ChordEdit:基于最优传输理论的免训练单步图像编辑
文章目录
- 一、前言
- 二、ChordEdit论文
-
-
- 1. 研究背景与问题
- 2. 核心方法:ChordEdit
- 3. 方法特性
- 4. 实验结果
- 5. 一句话总结
- 通俗解释
- 1. 背景:一步式模型很快,但"改图"是老大难
- 2. 传统方法为什么失败?——"粗暴相减"的陷阱
- 3. ChordEdit的解法——"走弦,不走差"
- 4. 可选的"语义增强"——到了终点再微调
- 5. 效果总结
- 一句话总结
- 问题1:怎么找到A到B的路径的?
- 1. 为什么叫"弦"?
- 2. 最优传输理论是什么?(用搬沙子比喻)
- 3. ChordEdit 是怎么找到A→B这条路的?
- 4. 一句话总结整个过程
- 问题2:最优传输理论
- 1. 起源:蒙日的"土堆问题"(1781年)
- 2. 突破:坎托罗维奇的"分配方案"(1940年代)
- 3. 动态视角:从"搬运方案"到"流体演化"(2000年)
- 4. 现代复兴:从数学象牙塔到AI核心
- 5. 一句话总结这个理论的精神
- 问题3:你怎么知道A到B总动能最小的全局路径
- 1. ChordEdit 并没有真正求解最优传输问题
- 2. 为什么这能"假装"最优传输?
- 3. 关于"结构认知":这是你最狠的质疑
- 4. 分工:模型负责"认知",ChordEdit 负责"稳"
- 5. 那真正的最优传输在哪?
- 一句话总结你的质疑
- 问题4:你怎么知道A到B总动能最小的全局路径
- 1. 弦理论是什么?
- 核心思想:世界不是由"点"构成的,而是由"弦"构成的
- 为什么需要弦理论?
- 2. 弦理论的故事
- 起源:一个"错误"的数学公式(1968年)
- 第一次超弦革命(1984年)
- 第二次革命与M理论(1995年)
- 现状:数学上极美,物理上未验证
- 3. 跟 ChordEdit 的"弦"有关系吗?
- 联系:两者共享"弦"的隐喻
- 区别:完全是两个世界的东西
- 关于"Chord"这个词的双关
- 4. 一句话总结
- 问题5:和弦的距离
- 1. 和弦之间的"距离"到底是什么?
- ① 共同音距离(Voice Leading 距离)
- ② 功能距离(T-S-D-T 循环)
- ③ 五度圈距离(Circle of Fifths)
- 2. 伟大音乐家怎么利用这些"距离"?
- 巴赫:数学般的声部连接
- 贝多芬:张力与释放的拓扑学
- 爵士乐:和弦替换(Chord Substitution)
- 3. 与 ChordEdit 的惊人共鸣
- 最核心的同构
- 4. 一句话总结
-
- 三、chordedit_cli.py
一、前言
仅供参考,未经实验验证。
二、ChordEdit论文
论文标题:ChordEdit: One-Step Low-Energy Transport for Image Editing
作者:Liangsi Lu1, Xuhang Chen2, Minzhe Guo1, Shichu Li3, Jingchao Wang4, Yang Shi1
机构:广东工业大学、惠州大学、深圳大学和北京大学
论文地址: https://arxiv.org/pdf/2602.19083
Github地址:https://github.com/ChordEdit/ChordEdit
1. 研究背景与问题
一步式文本到图像模型(如 SD-Turbo、SwiftBrush-v2、InstaFlow)通过蒸馏扩散模型实现了极快的单步推理速度,但将其用于文本引导图像编辑时,现有方法会严重失败:
- 物体严重扭曲(编辑目标变形到无法识别)
- 非编辑区域崩溃(背景、周围结构瓦解)
传统无训练编辑方法(如 FlowEdit、InfEdit)在多步扩散中表现稳定,其核心是计算源提示和目标提示的漂移差分(drift difference)。但在单步模型中,这种"简单漂移差分"会产生高能量、不稳定、方差大的控制场,单步大步长积分时误差剧烈累积,导致编辑失败。
2. 核心方法:ChordEdit
作者将编辑问题重新定义为源分布到目标分布的传输问题,利用动态最优传输理论(Dynamic Optimal Transport) 推导出一个低能量的控制策略:
弦控制场(Chord Control Field)
不直接使用瞬时不稳定的漂移差分,而是通过对时间窗口内的可观测场进行因果单边核平滑(时间加权平均),得到一个:
- 低能量(Low-Energy)
- 低方差(Variance-Reduced)
- 数值稳定(Inherently Stable)
的编辑场。这个平滑后的场可以用单步大步长精确穿越,实现"一步直达"的编辑。
公式上,它将朴素场 R ( x τ , t ) R(x_\tau, t) R(xτ,t) 替换为:
u ^ t ( x τ ) = t ⋅ R ( x τ , t − δ ) + δ ⋅ R ( x τ , t ) t + δ \hat{u}_t(x_\tau) = \frac{t \cdot R(x_\tau, t-\delta) + \delta \cdot R(x_\tau, t)}{t + \delta} u^t(xτ)=t+δt⋅R(xτ,t−δ)+δ⋅R(xτ,t)
这相当于对原始高能量场做时间卷积平滑,从理论上保证了 L 2 L^2 L2 收缩和 L ∞ L^\infty L∞ 收缩,抑制了能量尖峰。
