量化 Flux Fill (Nunchaku) 部署全记录
文章目录
一、为什么走这条路
方案选择历程
BrushNet SDXL → 效果差,修复导向不适合车灯重设计
SDXL Inpaint → 已跑通,但质量上限有限
Nunchaku Flux Fill → liblib 高点赞,MIT Han Lab 出品,技术路线:Flux Fill + INT4 量化
最终判断框架(用户方法论):
- 技术来源:MIT Han Lab(韩松团队)— 高效深度学习、模型压缩、量化推理领域顶级实验室。Flux 模型本身来自 Black Forest Labs(SD 原班团队)
- 技术先进性:Flux Fill(最强开源局部重绘)+ 4-bit 量化(16GB 能跑)
- 社区验证:liblib 高点赞
- 硬件适配:Nunchaku 量化版,4060 Ti 16GB 实测可跑
关键发现
在 16GB 显存下跑通 Flux Fill 是可能的,关键是 Nunchaku 量化引擎。它用 4-bit 量化把 12B 的 Flux Fill 模型压缩到 6.77GB,显存占用控制在 10GB 左右。
二、部署全流程
2.1 核心文档
官方工作流和说明:
https://nunchaku.tech/docs/ComfyUI-nunchaku/workflows/fill.html
2.2 需要安装的组件
| 组件 | 说明 | 来源 |
|---|---|---|
| ComfyUI-nunchaku 插件 | 提供量化模型加载节点 | GitHub:nunchaku-tech/ComfyUI-nunchaku |
| ComfyUI-InpaintEasy 插件 | 涂抹/蒙版工具 | GitHub:CY-CHENYUE/ComfyUI-InpaintEasy |
| nunchaku Python 包 | 量化推理引擎 | GitHub Releases 下载 wheel |
| PyTorch 2.9+cu126 | GPU 计算框架 | PyTorch 官网或本地 wheel |
2.3 模型下载
模型文件
| 文件 | 大小 | 放置位置 |
|---|---|---|
svdq-int4_r32-flux.1-fill-dev.safetensors |
~6.77GB | ComfyUI/models/diffusion_models/ |
ae.safetensors(Flux VAE) |
~159MB | ComfyUI/models/vae/(通常已有) |
clip_l.safetensors |
~246MB | ComfyUI/models/clip/(通常已有) |
t5xxl_fp16.safetensors |
~9.8GB | ComfyUI/models/clip/(通常已有) |
下载来源
svdq-int4_r32-flux.1-fill-dev.safetensors下载地址:https://modelscope.cn/models/nunchaku-tech/nunchaku-flux.1-fill-dev/files
clip_l.safetensors和t5xxl_fp16.safetensors下载地址:https://modelscope.cn/models/AI-ModelScope/flux_text_encoders/files
注:huggingface是通常是官方上传,魔塔上可能不是官方上传,文件名可能不同,需根据文件作用建立映射。
### 2.4 nunchaku Python 包安装
#### 确定版本
查看自己的环境:
- `python --version` → Python 3.12
- `python -c "import torch; print(torch.__version__)"` → 2.9.0+cu126
选择对应 wheel:
nunchaku-{version}+torch{torch_version}-cp{python_version}-cp{python_version}-win_amd64.whl
示例(Python 3.12, torch 2.9):
nunchaku-1.0.0+torch2.9-cp312-cp312-win_amd64.whl
#### 下载 wheel
从 GitHub Releases 下载:
https://github.com/nunchaku-tech/nunchaku/releases
#### 安装(关键:避免 torch 被降级)
```bash
# 不要直接用 pip install xxx.whl(会升级/降级 torch)
# 正确做法:加 --no-deps
pip install nunchaku-1.0.0+torch2.9-cp312-cp312-win_amd64.whl --no-deps
为什么必须 --no-deps?
