RAG Embedding Reranker 、Bert、CLIP&T5、池化模型
1、Embedding和Reranker
1.1. 总体介绍
Embedding 阶段
核心目标是快速召回,从海量候选集中筛选出 Top-K 相关内容,要求速度快,通常是双塔架构。
对于双塔结构,其实本质上是说有一个并行的网络结构,结构上是两个独立的子网络(塔),分别处理 查询(Query)和候选(Candidate) 的特征,最后通过向量相似度(如内积、余弦相似度)计算匹配分数。
Query → [塔1:Encoder] → Query Embedding
↘
相似度计算(内积/余弦) → 匹配分数
↗
Candidate → [塔2:Encoder] → Candidate Embedding
核心特点
双塔独立,无交叉:Query 和 Candidate 的特征在 Embedding 阶段完全分开处理,两个塔的参数互不干扰,仅在最后一步计算相似度。
支持离线预计算(核心优势),候选集(如文档、商品、向量库中的数据)的 Embedding 可以提前离线计算好,存入向量数据库。
线上推理时,只需要实时计算 Query 的 Embedding,再和向量库中的候选 Embedding 做相似度检索,速度极快(毫秒级)。
牺牲精度换速度,因为缺少 Query 和 Candidate 的深层特征交互,匹配精度相对单塔较低,适合召回阶段。
广泛应用
其实已经广泛应用在许多场景,也是Faiss等向量检索库的存在基础。
Reranker 阶段
核心目标是精准排序,对召回的少量候选集做精细化打分,要求精度高,通常是单塔架构。
Query特征 + Candidate特征 → [单塔:Shared Encoder] → 特征交叉 → 全连接层 → 匹配分数
核心特点
特征深度交叉(核心优势),Query 和 Candidate 的特征从输入层就开始融合,模型可以学习到两者的复杂关联(比如 Query 中的关键词和 Candidate 中上下文的依赖关系),匹配精度远高于双塔。
不支持离线预计算:必须同时输入 Query 和 Candidate 才能计算分数,无法提前缓存 Candidate 的特征。线上推理时,需要对召回的每个候选集都和 Query 一起输入模型计算,速度较慢(适合小批量数据)。
牺牲速度换精度:计算成本高,适合排序阶段(对召回的 Top-K 候选集做精准排序)。
1.2. 单塔和双塔模式
首先先引用一段Qwen官方的介绍文本https://github.com/QwenLM/Qwen3-VL-Embedding:
Qwen3-VL-Embedding 采用双塔架构,可以高效地将不同模态的内容独立编码为统一的向量表示,特别适合处理海量数据的并行计算。Embedding 模型接收单模态或混合模态输入,并将其映射为高维语义向量。我们提取基座模型最后一层中对应 [EOS] token 的隐藏状态向量,作为输入的最终语义表示。这种方法确保了大规模检索所需的高效独立编码能力。
