从 Web 到 AI:现代数据库运维平台的架构演进逻辑
在上一篇文章中,我们拆解了 AI 无头代理在数据库运维中的 5 个高频落地场景,展示了这项技术如何解决真实的业务痛点。很多读者可能会问:为什么 AI 无头代理能够如此快速地落地普及?为什么它没有出现在本地客户端时代,而是在 Web 统一管控架构成熟之后才爆发?
答案其实很简单:Web 架构不仅是 AI 无头代理的运行底座,更是这项技术能够实现的前提条件。没有过去五年 Web 统一管控架构的全面普及,就没有今天 AI 无头代理的爆发式增长。
本文将从技术架构的角度,深入分析 Web 架构与 AI 无头代理的天然契合性,拆解 AI+Headless Agent 的四层核心技术架构,对比它与传统自动化脚本的本质区别,帮助你理解这项技术的底层逻辑和未来演进方向。
一、Web 架构:AI 化的坚实基础
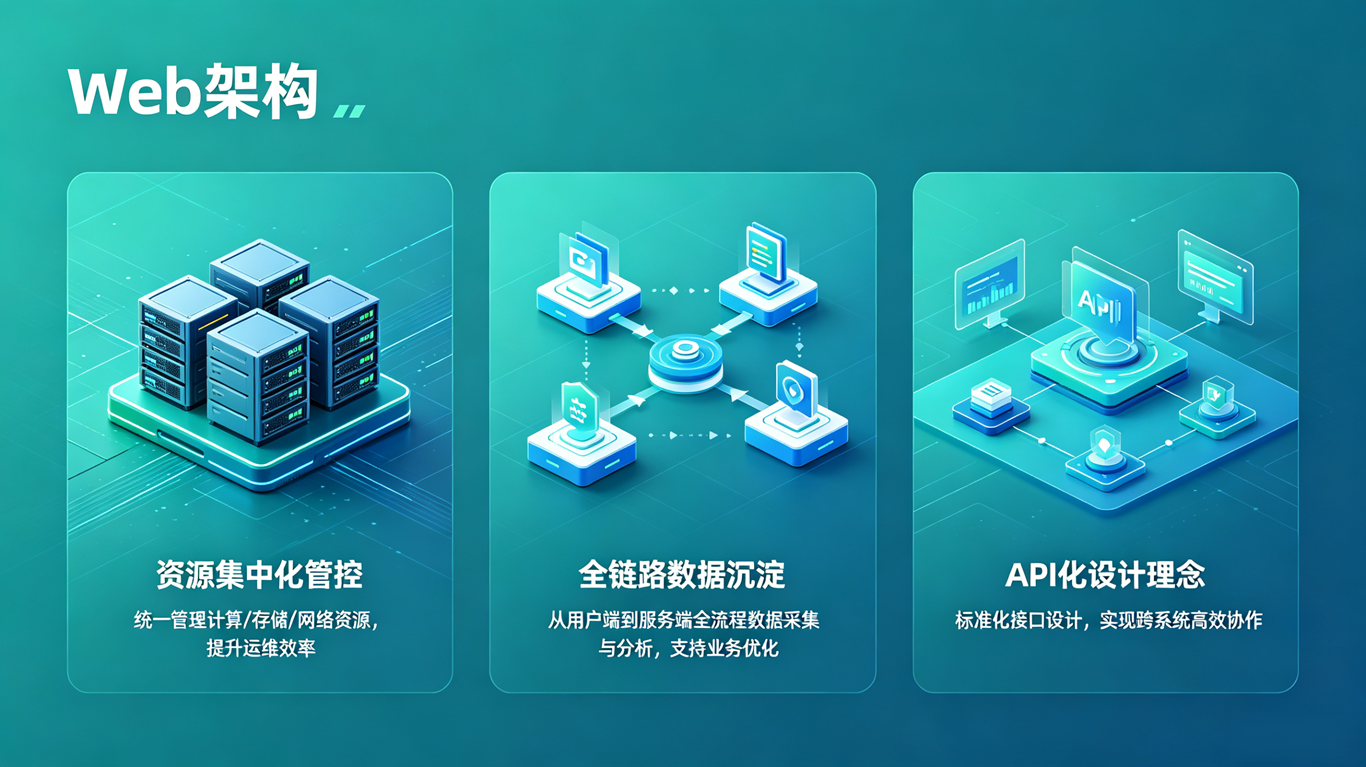
很多人认为 AI 无头代理是一个独立的技术创新,但实际上,它是 Web 统一管控架构发展到一定阶段的必然产物。Web 架构在过去五年中解决了三个核心问题,为 AI 化奠定了不可替代的基础。
第一个问题是资源的集中化管控。在本地客户端时代,数据库资源分散在各个运维人员的电脑上,没有统一的入口,没有统一的管理,没有统一的标准。每个运维人员都有自己的客户端配置,自己的连接信息,自己的操作习惯。这种分散式的架构,根本无法支撑一个统一的 AI 代理来管理所有数据库资源。
而 Web 架构实现了所有数据库资源的集中化管控。所有的数据库连接、权限配置、操作日志、运行数据都集中在一个统一的平台上。AI 代理只需要对接这一个平台,就可以管理企业所有的数据库资源,无需逐个对接不同的客户端和服务器。这种集中式的架构,是 AI 代理能够规模化运行的前提。
