LeWorldModel的理解5——潜在规划
文章目录
一、前言
仅供参考,未经实验验证。
二、LeWorldModel论文
论文标题:LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels(LeWorldModel: 从像素到像素的稳定端到端联合嵌入预测架构)
作者:Lucas Maes*, Quentin Le Lidec*, Damien Scieur, Yann LeCun, Randall Balestriero
论文地址: https://arxiv.org/pdf/2603.19312
GitHub 地址: https://github.com/lucas-maes/le-wm
3 方法: LeWorldModel
3.2 潜在规划
At inference time, we perform trajectory optimization in our world model latent space, as illustrated in Fig. 4. Given an initial observation o 1 \mathbf{o}_1 o1 , we initialize a candidate action sequence randomly and iteratively rollout predicted latent states up to a planning horizon H H H . The model predicts latent transitions according tog to
在推理时,我们在世界模型的潜在空间中执行轨迹优化,如图 4 所示。给定初始观测 o1,我们初始化一个候选动作序列,并迭代地预测规划视界 H 内的潜在状态。模型根据以下公式预测潜在状态转移:
z ^ t + 1 = pred ϕ ( z ^ t , a t ) , z ^ 1 = enc θ ( o 1 ) , \hat{\mathbf{z}}_{t+1} = \text{pred}_\phi(\hat{\mathbf{z}}_t, \mathbf{a}_t), \quad \hat{\mathbf{z}}_1 = \text{enc}_\theta(\mathbf{o}_1), z^t+1=predϕ(z^t,at),z^1=encθ(o1),
Planning is performed by optimizing the action sequence to minimize a terminal latent goal-matching objective:
规划通过优化动作序列以最小化终端潜在目标匹配目标来执行:
C ( z ^ H ) = ∥ z ^ H − z g ∥ 2 2 , z g = enc θ ( o g ) , ( 4 ) \mathcal{C}(\hat{\mathbf{z}}_H) = \|\hat{\mathbf{z}}_H - \mathbf{z}_g\|_2^2, \quad \mathbf{z}_g = \text{enc}_\theta(\mathbf{o}_g), \quad (4) C(z^H)=∥z^H−zg∥22,zg=encθ(og),(4)
【公式含义】:
该公式定义了 LeWorldModel (LeWM) 在潜在空间规划 (Latent Planning) 阶段使用的终端潜在目标匹配成本函数。其核心目的是量化在给定规划视野 H H H 下,模型预测的最终潜在状态与目标观测的潜在表示之间的差异,从而指导动作序列的优化,使智能体能够达成指定目标。
【符号解释】:
- C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H): 表示在规划视野 H H H 结束时,模型预测的最终潜在状态 z ^ H \hat{\mathbf{z}}_H z^H 的成本函数(Cost Function)。这个成本需要被最小化。
- z ^ H \hat{\mathbf{z}}_H z^H: 表示在规划视野 H H H 结束时,预测器 (predictor) 根据当前潜在状态和一系列动作 autoregressively 推演(rollout)得到的未来潜在状态。它是由预测器 pred ϕ ( z t , a t ) \text{pred}_{\phi}(\mathbf{z}_t, \mathbf{a}_t) predϕ(zt,at) 沿着规划视野 H H H 逐步预测得到的。
- z g \mathbf{z}_g zg: 表示目标观测 (goal observation) o g \mathbf{o}_g og 经过编码器 (encoder) enc θ \text{enc}_{\theta} encθ 编码后得到的目标潜在嵌入 (goal latent embedding)。
- ∣ ∣ ⋅ ∣ ∣ 2 2 ||\cdot||_2^2 ∣∣⋅∣∣22: 表示向量的 L2 范数(欧几里得距离)的平方。在这里,它计算的是预测的最终潜在状态 z ^ H \hat{\mathbf{z}}_H z^H 与目标潜在嵌入 z g \mathbf{z}_g zg 之间的欧几里得距离的平方,作为它们之间相似度或差异性的度量。
