bridge 将 Megatron 权重转换/导出为 HF 格式
# 导出后由上层 update_weight 流程推送到 SGLang 引擎
bridge = AutoBridge.from_hf_pretrained(model_path)
tasks = bridge.get_conversion_tasks(megatron_state_dict)
hf_weights = bridge.export_hf_weights(tasks)
# 或 LoRA:
adapter_weights = bridge.export_adapter_weights(...)
7.8. 继承树总览
LLMBridge (external)
├── GLM4Bridge
├── Qwen2Bridge (external)
│ └── MimoBridge
└── Qwen2MoEBridge (external)
├── GLM4MoEBridge
├── Qwen3_5Bridge
└── Qwen3NextBridge
DeepseekV3Bridge (external)
├── GLM4MoEEliteBridge
└── DeepseekV32Bridge
└── GlmMoeDsaBridge
MegatronModelBridge (external, Megatron-native)
└── NemotronHBridge (external)
└── MilesNemotronHBridge
7.9. 与 R3/TIS/True On-Policy 的集成
- R3: MoE Bridge 负责正确映射 router weights, 使得训练时可以 replay routing decisions
- TIS: Bridge 导出的 HF 权重用于更新 rollout engine, TIS 修正新旧策略差异
- True On-Policy: Bridge 确保训练和推理使用相同的模型结构 (config 一致), 是合约成立的前提
7.10. MBridge 设计评价
| 维度 | 评价 |
|---|---|
| 正确性 | ✅ 双向转换保证权重等价 |
| 可扩展 | ✅ 新模型只需加一个 Bridge 子类 + @register_model |
| 复杂度 | ⚠️ QKV merge/split 逻辑复杂,出错难调试 |
| 覆盖面 | ✅ Dense/MoE/MLA/SSM/Hybrid/MTP 全覆盖 |
| 与上游耦合 | 依赖外部 mbridge 库的 base classes |
vs 直接用 Megatron checkpoint:
- Megatron 原生 checkpoint 格式与 HF 不通用
- Bridge 使得 Miles 可以直接加载 HuggingFace 模型 -> 训练 -> 导出 HF 格式 -> 热更新到 SGLang
- 这是支撑 “三层解耦” 的关键: 训练层 (Megatron格式) <-> Bridge -> 推理层 (HF格式/SGLang)
0x08 RadixTree 前缀复用中间件
核心价值: Router 层维护活跃 session 的 token 前缀树, 最大化 KV-cache 利用率
8.1 工作原理
Session A: [sys][user1][asst1][user2]
Session B: [sys][user1][asst1][user3]
↑ 分叉点
RadixTree 将 A 和 B 路由到同一 engine → 共享 [sys][user1][asst1] 的 KV-cache
关键之处在于:
- 长对话场景 prefill 开销巨大 (token 数 × layers × heads)
- 前缀复用可将 prefill 从 O(n) 降到 O(Δn)
- 对话越长, 收益越大 (2-5x 吞吐提升)
8.2 架构定位
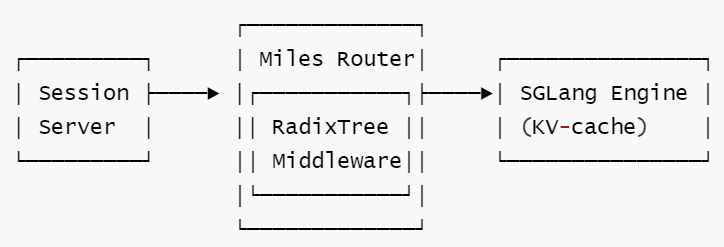
- 层级: Router 中间件 (
BaseHTTPMiddleware子类) - 作用: 拦截
/generate和/retrieve_from_text请求,利用全局文本前缀缓存减少重复 prefill - 注册方式: CLI 参数
--miles-router-middleware-paths miles.router.middleware_hub.radix_tree_middleware.RadixTreeMiddleware
8.3 核心数据结构
StringTreeNode
class StringTreeNode:
children: list[StringTreeNode] # 子节点列表 (线性扫描)
parent: Optional[StringTreeNode]
string_key: str # 本节点持有的文本片段
token_ids: Optional[list[int]] # 对应的 token IDs
logp: Optional[list[float]] # 对应的 log probabilities
loss_mask: Optional[list[int]] # 训练 loss mask
last_access_time: float # 最后访问时间
access_count: int # 访问计数
ref_count: int # 引用计数 (0=可回收)
weight_version: int # 生成时的模型权重版本
id: int # 节点唯一 ID
StringRadixTrie
class StringRadixTrie:
root: StringTreeNode
_lock: threading.RLock # 全局可重入互斥锁 (非读写锁)
max_cache_size: int = 10000 # 最大缓存 token 总量 (非节点数)
tokenizer: ... # 用于验证
verbose: bool = False
cur_cache_size: int = 0 # 当前已缓存 token 数
MatchResult
@dataclass
class MatchResult:
matched_prefix: str # 匹配到的文本前缀
token_ids: list[int] # 累积的 token IDs
logp: list[float] # 累积的 logprobs
loss_mask: list[int] # 累积的 loss mask
remaining_string: str # 未匹配的剩余文本
last_node: StringTreeNode # 最后匹配到的节点
8.4 核心算法
最长前缀匹配 (find_longest_prefix)
算法:从 root 开始,逐层扫描 children
对每个节点:
线性遍历 children 列表
选择 string_key 是剩余文本完整前缀的最长子节点
累积该节点的 token_ids /logp/loss_mask
继续递归直到无匹配
复杂度: 0 (文本长度 × 平均子节点数)
插入 (insert)
算法:类似查找,走到分叉点后:
- 如果完全匹配现有路径的一段 → 分裂节点
- 否则 → 创建新子节点
新节点携带 weight_version 标记
复杂度: 0 (文本长度 × 平均子节点数)
删除 (remove)
算法:先 find_longest_prefix 定位目标节点
递归删除整棵子树
向上合并单子节点 (路径压缩)
复杂度: 0 (子树大小)
8.5 GC / 版本追踪
基于 weight_version 的 GC
# 核心逻辑:
def gc_by_weight_version(self, current_weight_version, gc_threshold_k):
# 删除所有 weight_version <= current - gc_threshold_k 的节点
outdated_nodes = self._find_outdated_nodes(root, threshold)
for node in outdated_nodes:
self.remove(node)
设计要点:
- 非 LRU: 不按访问时间淘汰,而是按模型版本
- 理由: 旧版本模型生成的 KV-cache 在新模型下是无效的
ref_count == 0标记可回收,但实际触发靠 weight_version_find_outdated_nodes()(line 473-501) 整棵子树剪裁
8.6 锁模式
| 操作 | 锁行为 |
|---|---|
find_longest_prefix |
with self.lock |
insert |
with self.lock |
remove |
with self.lock |
gc_by_weight_version |
with self.lock |
get_stats |
with self.lock |
clear |
with self.lock |
单一 RLock, 所有操作互斥。这意味着:
- 高并发下 insert 和 lookup 会竞争
- 但由于 middleware 请求路径中 lock 持有时间很短 (纯内存操作),实际瓶颈不在此
8.7 Middleware 工作流 (radix_tree_middleware.py)