nunchaku 的依赖声明会拉取特定版本的 torch。如果你本地已经有 CUDA 版的 torch(如 2.9.0+cu126),直接 pip install 可能会:
- 把 torch 升级到更新的 CPU-only 版本(如 2.12.0+cpu)
- 导致 CUDA 不可用,ComfyUI 直接报错
如果不慎 torch 被覆盖了:
# 从本地 wheel 重新安装 GPU 版 torch
pip install torch-2.9.0+cu126-cp312-cp312-win_amd64.whl --force-reinstall --no-deps
pip install torchvision-0.24.0+cu126-cp312-cp312-win_amd64.whl --force-reinstall --no-deps
pip install torchaudio-2.9.0+cu126-cp312-cp312-win_amd64.whl --force-reinstall --no-deps
2.5 工作流加载
- 从官方文档下载工作流 JSON
- 修正模型名(如果模型文件名不同):
- 工作流里可能是
svdq-int4-flux.1-fill-dev - 实际文件是
svdq-int4_r32-flux.1-fill-dev.safetensors - 需要在 NunchakuFluxDiTLoader 节点的 widget 中改成正确的文件名
- 工作流里可能是
- 通过 ComfyUI 的 Load 加载 JSON
2.6 调出蒙版涂抹
- 右键 LoadImage 节点 → Open in MaskEditor
- 红色区域 = 要重绘的区域
- Save to node 保存
三、工作流 JSON 运作机制详解
3.1 什么是 ComfyUI 工作流 JSON
ComfyUI 的工作流本质上是一个 有向无环图(DAG)。每个节点代表一个操作(加载模型、编码文本、采样、解码、保存等),节点之间的连线代表数据流动。工作流 JSON 就是这个图的序列化表示。
3.2 JSON 的两种格式
UI 格式(人机交互用)
直接从 ComfyUI 保存的 .json 文件,包含节点位置、大小、颜色等 UI 信息:
{
"last_node_id": 59,
"last_link_id": 80,
"nodes": [
{
"id": 59,
"type": "NunchakuFluxDiTLoader",
"pos": [0, 0],
"size": [315, 210],
"widgets_values": ["svdq-int4_r32-flux.1-fill-dev.safetensors", 0, "nunchaku-fp16", "auto", 0, "bfloat16", "enabled"],
"inputs": [
{"name": "model_path", "type": "COMBO", "link": null},
...
],
"outputs": [
{"name": "MODEL", "type": "MODEL", "links": [42]}
]
}
],
"links": [
[42, 59, 0, 3, 0, "MODEL"]
]
}
关键字段说明:
nodes:所有节点的数组id:节点唯一编号type:节点类型,对应 ComfyUI 注册的类名widgets_values:节点上可直接填写的参数值(按顺序对应)inputs:输入接口,link表示连接到哪个输出outputs:输出接口,links表示连接到哪些输入
links:连接线数组,格式[link_id, from_node_id, from_slot, to_node_id, to_slot, type]
API 格式(程序调用用)
通过 HTTP API 提交时使用的简化格式,省略了 UI 信息:
{
"59": {
"class_type": "NunchakuFluxDiTLoader",
"inputs": {
"model_path": "svdq-int4_r32-flux.1-fill-dev.safetensors",
"cache_threshold": 0,
"attention": "nunchaku-fp16",
"cpu_offload": "auto",
"device_id": 0,
"data_type": "bfloat16",
"i2f_mode": "enabled"
}
}
}
区别:
- 节点 ID 做 key,而不是放在 nodes 数组里
- 连线用
["source_node_id", output_slot]表示,例如"clip": ["34", 0]表示从节点 34 的 0 号输出取 CLIP - 没有 UI 布局信息
class_type就是 UI 格式里的type
3.3 从 JSON 到实际执行——ComfyUI 的工作流执行流程
JSON 加载 → 节点实例化 → 拓扑排序 → 逐节点执行
- 加载 JSON:ComfyUI 解析 JSON,为每个
class_type创建对应的节点对象 - 建立连接:根据
links(UI 格式)或 inputs 里的引用(API 格式)建立节点间的数据通道 - 拓扑排序:按依赖关系确定执行顺序。例如必须先加载模型,才能用模型采样
- 逐节点执行:每个节点从输入接口接收数据,执行操作,将结果传给输出接口
3.4 本项目的 Flux Fill 工作流执行流程分解
以我们的 API 工作流为例,按实际执行顺序:
Step 1: 加载模型