Qwen3-VL-Reranker 采用单塔架构,通过内部的交叉注意力机制,深度分析查询与文档之间的语义关联,从而输出精确的相关性分数。“在实际工作中,Reranking 模型接收输入对 (Query, Document) 并进行联合编码。它利用基座模型内的交叉注意力机制,实现 Query 和 Document 之间更深层、更细粒度的跨模态交互和信息融合。模型最终通过预测两个特殊 token(yes 和 no)的生成概率来表达输入对的相关性分数。
与之有联系的还有Bi-Encoder和Cross-Encoder,bi-encoder 编码时 Query 和 Document 无交互,只能捕捉独立语义;cross-encoder 让两者全程交互,能识别 “上下文依赖、语义歧义、细粒度匹配”。
| 维度 | Bi-Encoder(双塔) | Cross-Encoder(单塔/交互式) |
|---|---|---|
| 处理时机 | Query和Doc独立编码,后期交互 | Query和Doc早期拼接,联合编码 |
| 相似度计算 | 向量点积/余弦相似度 | 深层网络交互后输出分数 |
| 计算复杂度 | O(n) 预处理 + O(1) 检索 | O(n) 逐对计算 |
| 精度 | 较低(信息瓶颈) | 较高(全交互) |
| 适用场景 | 大规模召回(百万级) | 精排/重排序(千级) |
尤其是针对embedding模型,双塔的必要性来自于query和doc的来源不一致,例如面对论文检索场景:长度差异极大,Query 10词 vs Doc 10k词;或者搜索引擎,模态不同,Query是关键词,Doc是全文;另外还有类似医疗问答,领域偏移,Query口语化,Doc学术化。
| 组件 | 作用 | 技术细节 |
|---|---|---|
| 权重共享 | 保证语义空间一致 | Query和Doc使用同一套Transformer参数 |
| CLS Pooling | 句子级表示 | 取首token的隐藏状态 |
| Mean Pooling | 更稳健的选择 | 对所有token取平均,削弱[CLS]偏见 |
| 投影层 | 降维加速检索 | 768→256/128维,配合ANN索引 |
| 温度缩放 | 控制分布锐度 | τ<1使分布更尖锐,训练更稳定 |
1.3 模型微调
Reranker(Cross-Encoder)完全可以重训练/微调,而且是RAG提分性价比最高的环节之一。
- Embedding = BiEncoder 双塔微调(粗召回)
- Reranker = CrossEncoder 单塔微调(精排)
-
训练数据格式(和Embedding三元组不一样)
Reranker用样本对:(query, doc, label)。label=1:相关正样本,label=0:不相关负样本,一条样本就是Query+文档拼接输入。
Embedding是三元组(q, pos_doc, neg_doc);Reranker是二分类标签对。 -
损失函数
