python爬虫爬取页面视频,并附上源码
·
第一步:安装pychram
第二步:安装python
第三步:在pychram终端依次运行:
pip install requests beautifulsoup4pip install requestspip list如果是macOS系统就运行
pip3 install bs4pip3 install requests第四步:在main.py中粘贴下面的代码,并把网站修改成你自己想抓取的
"""
从 finestcatchchamber.shop 商品页抓取并下载嵌入视频。
用法:
python main.py
python main.py "https://finestcatchchamber.shop/某个商品页/"
python main.py --proxy http://127.0.0.1:7890
"""
from __future__ import annotations
import argparse
import os
import re
import sys
from pathlib import Path
from urllib.parse import unquote, urlparse
import requests
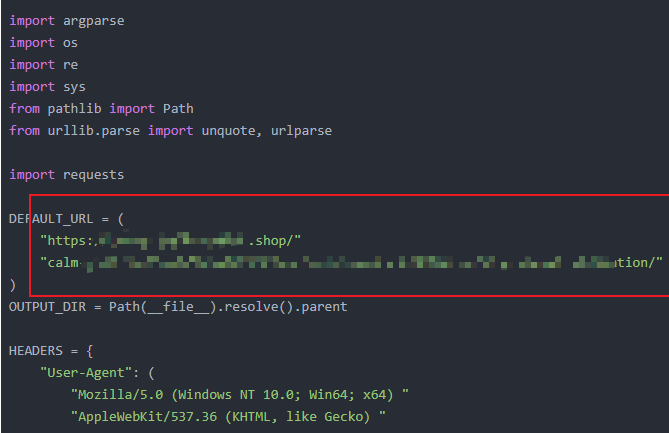
DEFAULT_URL = (
"https:xxxxxxxxx.shop/"
"calm-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxditation/"
)
OUTPUT_DIR = Path(__file__).resolve().parent
HEADERS = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/120.0.0.0 Safari/537.36"
),
"Referer": "https://xxxxxxxxxxxxxxxxxxxxxx.shop/",
}
VIDEO_PATTERNS = (
r'data-video="(https?://[^"]+\.(?:mp4|webm|m3u8)[^"]*)"',
r'<video[^>]+src="(https?://[^"]+\.(?:mp4|webm|m3u8)[^"]*)"',
r'"(https?://player\.vimeo\.com/progressive_redirect/playback/[^"]+\.mp4[^"]*)"',
)
DEFAULT_PROXY_PORTS = (7897, 7890, 10809, 1080, 8080)
def detect_local_proxy() -> str | None:
import socket
for port in DEFAULT_PROXY_PORTS:
try:
with socket.create_connection(("127.0.0.1", port), timeout=0.5):
return f"http://127.0.0.1:{port}"
except OSError:
continue
return None
def build_session(proxy: str | None = None) -> requests.Session:
session = requests.Session()
session.headers.update(HEADERS)
if proxy:
session.proxies.update({"http": proxy, "https": proxy})
return session
def fetch_page(session: requests.Session, url: str) -> str:
response = session.get(url, timeout=30)
response.raise_for_status()
return response.text
def extract_video_urls(html: str) -> list[str]:
found: list[str] = []
seen: set[str] = set()
for pattern in VIDEO_PATTERNS:
for match in re.findall(pattern, html, flags=re.IGNORECASE):
video_url = unquote(match.strip())
if not video_url.startswith("http"):
continue
if video_url not in seen:
seen.add(video_url)
found.append(video_url)
return found
def slug_from_page_url(page_url: str) -> str:
slug = page_url.rstrip("/").split("/")[-1]
return slug or "video"
def filename_from_url(url: str, page_slug: str, index: int) -> str:
parsed = urlparse(url)
rendition = "video"
match = re.search(r"/rendition/([^/]+)/", parsed.path)
if match:
rendition = match.group(1)
if index == 1 and page_slug:
return f"{page_slug}_{rendition}.mp4"
return f"{page_slug}_{rendition}_{index}.mp4"
def download_video(
session: requests.Session,
url: str,
output_path: Path,
chunk_size: int = 1024 * 1024,
) -> None:
with session.get(url, stream=True, timeout=120) as response:
response.raise_for_status()
total = int(response.headers.get("Content-Length", 0))
downloaded = 0
with output_path.open("wb") as file:
for chunk in response.iter_content(chunk_size=chunk_size):
if not chunk:
continue
file.write(chunk)
downloaded += len(chunk)
if total:
percent = downloaded * 100 // total
print(f"\r下载进度: {percent}% ({downloaded}/{total} bytes)", end="")
print(f"\n已保存: {output_path}")
def scrape_and_download(
page_url: str = DEFAULT_URL,
output_dir: Path = OUTPUT_DIR,
proxy: str | None = None,
) -> list[Path]:
output_dir.mkdir(parents=True, exist_ok=True)
proxy = proxy or os.environ.get("VIDEO_PROXY") or detect_local_proxy()
if proxy:
print(f"使用代理: {proxy}")
session = build_session(proxy)
page_slug = slug_from_page_url(page_url)
print(f"正在抓取页面: {page_url}")
html = fetch_page(session, page_url)
video_urls = extract_video_urls(html)
if not video_urls:
raise RuntimeError("未在页面中找到视频链接,请检查页面结构是否变化。")
print(f"找到 {len(video_urls)} 个视频链接")
saved_files: list[Path] = []
for index, video_url in enumerate(video_urls, start=1):
output_path = output_dir / filename_from_url(video_url, page_slug, index)
if output_path.exists() and output_path.stat().st_size > 0:
print(f"文件已存在,跳过: {output_path}")
saved_files.append(output_path)
continue
print(f"\n[{index}/{len(video_urls)}] 开始下载")
print(f"视频地址: {video_url}")
try:
download_video(session, video_url, output_path)
except requests.RequestException:
if proxy:
raise
fallback_proxy = detect_local_proxy()
if not fallback_proxy:
raise
print(f"直连失败,改用代理: {fallback_proxy}")
download_video(build_session(fallback_proxy), video_url, output_path)
saved_files.append(output_path)
return saved_files
def parse_args() -> argparse.Namespace:
parser = argparse.ArgumentParser(description="抓取商品页视频并保存到本地")
parser.add_argument("url", nargs="?", default=DEFAULT_URL, help="商品页 URL")
parser.add_argument(
"--proxy",
default=os.environ.get("VIDEO_PROXY"),
help="代理地址,例如 http://127.0.0.1:7890",
)
return parser.parse_args()
def main() -> int:
args = parse_args()
try:
saved = scrape_and_download(args.url, proxy=args.proxy)
except requests.RequestException as exc:
print(f"网络请求失败: {exc}", file=sys.stderr)
print(
"\n提示: 该页面视频托管在 Vimeo,若连接超时,请开启 VPN/代理后重试,例如:",
file=sys.stderr,
)
print(" python main.py --proxy http://127.0.0.1:7890", file=sys.stderr)
return 1
except RuntimeError as exc:
print(str(exc), file=sys.stderr)
return 1
print(f"\n完成,共保存 {len(saved)} 个文件到: {OUTPUT_DIR}")
return 0
if __name__ == "__main__":
raise SystemExit(main())
第五步:将网站地址改成你自己想抓取的


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)