Harness Engineering 如何让智能体可靠落地
AI 模型已经能够生成百万行级别的代码。但真正的挑战,正在从“如何让它写得更好”,转向“如何让它在复杂工程环境中稳定、可靠、可控地工作”。
围绕 AI 智能体构建约束、反馈与控制系统的这一套方法论,正在成为工程实践中的新范式。它被称为 Harness Engineering,也可以理解为“驾驭工程”。
它解决的核心问题是:当 AI Agent 拥有了强大的代码生成能力后,如何确保其输出的可靠性、一致性和长期可维护性。
harness engineering is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent will not make that mistake again in the future. —— Mitchell Hashimoto
什么是 Harness Engineering?
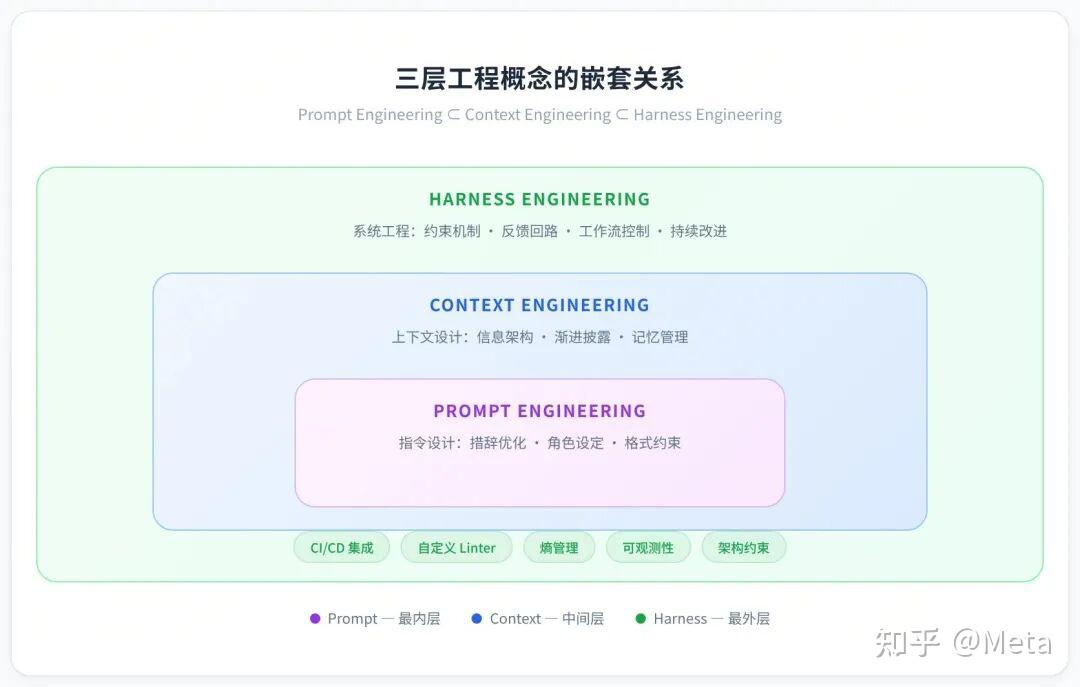
Harness Engineering 并不是凭空出现的,它是 Prompt Engineering 和 Context Engineering 的自然延伸。三者构成嵌套关系。
大模型能力越来越强之后,很多团队会自然走过三个阶段。

Prompt Engineering:开发者主要关心怎么把问题问清楚,怎么让模型按照指定格式输出,怎么通过 few-shot 示例提升效果。这个阶段适合问答、总结、改写、分类、结构化抽取等相对明确的任务。关注:Prompt 的措辞、格式、示例
Context Engineering:随着业务知识、代码仓库、用户历史、工具描述和外部数据源不断加入,系统的核心问题变成:如何在有限上下文窗口内,把最有价值的信息组织给模型。RAG、Memory、Context Compression、动态上下文路由都属于这个阶段的重要能力。关注:文档、代码片段、历史对话
Harness Engineering:Agent 不再只是读取上下文后生成答案,而是会在多轮循环中持续行动。它需要知道当前任务状态、可以使用哪些工具、每个工具有什么权限、执行结果是否可信、失败后如何恢复、是否需要人工确认、最终结果是否满足验收标准,本质上就是怎么让 Agent 可靠工作。关注:约束、反馈回路、控制系统
Prompt 和 Context 更偏输入侧优化,而 Harness 更偏运行时工程。它关注的是 Agent 作为一个可执行系统时,外部工程环境如何设计。
Harness 与 Agent 架构的关系?
