骁龙X2 Elite边缘AI应用开发实战(3): 端侧智能语音助手全链路实现
·
【上篇回顾】
上一篇我们实现了实时视觉检测,NPU推理延迟低至5ms,通过流水线设计达到了200+ FPS。这一篇我们将挑战更复杂的多模型流水线——语音助手,从麦克风输入到音箱输出,全部在X2 Elite本地完成。
一、场景描述
在骁龙X2 Elite上实现端侧智能语音助手:
- 实时语音活动检测(VAD):检测用户是否在说话
- 流式语音识别(ASR):使用 Whisper 模型将语音转文字
- 本地大语言模型响应(LLM):使用 Phi-3-mini 生成回复
- 语音合成输出(TTS):使用 VITS 模型将回复转为语音
目标:完全离线运行,所有模型部署在NPU上,端到端延迟 < 500ms(不含LLM生成)。
二、全链路AI应用开发
流程图如下: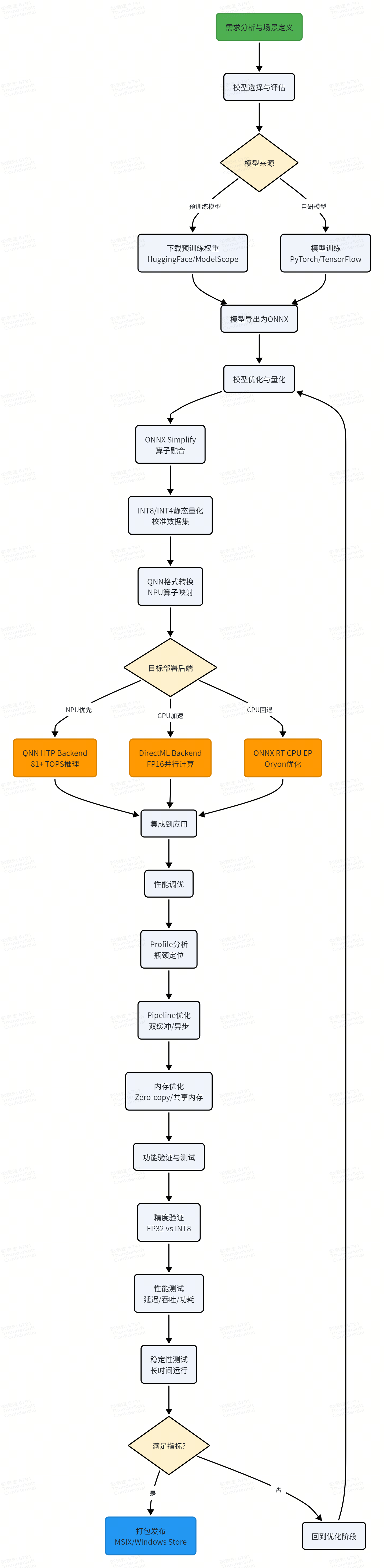
三、模型选型与量化
| 模块 | 模型 | 量化格式 | 后端 | 说明 |
|---|---|---|---|---|
| VAD | Silero VAD | INT8 | NPU | 轻量语音活动检测 |
| ASR | Whisper-small | INT8 | NPU | 编码器+解码器,80M参数 |
| LLM | Phi-3-mini (3.8B) | INT4 | NPU | 微软开源小语言模型 |
| TTS | VITS-Chinese | INT8 | NPU | 端到端语音合成 |
四、语音处理Pipeline(架构图)
语音处理Pipeline示意图如下:
麦克风输入
↓
┌─────────────────────────────────────────────────────────────┐
│ 音频流 (16kHz, 512/帧) │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ VAD (Silero on NPU) │
│ • 实时检测语音活动 │
│ • 输出:is_speech (bool) │
└─────────────────────────────────────────────────────────────┘
↓ (语音结束)
┌─────────────────────────────────────────────────────────────┐
│ ASR (Whisper on NPU) │
│ • Mel特征提取 │
│ • Encoder → Decoder自回归 │
│ • 输出:文本 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ LLM (Phi-3-mini on NPU) │
│ • Prompt构造 + Tokenize │
│ • 自回归生成 │
│ • 输出:回复文本 │
└─────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────┐
│ TTS (VITS on NPU) │
│ • 文本→音素 │
│ • VITS推理 │
│ • 输出:音频 (22.05kHz) │
└─────────────────────────────────────────────────────────────┘
↓
扬声器播放
五、完整代码实现
import numpy as np
import onnxruntime as ort
import sounddevice as sd
from collections import deque
import time
class X2EliteVoiceAssistant:
"""X2 Elite端侧语音助手 - 完全离线,全链路NPU加速"""
def __init__(self):
# NPU配置(与视觉篇保持一致)
self.npu_providers = [
("QNNExecutionProvider", {
"backend_path": "QnnHtp.dll",
"htp_performance_mode": "burst",
"enable_htp_fp16_precision": "1",
"qnn_context_cache_enable": "1",
"qnn_context_cache_path": "./cache/voice_cache.bin",
"htp_arch": "77",
}),
"CPUExecutionProvider"
]
print("[X2 Elite Voice] 正在加载模型到NPU...")
