LeWorldModel的理解1——概述
文章目录
一、前言
仅供参考,未经实验验证。
二、LeWorldModel论文
论文标题:LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels(LeWorldModel: 从像素到像素的稳定端到端联合嵌入预测架构)
作者:Lucas Maes*, Quentin Le Lidec*, Damien Scieur, Yann LeCun, Randall Balestriero
论文地址: https://arxiv.org/pdf/2603.19312
项目地址(GitHub 官方仓库): https://github.com/lucas-maes/le-wm
摘要
Joint Embedding Predictive Architectures (JEPAs) offer a compelling framework for learning world models in compact latent spaces, yet existing methods remain fragile, relying on complex multi-term losses, exponential moving averages, pretrained encoders, or auxiliary supervision to avoid representation collapse. In this work, we introduce LeWorldModel (LeWM), the first JEPA that trains stably end-to-end from raw pixels using only two loss terms: a next-embedding prediction loss and a regularizer enforcing Gaussian-distributed latent embeddings.
联合嵌入预测架构(JEPAs)提供了一个引人注目的框架,用于在紧凑的潜在空间中学习世界模型,但现有方法仍然脆弱,依赖于复杂的多项损失、指数移动平均、预训练编码器或辅助监督来避免表示坍塌。在这项工作中,我们提出了 LeWorldModel (LeWM),这是第一个仅使用两个损失项即可从原始像素端到端稳定训练的 JEPA:一个下一嵌入预测损失和一个强制执行高斯分布潜在嵌入的正则化器。
This reduces tunable loss hyperparameters from six to one compared to the only existing end-to-end alternative. With 15M parameters trainable on a single GPU in a few hours, LeWM plans up to 48× faster than foundation-model-based world models while remaining competitive across diverse 2D and 3D control tasks.
与现有的唯一端到端替代方案相比,这可将可调谐损耗超参数从六个减少到一个。LeWM 拥有 1500 万个可训练参数,可在几小时内在一台 GPU 上完成训练,其速度比基于基础模型的世界模型快 48 倍,同时在各种 2D 和 3D 控制任务中保持竞争力。
Beyond control, we show that LeWM’s latent space encodes meaningful physical structure through probing of physical quantities. Surprise evaluation confirms that the model reliably detects physically implausible events.
在超出控制的范围内,我们通过探测物理量来证明 LeWM 的潜在空间编码了有意义的物理结构。意外评估证实该模型能够可靠地检测出物理上不合理的事件。