一个典型 Agent 架构通常包含模型、提示词、记忆、规划器、工具调用、执行器等模块。
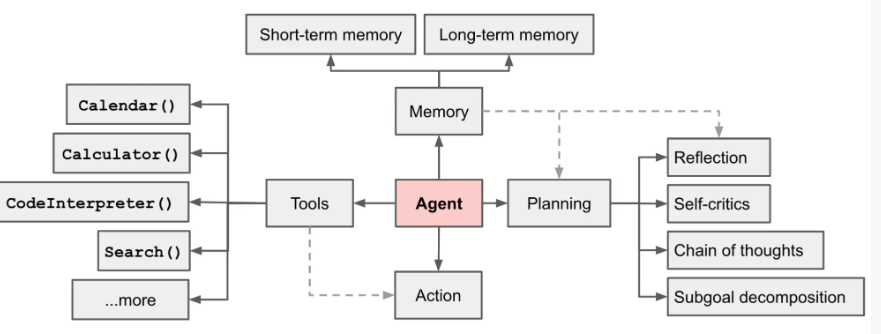
Harness 更关注这些模块之外的运行秩序,例如任务边界、权限控制、失败检测、日志观测、评估反馈、人工介入、沙箱隔离和回滚机制。
Phil Schmid 曾打过一个很形象的比方:如果把大模型看作 CPU,它具备强大的计算、推理和生成能力;那么 Agent 就像是在 CPU 之上组合了内存、状态、工具调用、任务规划和执行流程的一个“可运行系统”。但一个能运行的系统,并不等于一个能长期稳定运行的系统。Harness 更像是这个系统外层的 OS:它负责资源调度、权限控制、异常处理、状态管理、执行监控、反馈回路和恢复机制。
Mtrajan 的区分更直接:Context Engineering 管的是"给 Agent 看什么",Harness Engineering 管的是"系统怎么防崩、怎么量化、怎么修".
换句话说,Agent 让模型具备行动能力,而 Harness 让这种行动能力具备工程秩序。没有 Harness,Agent 可能只是一个能力很强但边界模糊的执行单元;有了 Harness,它才更接近一个可以被持续运行、观测、约束和纠偏的生产级系统。

为什么需要Harness Engineering?
上面说到Harness Engineering核心是确保Agent输出的可靠性、一致性和长期可维护性。那么我们看下Agent 的典型失败模式:
失败模式 1:试图一步到位(One-shotting)
Agent 倾向于在一个会话里把所有功能都做完。结果是上下文窗口耗尽,留下一堆没有文档的半成品代码,下一个会话启动时只能花大量时间猜测之前发生了什么
失败模式 2:过早宣布胜利
在项目后期,当部分功能已经完成后,Agent 会环顾四周,看到已有进展就直接宣布任务完成——即使还有大量功能未实现。
失败模式 3:过早标记功能完成
在没有明确提示的情况下,Agent 写完代码就标记为完成,却没有做端到端测试。单元测试或 curl 命令通过了不代表功能真正可用。
此外,智能体还有一个危险特性:它非常擅长模式复制。代码库里有什么模式,它就忠实地复制并放大 ——包括坏模式和架构漂移。这意味着不加约束的 Agent 会以惊人的速度积累技术债务。
Harness Engineering 的核心能力?