可选的近端细化(Proximal Refinement)
单步传输后,可额外做一个仅使用目标提示的轻量级前向传播,用于增强目标语义(如"将马变成独角兽"时强化角的出现),这一步不涉及反演,即插即用。
3. 方法特性
- 模型无关(Model-Agnostic):黑盒调用模型的速度/漂移场即可,不限定具体模型架构
- 无训练(Training-Free):不需要训练专用网络
- 无反演(Inversion-Free):不需要多步反演过程
- 轻量实时:单步推理,实现真正的实时编辑
4. 实验结果
在 PIE-bench 基准上对比了多种单步、少步和多步编辑方法:
- 背景保留(PSNR) 达到顶尖水平
- 语义对齐(CLIP Score) 具有竞争力
- 运行时间 极短(毫秒级),显存占用低(约7GB)
相比需要训练专用反演网络的 SwiftEdit、InfEdit 等方法,ChordEdit 在保持灵活性的同时实现了相当的编辑质量。
5. 一句话总结
ChordEdit 通过最优传输理论将"简单漂移差分"替换为"低能量弦控制场",解决了单步生成模型在文本引导图像编辑中的不稳定问题,首次在无需训练、无需反演的情况下实现了真正的一步式实时高保真图像编辑。
通俗解释
这篇论文讲的是一个让AI"一步改图"既快又稳的方法。我用几个比喻给你讲清楚。
1. 背景:一步式模型很快,但"改图"是老大难
现在有些AI画图模型(比如SD-Turbo)被"蒸馏"过了,原本需要跑50步才能出一张图,现在一步就能搞定,速度极快。
但问题是:这些模型生成新图很快,按照你的要求修改已有图片却很糟。比如你说"把这只狗变成狮子",传统方法一步改完,结果:
- 狮子长得歪七扭八(目标物体扭曲)
- 背景草地、天空也全碎了(非编辑区域崩溃)
2. 传统方法为什么失败?——"粗暴相减"的陷阱
传统无训练编辑的思路很简单:
目标提示的"力场" 减去 源提示的"力场" = 编辑所需的"控制力"
打个比方:
- 源提示是"狗",它对应一条从噪声到狗图片的路径A
- 目标提示是"狮子",它对应一条从噪声到狮子图片的路径B
- 传统方法认为:编辑就是把这两条路径直接相减,得到一条"从狗变到狮子"的捷径
问题就出在这里。
一步式模型被蒸馏后,它的内部路径非常非线性、敏感、陡峭。直接相减得到的不是"捷径",而是一条极其崎岖、能量爆炸的野路——有的地方坡度90度,有的地方还有断崖。你让它一步跨过去,必然会摔得面目全非,背景也连带被扯坏。
3. ChordEdit的解法——“走弦,不走差”
作者换了个思路:不玩"粗暴相减",而是把编辑看成**"搬运"问题**。
想象你要把一堆"狗的图片分布"搬运到"狮子的图片分布"。最优传输理论告诉你:最省力的搬运方式,不是找两条路径的差,而是找一条**平滑、低能量的"弦"**直接连接两者。
ChordEdit的核心就是这个"弦控制场":
它不是用 目标场 - 源场,而是对这两个场做一个时间加权平均。通俗说:
就像你要从A点走到B点,传统方法是把"A到终点的方向"和"B到终点的方向"粗暴相减,结果方向混乱;
ChordEdit则是把两个方向平滑融合,算出一条又直又稳的"弦",沿着这条弦一步就能走到位。
数学上,这相当于给原本狂暴的向量场做了一次**“平滑滤波”**,把尖峰和噪声都压下去,让整条路变得平坦可控。
4. 可选的"语义增强"——到了终点再微调
单步走到目标附近后,ChordEdit还可以额外做一个轻量操作:只用目标提示(“狮子”)再做一次小幅修正,强化"狮子特征"(比如鬃毛)。这一步不碰原图结构,只是补语义,类似"到了地方再整理一下妆容"。
5. 效果总结
| 特性 | 说明 |
|---|---|
| 一步搞定 | 不需要像传统扩散模型那样反复迭代50步 |
| 不改的地方不动 | 背景保留极好,不会莫名其妙碎掉 |
| 不用训练 | 直接套用在现有的一步模型上,即插即用 |
| 不用反演 | 不需要先把图片"倒推回噪声"再编辑,省去大量计算 |
一句话总结
传统方法改图像是"用两条陡峭山路的差值去攀岩",一步跨出去必然摔;ChordEdit像是"在山谷间拉了一条平稳的钢索",一步滑过去,既快又稳,原样不动的地方丝毫不动。
问题1:怎么找到A到B的路径的?
你的意思是本来是噪声到A和噪声到B两个方向,现在想要找到A到B那个方向,过去的方法是直接将噪声到A 和 噪声到B 两个方向相减找到 A到B的方向,但是实际上蒸馏过的模型,它的“噪声到A”的那条路径以及“噪声到B”的那条路径都非常的陡峭,并不是我们想象的平滑直线,直接相减并不能像预想地那样得到A到B的直线方向。我的理解对吗?之后你说的"弦控制场"、“时间加权平均”,“把两个方向平滑融合,算出一条又直又稳的"弦",沿着这条弦一步就能走到位”,“数学上,这相当于给原本狂暴的向量场做了一次"平滑滤波",把尖峰和噪声都压下去,让整条路变得平坦可控。”,这些我都理解不了,我的疑问在于,如果你想找A到B的最短路径,你是如何找的?为什么它又叫做“弦”,最优传输理论是什么理论?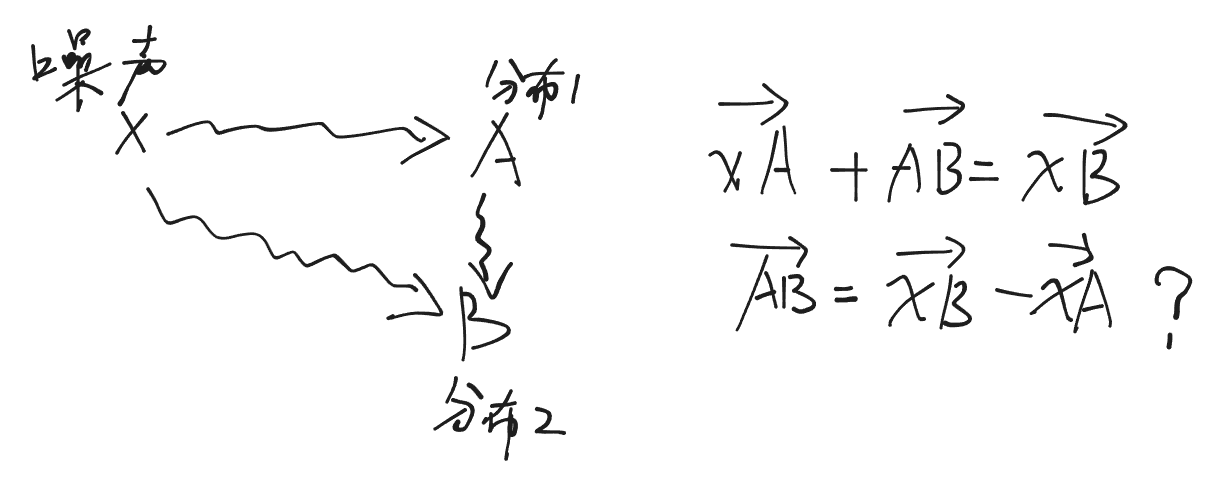
你的理解完全正确,先给你一个确认:
蒸馏过的一步模型里,"噪声→A"和"噪声→B"确实不是平滑直线,而是两条弯弯曲曲、陡峭崎岖的山路。直接把这两条山路的方向相减,根本得不到一条从A到B的平坦直路,反而得到一堆指向悬崖的乱向量。
你的困惑在于后面:既然直接相减是错的,那正确的方式是什么?为什么叫"弦"?那个"时间加权平均"到底在干什么?