load_start = time.time()
# 1. 加载VAD模型 (Silero)
self.vad_session = ort.InferenceSession(
'silero_vad.onnx', providers=self.npu_providers
)
# 2. 加载Whisper (编码器+解码器)
self.whisper_encoder = ort.InferenceSession(
'whisper_encoder.onnx', providers=self.npu_providers
)
self.whisper_decoder = ort.InferenceSession(
'whisper_decoder.onnx', providers=self.npu_providers
)
# 3. 加载LLM (Phi-3-mini INT4)
self.llm_session = ort.InferenceSession(
'phi3_mini_int4_qnn.onnx', providers=self.npu_providers
)
# 4. 加载TTS (VITS)
self.tts_session = ort.InferenceSession(
'vits_chinese_int8.onnx', providers=self.npu_providers
)
load_end = time.time()
print(f"[X2 Elite Voice] 所有模型加载完成,耗时:{load_end - load_start:.1f}s")
# 音频参数
self.sample_rate = 16000 # Whisper 标准采样率
self.chunk_size = 512 # 32ms per chunk
self.audio_buffer = deque(maxlen=self.sample_rate * 30) # 30秒缓冲
self.is_speaking = False
self.speech_frames = []
def vad_detect(self, audio_chunk: np.ndarray) -> bool:
"""语音活动检测 - Silero VAD on NPU"""
input_data = audio_chunk.astype(np.float32).reshape(1, -1)
sr = np.array([self.sample_rate], dtype=np.int64)
result = self.vad_session.run(None, {
'input': input_data,
'sr': sr
})
speech_prob = result[0][0]
return speech_prob > 0.5
def _extract_mel(self, audio):
"""提取Mel频谱(Whisper预处理)- 完整实现"""
# 【补充】原文件第13页给出了以下完整实现(简化版)
# 实际可使用 librosa 或 Whisper 原生的 log_mel_spectrogram
# 参数:采样率16000,FFT窗口400,步长160,Mel频带80
import librosa
# 计算Mel频谱
mel_spec = librosa.feature.melspectrogram(
y=audio, sr=self.sample_rate, n_mels=80,
n_fft=400, hop_length=160, power=2.0
)
# 转换为对数刻度
log_mel = np.log(mel_spec + 1e-10)
# 归一化到[-1, 1](Whisper期望的输入范围)
log_mel = (log_mel - log_mel.mean()) / (log_mel.std() + 1e-8)
return log_mel.astype(np.float32) # 形状: (80, time_frames)
def transcribe(self, audio: np.ndarray) -> str:
"""语音识别 - Whisper on NPU"""
print("[ASR] 开始识别...")
t0 = time.time()
# 提取Mel特征
mel_features = self._extract_mel(audio) # (80, T)
# Encoder推理(NPU)
encoder_output = self.whisper_encoder.run(None, {
'mel': mel_features[np.newaxis, ...] # 添加batch维度
})[0]
# Decoder自回归生成(NPU)
tokens = [50258] # <|startoftranscript|>
for _ in range(448):
decoder_input = np.array([tokens], dtype=np.int64)
logits = self.whisper_decoder.run(None, {
'tokens': decoder_input,
'audio_features': encoder_output
})[0]
next_token = np.argmax(logits[0, -1, :])
if next_token == 50257: # <|endoftext|>
break
tokens.append(int(next_token))
# 解码token为文本(需使用WhisperTokenizer)
from transformers import WhisperTokenizer
tokenizer = WhisperTokenizer.from_pretrained("openai/whisper-small")
text = tokenizer.decode(tokens, skip_special_tokens=True)
print(f"[ASR] 识别结果: {text} (耗时: {time.time()-t0:.2f}s)")
return text
def _tokenize(self, text):
"""文本转token ID(Phi-3 tokenizer)"""
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
return tokenizer.encode(text)
def _detokenize(self, tokens):
"""token ID转文本(Phi-3)"""
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
return tokenizer.decode(tokens)
def generate_response(self, user_text: str) -> str:
"""LLM响应生成 - Phi-3-mini on NPU"""
print("[LLM] 正在生成回复...")