第二个问题是全链路数据的沉淀。AI 的能力来源于数据。没有足够多、足够高质量的数据,大模型就无法学习到行业最佳实践,无法准确地诊断故障,无法生成正确的 SQL 语句。
在本地客户端时代,操作日志分散在各个本地电脑上,运行数据分散在各个服务器上,没有统一的存储,没有统一的格式,没有长期的留存。而 Web 架构实现了所有操作和运行数据的全链路、全维度、长期留存。过去五年中,企业积累了海量的数据库运维数据,包括数百万条 SQL 执行记录、数十万次故障处理案例、数万个优化后的 SQL 语句。这些数据是训练数据库运维大模型的宝贵财富,也是 AI 无头代理能够准确执行任务的基础。
第三个问题是API 化的设计理念。Web 平台从诞生之初就采用了 API 化的设计理念,所有的功能都通过 RESTful API 对外暴露。无论是数据库连接、SQL 执行、备份管理、权限配置,还是日志查询、监控告警,都可以通过 API 调用完成。
这种 API 化的设计,为 AI 无头代理提供了标准化的执行通道。AI 代理不需要直接操作数据库,只需要调用 Web 平台的 API 就可以完成所有的运维任务。这不仅大大降低了 AI 代理的开发难度,更重要的是,它继承了 Web 平台所有的安全能力,包括权限管控、密码隔离、操作审计等,确保 AI 代理的所有操作都是安全可控的。
二、AI+Headless Agent 的四层核心技术架构
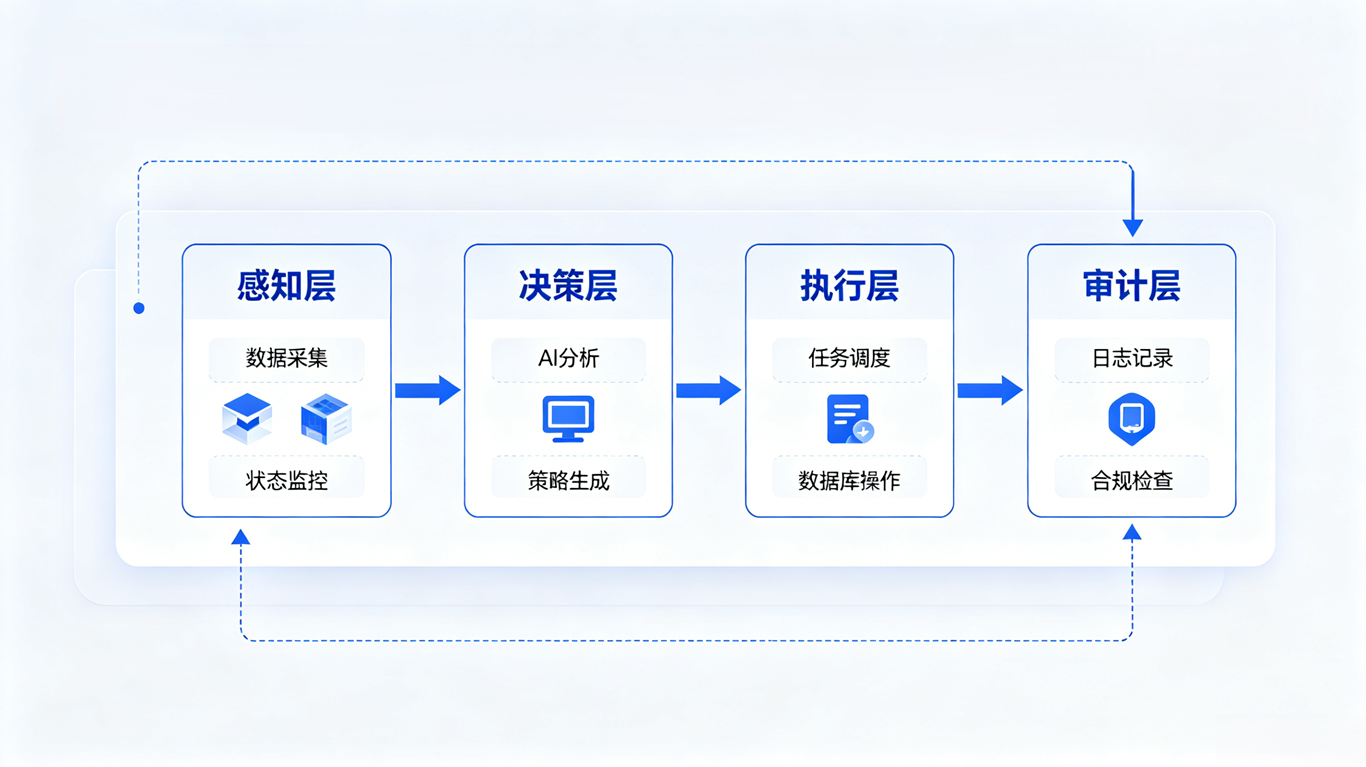
基于 Web 架构的三大核心优势,AI+Headless Agent 形成了一套完整的、分层解耦的技术架构。这套架构从上到下分为感知层、决策层、执行层和审计层,每一层都各司其职,协同工作,实现了从数据采集到任务执行的全链路自动化。