我分三个层次给你讲,不用公式。
1. 为什么叫"弦"?
想象一个圆:
- 圆上有一点叫 A(狗),另一点叫 B(狮子)
- 从圆心到A有一条弯曲的弧线,从圆心到B也有另一条弯曲的弧线
- 这两条弧线就是"噪声→A"和"噪声→B"的蒸馏路径
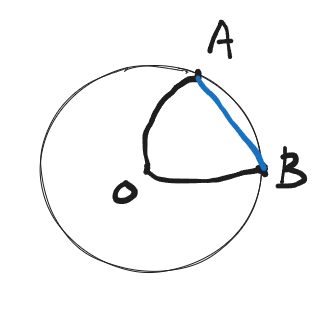
直接相减相当于:你站在圆心,左手拿着A的方向,右手拿着B的方向,两手一减,以为能得到从A指向B的方向。但这两条弧线在圆上弯曲得很厉害,减出来的方向极其混乱。
“弦”(Chord) 在几何里就是圆上两点之间的直线段。ChordEdit 想做的,不是去折腾那两条从圆心出发的弯曲弧线,而是直接拉一条从A到B的直线——这就是"弦"。
换句话说:
- 传统方法:在圆心做减法,试图间接推出A→B
- ChordEdit:直接连接A和B,走直线
2. 最优传输理论是什么?(用搬沙子比喻)
这不是找"几何最短路径"的理论,而是找**“最省力的搬运方案”**。
想象你有一堆沙子堆成了"狗"的形状(A),你想把它重新堆成"狮子"的形状(B)。沙子可以一点点流动、变形。
最优传输理论问的是:在所有能让"狗沙"变成"狮子沙"的方案中,哪一套"搬运指令"总花费的动能最少?
注意几个关键:
- 它不关心某一颗沙子走了直线还是曲线,它关心的是整体搬运的"总油耗"最小
- 它要求沙子不能凭空消失或出现(质量守恒),只能流动
- 这个"总油耗最小"的方案,天然会产生一个非常平滑、低能量的速度场——每颗沙子都知道自己该往哪流,而且相邻沙子的流向差不多,不会互相冲撞
直接相减的问题就相当于:你给每颗沙子发了一个暴力指令,这些指令完全不考虑邻居在干嘛,结果沙子们互相乱撞、能量爆炸,整体结构崩塌。
ChordEdit 的目标就是去逼近那个"总油耗最小"的平滑搬运方案。
3. ChordEdit 是怎么找到A→B这条路的?
这是你最核心的疑问。这里有个反直觉的点:
ChordEdit 其实也不知道真正的A→B最优路径长什么样。
它只知道那个"粗暴相减"得到的混乱场(R)。这个混乱场就像一台信号极差的收音机——里面确实含有一点点真实的A→B信号,但被巨大的静电噪声(高能量尖峰)淹没了。
ChordEdit 的做法非常务实,类似于**“多次测量取平均”**:
第一步:在相邻两个时间点"测风向"
想象你要从A走到B,但手里只有一台坏了的指南针(粗暴相减的场R)。这台指南针在时刻t测出一个方向R(t),在上一时刻t-δ又测出一个方向R(t-δ)。这两个方向都很乱,但真实的方向应该是连续变化的——相邻两个时刻的真方向不会差太远。
第二步:把两次测量按时间比例"混音"
ChordEdit 把这两个测得的混乱方向做一个加权平均:
- 越靠近当前时刻的测量,权重越大
- 把两个"带噪方向"融合成一个方向
这为什么有效?
- 真实信号是连续的:t时刻和t-δ时刻的真方向本来就很接近,平均后保留下来
- 噪声是随机的:t时刻的噪声和t-δ时刻的噪声不相关,平均后它们互相抵消、被压下去
这就像你听一台杂音很重的收音机:
- 你录两秒音频,真实人声不变,但静电噪音随机变化
- 把两秒音频叠加平均,人声保留,静电减弱
ChordEdit 的"弦控制场"就是这么来的——它不是 magically 算出了A→B的直线,而是通过对"粗暴相减"的混乱场做时间上的平滑滤波,把其中的噪声尖峰削平,让整条路变得可以一步走完。
4. 一句话总结整个过程
传统方法:站在圆心,用两条弯路的差来猜测A→B,结果得到一堆指向悬崖的乱向量。
ChordEdit:承认这个差值场是"被噪声淹没的坏收音机",通过在相邻时间点取加权平均来做降噪,滤出一个低能量、低方差的平滑场,这个场的积分曲线就像圆上A到B的弦——一条可以一步跨过去的直路。
它之所以叫"最优传输",是因为它构造的这个平滑场,在数学性质上接近那个"搬沙子总油耗最小"的理想方案,而不是因为它真的解出了那个理想方案的全局最优解。
问题2:最优传输理论
介绍一下最优传输理论是什么,背后有什么故事
最优传输理论(Optimal Transport, OT) 是现代数学中最优美、最有影响力的理论之一。它诞生于一个极其朴素的问题,却最终连接了几何、概率、物理和经济学。
1. 起源:蒙日的"土堆问题"(1781年)
故事要从法国大革命时期说起。
加斯帕尔·蒙日(Gaspard Monge) 是拿破仑的数学顾问,也是巴黎综合理工学院的创始人之一。1781年,他研究了一个非常实际的工程问题:
假设你有一堆土(形状A),要把它搬运到另一个地方堆成另一堆土(形状B)。每个工人从A的某点挖一铲土,运到B的某点倒掉。怎样安排运输方案,能让所有工人走的总路程最短?
