生产环境Agent避坑指南:从玩具到落地的12条核心经验
很多人写的 Agent 在本地跑 demo 的时候一切完美:能调工具、能查资料、能一步步完成任务。但一上生产就原形毕露:模型输出乱码、死循环跑不停、知识库给错误答案、多 Agent 互相打架……最后只能沦为演示工具。
这篇文章总结了在生产环境落地 Agent 踩过的所有坑,以及工业界经过验证的解决方案。看完你会发现,Agent 开发的难点从来不是“能不能跑通”,而是“能不能稳定跑一万次不出错”。
一、基础能力的工程化:这些细节决定了你的 Agent 能不能活过上线第一天
很多人觉得 Agent 的核心是大模型,只要模型够强,其他都是小事。但实际上,生产环境 90% 的问题都出在基础能力的工程化上。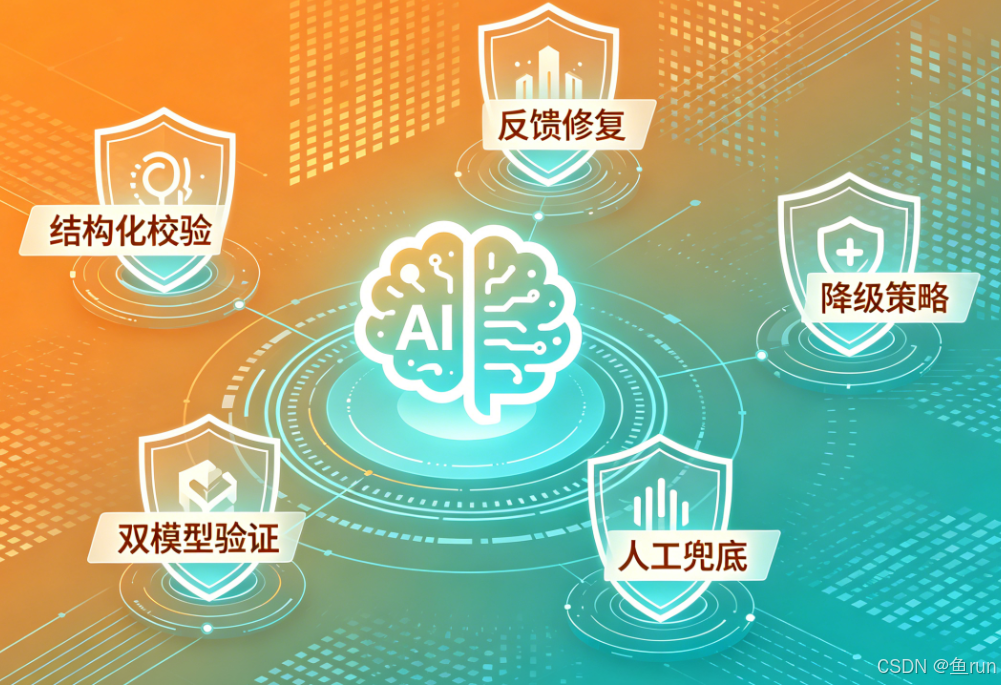
1.1 模型输出失败的全链路容错:不止是重试
下面是工业界标准的五层防御流程图,展示了从模型输出到最终兜底的完整容错链路:
模型输出失败是 Agent 最常见的问题,没有之一。很多人遇到失败只会简单重试,但这远远不够。
首先,我们要把失败分成四类,每一类的处理方式都不一样:
- 格式失败:模型没有按照约定的 JSON 或结构化格式返回,比如多了前后缀、少了闭合括号
- 内容失败:模型输出了“我无法回答这个问题”或者无关内容,甚至直接幻觉编造
- 调用失败:API 超时、限流、服务端 5xx 错误等基础设施层面的问题
- 逻辑自洽失败:模型输出了一个行动计划,但前后步骤互相矛盾。比如第一步说“先查数据库”,第二步却直接“根据用户输入生成答案”,跳过了查询环节
工业界标准的容错方案是五层防御:
- 结构化校验层:在模型输出后、业务逻辑前,用 Pydantic 做强校验。如果校验失败,不直接抛错
- 反馈修复重试:把错误信息塞回 prompt,让模型自己修正格式或逻辑错误,最多重试 2-3 次
- 降级策略:如果模型持续失败,跳过当前 Agent 节点,使用预设的规则引擎兜底
- 双模型交叉验证:对于关键业务,用一个小模型快速验证大模型的输出是否合理
- 最终兜底:给用户一句“暂时无法处理,已转人工”,同时保存完整上下文待后续处理
参考资料:
1.2 RAG 检索的工程化真相:向量数据库不是银弹
完整的 RAG 流程涉及多个环节,每个环节都有潜在的坑。下面是标准 RAG 流水线:
RAG 是现在最火的技术,但很多人对它的理解停留在“把文档扔向量数据库里就行”。实际上,RAG 的每一个环节都有坑。
完整的 RAG 流程应该是:
文档解析 → 特殊内容预处理 → 文本分块 → 生成向量 → 混合检索 → 重排序 → 上下文注入
这里有几个最容易被忽略的细节:
- 表格和代码块不能硬切:普通的文本分块器会把表格和代码块切成碎片,导致检索不到。需要用专门的表格解析器和代码摘要提取工具
- 不要只用向量检索:一定要加上关键词检索做混合检索,很多时候精确匹配比相似性匹配更准确
- PostgreSQL + pgvector 可能比专用向量数据库更适合你:对于大多数中小项目,用 PostgreSQL 的 pgvector 扩展就能满足需求,省去维护两个数据库的麻烦。而且 PostgreSQL 的事务特性和行级锁,对于 Agent 的会话状态管理非常有用
RAG 效果也不能靠感觉,必须用可量化的指标来评估:
- Recall@K:前 K 个检索结果中包含相关文档的比例,K 一般取 5 或 10
- MRR:第一个相关文档的排名的倒数取平均,适合“只要一个正确答案”的场景
- NDCG:考虑排序位置和相关性等级,适合有分级标注的场景
参考资料:
1.3 Agent 死循环与重复输出:如何从根源上治理
死循环是 ReAct 模式 Agent 的头号杀手。模型会反复调用同一个工具,或者输出完全一样的内容,直到把 Token 烧光。
死循环的检测方法:
- 设置最大迭代次数(一般 10 步足够),超过就强制终止
- 检测重复的 observation 内容,连续两次一样就判定死循环
- 流式输出时做滑动窗口实时检测,一旦发现连续几轮输出相似度过高,提前打断
从根源上解决死循环的方案:
- 在 prompt 中明确要求“每步必须推进状态,禁止重复相同动作”
- 在会话状态中记录历史动作,让模型知道“我已经做过这些了”
- 增加元认知步骤:每执行 3 步后,让模型自己判断“我是不是在原地打转?”如果是,主动换策略
参考资料:
1.4 工具可插拔架构:让你的 Agent 随时扩展新能力
下面是注册中心模式的工具架构设计,展示了工具如何被统一管理和动态调用:
一个好的 Agent 架构,应该能在不修改核心代码的情况下,随时添加新工具。
工业界通用的设计是注册中心模式:
- 每个工具实现统一的接口:name、description、input_schema、execute 方法
- 启动时动态扫描并注册到工具管理器
- 用配置文件驱动工具列表,Agent 根据用户意图从注册表中匹配工具
如果需要支持工具的热加载(不重启服务),可以用两种方案:
- 插件目录监听:用 watchdog 监控插件目录,有新文件自动加载
- 独立工具服务:用 gRPC 调用独立的工具服务,工具服务可以独立升级
现在 MCP(模型上下文协议)已经成为了工具标准化的事实标准。它定义了统一的 tool schema 和通信协议,一个工具写好之后,所有主流 Agent 框架都能直接调用。
参考资料:
二、复杂项目的边界治理:解决 90% 生产问题的关键
当你的 Agent 从单任务 demo 变成复杂的多模块系统时,会遇到很多基础能力覆盖不到的问题。这些问题才是真正区分玩具和生产系统的关键。
2.1 多 Agent 决策冲突:谁来当最终的裁判
多 Agent 系统的决策冲突需要分层治理,下面是三层冲突解决机制的完整流程:
多 Agent 系统最大的问题就是决策冲突。比如一个负责设计的 Agent 说用 Redis 缓存,一个负责实现的 Agent 却直接用数据库查询,最后产出的代码完全不对。
解决冲突的三层方案:
- 共享上下文约束:所有子 Agent 启动时,先加载主 Agent 的输出作为“不可变约束”,不能违背
- 冲突检测规则:预定义常见的冲突模式(比如缓存方案 vs 直查数据库),检测到冲突就暂停执行
- 仲裁 Agent 机制:引入一个专门的仲裁 Agent 来判断冲突双方谁对谁错。如果仲裁 Agent 也无法判断,就降级为人工确认

记住一个原则:所有自动化决策都要有人类介入的出口。没有任何 AI 系统能做到 100% 正确,最终的兜底永远是人。
2.2 知识库治理:过期错误的知识比没有知识更可怕