如果说 Agent 架构解决的是“智能体如何行动”,那么 Harness Engineering 解决的是“如何让这种行动能力在真实工程环境中稳定释放”。
结合 LangChain、OpenAI 以及实际 Agent 产品的落地经验来看,Harness Engineering 并不是给 Agent 再套一层复杂框架,而是在 Agent 运行过程中补齐那些传统 Demo 很少考虑、但生产系统必须具备的工程能力。
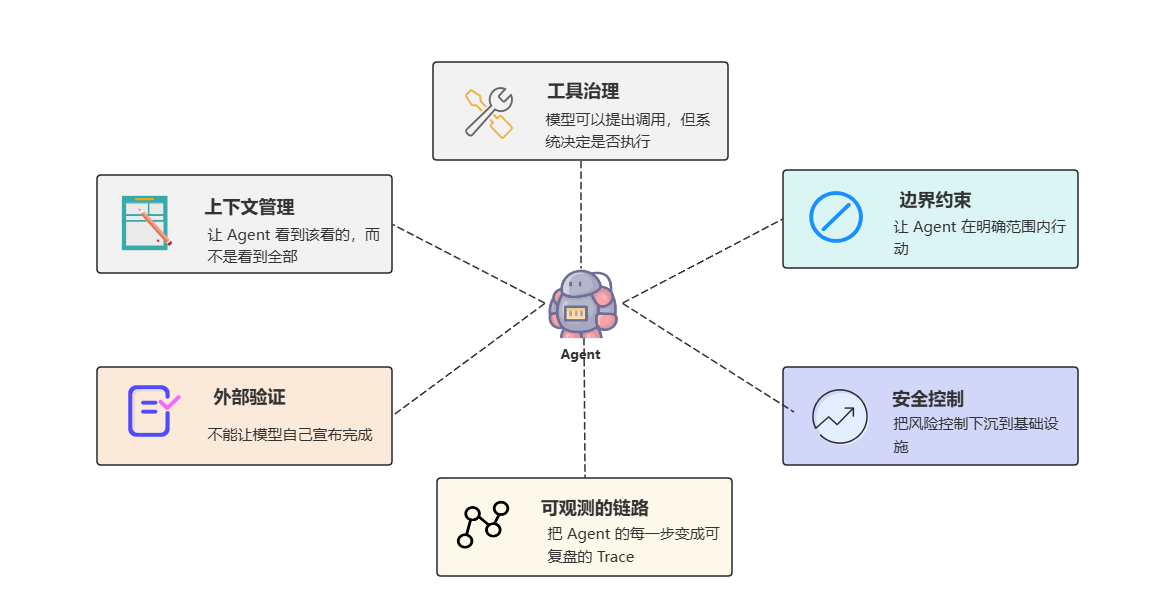
(1)上下文管理,让 Agent 看到该看的,而不是看到全部
在 LangChain 和 OpenAI 的实践中,上下文始终是影响 Agent 表现的核心变量。
但上下文不是越多越好。真实项目里的信息往往非常杂:业务文档、代码片段、工具说明、历史对话、运行日志、数据库结果都可能被塞进模型。如果没有筛选机制,模型看到的内容越多,反而越容易偏离重点。
Harness Engineering 需要做的是上下文治理:在不同任务阶段,为 Agent 提供真正有价值的信息,并过滤掉过期、无关或不可信的内容。
Context Engineering 解决“给模型看什么”,而 Harness Engineering 进一步关注这些上下文如何进入任务流程、如何被验证、如何影响后续决策。
Claude Code 的 CLAUDE.md 是一个很典型的上下文治理实践。它会把项目约定、架构说明、常用命令、代码风格等内容作为长期记忆加载进上下文。Anthropic 文档里也明确区分了项目级记忆、用户级记忆等不同位置。
(2)工具治理,模型可以提出调用,但系统决定是否执行
Agent 真正变得危险,不是因为它会回答问题,而是因为它可以调用工具。
无论是 LangChain Tools,还是 OpenAI 的 function calling / tools,本质上都是把模型连接到外部系统。只要工具具备读写文件、查询数据库、调用接口、发送消息、修改业务状态的能力,Agent 就不能再被当成一个普通文本生成器。
Harness Engineering 要在模型和工具之间建立治理层。模型可以提出调用意图,但工具是否允许执行、参数是否合法、是否需要人工确认、失败后如何处理,都应该由系统来控制。
尤其是删除、发布、支付、退款、权限变更这类高风险操作,不能依赖一句“请谨慎操作”的 Prompt。真正可靠的边界,必须固化在工具层和权限层。
OpenAI 的 function calling / tools 机制,本质上是让模型提出工具调用请求,然后由应用程序执行真实工具,并把结果返回给模型。
(3)边界约束,让 Agent 在明确范围内行动
Agent 的典型运行方式是循环:观察、推理、行动、再观察、再决策。
这个循环带来了自主性,也带来了失控风险。没有运行边界的 Agent,可能会反复调用工具、持续消耗 token、在错误路径上越走越远,或者在没有真正完成任务时停止。
Harness Engineering 要做的是控制这个循环:什么时候继续,什么时候停止,什么时候重试,什么时候转人工,什么时候判定任务已经失败。
这里的关键不是限制 Agent,而是让它的自主性具备工程边界。