DualCLIPLoader (34) → 加载 clip_l + t5xxl 文本编码器 → 输出 CLIP
VAELoader (32) → 加载 ae.safetensors(Flux VAE)→ 输出 VAE
NunchakuFluxDiTLoader (59) → 加载 4-bit 量化 Flux Fill → 输出 MODEL
LoadImage (20) → 加载 test1.jpg + 附带的掩码 → 输出 IMAGE + MASK
Step 2: 预处理
ImageAndMaskResizeNode (58) → 把 IMAGE 和 MASK 缩放到 1024×1024 → 输出 IMAGE + MASK
CLIPTextEncode (23) → 把提示词编码为语义向量 → 输出 CONDITIONING
CLIPTextEncode (7) → 把空文本编码为占位 → 输出 CONDITIONING
Step 3: 重绘条件注入
InpaintModelConditioning (38) → 核心节点,做三件事:
① 用 VAE 把输入图编码到潜空间(image → latent)
② 把掩码嵌入 latent 作为 noise_mask
③ 把正/负条件传递下去
→ 输出 positive + negative CONDITIONING + 带 noise_mask 的 LATENT
Step 4: 采样(核心推理)
FluxGuidance (26) → 给 conditioning 加上 guidance 参数(控制提示词影响强度)
KSampler (3) → 扩散采样:
① 从带 noise_mask 的 latent 开始
② 在掩码区域逐步去噪(20-30步)
③ 每步参考 CONDITIONING 调整生成方向
④ 非掩码区域保持原图latent不变
→ 输出采样后的 LATENT
Step 5: 解码输出
VAEDecode (8) → 把 latent 解码回 RGB 图像
SaveImage (9) → 保存为 PNG 文件
3.5 常见的 JSON 修改场景
| 场景 | 改什么字段 | 示例 |
|---|---|---|
| 换模型 | 模型加载节点的 widgets_values / model_path | svdq-int4_r32-flux.1-fill-dev.safetensors |
| 改提示词 | CLIPTextEncode 的 text | "modern LED car headlight" |
| 调采样参数 | KSampler 的 seed/steps/cfg | "steps": 30 |
| 换输入图 | LoadImage 的 image | "test1.jpg" |
| 换输出前缀 | SaveImage 的 filename_prefix | "car_light_result" |
| 加新的处理步骤 | 新增节点 + 连接线 | 加一个 upscale 节点 |
3.6 UI 格式 → API 格式的转换要点
当需要把 ComfyUI 保存的 UI 工作流转为 API 调用时:
- 遍历
nodes,提取每个节点的id、type、widgets_values - 遍历
links,建立节点间的连接关系 - 对有 widget 值的节点,参数名需要查
object_info确定 - 将
widgets_values按顺序映射到对应的参数名 - 连线用
["from_node_id", output_slot]表示
特别注意:widgets_values 的顺序不一定是参数名的字母序,必须通过 object_info 接口查询节点的 INPUT_TYPES 定义来确定哪个值对应哪个参数。
四、踩坑记录(详细版)
坑 1:模型名不一致 — NunchakuFluxDiTLoader 找不到模型
现象:在 ComfyUI 的 Load Image 节点里上传了图片,在蒙版编辑器里涂抹好了要重绘的区域,点击 Queue Prompt 后,弹出红色错误提示:
NunchakuFluxDiTLoader 59:
- Value not in list: model_path: 'svdq-int4-flux.1-fill-dev' not in [...]
原因:从 nunchaku 官网下载的工作流 JSON 里,NunchakuFluxDiTLoader 节点 widget_values 里的模型名是 svdq-int4-flux.1-fill-dev(没有 _r32),但实际放在 models/diffusion_models/ 目录下的模型文件名是 svdq-int4_r32-flux.1-fill-dev.safetensors(有 _r32 并且带 .safetensors 后缀)。模型文件可能是从魔塔社区等非官方源下载的,文件名与工作流预期的不一致。
解决:
- 在 ComfyUI 界面中,找到 NunchakuFluxDiTLoader 节点
- 在 model_path 下拉框中,不选原来的名字,手动选择
svdq-int4_r32-flux.1-fill-dev.safetensors - 或者直接编辑 JSON 文件,找到 NunchakuFluxDiTLoader 节点的
widgets_values[0],改成正确的文件名
坑 2:nunchaku Python 包版本不匹配 — 插件报 ModuleNotFoundError
现象:启动 ComfyUI,控制台打印大量红色错误:
ComfyUI-nunchaku 1.2.1 requires nunchaku >= v1.0.0, but found nunchaku 0.3.2.
