AMD Hello-ROCm 学习活动笔记-第一天部署和运行Gemma4大模型
题记
在Datawhale微信公众号上看到6月有关大模型专题学习,其中AMD中文教程:Hello-ROCm,正好近来空闲时间比较多,可以利用这个机会,深入实操有关大模型的微调相关的事宜,深入理解数据处理、训练、效果对比。
第一天部署和运行Gemma4大模型实操记录
第一天属于入门体验。没有什么特别的内容,主要是环境的部署和Gemma4的运行。基本上是按照教程一路走下来。现在在云上部署确实方便很多。
云环境简介
这次的Datawhale组织的AMD Hello-ROCm组队学习环境是AMD 云环境平台的算力资源+魔搭,需要注册这2网站的账号,登陆后可以兑换100小时的算力。
自己的实操记录
由于是按照教程照猫画虎,一步一步操作下来的,没有什么特别的。简单记录一下自己的操作结果。
1、检查当前 GPU 是否可用
在终端执行amd-smi命令。环境执行结果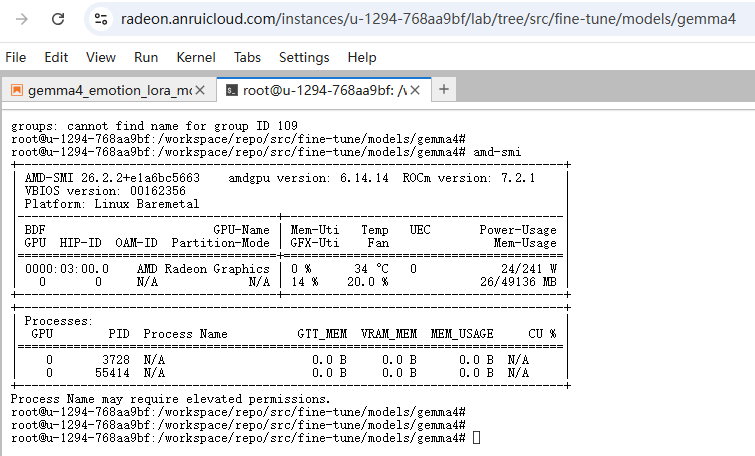
2、确认 PyTorch 能识别 AMD GPU
在终端执行python -c "import torch; print('PyTorch:', torch.__version__); print('ROCm available:', torch.cuda.is_available()); print('Device:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')",执行结果如下: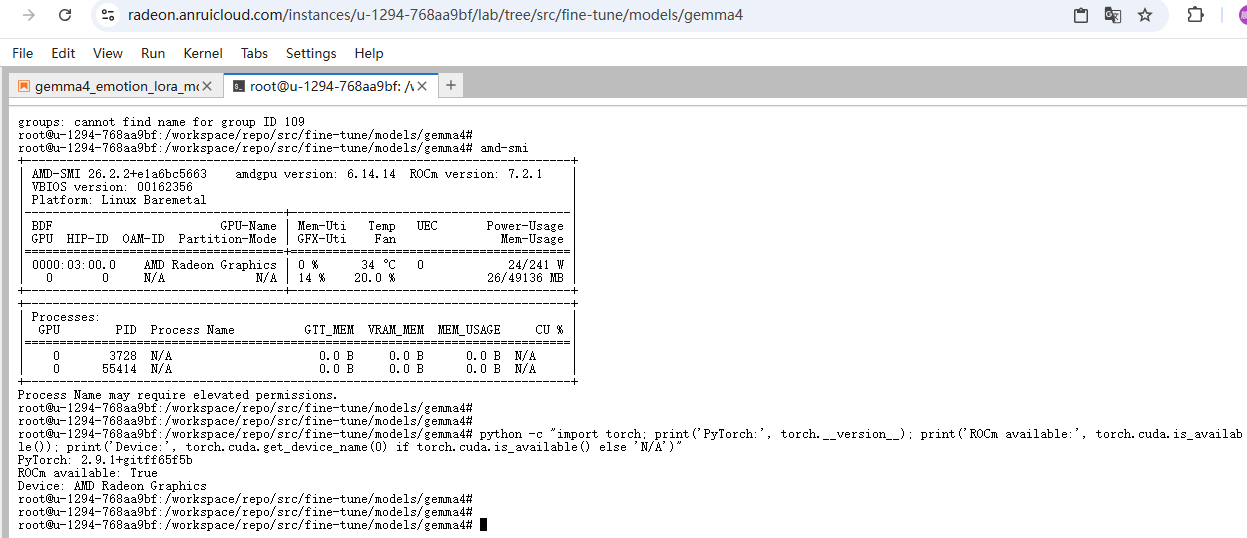
3、下载 Gemma4 模型
3.1 提升国内环境下的依赖下载速度,先把 pip 源切换到腾讯云镜像