标准二分类交叉熵 BCEWithLogitsLoss,优化「输入一对Q-D,预测是否相关」。 -
Embedding微调 vs Reranker微调核心区别
| 项目 | Embedding(Bi-Encoder) | Reranker(Cross-Encoder) |
|---|---|---|
| 输入形式 | q、doc分开过两个encoder | Q+D拼接一起输入同一个模型 |
| 训练数据 | 三元组(q,pos,neg) | 二元组(q,doc,0/1) |
| 算力开销 | 小,文档可以批量预处理 | 大,每条样本Q+D拼接,token更长、全交叉Attention |
| 数据需求量 | 大量正负样本 | 少量高质量样本即可见效(几十~几百条就能明显涨准确率) |
| 作用位置 | 全库粗召回Top20 | 对召回出来的20条重打分 |
Reranker小样本微调收益远大于Embedding,业务私有文档,几十条标注就能干掉大量误召回。
-
RAG落地实操: 通用开源Rerank(Cross-BGE、bge-reranker-base)在自己业务领域不准,比如行业黑话、专业术语、内部文档,通用模型打分错乱 → 微调自家语料。另外就是粗召回结果里很多看似字面相近、实际无关的文档,靠精排筛不掉。
-
总结
✅ Reranker支持重训练、微调,是RAG定制化标配;
✅ Embedding靠三元组对比学习,Reranker靠Q-D配对二分类;
✅ 缺标注优先微调Reranker,少量标注见效更快;标注海量再优化Embedding。
2、BERT(Bidirectional Encoder Representations from Transformers)
Google 于 2018 年提出的预训练语言模型,核心创新是基于 Transformer Encoder (Encoder-only)实现的双向上下文建模,彻底解决了传统预训练模型(如 ELMo 单向、GPT 左到右)无法同时利用左右上下文的问题,在文本分类、命名实体识别、问答等 NLP 任务上实现了性能突破。
2.1、BERT 的核心特性
BERT 仅使用 Encoder,每个 token 能同时关注到左右两侧的上下文信息(比如理解 “苹果” 是水果还是公司,需要依赖前后文)。
-
预训练任务设计
MLM(Masked Language Model):随机掩盖输入中 15% 的 token,让模型预测被掩盖的 token,强制模型学习上下文语义。
NSP(Next Sentence Prediction):让模型判断两个句子是否为连续的上下文(比如句子 A 是 “今天天气很好”,句子 B 是 “我们去公园散步” 为连续;句子 B 是 “猫喜欢吃鱼” 为不连续),学习句子级语义。 -
模型规模
原始 BERT 提供两个版本:
BERT-Base:12 层 Transformer Encoder,768 维隐藏层,12 个注意力头,约 1.1 亿参数。
BERT-Large:24 层 Transformer Encoder,1024 维隐藏层,16 个注意力头,约 3.4 亿参数。