Node `NunchakuFluxDiTLoader` import failed:
ModuleNotFoundError: No module named 'nunchaku.caching.fbcache'
然后 ComfyUI 虽然启动了,但节点列表里找不到 NunchakuFluxDiTLoader,工作流无法运行。
原因:ComfyUI-nunchaku 插件(v1.2.1)要求底层的 nunchaku Python 包版本 >= v1.0.0。如果安装了旧版(如 0.3.2),插件加载时会因为 API 不兼容而失败。这类似于"驱动版本太旧,新软件不认"。
解决:去 GitHub Releases 下载跟 Python 版本、torch 版本、操作系统匹配的 wheel 文件。例如 Python 3.12 + torch 2.9 + Windows 需要 nunchaku-1.0.0+torch2.9-cp312-cp312-win_amd64.whl,然后用 pip install 安装。
坑 3:torch 被 pip 偷偷升级为 CPU-only 版
现象:重装 nunchaku 后启动 ComfyUI,直接报错退出:
AssertionError: Torch not compiled with CUDA enabled
torch.cuda.is_available() 返回 False。本来能用的 GPU 突然不能用了。
原因:pip install nunchaku-xxx.whl 时,pip 会自动分析 wheel 的依赖关系。nunchaku 的 pyproject.toml 里写了 torch>=2.0.0,pip 检查发现当前 torch 版本满足条件就没动。但是!如果 pip 发现 torch 的某些依赖不满足(比如装了一些其他包导致 torch 被标记为"损坏"),它会从 PyPI 重新下载 torch——而 PyPI 上的最新 torch 是 CPU-only 版本(没有 CUDA 支持)。下载链接是 pypi.tuna.tsinghua.edu.cn 这个清华源,它提供的 torch 包是 CPU 版的。
解决:
方案 A(推荐):安装 nunchaku 时加 --no-deps:
pip install nunchaku-1.0.0+torch2.9-cp312-cp312-win_amd64.whl --no-deps
这样 pip 只装 nunchaku 本身,不碰 torch 和任何依赖。
方案 B(如果不慎已升级):从本地已有的 GPU 版 torch wheel 重装:
pip install torch-2.9.0+cu126-cp312-cp312-win_amd64.whl --force-reinstall --no-deps
pip install torchvision-0.24.0+cu126-cp312-cp312-win_amd64.whl --force-reinstall --no-deps
pip install torchaudio-2.9.0+cu126-cp312-cp312-win_amd64.whl --force-reinstall --no-deps
坑 4:access violation 崩溃 — nunchaku 加载模型时内存访问错误
现象:点击 Queue Prompt 后,ComfyUI 界面卡住,控制台打印:
Windows fatal exception: access violation
Stack (most recent first):
File "torch/storage.py", line 470 in __getitem__
File "nunchaku/utils.py", line 163 in load_state_dict_in_safetensors
然后整个 ComfyUI 进程崩溃退出。
原因:nunchaku 在加载 6.77GB 的量化模型文件时,访问了无效的内存地址。可能的原因有:
- 模型文件在下载过程中损坏了(6.77GB 大文件,用 curl 下载容易断、容易缺字节)
- ComfyUI 的模型缓存(cache)跟刚更新的 nunchaku 版本有冲突
- 显存不足或内存碎片导致分配失败
解决:
- 先重启 ComfyUI(不是重载,是完全关闭进程再启动),这能清空模型缓存
- 如果重启后仍然崩溃,说明模型文件大概率坏了,需要重新下载
- 重新下载时建议用浏览器下载(浏览器有断点续传和校验),而不是 curl
坑 5:模型文件下载损坏
现象:模型文件看起来存在(6.77GB),但一加载就 crash 或报错。
原因:6.77GB 的大文件通过 curl 下载时(尤其是经过代理),网络抖动会导致文件内容不完整或损坏。dir 命令看到的文件大小是对的(6.77GB),但里面某些字节是错的。
解决:
- 用浏览器手动下载,浏览器有重试和完整性校验
- 如果 HuggingFace 慢,用魔塔社区镜像
- 下载后检查文件大小是否与源站一致
- 存放路径:
ComfyUI/models/diffusion_models/svdq-int4_r32-flux.1-fill-dev.safetensors
坑 6:ImageAndMaskResizeNode 参数名对不上