- enc θ ( ⋅ ) \text{enc}_{\theta}(\cdot) encθ(⋅): 表示编码器函数,其参数为 θ \theta θ。它将原始像素观测(如图像)映射到紧凑的、低维的潜在表示。
- o g \mathbf{o}_g og: 表示目标观测,即智能体需要达到的最终视觉状态(例如,一个目标图像)。
【公式解释】:
该公式不是一个推导公式,而是 LeWorldModel 在推理阶段进行决策和规划时所使用的目标函数,尤其是在模型预测控制 (Model Predictive Control, MPC) 框架下。
1. 背景知识:
- 世界模型 (World Models):世界模型旨在学习环境的动态模型,使智能体能够在“想象空间”中预测动作的后果。LeWM 就是一种世界模型,它学习在紧凑的潜在空间中预测未来状态。
- 潜在空间规划 (Latent Space Planning):传统的规划通常在原始像素空间或手动设计的状态空间中进行。潜在空间规划则将观测数据编码到低维潜在空间,并在该空间中预测环境动态和规划动作序列,这通常更高效且能捕捉关键特征。
- 模型预测控制 (Model Predictive Control, MPC):MPC 是一种在线优化控制策略。它在每个时间步:
- 根据当前状态和对环境动态的预测,优化一系列未来动作以最小化某个成本函数。
- 只执行优化得到的动作序列中的第一个动作。
- 获取新的观测,更新当前状态,然后重复上述过程。这种“滚动视野”策略允许系统适应环境变化。
2. 公式的工作原理与应用场景:
公式 (4) 定义了 LeWM 在进行 MPC 时,用于评估和优化动作序列的终端成本。其工作流程如下:
-
目标设定:在规划开始时,会给定一个初始观测 o 1 o_1 o1 和一个目标观测 o g o_g og。
-
编码目标状态:首先,使用训练好的编码器 enc θ \text{enc}_{\theta} encθ 将原始像素形式的目标观测 o g \mathbf{o}_g og 转换为其对应的潜在表示 z g \mathbf{z}_g zg。这个 z g \mathbf{z}_g zg 代表了我们希望智能体达到的目标状态在潜在空间中的形式。
z g = enc θ ( o g ) \mathbf{z}_g = \text{enc}_{\theta}(\mathbf{o}_g) zg=encθ(og) -
预测未来轨迹:给定当前的潜在状态 z t \mathbf{z}_t zt(最初是 o 1 o_1 o1 编码得到的 z 1 \mathbf{z}_1 z1)和一系列候选动作 a 1 : H a_{1:H} a1:H,模型中的预测器 pred ϕ \text{pred}_{\phi} predϕ 会在潜在空间中autoregressively 推演 (rollout),预测未来 H H H 个时间步的潜在状态。最终得到在规划视野 H H H 结束时的预测潜在状态 z ^ H \hat{\mathbf{z}}_H z^H。
z ^ t + 1 = pred ϕ ( z t , a t ) \hat{\mathbf{z}}_{t+1} = \text{pred}_{\phi}(\mathbf{z}_t, \mathbf{a}_t) z^t+1=predϕ(zt,at)
这个过程从 z 1 \mathbf{z}_1 z1 开始,通过一系列动作 a 1 , a 2 , … , a H \mathbf{a}_1, \mathbf{a}_2, \ldots, \mathbf{a}_H a1,a2,…,aH 逐步预测到 z ^ H \hat{\mathbf{z}}_H z^H。 -
计算目标匹配成本:公式 C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H) 衡量了预测的最终潜在状态 z ^ H \hat{\mathbf{z}}_H z^H 与目标潜在状态 z g \mathbf{z}_g zg 之间的距离。L2 范数的平方表示了这两个潜在向量之间的欧几里得距离。
C ( z ^ H ) = ∣ ∣ z ^ H − z g ∣ ∣ 2 2 \mathcal{C}(\hat{\mathbf{z}}_H) = ||\hat{\mathbf{z}}_H - \mathbf{z}_g||_2^2 C(z^H)=∣∣z^H−zg∣∣22- 设计动机:最小化这个成本函数意味着智能体需要找到一个动作序列 a 1 : H a_{1:H} a1:H,使得执行这些动作后,模型预测的最终状态 z ^ H \hat{\mathbf{z}}_H z^H 尽可能地接近目标状态 z g \mathbf{z}_g zg。
-