2.2 BERT 的输入向量组成
BERT 的输入是经过特殊处理的 token 序列,最终输入到模型的向量是 3 种向量的逐元素相加,具体组成如下:
-
基础输入:Token Embeddings(词嵌入向量)
作用:将每个离散的 token 转换为低维稠密向量,是输入的基础语义表示。
生成方式:
对输入文本做 WordPiece 分词(解决未登录词问题,比如 “打篮球” 可能被切分为 “打”“篮球”;“Transformer” 是一个完整 token)。
每个 token 对应预训练好的词嵌入矩阵中的一个向量(维度与模型隐藏层一致,如 BERT-Base 为 768 维)。
特殊 token:BERT 定义了 3 个核心特殊 token,必须加入输入序列:
[CLS]:句子的分类标记,放在输入序列的最开头,其对应的输出向量常用于下游分类任务(如文本分类的类别判断)。
[SEP]:分隔标记,用于分隔两个句子(如 NSP 任务、问答任务中的问题和上下文)。
[MASK]:掩码标记,仅用于预训练阶段,替换被掩盖的 token。
示例(句子对输入):
plaintext
原始句子对:句子1“我爱中国”,句子2“中国很美丽”
分词后序列:[CLS] 我 爱 中国 [SEP] 中国 很 美丽 [SEP] -
位置编码:Position Embeddings(位置嵌入向量)
作用:Transformer Encoder 是无序的(仅通过注意力机制建模 token 关系,没有内置的位置信息),因此需要显式加入位置编码,让模型知道每个 token 在序列中的位置。
生成方式:
BERT 使用 可学习的位置嵌入(区别于原始 Transformer 的正弦余弦位置编码)。
位置嵌入的维度与 Token Embeddings 一致(768 维),每个位置( BERT 最大输入长度 512,可能)对应一个唯一的可学习向量。
无论输入序列多长,位置编码的索引从 0 开始递增,超过最大长度会被截断。 -
句子编码:Segment Embeddings(句子嵌入向量)
作用:用于区分输入序列中的不同句子(仅在句子对任务中需要,如 NSP、问答)。
生成方式:
是可学习的向量,维度同样为 768 维。
定义两个句子类型:A 和 B:
第一个句子(含 [CLS])的所有 token 对应 Segment A 向量;
第二个句子的所有 token 对应 Segment B 向量;
若输入是单句子,所有 token 都使用 Segment A 向量。 -
BERT 输入向量的最终计算
BERT 的输入向量是 Token Embeddings + Position Embeddings + Segment Embeddings 的逐元素相加,公式如下:
Input_Vec=Token_Emb+Pos_Emb+Seg_Emb
三个向量的维度完全相同(如 768 维),相加后得到最终的输入表示,送入 Transformer Encoder 进行编码。