在终端执行pip config set global.index-url https://mirrors.cloud.tencent.com/pypi/simple/,执行结果如下: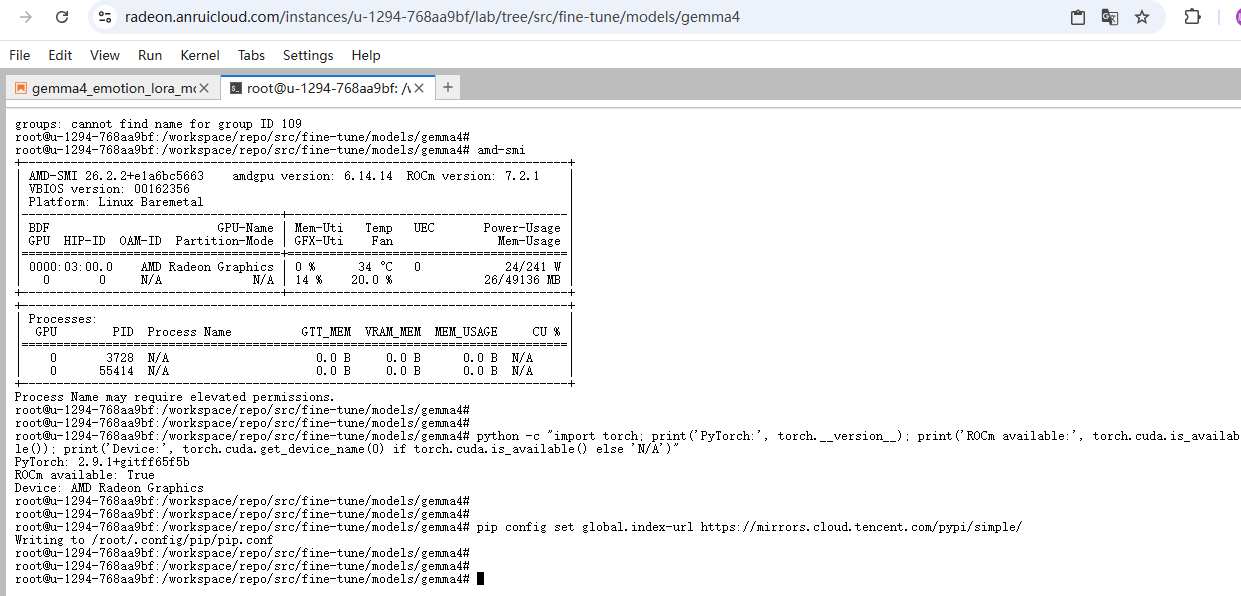
3.2 安装魔搭ModelScope
在终端执行pip install modelscope,执行结果如下: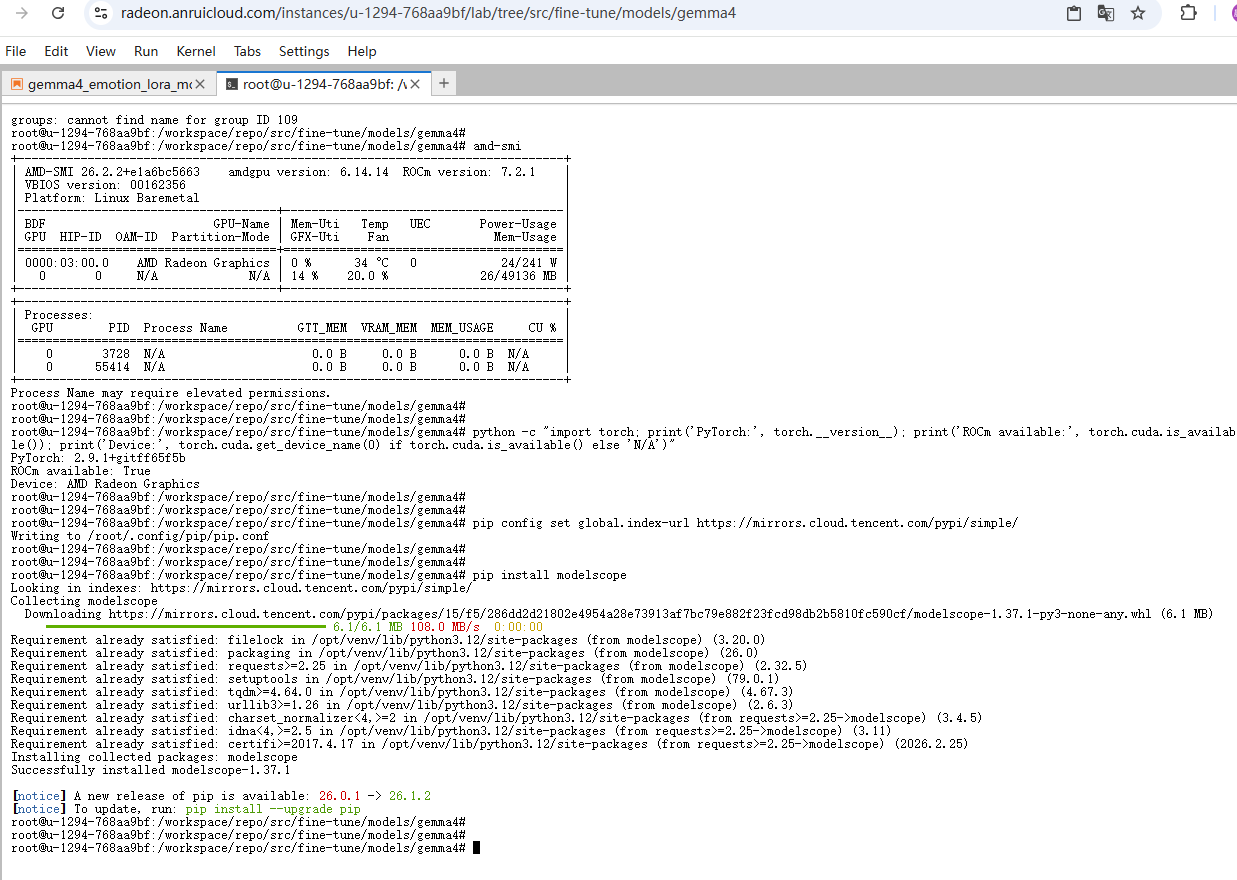
3.3 下载 Gemma4 模型到当前目录
在终端执行modelscope download --model google/gemma-4-E4B-it --cache_dir "./models,执行结果如下: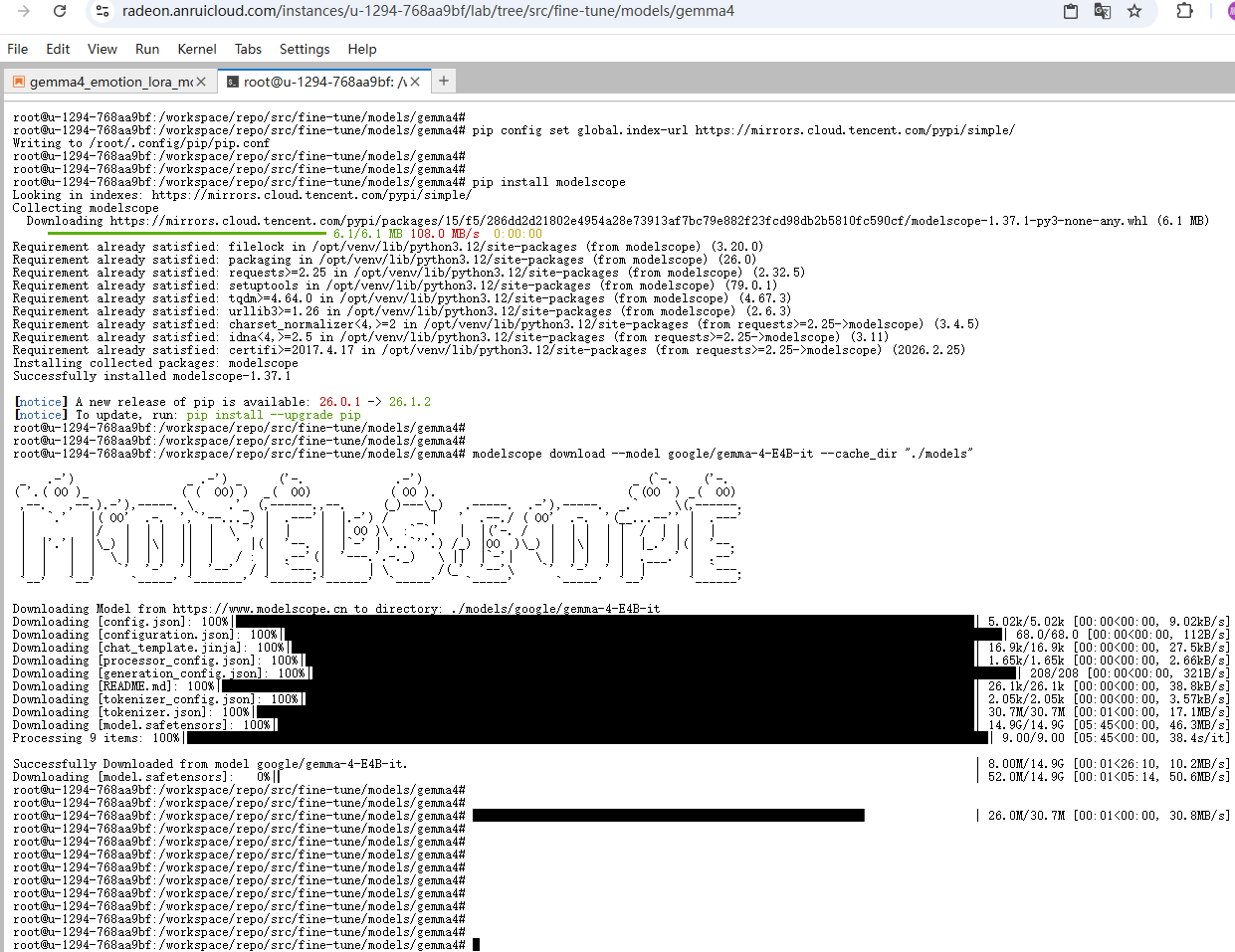