优化动作序列:在 MPC 框架下,一个求解器 (solver)(如论文中提到的交叉熵方法 Cross-Entropy Method, CEM)会迭代地优化动作序列 a 1 : H a_{1:H} a1:H。它通过采样不同的动作序列,计算每个序列对应的 C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H) 成本,然后根据成本最低的“精英”动作序列来更新采样分布,从而逐步收敛到一个能够最小化成本的动作序列。
3. 示例:
想象一个机器人需要将一个物体推到指定位置。
- 初始观测 o 1 o_1 o1:机器人当前视野中的场景图片。
- 目标观测 o g o_g og:物体被推到目标位置的场景图片。
- 编码:编码器将 o 1 o_1 o1 编码为 z 1 \mathbf{z}_1 z1,将 o g o_g og 编码为 z g \mathbf{z}_g zg。
- 规划:机器人需要规划一系列推的动作 a 1 : H a_{1:H} a1:H。预测器根据 z 1 \mathbf{z}_1 z1 和一系列推的动作,预测 H H H 步后物体将到达的潜在位置 z ^ H \hat{\mathbf{z}}_H z^H。
- 成本计算:公式 (4) 会计算 z ^ H \hat{\mathbf{z}}_H z^H 和 z g \mathbf{z}_g zg 之间的距离。如果 z ^ H \hat{\mathbf{z}}_H z^H 离 z g \mathbf{z}_g zg 很远,成本就高;如果很近,成本就低。
- 优化:规划算法(如 CEM)会不断尝试不同的推的动作序列,直到找到一个序列,使得预测的最终位置 z ^ H \hat{\mathbf{z}}_H z^H 与目标位置 z g \mathbf{z}_g zg 之间的距离最小化,即成本 C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H) 最小。
通过这种方式,LeWM 可以在潜在空间中“想象”不同动作序列的后果,并选择最佳的动作序列以达到目标,而无需在像素空间进行昂贵的预测或依赖奖励信号。
【总结】:
公式 C ( z ^ H ) = ∣ ∣ z ^ H − z g ∣ ∣ 2 2 \mathcal{C}(\hat{\mathbf{z}}_H) = ||\hat{\mathbf{z}}_H - \mathbf{z}_g||_2^2 C(z^H)=∣∣z^H−zg∣∣22 定义了 LeWorldModel 在潜在空间进行目标导向规划时的终端成本函数。它通过计算预测的最终潜在状态 z ^ H \hat{\mathbf{z}}_H z^H 与目标观测的潜在表示 z g \mathbf{z}_g zg 之间的欧几里得距离平方,来衡量规划的有效性。该成本函数在模型预测控制 (MPC) 框架下被最小化,以优化动作序列,使智能体能够高效地在潜在空间中规划出达到目标状态的路径。
回到原文
where z ^ H \hat{\mathbf{z}}_H z^H is the predicted latent state at the end of the rollout and z g \mathbf{z}_g zg is the latent embedding of the goal observation o g \mathbf{o}_g og . The world model parameters remain fixed during planning. This procedure corresponds to a finite-horizon optimal control problem:
其中 z ^ H \hat{\mathbf{z}}_H z^H 是预测的 rollout 结束时的潜在状态, z g \mathbf{z}_g zg 是目标观测值 z g \mathbf{z}_g zg 的潜在嵌入。世界模型参数在规划过程中保持固定。该过程对应于一个有限视界最优控制问题:
a 1 : H ∗ = arg min a 1 : H C ( z ^ H ) , ( 5 ) \mathbf{a}_{1:H}^* = \arg \min_{\mathbf{a}_{1:H}} \mathcal{C}(\hat{\mathbf{z}}_H), \quad (5) a1:H∗=arga1:HminC(z^H),(5)
【公式含义】:
该公式定义了 LeWorldModel (LeWM) 在潜在空间规划阶段,通过最小化终端潜在目标匹配成本函数,来求解最优动作序列的优化目标。它旨在找到在给定规划视野 H H H 内,能够使模型预测的最终潜在状态最接近目标潜在状态的行动方案。
【符号解释】:
- a 1 : H ∗ \mathbf{a}_{1:H}^* a1:H∗: 表示从时间步 1 到 H H H 的最优动作序列。这个序列包含了智能体在规划视野内将执行的一系列动作。
- arg min a 1 : H \arg \min_{\mathbf{a}_{1:H}} argmina1:H: 是一个数学运算符,表示寻找使后面的表达式最小化的自变量 a 1 : H \mathbf{a}_{1:H} a1:H 的值。在这里,它意味着我们要找到一个动作序列 a 1 : H \mathbf{a}_{1:H} a1:H,使得成本函数 C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H) 达到最小值。