注意:是逐元素相加,不是拼接(拼接会导致维度翻倍,增加计算量)。
3、T5(Text-to-Text Transfer Transformer)
Google 于 2019 年提出的 Encoder-Decoder 架构预训练语言模型,其核心创新是将所有 NLP 任务统一为 “文本到文本” 的格式,打破了理解类任务与生成类任务的界限,实现了真正的通用任务适配。不同于 Encoder-only(如 BERT)专注理解、Decoder-only(如 GPT)专注生成,T5 采用完整的 Transformer Encoder-Decoder 结构,兼顾了语义理解和文本生成能力,在翻译、摘要、问答、分类等数十种 NLP 任务上都取得了优异效果。
3.1、 T5 的核心设计理念
T5 的核心思想是:No Task is Special(没有任务是特殊的)。
传统 NLP 任务需要针对不同任务设计不同的输出形式(如分类任务输出标签 ID、翻译任务输出目标文本),而 T5 把所有任务都转化为 “输入文本 → 输出文本” 的形式,仅通过在输入中添加任务前缀来区分任务类型。
示例:不同任务的文本到文本转化,模型设计的优势在于:模型不需要为不同任务设计不同的输出头,预训练和微调的目标完全一致,都是 “生成目标文本”。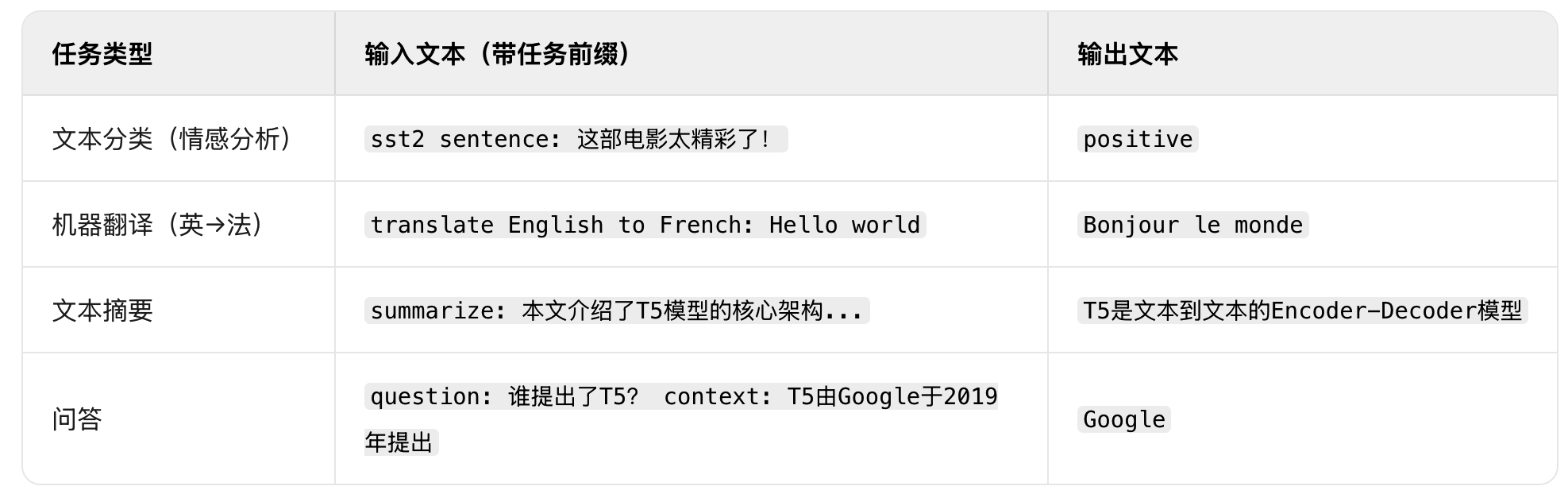
3.2、 T5 的模型架构
T5 采用 标准的 Transformer Encoder-Decoder 结构,由 Encoder、Decoder 两部分组成,且两者均为多层堆叠的 Transformer 块:
- Encoder 部分(编码器)
作用:对输入文本(含任务前缀)进行双向上下文编码,生成源文本的语义表示向量。
结构:每层包含 双向自注意力层 + 前馈神经网络(FFN)。
双向自注意力:输入序列的每个 token 可以关注到左右所有 token,充分理解上下文语义(与 BERT 一致)。
归一化与残差连接:每个子层都配有 Layer Normalization 和残差连接,提升训练稳定性。 - Decoder 部分(解码器)
作用:基于 Encoder 输出的语义表示,自回归生成目标文本。
结构:每层包含 3 个子层,顺序为:
掩码自注意力层:确保生成 token 时只能看到左侧已生成的 token(与 GPT 一致,防止信息泄露)。
Encoder-Decoder 注意力层:解码器的每个 token 可以关注到编码器输出的所有源文本 token(核心是建立输入与输出的关联,比如翻译任务中对齐源语言和目标语言的词汇)。
前馈神经网络(FFN):对注意力输出做非线性变换。
3.3、 T5 的预训练目标:Span Corruption
T5 摒弃了 BERT 的 MLM(掩码语言模型)和 GPT 的 CLM(因果语言模型),采用了全新的预训练目标 ——Span Corruption(片段破坏),更贴近 “文本到文本” 的任务范式。
Span Corruption 的具体流程