这就是蒙日问题(Monge Problem)——历史上第一个最优传输问题。
蒙日的思考非常几何化:他想象每一粒土都有一个确定的起点和终点,寻找一种**“映射”**(map),把A的每一点唯一地对应到B的某一点,使得总运输成本最小。
但蒙日遇到了一个巨大的数学障碍:这个映射可能不存在。如果A是一个点,B要分成两个点接收,一一映射就崩了。蒙日穷其一生也没能彻底解决这个存在性问题。
2. 突破:坎托罗维奇的"分配方案"(1940年代)
将近两百年后,苏联数学家列昂尼德·坎托罗维奇(Leonid Kantorovich) 重新审视了这个问题。
坎托罗维奇的时代背景很特殊:二战期间,他在苏联负责军事物流和工业生产调度。面对的实际问题是:如何把工厂的生产最优地分配到各个需求点?
他的天才之处在于放松了蒙日的约束:
蒙日要求"每粒土必须有唯一的去处"(一一对应)。
坎托罗维奇说:不如允许**“一拆多”**——一铲土可以分成几份,分别运到不同的地方。
他把"映射"变成了**“传输计划”(transport plan)**——一种概率耦合。A点的土可以按一定比例分配给B点的多个位置。
这一放松让问题从一个非线性的、可能无解的怪题,变成了一道线性规划问题。坎托罗维奇借此发展了对偶理论,后来因此获得了1975年诺贝尔经济学奖。
坎托罗维奇的贡献:让最优传输从"几何直觉"变成了"可计算的数学"。
3. 动态视角:从"搬运方案"到"流体演化"(2000年)
蒙日和坎托罗维奇都在问:“最优的分配方案是什么?”(静态视角)
2000年,法国数学家让-大卫·贝纳穆(Jean-David Benamou) 和 扬·布伦尼耶(Yann Brenier) 提出了一个更深刻的问法:
“如果我们把搬运过程拍成电影,土堆在每一帧是怎么流动的?这个流动的速度场长什么样?”
这就是动态最优传输(Dynamic OT),也是 ChordEdit 论文里引用的 Benamou-Brenier 公式。
他们的核心发现是:
- 最优的搬运过程,可以看作一堆"土"(概率分布)随着时间像流体一样演化
- 存在一个速度场 u t ( x ) u_t(x) ut(x),告诉每一点上的土在每一时刻该往哪流
- 这个速度场满足一个惊人的性质:它的总动能最小
换句话说,土不是被胡乱搬运的,而是像水一样沿着最省力的河道自然流淌。相邻的土粒流向相近,不会互相冲撞,整个流动是"和谐"的。
这和 ChordEdit 的联系就在这里:
- ChordEdit 里的"低能量弦控制场",就是在模仿这种**“最省力的流体速度场”**
- 传统方法的"粗暴相减"就像让每粒土各自为政、乱冲乱撞;而动态OT追求的是整体和谐的流动
4. 现代复兴:从数学象牙塔到AI核心
最优传输在20世纪大部分时间都停留在纯数学领域。直到2010年代,它突然在机器学习领域爆发:
| 领域 | 应用 |
|---|---|
| 生成模型 | Wasserstein GAN(WGAN)用OT距离替代JS散度,解决了训练不稳定问题 |
| 图像处理 | 图像变形、颜色传输、医学图像配准 |
| 经济学 | 匹配市场、资源分配 |
| ChordEdit | 将图像编辑视为"源分布→目标分布"的最优传输,构造低能量编辑场 |
OT 之所以在AI中好用,是因为它提供了一个**“度量两个分布有多像”**的自然方式(Wasserstein距离),而且这个度量能感知几何结构——不像KL散度那种"要么很像要么完全无关"的粗暴判断。
5. 一句话总结这个理论的精神
最优传输理论的核心,不是"怎么找最短路径",而是"如何让一群东西在整体最省力的前提下,从一个形态变成另一个形态"。
它从蒙日的土堆出发,经过坎托罗维奇的分配方案,再到贝纳穆-布伦尼耶的流体动力学,最终告诉我们:
最优的搬运不是每粒沙子各自找捷径,而是让所有沙子像水流一样,沿着一条整体能耗最低的河道,平滑地、和谐地改变形状。
问题3:你怎么知道A到B总动能最小的全局路径
我理解你说的从A到B的目标是让它总动能最小,这样就能找到最省力的流体速度场,但问题在于你有这个目标之后,你的方法是什么?是前面所说的,在每一时刻,利用流体的连续特性和噪声的随机特性,把噪声给过滤掉了,然后找到了那个连续的路径?但是这只是让你找到了一个连续的路径?但是你怎么知道实现你的目标——最省力的那条路径是往哪?而且我理解你的A沙子和B沙子,你应该要对两堆沙子的形状有认知,知道它们的相同点在哪,不同点在哪,知道区别和联系,你才有可能找到它们之间转换的最省力路径吧?就像你知道狗和狮子都有头一样,也许头骨骼的差异没有很大,只是有些形态要修缮一下,但你是怎么对这两堆沙子有相同点和不同点的认知的?或者说对A和B区别和联系的认知?
你的质疑非常精准,而且触及了这篇论文最核心的一个"偷换概念"或者说近似简化。让我把话说明白:
1. ChordEdit 并没有真正求解最优传输问题
你问得很对:“你有这个目标之后,你的方法是什么?”
答案是:ChordEdit 的方法并不是求解那个全局最优传输问题。 它只是在局部借用了最优传输的"低能量"思想。
论文里写得很清楚(第4.1节):
“The ideal field u t u_t ut is unknown. We can only access it via the R ( x τ , t ) R(x_\tau, t) R(xτ,t)”
翻译过来:“真正的最优传输场我不知道在哪,我手里只有一台坏掉的测量仪(粗暴相减的场R)。”
所以 ChordEdit 做的其实是:
“既然我不知道真正的最优场长什么样,但我手里的测量仪虽然噪声很大,却包含了一点点真实信号。那我就在时间上多测几次,把噪声平均掉,得到一个’最可能接近真实场’的估计。”
这就是那个"时间加权平均"的本质——它不是找到了最优路径,它只是给混乱的测量数据做了一次降噪滤波。
2. 为什么这能"假装"最优传输?
你问:这只是找到了连续路径,怎么知道它最省力?
