KV Cache 到底是什么?一文讲透大模型推理加速原理

大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚焦于业务型系统的工程化建设与长期维护。
我持续输出和沉淀前端领域的实战经验,日常关注并分享的技术方向包括 前端工程化、小程序、React / RN、Flutter、跨端方案,
在复杂业务落地、组件抽象、性能优化以及多端协作方面积累了大量真实项目经验。
技术方向:前端 / 跨端 / 小程序 / 移动端工程化
内容平台:掘金、知乎、CSDN、简书
创作特点:实战导向、源码拆解、少空谈多落地
文章状态:长期稳定更新,大量原创输出
我的内容主要围绕 前端技术实战、真实业务踩坑总结、框架与方案选型思考、行业趋势解读 展开。文章不会停留在“API 怎么用”,而是更关注为什么这么设计、在什么场景下容易踩坑、真实项目中如何取舍,希望能帮你在实际工作中少走弯路。
子玥酱 · 前端成长记录官 ✨
👋 如果你正在做前端,或准备长期走前端这条路
📚 关注我,第一时间获取前端行业趋势与实践总结
🎁 可领取 11 类前端进阶学习资源(工程化 / 框架 / 跨端 / 面试 / 架构)
💡 一起把技术学“明白”,也用“到位”
持续写作,持续进阶。
愿我们都能在代码和生活里,走得更稳一点 🌱
文章目录
引言
如果你研究过大模型推理系统,大概率会频繁看到一个词:
KV Cache
几乎所有推理框架都在谈它:
vLLM 在讲 KV Cache
TensorRT-LLM 在讲 KV Cache
SGLang 在讲 KV Cache
LMDeploy 在讲 KV Cache
甚至很多推理优化方案,本质上都是围绕 KV Cache 展开的:
PagedAttention
Prefix Cache
Chunked Prefill
KV Cache Offloading
于是很多人开始产生一种错觉:
KV Cache 是一种高级优化技巧。
实际上并不是,从某种意义上说:
没有 KV Cache,就没有今天的大模型推理系统。
甚至可以说:
Transformer 决定模型能力
KV Cache 决定推理速度
而真正理解 KV Cache,需要先回答一个问题:
为什么大模型推理这么慢?
一、为什么大模型推理会变慢
先看一个简单例子,用户输入:
你好
模型生成:
你好,请问有什么可以帮助你?
然后继续生成:
你好,请问有什么可以帮助你?
今天
接着:
你好,请问有什么可以帮助你?
今天天气
再接着:
你好,请问有什么可以帮助你?
今天天气不错
很多人以为:
每次只计算新Token
实际上不是,Transformer 的原始计算方式是:
第1个Token
计算1次
第2个Token
计算2次
第3个Token
计算3次
第N个Token
计算N次
随着序列增长:
计算量持续增长
最终:
推理越来越慢
二、问题出在哪里
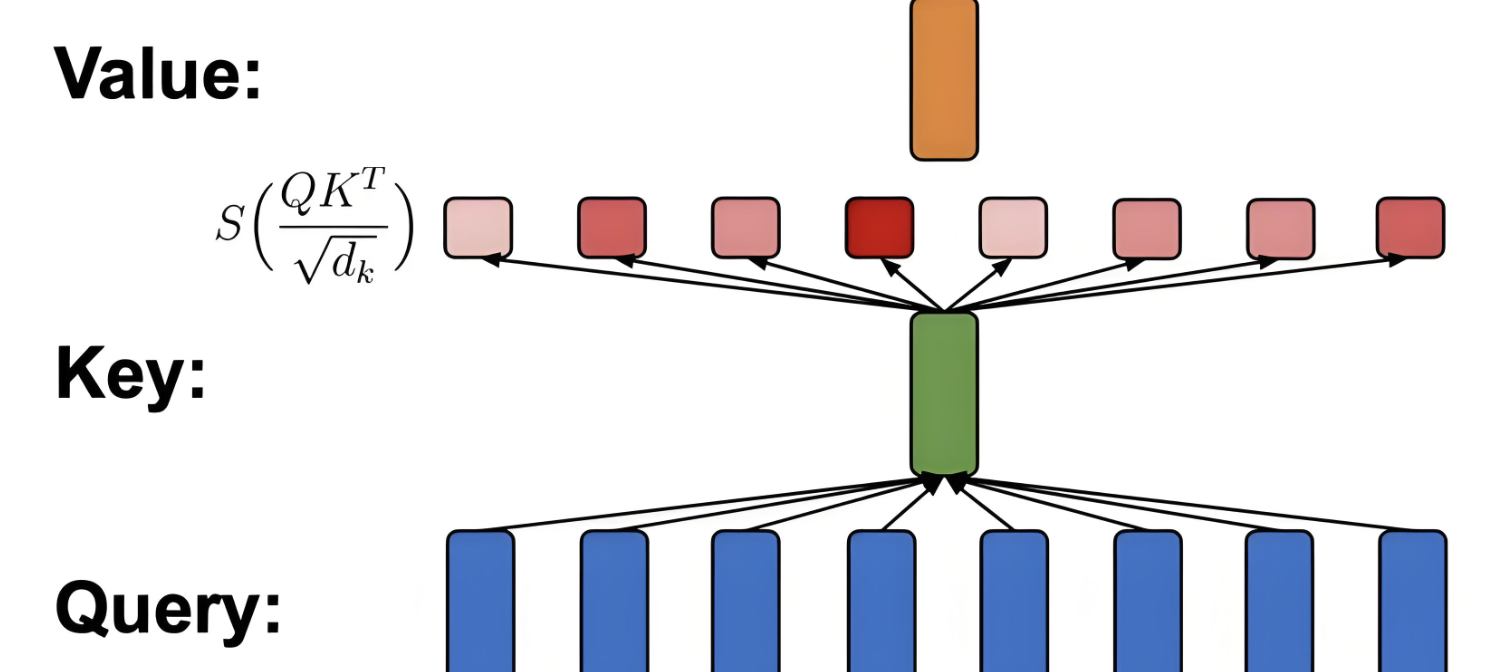
问题来自 Transformer 的 Attention,Attention 的本质是:
当前 Token 需要关注历史所有 Token。
例如:
我
爱
北
京
天
安
门
生成:
门
时。
模型需要关注:
我
爱
北
京
天
安
所有历史内容,计算过程:
Q × K
得到相关性,然后:
Attention × V
得到最终结果,这里出现三个核心概念:
Query (Q)
Key (K)
Value (V)
三、什么是 Key 和 Value
Transformer 每一层都会生成:
Q
K
V
三个向量,例如:
Token:
北京
经过线性变换:
Q_beijing
K_beijing
V_beijing
其中:
Q:
我想找谁
K:
我是哪个信息
V:
我携带什么内容
可以理解成:
Q = 查询条件
K = 索引
V = 数据
类似数据库:
Key → Value
结构,这也是:
KV
名称的来源。
四、为什么会产生大量重复计算
假设当前上下文:
我爱北京天安门
生成第一个 Token 时:
Q1
K1
V1
完成计算。生成第二个 Token 时,很多人以为:
只算新的Token
实际上:
Q1
K1
V1
Q2
K2
V2
又重新计算一次,第三个 Token:
Q1
K1
V1
Q2
K2
V2
Q3
K3
V3
再次重算,也就是说:
历史Token
不断重复计算
这是巨大的浪费。
五、KV Cache 的核心思想
解决方案非常简单:
已经计算过的 K 和 V,不要重复计算。
第一次计算:
Token1
↓
生成K1
生成V1
保存下来。
Cache
K1
V1
第二次推理:
直接复用
K1
V1
不再重新计算,只需要计算:
K2
V2
即可,形成:
历史Token
↓
KV Cache
新Token
↓
实时计算
六、KV Cache 工作流程
没有 Cache:
Token1
Token1 Token2
Token1 Token2 Token3
Token1 Token2 Token3 Token4
全部重算。
有 Cache:
Token1
↓
Cache KV
Token2
↓
Cache KV
Token3
↓
Cache KV
下一轮:
直接读取Cache
即可。
对比
无 Cache:
1
+
2
+
3
+
4
+
...
