从小白到入门:AI大模型搭建到底难不难?
你晓得现今最为魔幻的事儿具体是啥么? 乃是所有的人全都清楚AI大模型堪称火爆, 然而绝大多数的人对于它究竟是经由怎样的方式去“搭建”而成的, 却一无所知, 完全摸不着头脑, 处于全然迷糊的状态呢。
上周, 我和一个朋友交谈, 他向我询问, 大模型是否如同把积木一块块堆叠起来那般就可以达成?
我当时没忍住,笑了。后来想想,其实这个比喻也不是完全错。
要说怎么表述呢,人工智能大模型的构建, 更像是去建造一座城市那样, 并非是搭建一群积木这般简单情况。
想搭大模型?先想清楚你到底要干嘛
很多人一上来就问:我要搞一个大模型,从哪开始?
这种问题其实没答案。
只因“大模型”这三个字太过宽泛了, 你是打算从头去训练一个类似GPT那般有着几百亿参数的事物吗? 又或是想着在他人开源模型的基础之上进行微调呢?这两条路径全然不同, 投入的资源能够相差出几个数量级。
比如, 那家名为Meta所开源的Llama系列, 你能够在自身的服务器上面将其运行起来。然而要是你针对同类别的规模要自行从起始点开展训练一个模型的话, 仅仅是光涉及到的电费这一项就能够致使你陷入破产的境地。关于数据方面, 当前存在着像 Crawl这样公开的数据集,它抓取了几十亿数量的网页, 可是你必须得审慎地思考清楚到底该如何进行清洗、怎样去进行重、怎么去处理那些质量不高的内容。
一句话: 别才一开始就去思索着如同制造轮子那般的行为, 先瞅瞅使用轮子这种情况可不可以满足你的所需。
数据准备:这步干不好,后面全白搭
我碰到过好多许多团队, 模型的框架结构挑选决定好了, 训练的代码编制撰写完毕了,然而最终数据的质量状况一片乌七八糟。
关于数据清洗此项事宜, 听闻起来颇是无趣单调, 然而其重要程度无论怎样表述皆不为过。恰似您进行烹饪之事时, 食材如果不新鲜, 即便厨艺超群亦属徒劳无功了。
确切地来论至于特定的数字之上: 身为一个优良的预训练数据集而言, 一般情况下是需要历经最少三四轮的清洗以及过滤的。就拿中文数据当作示例而言, 从最先的那种原始抓取一直到最终能够得以使用, 数据量往往是会出现缩水情况的, 其幅度可以达到从百分之四十到百分之六十之多。这也就是说, 假设你抓取了一百TB的原始数据, 最终能够实现运用状况可行状态方面的, 大概有可能仅仅只有四十到五十TB。
此处所要处理的问题含有而非仅仅限制于, 比如HTML标签剩下的部分, 无关的字符, 重复出现的内容, 质量不高的机器翻译出来的文本, 涵盖敏感信息的内容之类标点符号。
还要注意一点极易被忽视的, 是数据分布。要是你的模型打算用于对话场景, 那么在训练数据里, 对话类样本起码得占据一定比例。倘若全部都是新闻报道, 那模型生成出来的内容就会如同新闻联播一般, 而非一个能够聊天的助手。
模型架构:选,但别只看到
当今之时, 几乎全部的AI大模型, 皆是建立于架构之上, 此情形并无任何悬念。
但, “运用”, 与, “领会”, 属于, 两码事。
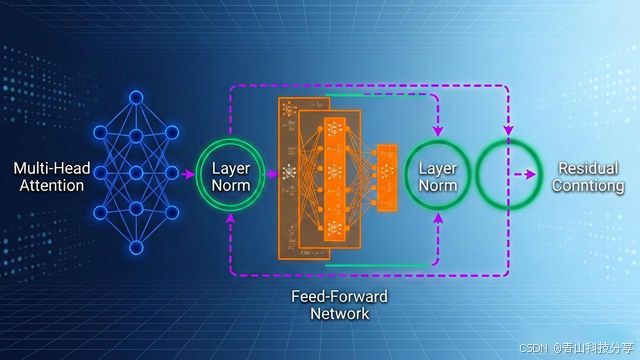
一个规整的模型, 其核心构成元件包含多头注意力机制, 以及前馈神经网络, 还有层归一化与残差连接。每一层都具备它的用途。像注意力机制能判定模型可以“看”到多远的前文内容这种情况, 这会对模型所生成内容的质量产生直接的冲击。
详细来讲, 要是你打算搭建出一个参数规模处于70亿左右的模型, 大致需要28至32层层, 每一层的隐藏维度约在4096左右, 注意力头数大概在32个左右。这些相关数字并非随意制定的, 而是历经大量实验检验所得到的平衡点。
当然, 要是你所运用的是现成的那种开源框架, 像是 Face的库, 这些参数均可直接予以配置, 不必亲自从零开展编写。然而, 倘若你打算进行某些改进, 例如采用稀疏注意力或者混合专家模型, 那么便需要对架构自身具备较为深刻的理解。
训练过程:烧钱又烧时间的阶段
这里我直接说数字吧。
拿几百张A100显卡去训练一个有着70亿参数的模型, 大概得跑几十天。此过程的成本, 从七位数人民币起步, 且没有上限。
而且这仅是单次训练, 实际上,极少有团队能够一次便成功, 你大概需要调整学习率, 调整批量大小, 调整模型初始化方式, 每历经一次调整就得再次运行一遍或者起码运行一部分。