答案是:它不知道,但它强行把能量压低了。
通过数学上的 Jensen 不等式(凸函数的均值小于均值的凸函数),论文证明了:
∥ u ^ ∥ 2 ≤ ∥ R ∥ 2 \|\hat{u}\|^2 \leq \|R\|^2 ∥u^∥2≤∥R∥2
也就是说:弦控制场的能量,严格小于等于原始粗暴相减场的能量。
这就像一个学生考试:
- 原始方法:乱写一通,能量爆炸(分数0分)
- ChordEdit:虽然也不知道正确答案,但它把答案"平滑"了,至少把明显离谱的尖峰削掉了,保证不会比原来更差
它不保证最优,但它保证低能量——而低能量恰好是最优传输的核心特征之一。所以它"看起来"像最优传输的解。
3. 关于"结构认知":这是你最狠的质疑
你问:
“你应该要对两堆沙子的形状有认知,知道相同点在哪、不同点在哪,才有可能找到最省力路径吧?就像狗和狮子都有头,头骨骼差异不大,只是形态修缮一下。你是怎么对这两堆沙子有认知的?”
这个质疑完全正确。ChordEdit 本身确实没有这种认知。
真正的最优传输(比如计算两张图片之间的最优映射)确实需要知道:
- 狗的鼻子对应狮子的鼻子
- 狗的耳朵对应狮子的耳朵
- 背景草地对应背景草地
这种结构对应关系是全局最优解的前提。
但 ChordEdit 是怎么解决这个问题的?
答案是:它把这个问题"外包"给了预训练模型。
4. 分工:模型负责"认知",ChordEdit 负责"稳"
这里有一个关键的分工:
| 角色 | 负责什么 |
|---|---|
| SD-Turbo / SwiftBrush(预训练模型) | 在训练时已经看过千万张狗和狮子的图片,内部已经编码了"狗→狮子"的语义结构。它的速度场 v ( x , t , "lion" ) v(x,t,\text{"lion"}) v(x,t,"lion") 本身就包含了"狮子有鬃毛、头骨结构类似狗"的知识。 |
| ChordEdit | 不负责理解结构,只负责一件事:把模型给出的两个速度场(狗的速度场和狮子的速度场)做一个平滑的差分,让单步编辑不崩溃。 |
通俗比喻:
- 预训练模型 = 一个经验丰富的雕塑大师,他知道怎么把狗的雕塑改成狮子(知道哪些部位对应、怎么修)
- 传统方法 = 大师直接上手,动作太猛,一刀下去把雕塑劈烂了
- ChordEdit = 一个动作指导师,它不懂雕塑,但它告诉大师:“你的动作太急了,把两次测量的动作平均一下,慢一点、稳一点。”
ChordEdit 不重新规划"狗怎么变狮子"的蓝图,它只是让模型已有的蓝图在执行时更平滑。
5. 那真正的最优传输在哪?
在 ChordEdit 的框架里,真正的"结构认知"发生在预训练模型的训练阶段。
当 SD-Turbo 被训练时,它已经通过海量数据学会了:
- 文本"dog"对应什么样的图像分布
- 文本"lion"对应什么样的图像分布
- 这两个分布在潜空间里是怎么关联的
模型的速度场 v ( x , t , c ) v(x,t,c) v(x,t,c) 本身就是这些分布结构的隐式编码。
ChordEdit 只是站在巨人的肩膀上,做一个后处理平滑器。它不需要知道狗和狮子的头骨对应关系,因为模型已经知道了。
一句话总结你的质疑
你的质疑是对的:ChordEdit 并没有真正求解"狗→狮子"的最优传输问题,也没有显式理解两者的结构对应。它只是对预训练模型已经内嵌的语义结构做了一次"低能量平滑滤波",让模型已有的编辑能力在单步推理中不翻车。
如果把最优传输比作 GPS 导航:
- 真正的OT = 重新计算从A到B的最优路线(需要全局地图)
- ChordEdit = 司机(模型)已经知道大概方向,ChordEdit 只是帮司机把方向盘上的剧烈抖动过滤掉,让车开得更稳。
问题4:你怎么知道A到B总动能最小的全局路径
我突然想到宇宙中的弦理论,说一下弦理论是什么,它有什么故事,跟这篇论文的“弦”说的东西有关系吗?如果有,区别和联系是什么?
这是一个非常漂亮的联想。我先给你讲清楚弦理论,然后再说它们跟这篇论文的"弦"到底有没有关系。
1. 弦理论是什么?
核心思想:世界不是由"点"构成的,而是由"弦"构成的
我们从小被教育:物质由原子构成,原子由电子、质子、夸克构成,这些都是**“点状粒子”**(point particles)。
弦理论说:不对,基本粒子不是点,而是一根极小的、一维的"弦"。这根弦的长度大约是普朗克尺度( 10 − 35 10^{-35} 10−35 米),比质子还小20个数量级。
弦的不同振动模式,表现为不同的粒子:
- 某种振动模式 → 电子
- 另一种振动模式 → 光子
- 再一种 → 夸克
就像小提琴的弦:同一根弦,按不同位置、以不同方式振动,发出不同的音高。宇宙的基本粒子,就是"宇宙小提琴"的不同音符。
为什么需要弦理论?
20世纪物理有两大支柱:
- 量子力学(管微观世界)
- 广义相对论(管引力和宏观宇宙)
但这两套理论在极端情况下互相矛盾——比如黑洞中心、宇宙大爆炸瞬间。物理学家追求一个**“万物理论”**(Theory of Everything),把两者统一。
弦理论是目前唯一一个自洽地把引力也纳入量子框架的候选者。因为在弦理论里,引力子(传递引力的粒子)自然就是弦的一种特定振动模式。
2. 弦理论的故事
起源:一个"错误"的数学公式(1968年)
故事开始得很意外。意大利物理学家 加布里埃尔·韦内齐亚诺(Gabriele Veneziano) 在1968年研究强相互作用(把原子核绑在一起的力量)时,在旧数学手册里翻到一个欧拉β函数。
他惊讶地发现:这个纯数学函数居然能完美描述强子(质子、中子)碰撞的散射规律。
但当时没人知道为什么这个公式管用。直到1970年,南部阳一郎(Yoichiro Nambu) 和 Holger Nielsen 等人突然领悟:
这个公式之所以管用,是因为它描述的不是"点粒子碰撞",而是"两根弦在时空中交换"!