1. 感知层:实时监控数据库运行状态
感知层是整个架构的眼睛,负责实时采集数据库的所有运行数据。它对接 Web 平台的监控系统,持续获取数据库的 CPU 使用率、内存占用、磁盘空间、连接数、慢 SQL 数量、锁等待、事务状态等上百个指标。
同时,感知层还会实时监听 Web 平台的操作日志和告警信息,及时发现异常情况。当某个指标超过阈值或者出现告警时,感知层会立即将数据推送给决策层,触发后续的分析和处理流程。
感知层的核心优势是实时性和全面性。它可以做到秒级数据采集,覆盖数据库运行的所有维度,比人工监控更及时、更全面,不会遗漏任何异常情况。
2. 决策层:大模型进行任务规划与问题分析
决策层是整个架构的大脑,是 AI 能力的核心体现。它基于大模型技术,具备任务理解、任务拆解、问题分析、决策制定的能力。
当接收到用户的自然语言指令或者感知层的异常告警时,决策层会首先理解任务目标或者问题本质。然后,它会基于学习到的行业最佳实践和企业历史数据,制定最优的执行计划。比如,当发现磁盘空间不足时,决策层会自动分析哪些数据可以清理,制定清理方案;当收到一个数据同步需求时,决策层会自动拆解任务步骤,生成同步脚本。
决策层还具备自我修正的能力。如果执行过程中出现异常,它会自动分析失败原因,调整执行策略,重新尝试执行,直到任务完成或者确定无法解决。
3. 执行层:Headless Agent 静默执行操作
执行层是整个架构的手,负责具体的任务执行。它就是我们所说的 Headless Agent,全程在服务端后台静默运行,没有可视化界面。
执行层接收决策层下达的执行计划,然后调用 Web 平台的 API 完成具体的操作。比如执行 SQL 语句、创建备份、配置定时任务、清理临时表、创建索引等。所有的操作都通过 Web 平台的 API 完成,继承了 Web 平台的所有安全能力。