8.8 与 Session 的关系
关键发现: RadixTree 与 Session Server 是 完全独立的:
- RadixTree 是全局文本缓存,以文本内容为 key
- Session Server 管理有状态对话,以 session_id 为 key
- 两者通过相同 Router 但互不感知
- 多个 session 如果共享文本前缀,自然复用同一 trie 路径
8.9 性能特征
| 指标 | 值 |
|---|---|
| 查找复杂度 | O (L × B), L = 文本长度,B = 平均分支因子 |
| 插入复杂度 | O(L × B) |
| 最大缓存 | 10000 tokens (总 token_ids 计数,非节点数) |
| 子节点查找 | 线性扫描 (非 hash map) |
| 锁粒度 | 全局单锁 |
| GC 触发 | weight_version 阈值 |
潜在优化点: children 用 list (线性扫描) 而非 dict/trie, 在高分支因子场景可能成为热点。
8.10 RadixTree 设计评价
| 维度 | 评价 |
|---|---|
| 正确性 | ✅ weight_version GC 确保不会用过期缓存 |
| 简洁性 | ✅ 单锁 + 纯内存,无外部依赖 |
| 扩展性 | ⚠️ 线性 children 扫描;单锁全互斥 |
| 适用场景 | 长对话、大量共享前缀 (如同 system prompt 的多 session) |
| 不适用 | 短对话、前缀高度唯一场景收益低 |
vs SGLang 内置 prefix cache:
- SGLang 在 engine 内部做 KV-cache prefix sharing (token 级)
- Miles RadixTree 在 Router 层 做跨 engine 路由决策 (文本级)
- 两者互补: RadixTree 确保相同前缀的请求路由到同一 engine -> engine 内 prefix cache 命中
0xEE 个人信息
★★★★★★关于生活和技术的思考★★★★★★
微信公众账号:罗西的思考

0xFF 参考

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)