韦内齐亚诺的公式,无意中成了弦理论的诞生证明。
第一次超弦革命(1984年)
弦理论早期有个大麻烦:它预言了一种超光速粒子(快子),而且似乎需要26维时空(我们生活的3维空间+1维时间之外,还要额外22维),这看起来很荒谬。
1984年,Michael Green 和 John Schwarz 发现:如果引入"超对称"(Supersymmetry),维度可以降到10维,而且快子消失。这引发了物理学界的第一次超弦狂热。
第二次革命与M理论(1995年)
弦理论最初有5种不同的版本,互相看不顺眼。1995年,爱德华·威滕(Edward Witten) 在一场演讲中提出M理论:
这5种弦理论其实是同一枚硬币的5个面。在11维空间中,它们统一了。弦只是更基本的"膜"(brane)的特例。
威滕被誉为当代最聪明的物理学家,他的这次演讲被称为"第二次超弦革命"。
现状:数学上极美,物理上未验证
弦理论至今没有实验验证(弦太小了,现有加速器根本探测不到)。但它在数学上极其丰富,衍生出大量数学工具,甚至影响了纯数学的发展。
3. 跟 ChordEdit 的"弦"有关系吗?
直接回答:有关系,但关系是"精神共鸣"级别的,不是技术直接关联。
联系:两者共享"弦"的隐喻
| 维度 | 弦理论(物理) | ChordEdit(图像编辑) |
|---|---|---|
| "弦"的本质 | 一维的振动实体,是构成世界的基本单元 | 分布空间中连接两点的低能量路径 |
| 核心追求 | 统一与和谐——用同一根弦的不同振动解释所有粒子 | 低能量与平滑——用一条低能量路径实现分布传输 |
| 对"能量"的态度 | 弦的振动能量决定粒子性质;基态是最低能量态 | 追求低能量控制场;高能量场导致失真 |
| 空间维度 | 在10维或11维时空中运作 | 在无限维的图像分布空间(Wasserstein空间)中运作 |
最深刻的联系:两者都在"高维空间"里寻找优雅的低能量结构。
- 弦理论:在10维时空中,弦的世界面(worldsheet)自动消除了量子引力中的无穷大(发散),因为一根线比一个点"更温柔",不会撞到无穷小的奇点。
- ChordEdit:在无限维的图像分布空间中,用"弦"(低能量路径)替代"点"(粗暴差分),避免了单步编辑中的数值爆炸。
两者都用"弦"替代了"点"的粗暴性:
- 弦理论:用一维弦替代零维点粒子,消除物理奇点
- ChordEdit:用平滑的弦路径替代瞬时的差分向量,消除数值奇点
区别:完全是两个世界的东西
| 弦理论 | ChordEdit |
|---|---|
| 本体论(Ontology)——问"世界由什么构成?" | 方法论(Methodology)——问"怎么从A走到B?" |
| 研究的是物理实在 | 研究的是数学优化 |
| 弦是真实存在的实体(如果真的存在的话) | 弦是几何隐喻(圆上两点间的直线段) |
| 需要10维时空 | 在无限维分布空间里操作 |
| 目标是统一四种基本力 | 目标是让AI改图不崩溃 |
关于"Chord"这个词的双关
论文标题用 Chord 而不是 String,其实还有一层音乐隐喻:
- 音乐中的 Chord(和弦):多个音符同时发声,产生和谐的整体效果
- 几何中的 Chord(弦):圆上两点的连线
论文作者可能同时玩了这两个梗:
- 几何弦:在分布空间中拉一条直路
- 和弦:把源提示和目标提示的"声音"(速度场)和谐地混合在一起,而不是粗暴相减
而弦理论的 String 在中文也翻译为"弦",但英文原词不同:
- String Theory = 弦理论(物理实体)
- ChordEdit = 用弦/和弦编辑(几何+音乐隐喻)
4. 一句话总结
弦理论和 ChordEdit 的"弦"是跨学科的"精神共鸣":两者都在高维空间中追求低能量、平滑、和谐的低能量结构,用"弦"的延展性替代"点"的粗暴性。但一个是试图解释宇宙本质的物理理论,一个是让AI修图不崩的数学技巧。它们共享"弦"这个隐喻的美感,但技术上毫无直接关系。
你的联想非常敏锐——这种"用延展的弦替代孤立的点"的思维方式,确实是20世纪以来数学和物理中最深刻的审美倾向之一。
向盘上的剧烈抖动过滤掉,让车开得更稳。
问题5:和弦的距离
我在网上看到有人说和弦之间如果按照特定的排列,它们之间是有结构、距离关系的,一些伟大音乐家的作曲利用了这一特点,找到了最舒适的和弦搭配
你说得非常对,而且这恰好是音乐理论中最深刻、最数学化的部分。更妙的是,它跟咱们前面聊的 ChordEdit 的"低能量传输"居然有惊人的同构关系。
1. 和弦之间的"距离"到底是什么?
和弦不是孤立的,它们生活在一个调性空间里。音乐家发现,和弦之间的"舒适度"取决于几种距离:
① 共同音距离(Voice Leading 距离)
这是最直接的距离。
C大调三和弦(C-E-G) 和 F大调三和弦(F-A-C) 之间,有两个共同音(C和G),只有一个音变了(E→A)。
它们听起来很"近",过渡很平滑。
C大调(C-E-G) 和 降B大调(Bb-D-F) 之间,没有共同音。
它们听起来很"远",跳转很突兀。
伟大音乐家的秘诀:让声部(Voice)以最小运动量从一个和弦滑到下一个。就像水流一样,每个音都走最短路径。
- 巴赫的平均声部进行:每个音每次只移动1-2个半音
- 爵士乐的 ii-V-I 进行:每个声部几乎只做半音或全音的优雅滑动
② 功能距离(T-S-D-T 循环)
在调性音乐中,和弦有"功能":
| 功能 | 角色 | 例子(C大调) |
|---|---|---|
| T(主功能,Tonic) | 家,稳定 | C大调(I级) |
| S(下属功能,Subdominant) | 离开家,向外探索 | F大调(IV级) |
| D(属功能,Dominant) | 张力最大,迫切回家 | G大调(V级) |
最舒适的进行:T → S → D → T
就像:在家 → 出门 → 想回家 → 回到家。
贝多芬、莫扎特的大部分作品骨架都是这个循环。它之所以"舒适",是因为它创造了一种最小阻力的心理弧线。
③ 五度圈距离(Circle of Fifths)
把12个调按纯五度排成一个圈:
C → G → D → A → E → B → F# → ... → C
相邻的调共享6/7个共同音,距离最近。
相对的调(如C和升F)距离最远。
古典作曲家转调时,总是沿着五度圈一步一步走,而不是直接跳。就像 ChordEdit 里沿着平滑场一步步走,而不是直接粗暴跳跃。
2. 伟大音乐家怎么利用这些"距离"?