执行层的核心优势是稳定性和可靠性。它可以 7×24 小时不间断运行,不会疲劳,不会疏忽,不会情绪化,能够严格按照执行计划完成任务,确保操作的标准化和一致性。
4. 审计层:全程记录并反馈执行结果
审计层是整个架构的安全屏障,负责全程记录所有的操作,并反馈执行结果。它会记录从任务发起到执行完成的每一个步骤:谁在什么时间下达了什么指令,决策层如何拆解任务,执行层执行了什么操作,影响了多少行数据,执行结果是什么。
所有的审计日志都会实时同步到云端,采用不可篡改的方式存储,满足合规审计的要求。同时,审计层还会将执行结果反馈给用户,生成详细的执行报告,让用户能够清楚地了解任务的执行情况。
三、与传统自动化脚本的本质区别
很多人会问:AI 无头代理和我们之前写的自动化脚本有什么区别?不都是自动执行任务吗?
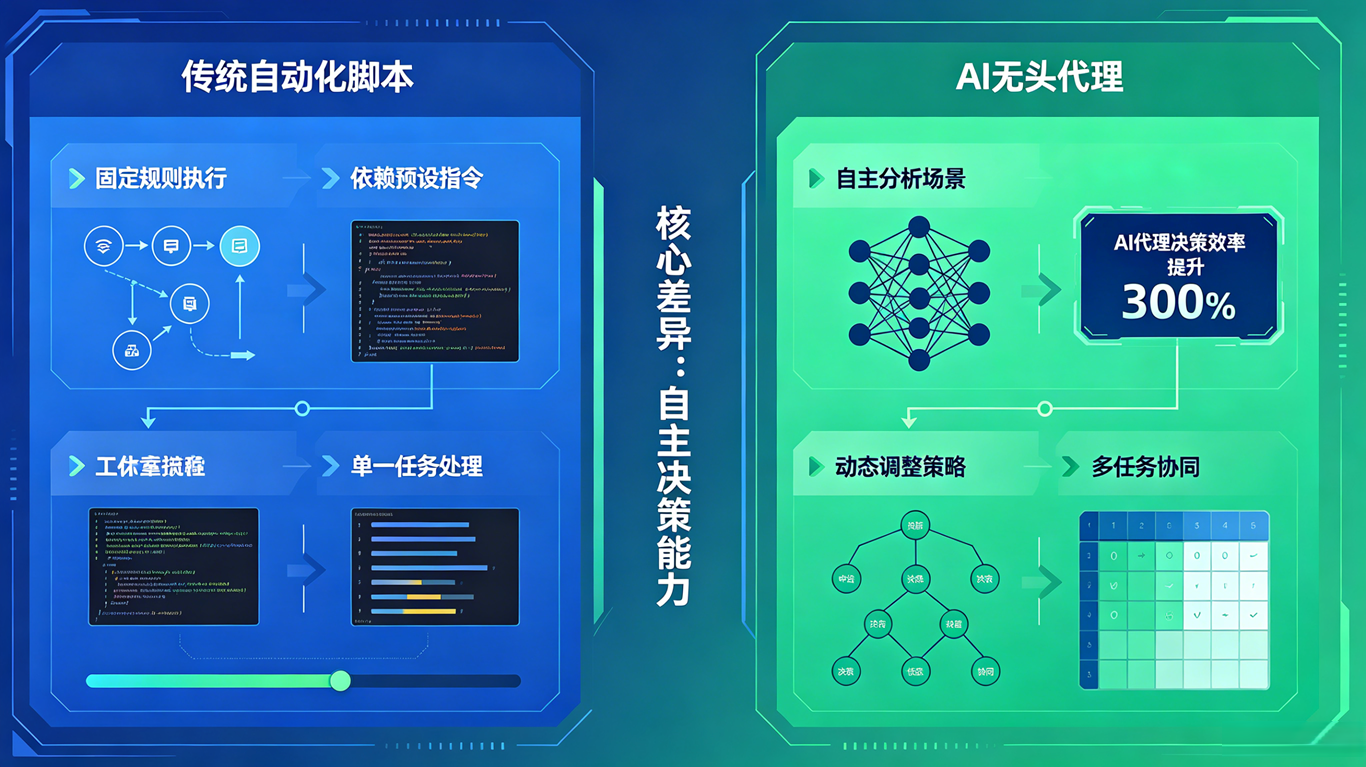
答案是:它们有着本质的区别。传统自动化脚本是预设规则的执行者,而 AI 无头代理是自主决策的思考者。
传统自动化脚本只能处理已知的、明确的问题。你需要预先编写好所有的逻辑,告诉脚本在什么情况下应该做什么。如果出现了脚本中没有预设的情况,脚本就会失败。而且,脚本的维护成本非常高,每当业务发生变化,就需要修改脚本。
而 AI 无头代理具备自主决策的能力。它不需要你预先编写所有的逻辑,只需要告诉它最终的目标。它会自己分析问题,自己制定执行计划,自己处理异常情况。它可以处理未知的、复杂的问题,能够适应业务的变化,无需频繁修改。
举一个简单的例子:清理磁盘空间。
- 传统脚本:你需要预先编写好清理哪些目录下的哪些文件,清理多少天之前的文件。如果出现了新的日志目录,或者磁盘空间还是不足,脚本就无法处理。
