从零到一!Qwen7B医疗大模型完整落地:QLoRA微调→量化→Ollama本地部署实战
从零到一!Qwen7B医疗大模型完整落地:QLoRA微调→量化→Ollama本地部署实战
摘要
本文从零开始完整记录通用大模型垂直医疗私有化落地全流程。基于Qwen2.5-7B基座,使用LLaMA-Factory完成QLoRA医疗SFT微调、模型合并、GGUF量化压缩,最终通过Ollama实现本地离线部署。全程个人设备可跑、低成本、高复用,附带原版模型VS微调模型硬核对照测试,直观验证微调效果,适合所有新手入门大模型微调落地。
关键词:大模型微调、Qwen7B、医疗大模型、QLoRA、llama.cpp、Ollama本地部署
一、项目前言
很多新手想学大模型微调,但大多卡在:只会训练、不会合并、不会量化、不会本地部署,全程断层。
本次项目真正实现从零到一完整闭环:
数据集准备 → 云端QLoRA微调 → LoRA权重合并 → 本地GGUF量化压缩 → Ollama私有化部署 → 效果对照验证
最终成功打造一个专属私人离线医疗问诊大模型,可解读化验单、常见病问诊、健康指导,相比原生通用模型,专业能力大幅提升。
二、整体技术链路(一站式闭环)
医疗数据集 → LLaMA-Factory QLoRA微调 → 合并完整HF模型 → llama.cpp GGUF FP16转换 → Q4_K_M极致量化 → Ollama本地部署 + API调用
运行环境
-
训练:AutoDL 云端Linux环境
-
量化&部署:本地Windows + RTX4090 24G
-
核心框架:LLaMA-Factory、llama.cpp、Ollama
三、从零实操完整步骤
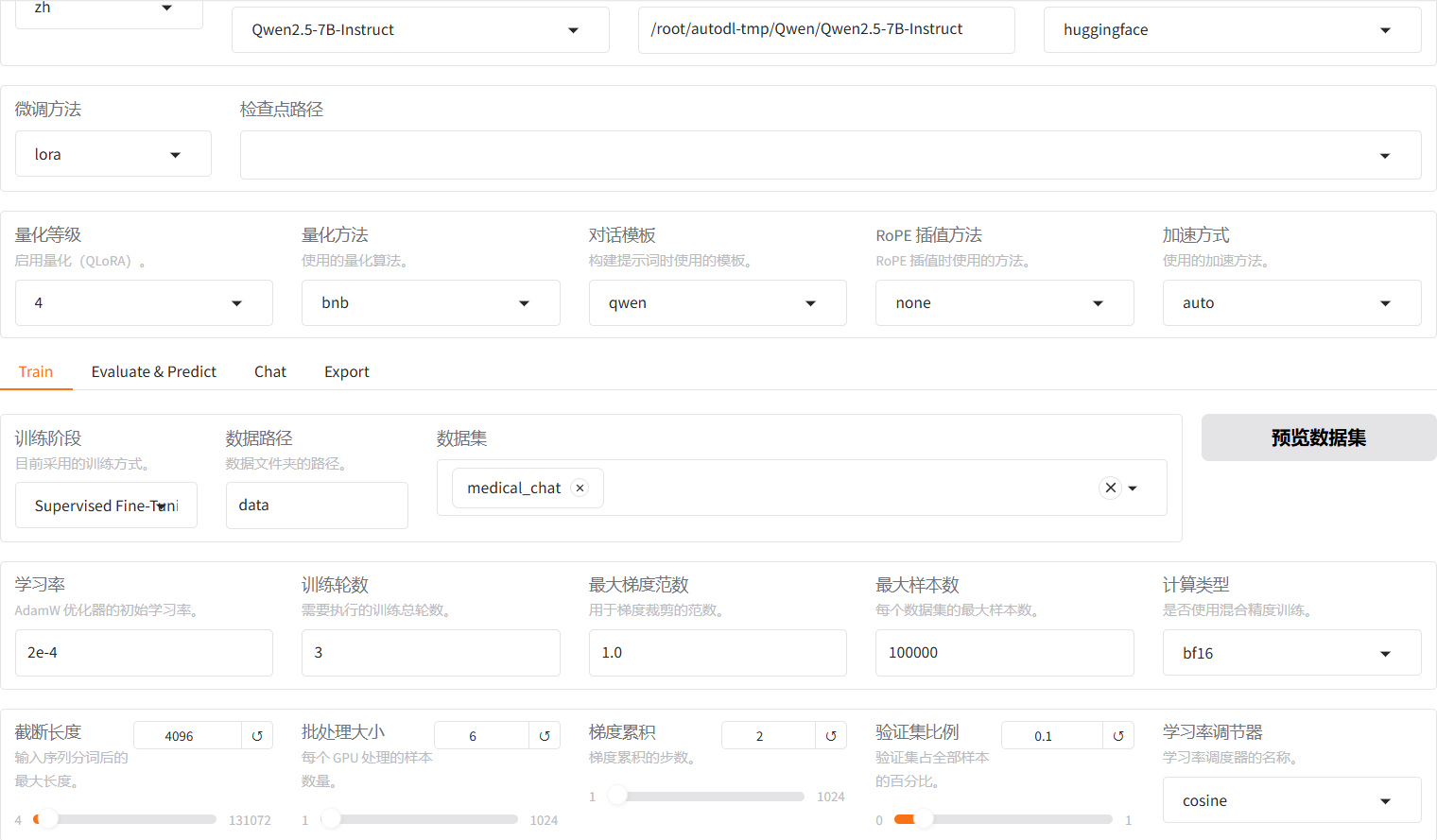
1. 云端微调 & 模型合并打包
使用自建医疗问诊数据集,在LLaMA-Factory中开启QLoRA轻量化微调,低显存即可完成训练。
训练完成后,将LoRA适配器与Qwen7B基座权重合并,生成完整HF格式模型文件夹:merged_qwen7b_medical
云端打包下载:
zip -r merged_qwen7b_medical.zip merged_qwen7b_medical
下载至本地Windows并解压备用。
2. 本地量化环境配置(仅一次永久生效)
解决torch模块缺失、转换报错问题,一键安装所有依赖:
pip install torch sentencepiece protobuf transformers accelerate safetensors -i https://pypi.tuna.tsinghua.edu.cn/simple
3. HF模型转GGUF FP16
使用绝对路径,彻底规避路径报错:
python convert_hf_to_gguf.py D:\weitiao\merged_qwen7b_medical --outtype f16 --outfile qwen7b-med-f16.gguf
4. Q4_K_M 终极量化(7B模型最优档位)
Q4_K_M兼顾精度与体积,最终模型仅4.2G,本地显卡无压力:
.\build\bin\llama-quantize.exe D:\weitiao\merged_qwen7b_medical\qwen7b-med-f16.gguf D:\weitiao\merged_qwen7b_medical\qwen7b-med-Q4_K_M.gguf Q4_K_M
5. Ollama 本地私有化部署
复用LLaMA-Factory自动生成的模板,修改路径+医疗专属系统提示词,适配微调模型:
FROM D:\weitiao\merged_qwen7b_medical\qwen7b-med-Q4_K_M.gguf TEMPLATE """{{ if .System }}<|im_start|>system {{ .System }}<|im_end|> {{ end }}{{ range .Messages }}{{ if eq .Role "user" }}<|im_start|>user {{ .Content }}<|im_end|> <|im_start|>assistant {{ else if eq .Role "assistant" }}{{ .Content }}<|im_end|> {{ end }}{{ end }}""" SYSTEM """你是专业私人医疗问诊助手,由医疗数据集微调训练而成,禁止自称通义千问、阿里云。专注医学问诊、化验单解读、常见病诊疗科普,不开处方药,重症建议及时就医。""" PARAMETER stop "<|im_end|>" PARAMETER num_ctx 4096 PARAMETER temperature 0.5 PARAMETER num_gpu_layers 999
导入模型并启动对话:
ollama create qwen-med:7b -f Modelfile ollama run qwen-med:7b
四、核心验证:微调到底有没有用?(硬核对照)
很多人微调完不知道成功没,这里用同一道专业医疗题,对比【原版Qwen7B】VS【微调医疗模型】
测试问题:
HBSAg=35.5、HBSAb=0.47、HBeAg=0.31、HBeAb=0.02、HBcAb=0.001,HBV-DNA7×10³ IU/ml,ALT48,AST43,轻度偏高,请问大三阳还是小三阳,病毒复制高低,要不要抗病毒?
1. 原版官方 Qwen7B(未微调)
完全不懂医疗指标规则,误判五项指标全部阴性,无法区分大小三阳,病毒复制、肝功能解读混乱,给出的治疗建议模棱两可,完全不具备临床参考性。
2. 微调后医疗模型
精准输出专业结论:
-
判定结果:乙肝小三阳
-
病毒载量:7×10³ 属于低水平病毒复制
-
肝功:转氨酶轻度升高,轻微肝细胞损伤
-
诊疗建议:无需立刻抗病毒,定期复查随访即可
完全符合临床诊疗指南!
附加测试:痘印修复区分红/黑痘印、慢性咽炎对症养护,微调模型回答专业细化,通用模型只会泛泛而谈,微调效果肉眼可见。
五、全程高频踩坑总结(新手必看)
-
多Python环境报错:torch只需安装一次,认准训练所用环境
-
模型找不到:全程使用绝对路径,拒绝相对路径
-
PowerShell无法运行exe:必须加 .\ 前缀
-
量化文件名更新:新版llama.cpp编译产物为
llama-quantize.exe -
模型自我介绍错乱:修改Modelfile的SYSTEM词重新构建即可
六、项目拓展方向
-
API接口调用:Ollama默认11434端口,可对接Python程序、前端网页,搭建私人问诊系统
-
精度升级:可更换Q5_K_M量化,更高精度适配专业医疗场景
-
二次迭代:扩充罕见病、体检报告数据集,持续提升模型专业性
-
量化评估:接入评测框架,用客观指标替代人工测评
七、总结
本次项目真正从零到一完成大模型垂直落地,验证了:个人开发者无需高端算力,依靠QLoRA微调+量化压缩,即可将通用基座模型,转化为具备专业医疗能力的私有化本地大模型。
整套流程可复用、可迁移,可用于教育、法律、办公等任意垂直领域微调落地!
八、截图
模型下载截图
微调截图
对话截图


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)