+
N
总计算量:
O(N²)
有 Cache:
每次只算新增Token
变成:
O(N)
推理速度大幅提升。
七、KV Cache 长什么样
以一个 Attention Layer 为例,假设:
Sequence Length = 4
Hidden Size = 4096
Heads = 32
那么缓存内容:
Layer1
├── K Cache
└── V Cache
Layer2
├── K Cache
└── V Cache
Layer3
├── K Cache
└── V Cache
一直到:
Layer32
每层都有独立 Cache。
数据结构
通常类似:
kv_cache = {
layer_id: {
"k": Tensor,
"v": Tensor
}
}
推理时:
直接读取历史KV
参与计算。
八、KV Cache 为什么这么占显存
这是所有推理系统最头疼的问题。很多人发现:
模型加载完成
显存正常
开始对话后:
显存疯狂上涨
原因就在 KV Cache。
举个例子
Llama 70B:
80层
64 Heads
8192 Hidden Size
如果上下文:
32K Token
KV Cache 可能占用:
几十GB
甚至超过模型权重,所以推理系统里经常出现:
模型没撑爆GPU
KV Cache撑爆GPU
的情况。
九、为什么 vLLM 会火
因为传统 KV Cache 有严重问题。例如,用户A:
占用10MB
用户B:
占用20MB
用户C:
占用5MB
随着会话增多:
显存碎片越来越多
形成:
Memory Fragmentation
问题。
vLLM 的解决方案
借鉴操作系统,分页内存思想。即:
PagedAttention
把 KV Cache 拆成:
Block1
Block2
Block3
像虚拟内存一样管理。这样:
显存利用率提升
吞吐提升
这也是 vLLM 爆火的重要原因。
十、Prefix Cache
企业场景还有一个问题,例如:
你是一个专业助手
请遵守公司规范
请使用中文回答
...
每个请求都一样,这部分 Prompt:
重复计算
非常浪费,于是出现:
Prefix Cache
首次计算:
System Prompt
↓
生成KV
↓
缓存
后续请求:
直接复用
无需再次 Prefill,因此:
首Token延迟下降
非常明显。
十一、为什么 Agent 时代更依赖 KV Cache
过去 ChatBot:
几轮对话
结束,现在 Agent:
长上下文
长任务
多轮决策
例如:
100K Context
甚至:
1M Context
已经开始出现,此时:
KV Cache
变成推理系统核心资源,很多时候:
GPU不是算力瓶颈
KV Cache才是瓶颈
十二、下一代 KV Cache 技术
随着上下文越来越长,行业正在研究:
KV Compression
压缩,例如:
量化KV
INT8 KV
FP8 KV
降低显存,还有:
KV Eviction
淘汰机制,类似:
LRU Cache
策略,长期不用的数据:
自动删除
甚至:
KV Cache Offloading
把 KV 放到:
CPU Memory
SSD
Remote Memory
中。进一步突破 GPU 限制。
十三、真正的本质
很多人认为:
Transformer
是大模型推理的核心,实际上到了推理系统阶段会发现:
Attention
↓
KV Cache
↓
Memory Management
才是真正决定性能的关键,因为:
训练阶段:
算力决定效率
而:
推理阶段:
显存决定效率
KV Cache 恰好连接了:
Attention
+
Memory
两大核心问题。
总结
如果用一句话解释 KV Cache:
KV Cache 本质上是 Transformer Attention 的结果缓存机制,用空间换时间,避免历史 Token 的重复计算。
它解决的是:
重复计算问题
核心思想可以概括为:
已经算过的 K 和 V
不要再算第二次
从架构角度来看:
Transformer
决定模型能力
而:
KV Cache
决定推理效率
过去很多人认为:
GPU 是推理系统的核心
但随着长上下文和 Agent 时代到来,越来越多工程师开始发现:
未来推理系统竞争的核心,可能不是谁拥有更多 GPU,而是谁拥有更高效的 KV Cache 管理能力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)