- AI 无头代理:你只需要告诉它 "清理磁盘空间,确保剩余空间不低于 20%"。它会自动分析磁盘使用情况,找出可以清理的文件,制定清理方案,执行清理操作,然后验证清理结果。如果清理后空间还是不足,它会自动寻找其他可以清理的内容,直到满足要求。
这就是两者的本质区别:传统脚本是 "你教它怎么做",而 AI 无头代理是 "你告诉它做什么"。
四、未来演进方向:完全自治的数据库运维体系
目前的 AI 无头代理还处于半自治阶段,它可以自动处理 80% 以上的标准化运维任务,但对于一些复杂的、重大的问题,仍然需要人工决策和干预。但随着大模型技术的不断发展和数据的不断积累,AI 无头代理的能力会持续提升,最终将实现完全自治的数据库运维体系。
未来的完全自治数据库运维体系,将具备以下能力:
- 自我监控:能够实时监控自身的运行状态,发现自身的问题并自动修复
- 自我优化:能够根据数据库的运行情况,自动调整配置参数,优化性能
- 自我升级:能够自动学习新的运维知识和最佳实践,不断提升自身的能力
- 自我决策:能够独立处理所有的运维问题,无需人工干预
到那时,数据库运维将真正实现无人值守。运维人员将彻底从繁琐的日常工作中解脱出来,专注于更高层次的架构设计和数据价值挖掘。
结语
从本地客户端到 Web 统一管控,再到 AI 无头代理,数据库运维的每一次架构演进,都是为了解决前一代架构的核心痛点。Web 架构解决了 "管控" 的问题,而 AI 无头代理解决了 "效率" 和 "安全" 的问题。
Web 架构为 AI 化奠定了坚实的基础,而 AI 无头代理则将 Web 架构的价值发挥到了极致。两者的完美结合,正在重构数据库运维的整个行业生态,开启一个全新的智能运维时代。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)