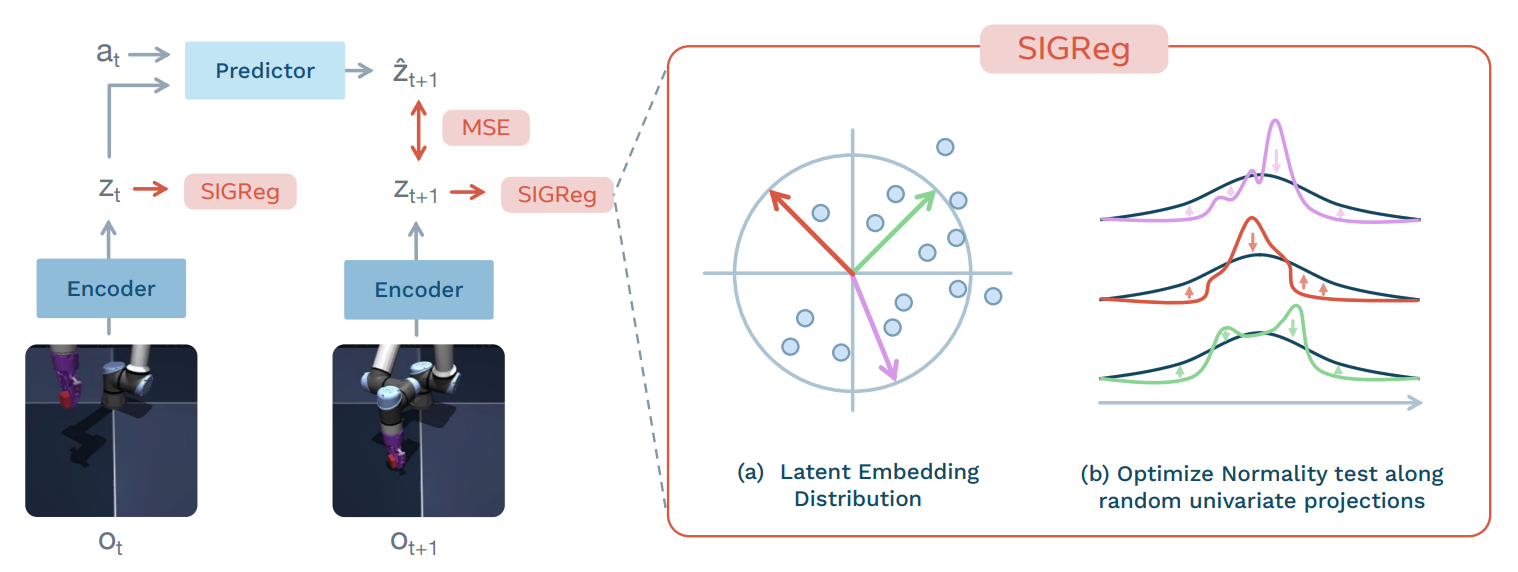
Figure 1: LeWorldModel Training Pipeline. Given frame observations o1:T
and actions a1:T, the encoder maps frames into low-dimensional latent representations z1:T. The predictor models the environment dynamics by autoregressively predicting the next latent state zt+1 from the current latent state zt and action at. The encoder and predictor are jointly optimized using a mean-squared error (MSE) prediction loss. LeWM does not rely on any training heuristics, such as stop-gradient, exponential moving averages, or pre-trained representations. To prevent trivial collapse, the SIGReg regularization term enforces Gaussian-distributed latent embeddings, promoting feature diversity. More specifically, latent embeddings are projected onto multiple random directions, and a normality test is applied to each one-dimensional projection. Aggregating these statistics encourages the full embedding distribution to match an isotropic Gaussian.
图 1:LeWorldModel 训练流程。给定帧观测 o 1 : T o_{1:T} o1:T 和动作 a 1 : T a_{1:T} a1:T ,编码器将帧映射到低维潜在表示 z 1 : T z_{1:T} z1:T 。预测器通过自回归地从当前潜在状态 zt 和动作 at 预测下一个潜在状态 z t + 1 z_{t+1} zt+1来模拟环境动力学。编码器和预测器使用均方误差 (MSE) 预测损失进行联合优化。LeWM 不依赖任何训练技巧,例如停止梯度、指数移动平均或预训练表示。为防止平凡崩溃,SIGReg 正则化项强制潜在嵌入服从高斯分布,从而促进特征多样性。更具体地说,潜在嵌入被投影到多个随机方向上,并对每个一维投影应用正态性检验。聚合这些统计数据可以鼓励完整的嵌入分布匹配各向同性高斯分布。
Figure 1: LeWorldModel 训练流程解析
总体目的 (Overall Purpose):
这张图(Figure 1)清晰地展示了 LeWorldModel (LeWM) 的端到端训练流程。LeWM 是一种联合嵌入预测架构(Joint Embedding Predictive Architecture, JEPA),旨在从原始像素数据中学习一个稳定的世界模型。这张图的核心是揭示模型如何通过两个关键损失项(预测损失和正则化损失)来优化其编码器和预测器,从而实现对环境动态的有效建模并避免表示坍塌。
核心模块与协作流程 (Core Components & Collaborative Flow):
-
输入观测 (Observations O t O_t Ot 和 O t + 1 O_{t+1} Ot+1):