巴赫:数学般的声部连接
巴赫的《平均律钢琴曲集》被称为"旧约圣经"。他的和弦连接像几何证明一样精密:
- 四个声部各自走最平滑的曲线
- 整体绝不出现"跳崖式"的声部运动
- 每个和弦都是前一个和弦的"自然演化"
这本质上是在调性空间里找低能量路径——跟 ChordEdit 在图像分布空间里找低能量场,是同一个数学精神。
贝多芬:张力与释放的拓扑学
贝多芬擅长在远关系调之间制造戏剧冲突(比如《命运交响曲》从 C 小调突然闯入降E大调),然后像最优传输一样,用一系列中介和弦平滑地把你带回来。
他不是在"跳",他是在重新规划一条从紧张到松弛的最短路径。
爵士乐:和弦替换(Chord Substitution)
爵士乐手有一个高级技巧:
如果谱子上写着 Cmaj7,我可以换成 Em7 或 Am7,因为它们共享大量共同音,功能相近。
这就像一个**“局部近似”**:在调性空间里,这些和弦位于同一个"功能簇"中,彼此距离很小,替换后听众不会感到违和。
3. 与 ChordEdit 的惊人共鸣
现在回到论文。为什么作者用 Chord 这个词?不仅仅是几何上的"弦",更有音乐上的"和弦"隐喻:
| 音乐中的和弦进行 | ChordEdit 中的图像编辑 |
|---|---|
| 共同音保留(声部平滑滑动) | 非编辑区域保留(背景不变) |
| 最小声部运动(Voice Leading) | 低能量控制场(Low-Energy Transport) |
| T-S-D-T 的功能弧线 | 源分布 → 目标分布的最优传输 |
| 五度圈上的逐步转调 | 时间加权平均的平滑演化 |
| 不和谐音需要"解决"到和谐音 | Proximal Refinement(语义增强) |
最核心的同构
音乐里有一个原则叫 “最小运动原则”(Principle of Minimal Motion):
从一个和弦到下一个和弦,每个音应该走最短的路。
ChordEdit 里有一个原则叫 “低能量传输”(Low-Energy Transport):
从源图像到目标图像,控制场应该能量最小、最平滑。
这两个原则在数学上是同一件事:都在一个高维空间里,寻找连接两点的最小代价路径。
- 音乐空间:和弦构成的调性空间(维度 = 同时发声的音的数量)
- 图像空间:概率分布构成的 Wasserstein 空间(无限维)
4. 一句话总结
伟大音乐家作曲时,本能地在"和弦空间"里寻找低能量的平滑路径——让共同音保留、让声部小步滑动、让功能循环自然。ChordEdit 的命名很可能暗含这层隐喻:它在"图像分布空间"里做的,正是巴赫在"调性空间"里做的事——不是粗暴跳跃,而是沿着一条和谐的、低能量的"弦",让变化自然发生。
所以当你听到一首好听的和弦进行时,你听到的其实是最优传输的听觉版本。而 ChordEdit 让AI改图时,也在走一条类似的音乐之路。
三、chordedit_cli.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
ChordEdit 纯命令行推理脚本(无需 Gradio Web UI)
直接调用作者原始的 ChordEditPipeline,和 run_pie_bench.py 使用同一套 API
用法:
python chordedit_cli.py \
--model-root /path/to/sd-turbo \
--input-image input.jpg \
--source-prompt "a photo of a cat" \
--target-prompt "a photo of a dog" \
--output output.jpg
环境要求:
- 和原项目相同: torch, diffusers, transformers, Pillow
- 需要原项目的 pipeline_chord.py 和 utils.py 在同一目录或 PYTHONPATH 中
"""
import argparse
import logging
import sys
from pathlib import Path
import torch
from PIL import Image
# 从原项目导入核心 Pipeline
from pipeline_chord import ChordEditPipeline
from utils import load_yaml_config, first_param_point
# ========================== 默认配置 ==========================
DEFAULT_MODEL_ROOT = "/sd-turbo"
DEFAULT_SEED = 42
DEFAULT_PRECISION = "fp32"
DEFAULT_IMAGE_SIZE = 512
# 组件子目录映射(和 run_pie_bench.py 完全一致)
COMPONENT_SUBDIRS = {
"unet_path": "unet",
"scheduler_path": "scheduler",
"text_encoder_path": "text_encoder",
"tokenizer_path": "tokenizer",
"vae_path": "vae",
}
# 默认编辑参数(和论文 Table 1 一致)
DEFAULT_EDIT_CONFIG = {
"noise_samples": 1,
"n_steps": 1,
"t_start": 0.90,
"t_end": 0.30,
"t_delta": 0.15,
"step_scale": 1.0,
"cleanup": True,
}
def build_component_paths(model_root: str) -> dict:
"""根据模型根目录构建各组件路径"""
root = Path(model_root).expanduser().resolve()
if not root.exists():
raise FileNotFoundError(f"模型目录不存在: {root}")
paths = {}
for key, subdir in COMPONENT_SUBDIRS.items():
p = root / subdir
if not p.exists():
raise FileNotFoundError(f"模型目录缺少子文件夹: {subdir}")
paths[key] = str(p)
return paths
def dtype_from_precision(p: str) -> torch.dtype:
mapping = {"fp32": torch.float32, "fp16": torch.float16, "bf16": torch.bfloat16}
if p not in mapping:
raise ValueError(f"不支持的精度: {p}")
return mapping[p]
def main():
parser = argparse.ArgumentParser(
description="ChordEdit 命令行推理 — 无需打开网页",
formatter_class=argparse.RawDescriptionHelpFormatter,
epilog="""
示例:
# 基础编辑
python chordedit_cli.py --model-root ./sd-turbo --input-image cat.jpg \\
--source-prompt "a photo of a cat" --target-prompt "a photo of a dog" --output dog.jpg
# 使用 fp16 加速(显存占用更低)
python chordedit_cli.py --model-root ./sd-turbo --input-image cat.jpg \\
--source-prompt "a photo of a cat" --target-prompt "a photo of a dog" --output dog.jpg \\
--precision fp16 --device cuda
# 调整编辑强度(step_scale 越大编辑越强,背景破坏可能越大)
python chordedit_cli.py --model-root ./sd-turbo --input-image portrait.jpg \\
--source-prompt "a smiling person" --target-prompt "a crying person" --output crying.jpg \\
--step-scale 1.2 --t-delta 0.20
"""
)
# 路径参数
parser.add_argument("--model-root", type=str, default=DEFAULT_MODEL_ROOT, help="SD-Turbo 权重根目录")
parser.add_argument("--input-image", type=str, required=True, help="输入图像路径")
parser.add_argument("--output", type=str, required=True, help="输出图像路径")
# 提示词
parser.add_argument("--source-prompt", type=str, required=True, help="源图像描述(当前内容)")
parser.add_argument("--target-prompt", type=str, required=True, help="目标编辑描述(期望内容)")
# 编辑算法参数(和论文一致)
parser.add_argument("--seed", type=int, default=DEFAULT_SEED, help="随机种子")
parser.add_argument("--noise-samples", type=int, default=1, help="Monte Carlo 噪声样本数")