- C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H): 表示在规划视野 H H H 结束时,模型预测的最终潜在状态 z ^ H \hat{\mathbf{z}}_H z^H 的成本函数(Cost Function)。根据论文中的公式 (4),此成本函数具体定义为 C ( z ^ H ) = ∣ ∣ z ^ H − z g ∣ ∣ 2 2 \mathcal{C}(\hat{\mathbf{z}}_H) = ||\hat{\mathbf{z}}_H - \mathbf{z}_g||_2^2 C(z^H)=∣∣z^H−zg∣∣22,即预测的最终潜在状态与目标潜在嵌入之间的L2范数平方。
- z ^ H \hat{\mathbf{z}}_H z^H: 表示在规划视野 H H H 结束时,由预测器根据初始潜在状态和动作序列 a 1 : H \mathbf{a}_{1:H} a1:H 自动回归(autoregressively)预测得到的未来潜在状态。
- H H H: 表示规划视野(Planning Horizon),即模型向前预测和规划动作的步数。
【公式解释】:
该公式不是一个推导公式,而是一个优化目标,用于在 LeWorldModel 的潜在空间中进行决策和规划。它构成了模型预测控制 (Model Predictive Control, MPC) 策略的核心部分。
1. 背景知识:
- 潜在空间规划 (Latent Space Planning):LeWorldModel 的核心思想是将原始像素观测通过编码器映射到低维、紧凑的潜在空间。在这个潜在空间中,一个预测器学习环境的动态,即如何从当前潜在状态和动作预测下一个潜在状态。规划过程也在这个潜在空间中进行,避免了在复杂高维像素空间中直接操作。
- 模型预测控制 (Model Predictive Control, MPC):MPC 是一种控制策略,它在每个时间步:
- 利用一个环境模型来预测未来一段时间内的系统行为。
- 基于这些预测,优化一个未来动作序列,以最小化一个预定义的成本函数。
- 只执行优化得到的动作序列中的第一个动作。
- 获取新的观测,更新当前状态,并重新进行上述优化过程(“滚动视野”)。
2. 公式的工作原理与应用场景:
公式 (5) 表明,LeWorldModel 在规划时,目标是找到一个最优的动作序列 a 1 : H ∗ \mathbf{a}_{1:H}^* a1:H∗,这个序列能够最小化在规划视野 H H H 结束时由其内部世界模型(编码器和预测器)所预测的最终潜在状态 z ^ H \hat{\mathbf{z}}_H z^H 的成本 C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H)。
具体而言,这个优化过程在 LeWM 的推理(inference)阶段,用于潜在规划 (Latent Planning):
- 设定目标:首先,智能体被赋予一个初始观测 o 1 \mathbf{o}_1 o1 和一个目标观测 o g \mathbf{o}_g og。
- 编码目标:使用训练好的编码器 enc θ \text{enc}_{\theta} encθ 将目标观测 o g \mathbf{o}_g og 转换为其潜在表示 z g \mathbf{z}_g zg(如公式 (4) 所示)。这个 z g \mathbf{z}_g zg 是我们希望智能体达到的目标状态在潜在空间中的“样子”。
- 生成候选动作序列:规划算法(例如论文中提到的交叉熵方法 Cross-Entropy Method, CEM)会生成一系列长度为 H H H 的候选动作序列 a 1 : H \mathbf{a}_{1:H} a1:H。
- 预测未来状态:对于每一个候选动作序列,LeWM 的预测器 pred ϕ \text{pred}_{\phi} predϕ 将从当前潜在状态(由 o 1 \mathbf{o}_1 o1 编码得到)开始,结合该动作序列,在潜在空间中自动回归地推演(rollout),预测出在 H H H 个时间步后将达到的最终潜在状态 z ^ H \hat{\mathbf{z}}_H z^H。
- 计算成本:根据公式 (4),计算每个预测的最终潜在状态 z ^ H \hat{\mathbf{z}}_H z^H 与目标潜在状态 z g \mathbf{z}_g zg 之间的目标匹配成本 C ( z ^ H ) = ∣ ∣ z ^ H − z g ∣ ∣ 2 2 \mathcal{C}(\hat{\mathbf{z}}_H) = ||\hat{\mathbf{z}}_H - \mathbf{z}_g||_2^2 C(z^H)=∣∣z^H−zg∣∣22。成本越低,说明预测的最终状态与目标状态越接近。