- 图的左下方显示了两个机械臂抓取物体的图像,分别代表了连续的帧观测 O t O_t Ot (当前时刻) 和 O t + 1 O_{t+1} Ot+1 (下一时刻)。这些是模型从环境中接收到的原始像素数据。
-
编码器 (Encoder):
- 两个“Encoder”模块负责将原始像素观测 O t O_t Ot 和 O t + 1 O_{t+1} Ot+1 映射(编码)成紧凑的、低维度的潜在表示 Z t Z_t Zt 和 Z t + 1 Z_{t+1} Zt+1。
- 设计原理: 编码器通常采用像Vision Transformer (ViT) 这样的神经网络架构,能够从复杂的像素输入中提取出对环境动态至关重要的特征。在LeWM中,编码器是端到端训练的,这意味着它不是预训练的,而是与整个模型一起学习。
-
预测器 (Predictor):
- “Predictor”模块的任务是预测下一个潜在状态 Z ^ t + 1 \hat{Z}_{t+1} Z^t+1。它的输入是当前时刻的潜在状态 Z t Z_t Zt 和代理在当前时刻执行的动作 a t a_t at。
- 工作机制: 预测器通过学习到的环境动态模型,以自回归(autoregressively)的方式,从 Z t Z_t Zt 和 a t a_t at 推断出未来时刻的潜在表示 Z ^ t + 1 \hat{Z}_{t+1} Z^t+1。这使得模型能够在潜在空间中模拟未来。
-
预测损失 (MSE Prediction Loss):
- 图的中间上方,一个标有“MSE”的红色方框以及双向箭头,表示模型计算预测的下一个潜在状态 Z ^ t + 1 \hat{Z}_{t+1} Z^t+1 与实际的下一个潜在状态 Z t + 1 Z_{t+1} Zt+1 之间的差异。
- 作用: 这里使用的是**均方误差(Mean-Squared Error, MSE)**作为预测损失。其公式为 L p r e d = ∣ ∣ Z ^ t + 1 − Z t + 1 ∣ ∣ 2 L_{pred} = ||\hat{Z}_{t+1} - Z_{t+1}||^2 Lpred=∣∣Z^t+1−Zt+1∣∣2。这个损失函数驱动编码器学习能够产生可预测潜在表示的能力,并促使预测器准确地模拟环境动态。通过最小化这个损失,模型能够更好地预测未来的状态。
-
SIGReg 正则化 (SIGReg Regularization Term):
- 图中在 Z t Z_t Zt 和 Z t + 1 Z_{t+1} Zt+1 旁边各有一个“SIGReg”红色方框,并有一个虚线框将右侧的详细解释框起来。这是LeWM防止表示坍塌的关键机制。
- 设计动机: 仅凭预测损失,模型容易陷入“表示坍塌(representation collapse)”的困境,即编码器将所有输入都映射到几乎相同的潜在表示,从而使得预测任务变得简单但无用。为了避免这种情况,SIGReg 被引入。
- 工作机制(右侧放大图详解):
- (a) 潜在嵌入分布 (Latent Embedding Distribution): 这个子图展示了潜在空间中嵌入点(蓝色圆圈)的分布。SIGReg 的目标是使这些潜在嵌入的分布匹配一个各向同性高斯分布(isotropic Gaussian distribution)。
- (b) 沿随机单变量投影优化正态性检验 (Optimize Normality test along random univariate projections):
- 为了在高维空间中有效地评估和强制高斯分布,SIGReg 采用了一种巧妙的方法:它将潜在嵌入**投影(projected)**到多个随机的、单位范数方向上(图中用不同颜色的箭头表示)。
- 对于每个一维投影(即投影后的数据),模型会应用一个正态性检验(normality test),具体是Epps-Pulley统计量。图中三条曲线表示了投影后数据(黑色曲线)和目标高斯分布(彩色曲线,如紫色、红色、绿色)的概率密度函数。通过调整潜在嵌入的分布,使其在这些一维投影上尽可能接近高斯分布。
- 理论依据: 根据Cramér-Wold定理,如果一个高维分布的所有一维投影都匹配高斯分布,那么整个高维联合分布也会匹配高斯分布。