随机选择输入文本中的连续片段:比如从句子 T5 is a text-to-text model 中随机选择连续的 2 个 token text-to-text。
用一个特殊 token 替换该片段:特殊 token 的格式为 <extra_id_0>,替换后句子变为 T5 is a <extra_id_0> model。
让模型预测被替换的片段内容:模型的输出目标是 <extra_id_0> text-to-text,即先输出特殊 token,再输出被破坏的片段。
核心优势
相比 MLM 只替换单个 token,Span Corruption 替换连续片段,更能训练模型理解文本的短语级、句子级语义。
预训练目标与下游任务的 “文本到文本” 格式完全一致,减少了预训练到微调的鸿沟。
4、CLIP(Contrastive Language-Image Pre-training)
OpenAI 于 2021 年提出的革命性多模态模型,核心是通过对比学习让图像与文本编码器在同一向量空间对齐,实现零样本分类、跨模态检索等能力。模型架构主要依赖的是双编码器 + 统一嵌入空间。CLIP 由图像编码器和文本编码器两部分组成,两者独立训练但输出向量映射到同一高维空间,结构如下:
核心应用
内容检索:电商商品图搜、视频字幕匹配、学术论文图文检索。
内容审核:图文一致性校验,识别违规图文配对。
多模态交互:智能相册分类、AI 绘画提示优化、机器人视觉语义理解。
衍生模型
FLIP:优化训练效率,降低算力成本;
BLIP:融合生成式能力,提升图文生成与理解精度;
CLIP ViT-L/14-336px:更高分辨率输入,提升细粒度识别能力。
5、Decoder和encoder 架构图
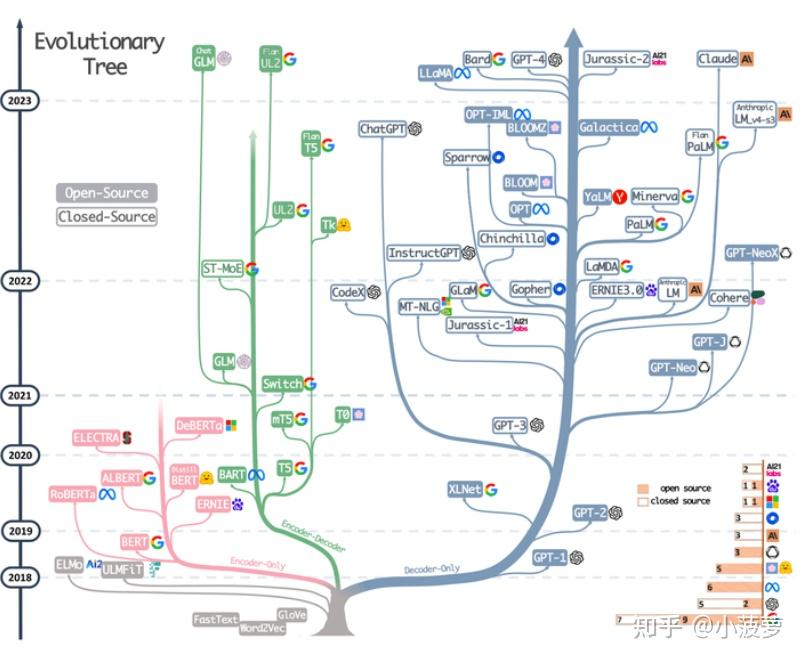
Transformer 的原始架构(《Attention Is All You Need》)由 Encoder(编码器) 和 Decoder(解码器) 两部分组成,两者的核心差异在于注意力层是否有mask层。
Decoder-only 成为大模型主流:GPT、LLaMA 等模型证明,足够大的参数量 + 海量数据能让 Decoder-only 模型兼具理解与生成能力,成为通用大语言模型的首选架构。
Encoder-Decoder 向轻量化演进:通过参数共享、知识蒸馏等技术降低算力开销,专注于高精度序列转换任务。
多模态融合:三大范式均向多模态扩展(如 CLIP 的 Encoder-only、GPT-4 的 Decoder-only、Flamingo 的 Encoder-Decoder),实现图文、音视频的统一建模。
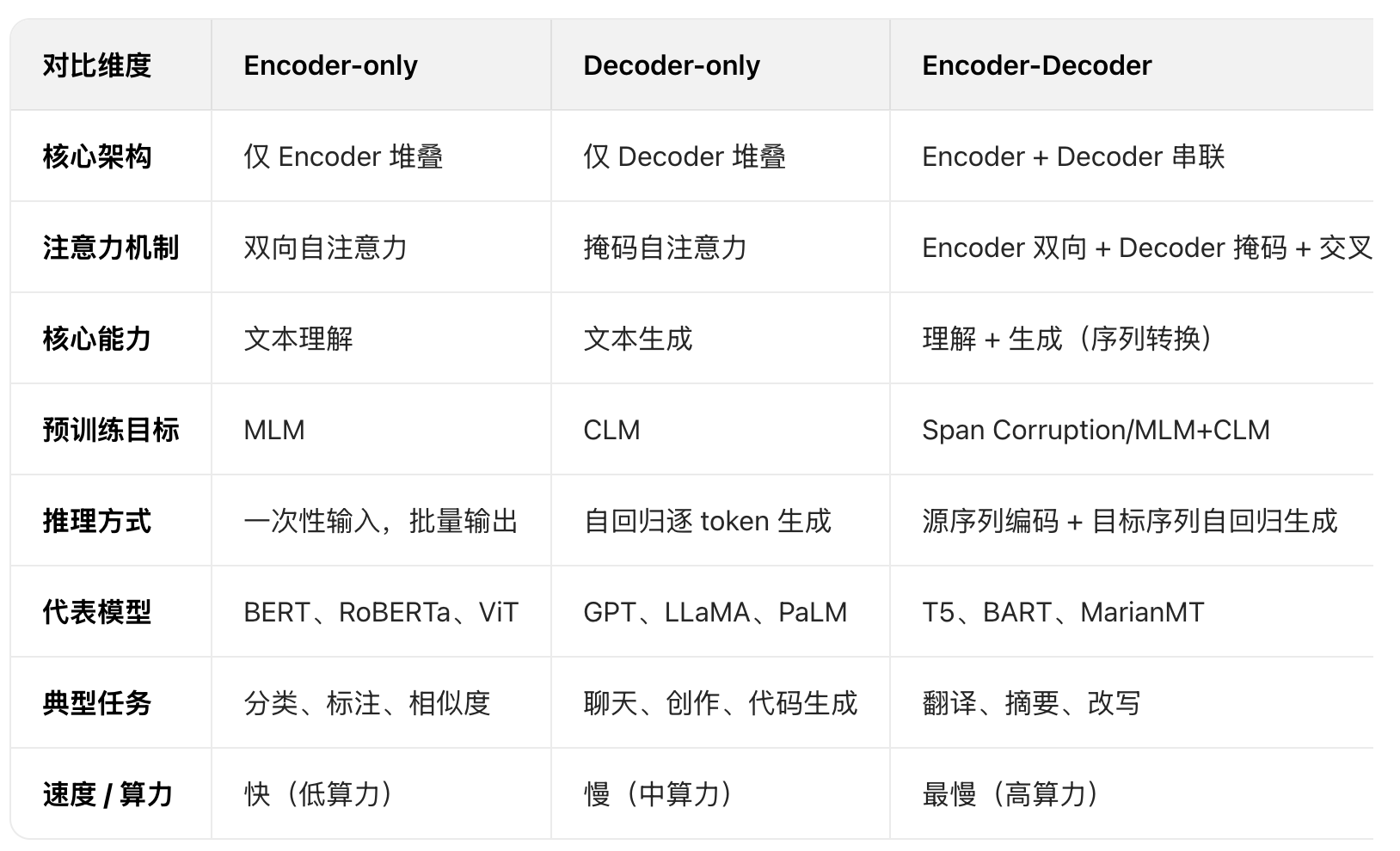
6、池化技术
区别于之前CNN模型中的pooling技术,语言模型中的池化与
BERT 是静态锚点池化(依赖 [CLS] token),Qwen3-Embedding 是动态融合池化(Transformer 类大模型嵌入的主流设计,无专属锚点 token),且后者针对嵌入任务做了专项优化(区别于通用大模型)。