更使人备受折磨的是, 要训练到一半的时候, 你才能够发觉模型是不是出现了问题。所以, 好多团队会先于小规模的层面上去进行实验, 比如说采用1亿参数的版本运行一两天, 瞧瞧损失函数是不是依照常理下降, 并且看看梯度有没有出现引发爆炸或者消失不见的情况。
处于训练进程里的监控同样是相当的重要。通常情形下会进行记录训练当中的损失、验证彼时的损失、学习率所产生的改变、梯度的范数等一系列指标。要是这个梯度范数突然间大幅攀升, 那就表明很有可能出现了梯度爆炸这种状况, 如此一来便要求对学习率予以调整或者去进行梯度裁剪。
微调与对齐:让模型更“听话”
基座模型被训练出来后, 它仅仅是个“语言引擎”, 能够生成语句通顺的文字, 然而并不一定清楚该如何回应你的问题。
这时候就需要做微调和对齐。
进行微调, 就是借助高质量的人工标注数据, 使得模型能够学会特定的输入输出模式。举例来说, 倘若你给予它一堆呈现为“用户提问 - 优质回答”样式的样本, 那么它便能够学会怎样去充当一个好助手。
要是进行对齐这一行为, 当下最为主流的办法乃是RLHF, 这RLHF也就是建立于人类反馈基础之上的强化学习。简单来讲, 便是安排人去给模型的输出给出分数, 随后模型依据这个反馈去调整自身的生成策略。
这一步投入并非微小, 举例而言, 一个规模属于中等档次的微调项目 , 大概所需数量是几万至几十万条具备高质量特征的标注数据。每一条数据均要历经人工执行审核以及标注的流程。要是寻觅专业的从事标注工作的团队, 每一条数据所产生的成本大约处于几毛钱至几块钱这个范围之中。
推理部署:模型做好只是上半场
很多人以为模型训练完就万事大吉了。
实际上,部署上线才是另一个大坑。
具备70亿参数的模型, 若未运用任何优化办法, 仅是将模型参数载入显存之中, 便会需求十几GB的显存。倘若用户的请求数量众多, 那么你还得借助多张显卡来实行负载均衡。
常见的优化方法包括:
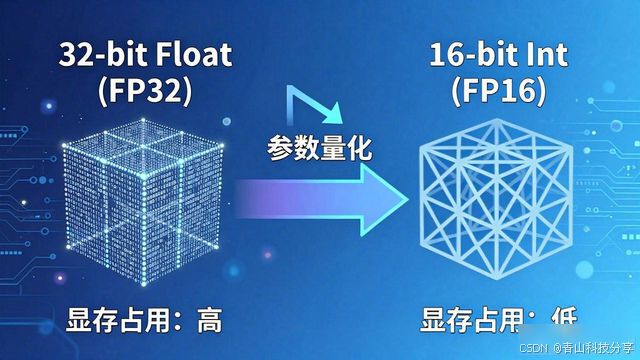
量化, 即将模型参数, 由32位浮点数, 压缩到16位, 甚至是8位。如此一来, 显存占用率, 直接减半、降至四分之一。
蒸馏, 是通过运用一个大型教师模型, 来训练一个更小的学生模型, 如此一来, 其推理速度能够快上好几倍。
剪枝:去掉模型中一些不重要的连接,减少计算量。
这些技术听闻起来蛮专业, 不过实际上已然存在诸多开源工具助你达成了。像llama.cpp、vLLM、 - LLM等等, 均可助你进行模型优化以及加速部署。
别被“参数竞赛”带偏了
现在很多人比模型好不好,就只会看参数数量。
70亿的看不起10亿的,130亿的看不起70亿的。
但是倘若实话实说的话, 参数的数量仅仅是代表着模型的容量而已, 并非代表模型的质量。存在这样一个拥有1000亿参数的模型, 就算它的数据质量糟糕, 而且训练的方法不太正确的情况下, 其表现很有可能还比不上一个有着70亿参数且经过精心训练的模型。
与此同时, 参数越大, 那么部署成本也就越高, 并且响应速度会越慢。要是你所从事的并非属于那么一种需求是高精度推理的场景, 小模型是完全能够满足需要的。
要从实际情况来讲, 多数的个人开发者以及小团队, 在使用70亿参数级别的模型时就已然觉得很费劲了。那些动不动就几百亿参数的模型, 那可是只有大公司才有能力去玩的事物。
所以, 要先弄明白你自身的需求, 之后再去决定该选用多大规模的模型。可千万别因为参与参数竞赛而把自己弄到破产的地步。
写在最后
搭一个大模型,真的不难。
难的是把它搭好。
从开展数据准备起, 直至架构设计阶段, 从进行训练调优开始, 到部署上线为止, 每一步当中都有着数目众多的坑在等着你。然而只要你并非想要跟进行正面强硬争夺, 借助现成的开源工具连同模型, 去打造一个体量小运转美的应用程序, 此番做法是完全具备可行性的。
别被那些动不动就“颠覆”“革命”的PR文章吓到了。
说到底, AI里面这大模型的东西, 说白了, 是和一堆数学以及工程相关的问题。只要你肯愿意花上一些可算花费的时间, 最终往往而言总能搞明白的。
试试呗,反正又不亏。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)