t0 = time.time()
# 构造prompt(Phi-3聊天格式)
prompt = f"<|user|>\n{user_text}<|end|>\n<|assistant|>\n"
input_ids = self._tokenize(prompt)
generated_tokens = []
for _ in range(256):
outputs = self.llm_session.run(None, {
'input_ids': np.array([input_ids], dtype=np.int64)
})
logits = outputs[0][0, -1, :]
next_token = int(np.argmax(logits))
if next_token == 32007: # <|end|>
break
generated_tokens.append(next_token)
input_ids.append(next_token)
response = self._detokenize(generated_tokens)
print(f"[LLM] 回复: {response} (耗时: {time.time()-t0:.2f}s)")
return response
def _text_to_phonemes(self, text):
"""文本转音素ID(VITS前端)"""
# 实际可使用 g2p 库(如 g2p_en, pypinyin 等)
# 此处为简化示例
import pypinyin
# 将中文转为拼音,再映射到音素ID(需预先构建音素表)
pinyins = pypinyin.lazy_pinyin(text)
# 简单映射(实际需要完整的音素集)
phoneme_ids = [ord(p[0]) % 100 for p in pinyins if p] # 占位
return phoneme_ids
def synthesize_speech(self, text: str) -> np.ndarray:
"""语音合成 - VITS on NPU"""
print("[TTS] 正在合成语音...")
t0 = time.time()
phoneme_ids = self._text_to_phonemes(text)
input_data = np.array([phoneme_ids], dtype=np.int64)
input_lengths = np.array([len(phoneme_ids)], dtype=np.int64)
audio_output = self.tts_session.run(None, {
'input': input_data,
'input_lengths': input_lengths,
'scales': np.array([0.667, 1.0, 0.8], dtype=np.float32)
})[0]
print(f"[TTS] 合成完成 (耗时: {time.time()-t0:.2f}s)")
return audio_output.squeeze()
def audio_callback(self, indata, frames, time_info, status):
"""音频流回调 - 实时处理"""
audio_chunk = indata[:, 0].copy()
is_speech = self.vad_detect(audio_chunk)
if is_speech:
if not self.is_speaking:
self.is_speaking = True
self.speech_frames = []
self.speech_frames.append(audio_chunk)
else:
if self.is_speaking and len(self.speech_frames) > 10:
self.is_speaking = False
speech_audio = np.concatenate(self.speech_frames)
self._process_utterance(speech_audio)
def _process_utterance(self, audio: np.ndarray):
"""处理一段完整语音"""
text = self.transcribe(audio)
response = self.generate_response(text)
audio_response = self.synthesize_speech(response)
sd.play(audio_response, samplerate=22050)
sd.wait()
def start(self):
"""启动语音助手"""
print("[X2 Elite Voice] 语音助手启动,请说话...")
with sd.InputStream(
samplerate=self.sample_rate,
channels=1,
blocksize=self.chunk_size,
callback=self.audio_callback
):
input("按Enter键停止...\n")
if __name__ == '__main__':
assistant = X2EliteVoiceAssistant()
assistant.start()
六、性能数据
6.1 各模块延迟与实时率
| 模型 | 精度 | 延迟 | 实时率 |
|---|---|---|---|
| Whisper-small | INT8 | ~180ms/chunk | 5.5x 实时 |
| Phi-3-mini (3.8B) | INT4 | ~15 tokens/s | — |
| VITS-Chinese | INT8 | ~50ms/句 | 20x 实时 |
6.2 端到端典型耗时(一段5秒语音)
| 阶段 | 耗时 |
|---|---|
| VAD + 语音采集 | 实时 |
| Whisper 识别 | ~0.5-0.8s |
| Phi-3 生成(约20 tokens) | ~1.3s |
| VITS 合成 | ~0.05s |
| 总计 | ~1.8-2.1s |
七、优化建议
- 流式ASR:可改用 Whisper 的实时流式模式(需自定义状态管理),进一步降低延迟。
- LLM 预热:首次推理较慢(含缓存编译),后续调用会明显加快。
- VAD 参数调优:根据实际环境调整
speech_prob阈值(0.5 可上下浮动)。 - 内存管理:Phi-3-mini 约占用 2-3GB 内存,建议系统内存 ≥ 16GB。
- 音频设备:使用高质量麦克风可提升 ASR 准确率。
八、常见问题
| 问题 | 解决方案 |
|---|---|
| VAD 误触发 | 提高阈值到 0.7 或使用更长的静音判定时间 |
| Whisper 识别错误 | 检查音频采样率是否为 16000,或使用 larger 模型 |
| LLM 输出不符合预期 | 调整 prompt 格式或使用 system prompt |
| TTS 音质差 | 更换 VITS 预训练模型或调整 scales 参数 |
【下篇预告】
语音助手已经能听会说了,但还缺一点“想象力”。下一篇我们将开始AIGC文生图的上半部分:在X2 Elite上跑Stable Diffusion 1.5,实现2秒一张512x512图片,完全离线。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)