这是一个坑。举例:规则库里有一条“禁止使用 async/await”,那是两年前的技术决策,后来已经废弃了。但 AI 依然严格遵守这条规则,生成的代码全是回调风格,被 Code Review 打回了无数次。
知识库治理的核心是建立完整的生命周期:
- 版本标记:每条规则带生效时间范围和版本号,AI 会检查规则是否适配当前代码库基线
- 优先级划分:明确区分“必须遵守的强制规则”和“仅供参考的经验建议”,规则的优先级永远高于 RAG 检索结果
- 反馈闭环:当开发者发现 AI 遵守了错误规则时,可以一键“报告规则错误”,触发审核流程
- 规则健康度评分:统计每条规则被 AI 遵循的次数和被人纠正的次数,得分过低的规则自动降级或删除
2.3 大型存量项目适配:如何让 AI 看懂几十万行代码
在一个几十万行的存量项目里,AI 最大的问题就是“看不懂全局”。它只能看到你给它的那几个文件,做出的决策往往是局部最优但全局错误。
我们的解决方案是:
- 预生成项目结构摘要:包含目录树、每个模块的核心职责、关键入口文件,压缩成几千 Tokens 作为 system prompt 的一部分
- 按需加载源码:AI 不直接看全部代码,而是先读摘要,确定要修改哪个模块后,再通过工具动态读取该模块的关键文件
- CI 自动更新摘要:每次代码合并后,自动重新生成项目结构摘要,确保 AI 永远看到最新的代码

2.4 代码生成的质量与安全:别让 AI 好心办坏事
AI 生成的代码看起来很完美,但实际上藏着很多坑。我们统计过,AI 生成代码的平均采纳率只有 50% 左右,剩下的问题主要分布在:
- 30%:逻辑正确但不符合业务隐含约束
- 20%:使用了已废弃的 API 或过时的写法
- 15%:性能问题(比如 N+1 查询、没有加索引)
- 15%:代码风格不一致
- 20%:完全错误的幻觉代码
为了控制代码生成的质量和安全,可以做两层防护:
- 修改范围沙箱:AI 在生成代码前,必须先声明“我打算修改哪些文件的哪些行范围”。系统校验这个范围是否超出权限,生成后再次校验实际 diff 是否在声明范围内
- 自动化测试验证:要求 AI 生成代码的同时,必须生成对应的测试用例。然后运行单元测试和变异测试,验证代码的正确性
参考资料:
三、生产环境 Agent 落地的 3 条核心原则
最后,总结一下我认为最重要的三条原则,只要遵守这三条,就能避开 80% 的坑。
1. 容错优先:假设每一步都会出错
永远不要相信大模型的输出。假设模型会输出错误格式、会幻觉、会死循环、会调用错误的工具。在每一个环节都设计容错机制,多层防御。
2. 边界清晰:明确哪些事 AI 能做,哪些事必须人来做
不要试图让 AI 解决所有问题。对于高风险、高复杂度的场景,一定要有人工介入的环节。AI 的定位是辅助人类,而不是替代人类。
3. 数据驱动:所有优化都要有可量化的指标支撑
不要仅凭感觉说“我的 Agent 效果很好”。一定要建立可量化的指标体系:成功率、留用率、响应时间、成本。所有的优化都要围绕这些指标展开。
Agent 技术发展到今天,已经不是一个概念了。但从 demo 到生产,还有很长的路要走。希望这篇文章能帮你少踩一些坑,让你的 Agent 真正跑起来。
参考资料

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)