现象:通过 ComfyUI API 提交工作流时,返回 400 错误:
ImageAndMaskResizeNode 58:
- Required input is missing: mask_blur_radius
- Required input is missing: resize_method
- Required input is missing: crop
原因:从工作流 JSON 里看到的节点参数名(widgets_values 里的字段)跟 ComfyUI 实际注册的节点接口参数名可能不一样。例如工作流 JSON 里的字段叫 interpolation 和 method,但 ComfyUI 的 ImageAndMaskResizeNode 实际接受的参数名是 resize_method 和 crop。这是因为 ComfyUI 的 API 参数名由节点的 INPUT_TYPES 定义,而 JSON 里 widgets 的排列顺序和命名不一定跟 API 参数名一一对应。
解决:不要猜参数名,直接问 ComfyUI:
import requests
d = requests.get('http://127.0.0.1:8188/object_info').json()
node_info = d['ImageAndMaskResizeNode']
for k, v in node_info['input']['required'].items():
print(f'{k}: {v}')
这会打印出节点真正接受的参数名和类型。然后按打印出来的名字传参:
# 错误写法(从JSON里猜的):
inputs = {'interpolation': 'lanczos', 'method': 'center'}
# 正确写法(从 object_info 查到的):
inputs = {'resize_method': 'lanczos', 'crop': 'center', 'mask_blur_radius': 10}
坑 7:DualCLIPLoader 只有一个 CLIP 输出
现象:提交 API 工作流时报错:
CLIPTextEncode 7:
- Exception when validating inner node: tuple index out of range
原因:DualCLIPLoader 虽然名字里有"Dual"(双),但它只有一个 CLIP 输出(slot 0)。写工作流的时候想当然地认为"双 CLIP 加载器应该有两个 CLIP 输出,一个给正向提示词,一个给负向提示词",就把正 CLIPTextEncode 连到 slot 0、负 CLIPTextEncode 连到 slot 1。但 slot 1 根本不存在,所以报 “tuple index out of range”。
实际上 DualCLIPLoader 的内部实现是:一个 CLIP 模型同时加载两个 CLIP(clip_l 和 t5xxl),合并成一个输出。所以正/负提示词都从 slot 0 取就行。
解决:
# 错误写法
'positive_clip': ['34', 0], # 正确
'negative_clip': ['34', 1], # 不存在!报错
# 正确写法
'positive_clip': ['34', 0],
'negative_clip': ['34', 0], # 也用 slot 0
坑 8:ComfyUI 模型缓存导致第二次加载崩溃
现象:第一次运行工作流成功了(模型加载、推理、出图都正常),但关掉 ComfyUI 再打开,同样的工作流、同样的参数,第二次运行时在模型加载阶段就崩溃了(access violation 或 CUDA OOM)。
原因:ComfyUI 有模型缓存机制。第一次加载模型时,模型文件被读入内存并分派到 GPU。关闭 ComfyUI 后,缓存在内存中的模型数据并没有完全清理干净,或者 GPU 显存没有被完全释放。第二次启动时,缓存中的部分数据跟新加载的模型冲突。此外,nunchaku 的量化模型加载器在初始化时分配了固定的显存缓冲区,如果上次留下的碎片没有回收,第二次分配就会访问到无效地址。
解决:
- 最直接的方法:完全关闭 ComfyUI 进程(不是关窗口,是在任务管理器确认进程已结束)
- 等待几秒让 GPU 显存彻底释放
- 重新启动 ComfyUI
- 如果还是崩溃,可以试试在启动参数中加
--lowvram或--normalvram来调整显存策略 - 如果频繁出现,建议在 ComfyUI 的
extra_model_paths.yaml中禁用模型缓存
五、成功后的技术栈
Hardware: RTX 4060 Ti 16GB
Software: ComfyUI 0.18.1 + nunchaku 1.0.0 + torch 2.9.0+cu126
图像 → LoadImage → ImageAndMaskResizeNode → InpaintModelConditioning
↓
DualCLIPLoader → CLIPTextEncode(prompt) ─────────────┘
↓
FluxGuidance → KSampler → VAEDecode → SaveImage
↑
NunchakuFluxDiTLoader(svdq-int4_r32) ──────┘