- 作用: 通过这种方式,SIGReg 有效地鼓励潜在嵌入保持多样性,避免坍塌,并促进模型学习到更有意义和区分度的特征。
LeWM 的完整训练目标 (Complete LeWM Training Objective):
LeWM 的总损失函数由预测损失和 SIGReg 正则化损失两项组成,其公式为:
L L e W M ≡ L p r e d + λ S I G R e g ( Z ) L_{LeWM} \equiv L_{pred} + \lambda SIGReg(Z) LLeWM≡Lpred+λSIGReg(Z)
其中, L p r e d L_{pred} Lpred 是预测损失, S I G R e g ( Z ) SIGReg(Z) SIGReg(Z) 是应用于潜在嵌入 Z Z Z 的正则化项, λ \lambda λ 是正则化权重,作为唯一的有效超参数。
总结:
Figure 1 以简洁而有力的图示,概括了 LeWorldModel 训练的核心思想:通过一个简单的两项损失函数,即预测损失和 SIGReg 正则化,模型能够稳定地从原始像素中学习到有意义的潜在世界模型。预测损失确保模型能够准确预测未来状态,而 SIGReg 则通过强制潜在空间中的嵌入分布为各向同性高斯来有效防止表示坍塌,促进特征多样性,从而解决了现有 JEPA 方法中常见的稳定性问题,并避免了对复杂启发式方法或预训练模型的依赖。
专业名词解释 (Glossary of Professional Terms)
-
LeWorldModel (LeWM):
- 解释: 这是本篇论文提出的具体模型名称,全称是 “Stable End-to-End Joint-Embedding Predictive Architecture from Pixels”。它是一种世界模型,旨在通过预测未来状态的潜在表示来学习环境动态。
- 通俗理解: 就像一个专门设计来学习世界运转规律的AI系统,叫做“Le世界模型”。
-
Joint Embedding Predictive Architecture (JEPA) / 联合嵌入预测架构:
- 解释: 一种学习世界模型的框架。其核心思想是,通过学习将高维输入(如图像)编码到低维潜在空间中,并在这个潜在空间中预测未来的状态,从而捕捉环境动态中最相关的特征。它不试图像素级地重建整个环境,而是预测其抽象表示。
- 通俗理解: 想象一个孩子学习认识世界。JEPA不是要记住所有细节(比如每片叶子的形状),而是学习事物的核心特征(比如树会开花结果)。它把这些特征“压缩”成一个简单的“概念编码”,然后用这些概念来预测未来(比如预测树明年还会长叶子)。
-
End-to-End Training / 端到端训练:
- 解释: 指整个神经网络模型(从输入到输出的所有部分)作为一个整体进行训练,所有参数同时优化,而不是分阶段或依赖预训练的组件。
- 通俗理解: 就像学习做饭,不是先学切菜,再学炒菜,最后学调味,而是从头到尾把所有环节都一起练习,让它们配合得最好。
-
Raw Pixels / 原始像素:
- 解释: 指未经任何高级处理的图像或视频的原始数据,即构成图像的最小单位。
- 通俗理解: 计算机看到的图片最基本的样子,就是一堆颜色小点(像素)组成的方格。
-
World Model / 世界模型:
- 解释: 一种机器学习模型,它学习环境的动态规律,使其能够预测在给定动作下环境将如何变化。这允许智能体在“想象空间”中进行规划和学习,而无需与真实环境进行大量交互。
- 通俗理解: 就像AI有一个“内在的模拟器”或“白日梦能力”。它通过观察世界,学会了世界的物理规则,然后可以在自己的“脑海里”模拟各种情况,预测不同行为会导致什么结果。
-
Latent Space / Representation / Embedding / 潜在空间 / 表示 / 嵌入:
- 解释: 机器学习模型将高维原始数据(如图像)压缩和抽象化后形成的低维向量空间。在这个空间中,数据的关键特征被捕捉,并且相似的数据点在空间中彼此靠近。
- 通俗理解: 想象把一张复杂的照片(高维数据)浓缩成一个简单的“标签”或“密码”(低维向量),这个标签包含了照片最重要的信息。所有这些标签构成的空间就是“潜在空间”。