需要注意的是,实际执行的结果和教程给示例有出入,不一定会在终端看到**100%**的字样,只要能看到终端的命令行提示符,就代表安装成功。
3.4 确认 Gemma4 模型模型文件完整下载成功
在终端执行ls -lh ./models/google/gemma-4-E4B-it/,执行结果如下: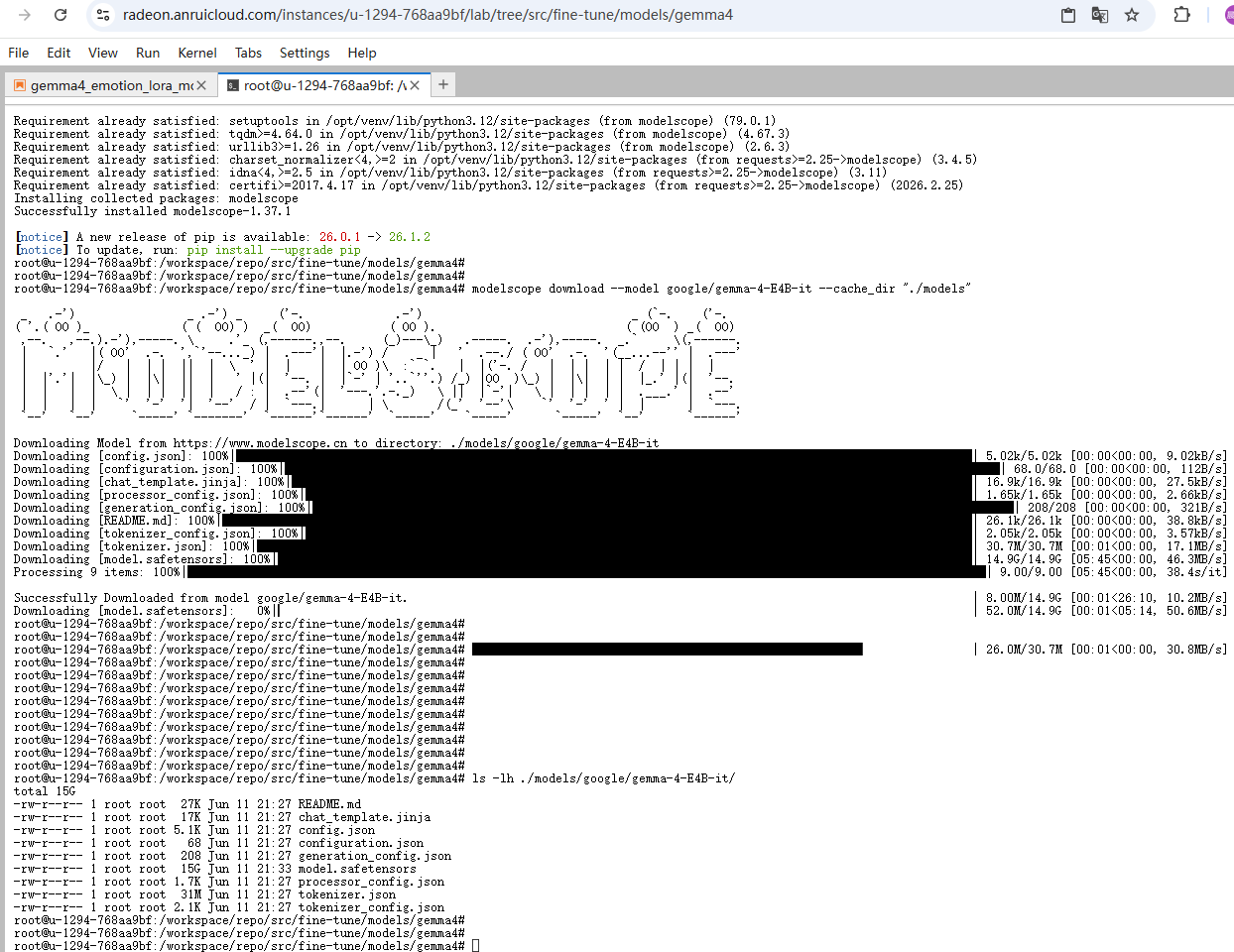
- 启动 vLLM 服务
4.1 在终端执行
uv pip uninstall torchvision # 经测试,在该云环境中,需卸载重新安装这个库才能正常使用
uv pip install vllm torchvision \
--no-cache \
--index-url https://mirrors.aliyun.com/pypi/simple/ \
--extra-index-url https://wheels.vllm.ai/rocm/ \