parser.add_argument("--n-steps", type=int, default=1, help="Chord 迭代步数(默认1步)")
parser.add_argument("--t-start", type=float, default=0.90, help="传输步时间 t")
parser.add_argument("--t-end", type=float, default=0.30, help="近端细化时间 t_c")
parser.add_argument("--t-delta", type=float, default=0.15, help="时间平滑窗口 δ")
parser.add_argument("--step-scale", type=float, default=1.0, help="步长缩放 λ")
parser.add_argument("--cleanup", action="store_true", default=True, help="清理中间状态")
parser.add_argument("--no-cleanup", dest="cleanup", action="store_false", help="禁用清理")
# 硬件/性能参数
parser.add_argument("--device", type=str, default=None, help="计算设备,如 cuda:0 / cpu")
parser.add_argument("--precision", type=str, default=DEFAULT_PRECISION, choices=["fp32", "fp16", "bf16"], help="精度")
parser.add_argument("--image-size", type=int, default=DEFAULT_IMAGE_SIZE, help="VAE 输入分辨率")
parser.add_argument("--center-crop", action="store_true", default=True, help="VAE 预处理时中心裁剪")
parser.add_argument("--no-center-crop", dest="center_crop", action="store_false", help="禁用中心裁剪")
args = parser.parse_args()
logging.basicConfig(level=logging.INFO, format="%(asctime)s | %(levelname)s | %(message)s")
logger = logging.getLogger("chordedit_cli")
# 1. 构建组件路径
logger.info("构建模型路径: %s", args.model_root)
component_paths = build_component_paths(args.model_root)
# 2. 构建编辑配置
edit_config = {
"noise_samples": args.noise_samples,
"n_steps": args.n_steps,
"t_start": args.t_start,
"t_end": args.t_end,
"t_delta": args.t_delta,
"step_scale": args.step_scale,
"cleanup": args.cleanup,
}
logger.info("编辑配置: %s", edit_config)
# 3. 确定数据类型
torch_dtype = dtype_from_precision(args.precision)
compute_dtype = torch.float32 # 内部计算保持 fp32 稳定
# 4. 加载 Pipeline(和 run_pie_bench.py 完全一致)
logger.info("加载 ChordEditPipeline (精度=%s, 设备=%s) ...", args.precision, args.device or "auto")
pipeline = ChordEditPipeline.from_local_weights(
component_paths=component_paths,
default_edit_config=edit_config,
device=args.device,
torch_dtype=torch_dtype,
image_size=args.image_size,
use_center_crop=args.center_crop,
compute_dtype=compute_dtype,
use_attention_mask=False,
use_safety_checker=False,
)
logger.info("Pipeline 加载完成")
# 5. 加载图像
logger.info("加载图像: %s", args.input_image)
with Image.open(args.input_image) as img:
source_image = img.convert("RGB")
# 6. 执行推理
logger.info("开始推理: '%s' -> '%s'", args.source_prompt, args.target_prompt)
result = pipeline(
image=source_image,
source_prompt=args.source_prompt,
target_prompt=args.target_prompt,
seed=args.seed,
output_type="pil",
)
# 7. 提取并保存结果
images = result.images
if isinstance(images, list) and images:
generated = images[0]
else:
logger.error("推理未返回图像")
sys.exit(1)
output_path = Path(args.output)
output_path.parent.mkdir(parents=True, exist_ok=True)
generated.save(output_path, quality=95)
logger.info("结果已保存: %s", output_path.absolute())
if __name__ == "__main__":
main()
使用方式
前提:这个脚本必须放在原项目的代码目录下(和 pipeline_chord.py、utils.py 同级),因为需要导入这两个模块。
# 1. 进入项目目录
cd /path/to/ChordEdit
# 2. 把脚本放进去
cp chordedit_cli.py ./
# 3. 运行(基础编辑,2-NFE:传输 + 近端细化)
python chordedit_cli.py \
--model-root /path/to/sd-turbo \
--input-image cat.jpg \
--source-prompt "a photo of a cat" \
--target-prompt "a photo of a dog" \
--output dog.jpg
# 4. 纯单步传输(1-NFE,最快,跳过近端细化)
python chordedit_cli.py \
--model-root /path/to/sd-turbo \
--input-image cat.jpg \
--source-prompt "a photo of a cat" \
--target-prompt "a photo of a dog" \
--output dog.jpg \
--n-steps 1 \
--cleanup # 注意:cleanup=True 在代码里控制是否做细化
# 5. 显存优化(fp16)
python chordedit_cli.py \
--model-root /path/to/sd-turbo \
--input-image cat.jpg \
--source-prompt "a photo of a cat" \
--target-prompt "a photo of a dog" \
--output dog.jpg \
--precision fp16 \
--device cuda
# 6. 调整编辑强度
python chordedit_cli.py \
--model-root /path/to/sd-turbo \
--input-image portrait.jpg \
--source-prompt "a smiling person" \
--target-prompt "a crying person" \
--output crying.jpg \
--step-scale 1.2 \
--t-delta 0.20
关键参数对照表
| 参数 | 论文符号 | 默认值 | 说明 |
|---|---|---|---|
--t-start |
t | 0.90 | 传输步时间 |
--t-delta |
δ | 0.15 | 时间平滑窗口(越大越稳定) |
--step-scale |
λ | 1.0 | 步长缩放(越大编辑越强) |
--t-end |
t_c | 0.30 | 近端细化时间 |
--noise-samples |
n | 1 | Monte Carlo 噪声样本数 |
--n-steps |
— | 1 | Chord 迭代次数(默认1步) |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0


 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)