6.1 BERT模型中的池化技术
BERT模型的池化一句话可以概括:[CLS] 锚点单 token 池化,核心依赖[CLS] 特殊 token。BERT 的输入会强制在句首添加 [CLS](Classification)特殊 token,这个 token 的核心作用就是作为全局特征的 “锚点”,其设计逻辑是:
在 Transformer 编码器的多层双向自注意力计算中,[CLS] token 会注意力聚合整个输入序列的所有 token 特征,因为自注意力会让每个 token 关注其他所有 token,而 [CLS] 无实际语义,专门做全局融合),最终编码器输出的**[CLS] token 对应的向量**,就是整个序列的全局聚合向量(即池化结果)。
BERT 的池化实现:直接取 [CLS] 向量(无额外计算,纯索引)
BERT 的池化是最轻量化的池化方式,无任何矩阵运算、激活函数,仅做索引取值
输入序列 → 嵌入层(WordPiece+Position+Segment Embedding加和)→
Transformer Encoder多层编码 → 输出序列向量(shape: [seq_len, hidden_dim])→
取索引0的[CLS]向量(shape: [hidden_dim])→ 池化完成
6.2 Qwen3-Embedding 的池化
均值池化(Mean Pooling)
这是 Qwen3-Embedding最核心的池化方式(也是目前所有大模型嵌入的标配),替代了 BERT 的 [CLS] 单 token 池化,核心逻辑是:用整个序列所有 token 的编码向量的 “均值”,代表全局语义特征,相比单 token 池化,能更充分利用所有 token 的语义信息,表征能力更强。
主要步骤可以分为:
- 带掩码的均值池化(核心计算)
padding 是批量处理的刚需,但 padding token 本身无任何语义信息,只是为了满足张量形状要求,这是掩码存在的前提。padding 的 token 是无实际语义的填充值,若直接参与均值计算会稀释全局特征,因此需要通过 ** 掩码(mask)** 过滤。 - L2 归一化(必做步骤,嵌入任务专属)
均值池化后的向量会做L2 归一化(将向量归一化到单位球面上)
类似于CNN中的池化操作,除了上文提到的均值池化,另外还有max-pooling,甚至于mean-max pooling。均值池化:捕捉序列的整体语义趋势(全局平均特征);最大池化(Max Pooling):捕捉序列的关键语义特征(每个维度上的最大值,突出核心信息);融合方式:将均值池化向量和最大池化向量逐元素拼接 / 加和,再做 L2 归一化,兼顾全局和核心特征。
通过池化可以达到1、序列→单向量,实现定长输出;2、聚合全局语义,保留文本核心信息;3、统一表征形式,保证计算 / 存储的一致性。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)