-
Encoder / 编码器:
- 解释: 神经网络的一部分,负责将原始输入数据(如像素)转换成低维的潜在表示。
- 通俗理解: 就像一个把复杂图片“总结”成一个简短“概念标签”的AI翻译器。
-
Predictor / 预测器:
- 解释: 神经网络的另一部分,它接收当前时刻的潜在表示和动作,然后预测下一个时刻的潜在表示。
- 通俗理解: 就像一个“预言家”,根据当前的“概念标签”和“你做什么”,预测下一个瞬间的“概念标签”。
-
Loss Term / Loss Function / 损失项 / 损失函数:
- 解释: 在机器学习中,用于衡量模型预测结果与真实值之间差异的函数。训练的目标是最小化这个损失函数。
- 通俗理解: 这是一个衡量模型“犯错程度”的指标。犯的错越多,损失值就越大;犯的错越少,损失值就越小。AI训练就是努力让这个损失值最小化。
-
Prediction Loss / 预测损失:
- 解释: 衡量模型预测的未来潜在表示与实际的未来潜在表示之间的差异。通常使用均方误差(MSE)。
- 通俗理解: 衡量“预言家”预测得准不准。如果预测的“概念标签”和实际发生的“概念标签”很接近,这个损失就小。
-
Regularizer / Regularization / 正则化 / 正则化项:
- 解释: 在训练模型时添加的额外项,旨在防止模型过拟合训练数据,并鼓励模型学习到更通用、更鲁棒的特征。它通常通过限制模型复杂度或强制某些属性来实现。
- 通俗理解: 就像给AI学习设定的“附加规则”。除了要学得准,还得学得“有条理”、“不走极端”,防止它只记住特例而无法应对新情况。
-
Representation Collapse / 表示坍塌:
- 解释: 一种常见的训练失败模式,指模型学习到的潜在表示失去了区分度,将所有不同的输入都映射到相似甚至相同的潜在向量上。这使得潜在空间变得无用。
- 通俗理解: 就像AI学会了把所有图片都“总结”成同一个“概念标签”(比如,无论是猫、狗还是树,都总结成“一团模糊”)。这样它的“概念空间”就失去了意义,无法区分任何事物。
-
Mean-Squared Error (MSE) / 均方误差:
- 解释: 一种常用的损失函数,计算预测值与真实值之差的平方的平均值。它对较大的误差给予更大的惩罚。
- 通俗理解: 计算“预测值”和“真实值”之间的差距,然后把这个差距平方后再求平均。平方的目的是让正负误差都变成正数,并且对大误差惩罚更重。
-
Autoregressive / 自回归:
- 解释: 指模型在预测序列中的下一个元素时,会依赖于其自身之前已经预测出的元素。
- 通俗理解: 就像写一个故事,写下一句话时会参考前面已经写好的句子。AI在预测未来状态时,是基于它之前一步步预测出来的结果来继续预测更远的未来。
-
SIGReg (Sketched-Isotropic-Gaussian Regularizer) / 草图各向同性高斯正则化器:
- 解释: LeWM中使用的特定正则化方法,旨在强制潜在表示的分布接近一个各向同性高斯分布,从而防止表示坍塌。它通过将高维嵌入投影到多个随机一维方向上,并对这些一维投影应用正态性检验来实现。
- 通俗理解: 这是给AI设定的一个特殊“附加规则”,要求它在总结“概念标签”时,不能把所有标签堆在一起,也不能形成奇怪的形状。它要求这些“概念标签”在潜在空间中要均匀分散,就像在一个球体里随机撒了一把沙子一样,形成一个“均匀分布的云团”。
-
Isotropic Gaussian Distribution / 各向同性高斯分布:
- 解释: 一种多维概率分布,其在各个方向上都具有相同的方差(“各向同性”),且形状是完美的球形(“高斯”是钟形曲线)。在机器学习中,这通常被用作一个理想的、具有良好性质的目标分布。
- 通俗理解: 想象一个三维空间中的数据点分布,如果它在所有方向上都一样散开,没有偏向某个方向,并且整体呈现一个完美球形的“云团”,这就是各向同性高斯分布。它是一个“整齐、均衡”的理想分布。
-
Normality Test / 正态性检验:
- 解释: 统计学方法,用于检验一组数据是否服从正态(高斯)分布。