OpenAI Agents SDK 里有 handoff 机制,可以把不同任务交给不同专业 Agent。OpenAI 文档里也说明 handoff 会以类似工具的形式暴露给模型,并可携带结构化输入。本质上就是,不要让一个 Agent 什么都做,而是通过任务路由限制它的责任边界。
(4)外部验证,不能让模型自己宣布完成
Agent 经常会出现一种问题:它认为任务完成了,但系统并没有真的完成。
代码可能已经修改,但测试没有通过;文档可能已经生成,但没有写入目标位置;接口可能返回成功,但业务状态没有变化;分析报告看起来完整,但口径并不符合业务规则。
因此,Harness Engineering 必须引入外部验证机制。
Reflection 可以作为一种自检方式,但不能成为最终依据。真正可靠的系统,需要通过测试、规则校验、Schema 校验、业务状态检查、人工确认等方式,判断 Agent 的输出是否真的满足要求。
生产级 Agent 不能让模型自己给自己盖章。
在 Coding Agent 里,这通常表现为:代码修改后必须跑测试;生成配置后必须校验 Schema;写文档后必须确认目标位置和链接;调用接口后必须检查真实业务状态。
(5)可观测的链路,把 Agent 的每一步变成可复盘的 Trace
当 Agent 只是回答问题时,错误通常停留在文本层面;当 Agent 开始执行动作时,错误就会进入真实系统。
这时,可观测性就不再是锦上添花,而是基础能力。
Harness Engineering 需要记录 Agent 的执行轨迹:它基于什么上下文做判断,为什么选择某个工具,工具返回了什么,系统如何校验结果,最终交付物是怎么产生的。
这些信息决定了团队能否复盘一次失败,也决定了后续能否持续优化 Agent。
没有执行轨迹,团队只能凭感觉改 Prompt;有了执行轨迹,才能判断问题到底出在模型、上下文、工具、权限还是验证规则。
OpenAI Agents SDK 默认支持 tracing,会记录 Agent run 里的模型生成、工具调用、handoff、guardrail 等事件。
LangSmith 也提供类似能力,用于捕获、调试、评估和监控 LLM 应用行为。
(6)安全控制,把风险控制下沉到基础设施
很多 Agent 系统早期会把安全要求写进 Prompt,比如“不要访问隐私数据”“不要执行危险操作”“不要修改无关文件”。
这类提示有用,但不应该成为唯一防线。
生产级 Harness 必须把安全边界下沉到系统层。Agent 能访问哪些数据,能调用哪些工具,能修改哪些资源,哪些操作必须人工确认,都应该由权限系统和基础设施来保证。
真正可靠的 Agent 系统,不是假设模型永远不会犯错,而是假设模型一定可能犯错,然后通过系统边界限制损害范围。
不能意味着写Prompt:请不要删除重要文件。
更可靠的做法是:
if (operation === "delete" && !path.startsWith("/tmp/workspace")) {
throw new Error("禁止删除工作区之外的文件");
}
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)