- 选择最优序列:公式 (5) 的核心在于 arg min \arg \min argmin,它指示我们要选择那个使成本 C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H) 最小化的动作序列 a 1 : H \mathbf{a}_{1:H} a1:H。这个被选中的动作序列就是我们当前规划视野下的最优动作序列 a 1 : H ∗ \mathbf{a}_{1:H}^* a1:H∗。
示例:
假设一个机器人需要在厨房中操作,将一个苹果从桌子A移动到桌子B。
- 初始观测:机器人视角下苹果在桌子A的图片。
- 目标观测:机器人视角下苹果在桌子B的图片。
- 潜在编码:将两张图片分别编码为潜在状态 z current \mathbf{z}_{\text{current}} zcurrent 和 z goal \mathbf{z}_{\text{goal}} zgoal。
- 规划过程:机器人需要规划一系列操作(例如,移动到苹果旁边,抓取,移动到桌子B上方,放下)。假设规划视野 H = 5 H=5 H=5 步。
- 优化目标:公式 (5) 的作用就是找到一个包含 5 个操作的最佳序列 a 1 : 5 ∗ \mathbf{a}_{1:5}^* a1:5∗,使得当机器人执行这 5 个操作时,LeWM 的预测器所预测的最终潜在状态 z ^ 5 \hat{\mathbf{z}}_5 z^5(即苹果在桌子B的位置)与实际目标潜在状态 z goal \mathbf{z}_{\text{goal}} zgoal 的差异最小。
- MPC应用:在实际执行时,机器人只会执行这个最优序列中的第一个动作。然后,它会观察环境的新状态,重新进行编码,并再次使用公式 (5) 来规划下一个最优动作序列,以此类推,直到目标达成或规划预算耗尽。
【总结】:
公式 a 1 : H ∗ = arg min a 1 : H C ( z ^ H ) \mathbf{a}_{1:H}^* = \arg \min_{\mathbf{a}_{1:H}} \mathcal{C}(\hat{\mathbf{z}}_H) a1:H∗=argmina1:HC(z^H) 是 LeWorldModel 在潜在空间进行目标导向规划的核心优化目标。它通过寻找一个能够最小化预测的最终潜在状态与目标潜在状态之间差异(即成本函数 C ( z ^ H ) \mathcal{C}(\hat{\mathbf{z}}_H) C(z^H))的动作序列 a 1 : H \mathbf{a}_{1:H} a1:H,来确定在给定规划视野 H H H 下的最优行动方案。这使得 LeWM 能够在没有奖励信号的情况下,高效且稳定地进行基于模型的决策。
问题:rollout 是什么意思?
在强化学习和世界模型(World Model)的语境下,rollout 指的是:
通俗定义
Rollout = 让模型"想象"或"模拟"一段未来,生成一条完整的轨迹(状态→动作→下一状态→…)
两种常见含义
1. 真实环境 Rollout(实际执行)
# 在真实环境中执行动作,收集真实数据
for t in range(T):
action = policy(state) # 策略决定动作
next_state = env.step(action) # 真实环境返回下一状态
state = next_state
特点:和真实世界交互,数据贵、有风险(比如机器人摔了)。
2. 模型 Rollout / 想象 Rollout(LeWM 等世界模型的核心)
# 用学到的世界模型"做梦",想象未来
state = encoder(obs) # 当前状态嵌入
for t in range(T):
action = policy(state) # 决定动作
state = predictor(state, action) # 模型预测下一状态(不是真的去执行!)
imagined_trajectory.append(state)
特点:
- ❌ 不是真实发生
- ✅ 完全在模型"脑中"模拟
- ✅ 零成本、零风险、可以大量生成
- ✅ 用于训练策略、规划未来
LeWorldModel 中的 Rollout
emb = encoder(obs) # (B, T, D) 真实编码
next_emb = predictor(emb, actions) # (B, T, D) 单步预测
训练时只做了单步预测(预测下一帧),但模型学好后可以:
# 多步 Rollout(想象未来)
state = emb[:, 0] # 初始状态
for t in range(100): # 想象未来100步
action = some_action[t] # 某个动作序列
state = predictor(state, action) # 一步预测
# state 现在变成"想象的第 t+1 步"
类比理解
| 场景 | Rollout 是什么 |
|---|---|
| 下棋(AlphaGo) | 在脑中模拟"如果走这步,对方会怎么走,然后我怎么走…" |
| 开车(自动驾驶) | 模型想象"如果左转,3秒后会在哪里,周围车会怎么动" |
| 玩游戏 | 想象"按这个键,角色会跳,然后会落在哪" |
| 做计划 | 你规划明天行程:“如果先去A,再去B,需要多久…” |
为什么 Rollout 重要?