- 通俗理解: 一种统计学上的“体检”,用来判断一组数据是不是符合“正常”的钟形曲线分布。
-
Cramér-Wold Theorem / Cramér-Wold 定理:
- 解释: 一个重要的数学定理,指出如果一个多维概率分布的所有一维投影都与另一个分布的所有一维投影相同,那么这两个多维分布本身就是相同的。这使得在实践中可以通过检验一维投影来推断高维分布。
- 通俗理解: 这个定理的意思是,如果你想知道两个复杂的、多维的“云团”是不是一样的,你不需要直接比较它们整个形状。你只需要从各个方向上“切”一片下来(做一维投影),如果所有这些“切片”的形状都一样,那么这两个“云团”就一定是一样的。
-
Hyperparameter ( λ \lambda λ) / 超参数 ( λ \lambda λ):
- 解释: 在模型训练之前需要手动设置的参数,而不是通过训练数据学习得到的参数。例如,学习率、正则化强度等。
- 通俗理解: 就像一个食谱中的“盐的用量”。不是AI自己学出来的,而是我们作为厨师,在开始做饭前就要定好的一个数值。
LeWorldModel (LeWM) 训练流程的通俗解释
现在,让我们用一个更易理解的场景来比喻 LeWorldModel 的训练过程。
想象一下,你正在教一个名叫“小乐”的机器人认识世界,并学会预测未来。
小乐的学习目标:
小乐的目标是看图片(原始像素),然后能“想象”出接下来会发生什么,这样它就能更好地规划自己的行动。但它不是要记住每张图片的每个小点,而是要抓住事物的核心“概念”。
小乐的“大脑”结构:
- “概念提取器”(Encoder/编码器): 就像小乐的“眼睛”和“大脑”结合体。当小乐看到一张图片(比如一个苹果),这个提取器就会把它变成一个简短的、抽象的“概念标签”(潜在表示)。它不会记住苹果是红的圆的,而可能只是一个代表“苹果”的数字编码。
- “未来预言家”(Predictor/预测器): 就像小乐的“想象力”。当小乐有一个当前的“概念标签”(比如“苹果”)和它将要做的动作(比如“拿起”),预言家就会预测出下一个瞬间的“概念标签”(比如“苹果被拿起”)。
小乐的学习过程(端到端训练):
小乐的训练就像一个整体的考试,所有部分(概念提取器和预言家)都一起学习,互相配合。它只有两个主要的“评分标准”:
-
“预言准确度”(Prediction Loss/预测损失 - MSE):
- 考试内容: 小乐看到一张图片 O t O_t Ot 得到“概念标签” Z t Z_t Zt,然后它做了一个动作 a t a_t at。预言家预测出下一个“概念标签” Z ^ t + 1 \hat{Z}_{t+1} Z^t+1。与此同时,小乐又看到了真实世界发生的下一张图片 O t + 1 O_{t+1} Ot+1,并由概念提取器得到真实的“概念标签” Z t + 1 Z_{t+1} Zt+1。
- 评分方式: 预言家预测的 Z ^ t + 1 \hat{Z}_{t+1} Z^t+1 和真实发生的 Z t + 1 Z_{t+1} Zt+1 之间有多接近?如果很接近,这个损失就小,说明预言家很准,概念提取器提取的概念也很有用。
- 通俗理解: 就像小乐预言“苹果被拿起”,然后它看到真实情况确实是“苹果被拿起”,它就会很高兴,说明它学对了。
-
“概念多样性”(SIGReg Regularization/SIGReg 正则化):
- 考试内容: 仅仅靠预言准确度是不够的。小乐有个坏习惯:为了让预言变得容易,它可能会把所有东西都“总结”成同一个模糊的“概念标签”(比如把所有东西都叫“物品”)。这样预言家就很容易预测下一个还是“物品”,但这个“世界模型”就废了,因为它无法区分具体是“苹果”还是“香蕉”。
- 评分方式: 为了避免这种“概念坍塌”,我们引入了 SIGReg。它要求小乐提取出来的所有“概念标签”在潜在空间中必须是均匀分散、没有偏向的(各向同性高斯分布)。这就像要求小乐给每个东西起名字时,不能总用“物品”这种大类词,而是要用更具体、更丰富的词汇,并且这些词汇不能都挤在一起,要散开来。