实测性能:
- 20 步推理:~11 秒(GPU)
- 首次加载模型:~30 秒
- 总执行时间:~28 秒
- 显存占用:~10GB / 16GB
六、与 BrushNet 的对比
| 维度 | BrushNet SDXL | Nunchaku Flux Fill |
|---|---|---|
| 模型大小 | ~1.5GB | ~6.77GB(量化后) |
| 显存占用 | ~8GB | ~10GB |
| 推理速度 | ~15s | ~11s(20步) |
| 效果 | 差(修复导向) | 较好(重设计导向) |
| 社区认可度 | 低 | liblib 高点赞 |
| 技术来源 | 个人/学术 | MIT Han Lab(韩松实验室)+ Black Forest Labs |
| 技术路线 | 简单 ControlNet 式 | Flux Fill + 量化加速 |
结论:Nunchaku Flux Fill 效果明显优于 BrushNet,且 16GB 可跑,是目前的最佳路线。
七、实验记录:车灯局部重绘
实验信息
| 项目 | 内容 |
|---|---|
| 实验编号 | EXP-001 |
| 日期 | 2026-06-07 |
| 模型 | svdq-int4_r32-flux.1-fill-dev (Nunchaku 量化版 Flux Fill) |
| 硬件 | RTX 4060 Ti 16GB |
| 推理用时 | ~20秒(含模型加载+20步采样+解码) |
输入
原图:test1.jpg(3497×1960),一辆车的车灯区域特写

蒙版:用户在 ComfyUI 中用 MaskEditor 涂抹了车灯区域(白色 = 重绘区域)
提示词:
modern LED car headlight, sleek futuristic design,
flowing light lines, high quality automotive lighting
工作流各节点详解
节点20: LoadImage
└─ 加载 test1.jpg,输出 IMAGE(RGB 张量)
节点21: LoadImage
└─ 加载 car_light_mask_l.png(用户涂抹的蒙版文件),输出 MASK(单通道灰度)
注:蒙版白色区域 = 要重绘的区域,黑色区域 = 保持原图不变
节点58: ImageAndMaskResizeNode
├─ 输入:IMAGE + MASK
├─ 参数:width=1024, height=1024, resize_method=lanczos, crop=center
└─ 作用:将 3497×1960 的大图缩放到 1024×1024(Flux 模型原生分辨率),
蒙版同步缩放,超出部分按 center 裁剪
节点34: DualCLIPLoader
└─ 加载 Flux 的文本编码器(clip_l + t5xxl),输出 CLIP
节点23: CLIPTextEncode(正向提示词)
├─ 输入:CLIP + 提示词文本
└─ 输出:CONDITIONING(将"modern LED car headlight..."编码为模型可理解的语义向量)
节点7: CLIPTextEncode(负向提示词)
├─ 输入:CLIP + 空文本
└─ 输出:空的 CONDITIONING(Flux 不需要负向条件,但 InpaintModelConditioning 需要占位)
节点38: InpaintModelConditioning(核心重绘逻辑)
├─ 输入:positive/negative conditioning + VAE + IMAGE + MASK
├─ 参数:noise_mask=True
├─ 作用:
│ 1. 用 VAE 对输入图编码为潜空间张量(latent)
│ 2. 把蒙版嵌入到 latent 中作为 noise_mask
│ 3. 蒙版区域在采样时会被注入噪声并重新生成,非蒙版区域受保护
└─ 输出:positive/negative conditioning + 带 noise_mask 的 latent
节点32: VAELoader
└─ 加载 Flux 的自编码器(ae.safetensors),负责图像↔潜空间的转换
节点59: NunchakuFluxDiTLoader(量化模型加载)
├─ 加载 4-bit 量化的 Flux Fill 模型(6.77GB→显存占用约 10GB)
├─ 参数:attention=nunchaku-fp16, data_type=bfloat16, cpu_offload=auto
└─ 输出:MODEL(量化后的 Flux Fill DiT 模型)
节点26: FluxGuidance
├─ 输入:conditioning + guidance=10.0
└─ 作用:给 conditioning 添加 guidance 信息,控制生成对提示词的遵循程度
节点3: KSampler
├─ 输入:MODEL + positive/negative + latent + 采样参数
├─ 参数:seed=42, steps=20, cfg=1.0, sampler=euler, scheduler=normal, denoise=1.0
├─ 作用:核心扩散采样过程