| 问题 | Rollout 解决 |
|---|---|
| 真实数据少/贵 | 模型自己"脑补"大量数据 |
| 危险场景难试 | 在想象中试错,不真撞车 |
| 需要长远规划 | 模拟多步后果,选最好动作 |
| 策略训练 | 用想象数据训练,少去真实环境 |
一句话总结
Rollout = 让模型当"预言家",从当前状态出发,一步步推演未来会发生什么。在世界模型里,这是"想象"的能力;在强化学习里,这是"试错"的能力。
回到原文
which we solve using the Cross-Entropy Method (CEM) [40], a sampling method that iteratively selects the best plan and updates the parameters of the sampling distribution with the statistics of the best plans. The planning horizon H H H trades off long-term lookahead against increased computational cost and model bias.
我们使用交叉熵方法(CEM)[40]来解决这个问题,这是一种采样方法,它迭代地选择最佳规划并用最佳规划的统计数据更新采样分布的参数。规划视界H 在长期前瞻性与增加的计算成本和模型偏差之间进行权衡。
In particular, auto-regressive rollouts accumulate prediction errors as the horizon grows, which can deteriorate the quality of the optimized action sequence. To mitigate this effect, we adopt a Model Predictive Control (MPC) strategy: only the first K planned actions are executed before replanning from the updated observation. We provide more details on the planning strategy in appendix D.
特别是,自回归滚筒会随着预测范围的增长而累积预测误差,这会降低优化动作序列的质量。为了缓解这种影响,我们采用了模型预测控制(MPC)策略:在从更新后的观测值重新规划之前,只执行最初的 K个规划动作。我们将在附录 D 中提供有关规划策略的更多详细信息。
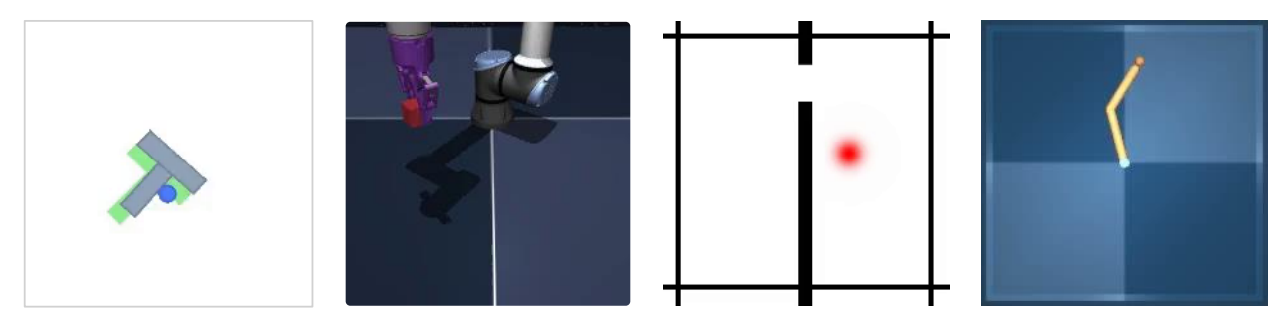
Figure 5: Environments used for evaluation. Left: Push-T, a 2D manipulation task where the agent must push a block toward a target configuration, commonly used as a robotics benchmark. Center (1): OGBench-Cube, a visually richer 3D manipulation environment where a robotic arm interacts with a cube to reach a target position. Center (2): Two-Room, a simple 2D navigation environment where an agent moves between rooms to reach target positions. Right: Reacher, a task where a 2-joint arm needs to reach a target configuration in a 2D plane. All environments have a continuous action space. More details on environment and datasets are available in appendix E.
图 5:用于评估的环境。左:Push-T,一个 2D 操作任务,代理必须将一个方块推向目标配置,该任务通常用作机器人基准测试。中间 (1):OGBench-Cube,一个视觉上更丰富的 3D 操作环境,其中机械臂与立方体交互以到达目标位置。中间 (2):Two-Room,一个简单的 2D 导航环境,代理在房间之间移动以到达目标位置。右:Reacher,一个任务,其中一个 2 关节臂需要在 2D 平面上到达目标配置。所有环境都具有连续动作空间。有关环境和数据集的更多详细信息,请参阅附录 E。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0


 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)