- 如何检查: SIGReg很聪明,它不用直接看所有复杂的“概念标签”组成的“云团”,而是随机从不同方向“切”几片下来(随机单变量投影),检查这些“切片”里的“概念标签”是不是都均匀分布的(正态性检验)。如果这些“切片”都均匀,那么整个“云团”也基本是均匀的(Cramér-Wold 定理)。
- 通俗理解: 就像老师检查小乐的词汇量。老师不直接看小乐是不是认识所有词,而是随机抽查它对某些词的理解。如果它对这些词的理解都很“均衡”(比如不会把所有水果都混淆),那么老师就认为它的词汇量丰富且有条理。
最终的“成绩单”:
小乐的总分就是“预言准确度”和“概念多样性”的加权和。我们有一个超参数 λ \lambda λ(比如0.1),用来决定“概念多样性”在总分中的重要程度。这个 λ \lambda λ 是唯一需要我们手动调整的参数,因为它的值对小乐的学习效果影响最大,但也很容易调整。
总结来说:
LeWorldModel(小乐机器人)通过观察图片,学习将它们转化为抽象的“概念标签”。然后,它用这些标签预测未来。为了防止它把所有东西都看成一个模糊的概念,我们还要求它的**“概念标签”必须是多样且均匀分散的**。通过这两个简单的“学习规则”,小乐就能稳定地从原始视觉输入中学习到一套有用的世界运行规律,而不需要复杂的技巧或预先的知识。
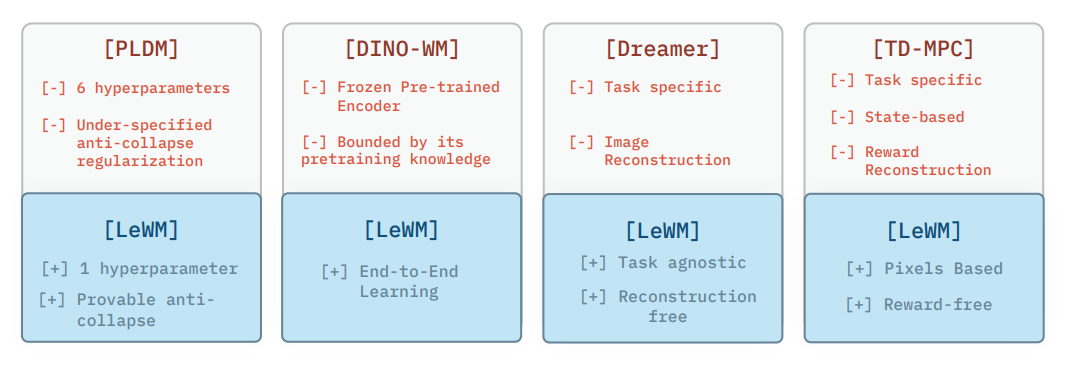
Figure 2: Characteristics of latent world model approaches. Methods are grouped by training paradigm. End-to-end methods (PLDM) learn both the encoder and predictor jointly from pixels without relying on pre-trained representations or heuristic tricks such as stop-gradient or exponential moving averages, but require many hyperparameters and lack formal collapse guarantees. Foundation-based methods (DINO-WM) avoid collapse by freezing a pre-trained foundation vision encoder, forgoing end-to-end learning. Task-specific methods (Dreamer, TD-MPC) require reward signals or privileged state access during training. LeWM addresses the limitations of each category: it is end-to-end, task-agnostic, pixel-based, reconstruction- and reward-free, and requires only a single hyperparameter with provable anti-collapse guarantees.
图 2:潜在世界模型方法的特征。方法按训练范式分组。端到端方法(PLDM)从像素中联合学习编码器和预测器,不依赖于预训练表示或停止梯度或指数移动平均等启发式技巧,但需要许多超参数且缺乏正式的崩溃保证。基于基础模型的方法(DINO-WM)通过冻结预训练的基础视觉编码器来避免崩溃,放弃端到端学习。特定任务的方法(Dreamer, TD-MPC)在训练期间需要奖励信号或特权状态访问。LeWM 解决了每个类别的局限性:它是端到端的、任务无关的、基于像素的、无重建和无奖励的,并且只需要具有可证明的抗崩溃保证的单个超参数。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 16
16 0
0- 0


 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)