│ 1. 从 latent 开始,在蒙版区域逐步去噪
│ 2. 每步根据 CONDITIONING 引导生成方向
│ 3. 非蒙版区域用原图的 latent 直接复制
│ 4. 20 步后得到最终 latent
└─ 输出:采样完成的潜空间张量
节点8: VAEDecode
├─ 输入:latent + VAE
└─ 作用:把潜空间张量解码为 RGB 图像(1024×1024)
节点9: SaveImage
└─ 保存输出图像为 car_light_result_XXXXX_.png
输出
生成图:car_light_result_00001_.png(1288KB,1024×1024)

生成时间:23.94秒
效果:还行,至少能看。
数据流汇总
test1.jpg ─→ LoadImage ─┐
├→ ImageAndMaskResizeNode ─→ InpaintModelConditioning ─→ FluxGuidance ─→ KSampler ─→ VAEDecode ─→ SaveImage
car_light_mask_l.png ─→ LoadImage ─┘ ↑ ↑
ae.safetensors(VAE) svdq-int4_r32-flux.1-fill-dev
八、给未来的自己
- 搜索用对工具:web_search 局限性大,在有网络限制环境中效果差。优先用专业 AI 搜索(如 Kimi)或直接去 GitHub / HuggingFace / 魔塔社区搜。
- 下载用浏览器:大文件(>1GB)浏览器下载比 curl 稳定、可续传、速度快。
- 建模名映射:从非官方源下载模型时,文件名可能不同。理解每个模型的作用,按功能映射而非按名字映射。
- pip install 加 --no-deps:安装大型依赖时,防止 torch 等核心库被意外覆盖。
- 官方文档优先:遇到新工具时,先去官网看文档(如 nunchaku.tech),比二手资料可靠。
九、关于comfyui的MaskEditor的问题
我用了那个comfyui的MaskEditor,涂抹之后会在E:\ComfyUI\input\clipspace生成四个文件:clipspace-mask-1780817644860.png、clipspace-paint-1780817644860.png、clipspace-painted-1780817644860.png、clipspace-painted-masked-1780817644860.png,跟我想象的不一样,我以为只要一张黑白的掩码图就可以了,但是我看这四张只有clipspace-paint-1780817644860.png是黑色的,但也没有白色的部分,怎么回事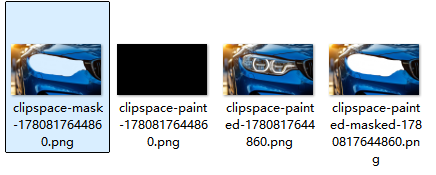
这四张都是 ComfyUI 的临时缓存文件,你不需要手动去碰它们,真正传给 BrushNet 的掩码已经在 Load Image 节点里自动绑定了。
四张文件分别是什么
| 文件名 | 实际内容 | 用途 |
|---|---|---|
clipspace-mask-...png |
真正的掩码(黑底 + 白色涂抹区域) | 传给 BrushNet 的 MASK 输入 |
clipspace-paint-...png |
画笔笔触记录(透明背景 + 红色笔触) | 临时缓存,可忽略 |
clipspace-painted-...png |
原图 + 红色遮罩预览叠加 | 给你肉眼确认范围的 |
clipspace-painted-masked-...png |
被遮罩区域挖空后的预览 | 临时预览 |
为什么 clipspace-paint 看起来是黑的?
因为那张图是透明背景(RGBA),只有红色笔触有像素。Windows 默认的图片查看器会把透明区域显示成纯黑色,所以看起来"全黑"。
如果你用 Photoshop 或支持透明通道的查看器打开,会看到它是透明底 + 红色涂抹痕迹。
真正有用的掩码长什么样?
clipspace-mask-...png 才是标准掩码:
- 黑色 = 保留原图(不画)
- 白色 = 交给 AI 重绘
但你在 Windows 照片查看器里可能也看不清,因为白色区域可能很细,或者和背景对比不明显。
你不需要管这些文件
在 ComfyUI 工作流里:
Load Image节点上传原图- 右键 → Open in MaskEditor 涂抹
- 点 Save to node
- 这个节点的 MASK 输出端 已经自动包含了你涂的遮罩
你直接把这个 MASK 连到 BrushNet 的 mask 输入就行,不需要手动去找 E:\ComfyUI\input\clipspace 里的文件。
验证方法
如果你不放心,在 ComfyUI 里加一个 Preview Image 节点:
- 把
Load Image的 MASK 输出连到Preview Image - 运行后你会看到一张黑底白块的图,白色部分就是你涂的区域
如果 Preview 出来是白的,说明遮罩正确,BrushNet 会只在那块区域动笔。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0


 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)