-U
执行结果如下: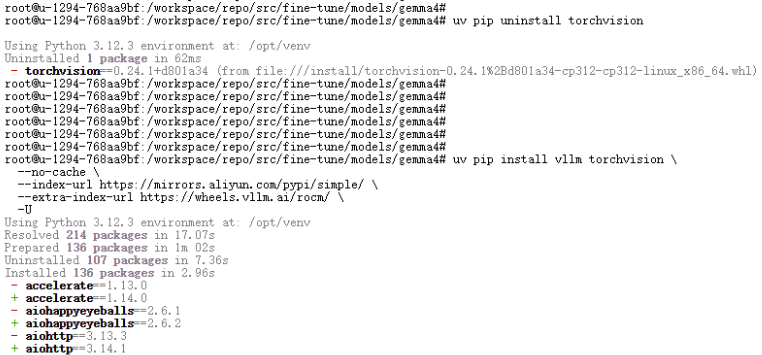
4.2 启动vllm
在终端执行
vllm serve ./models/google/gemma-4-E4B-it/ --served-model-name gemma-4-E4B-it
执行结果如下: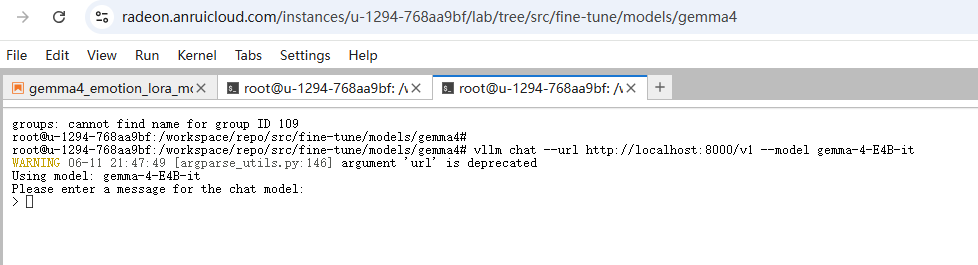
4.3 打开新终端进行对话测试
在终端执行
vllm chat --url http://localhost:8000/v1 --model gemma-4-E4B-it
执行结果如下:
注意事项
1、实验完成后,记得关闭云环境的实例,不然后一直计算算力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)