【Codex配置实战】从 config.toml 到 AGENTS.md:把 AI 编程助手调成顺手的开发环境

🔥个人主页:爱和冰阔乐
📚专栏传送门:《数据结构与算法》 、C++
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

🏠博主简介
文章目录
前言
最近用 AI 写代码的人越来越多,但很多同学对 Codex 的理解还停留在一个层面:把它当成一个能帮你补代码、解释代码的聊天工具。
这个理解不能说错,但有点浅。
如果只是让 Codex 写一个函数、解释一段报错,那它确实像一个普通的 AI 助手。但真正把它放进项目里用一段时间之后,你会发现 Codex 更像一个可以参与开发流程的“本地开发代理”。它能读项目、搜文件、改代码、跑测试、看日志,甚至可以通过 MCP 去连接浏览器、仓库、文档系统等工具。
能力变强以后,问题也就跟着来了:
它能不能随便改文件?
它能不能联网?
它遇到危险命令要不要先问我?
它怎么知道这个项目用的是 pnpm 还是 npm?
它怎么知道不要乱改数据库迁移文件?
它怎么知道我的代码风格是什么?
这些问题不能靠每次聊天临时提醒解决。你每次都说“不要乱加依赖”“改完记得跑测试”“别动生产配置”,不仅麻烦,而且容易漏。
所以 Codex 真正好用的关键,不只是模型本身,而是配置。
本文就从 config.toml、AGENTS.md、权限策略、沙箱模式和 MCP 这几块,把 Codex 的配置体系梳理一遍。目标不是堆概念,而是让你知道:每个配置到底管什么,什么时候该配,怎么配才不容易翻车。

一、为什么 Codex 需要配置?
传统编辑器插件大多只负责提示和补全,比如补全变量名、生成一小段代码、解释某个函数。它们一般不会主动修改一堆文件,也不会自己执行命令。
Codex 不一样。
你可以直接给它一个任务:
帮我修复登录失败时错误提示不准确的问题,并补充测试。
正常情况下,它可能会做这些事:
- 搜索 login、auth、error 相关代码
- 阅读接口实现和测试目录
- 找到最小修改点
- 修改错误提示逻辑
- 补充测试用例
- 运行测试命令
- 根据测试结果继续修复
- 最后总结改了哪些文件
这已经不是简单的“代码生成”了,而是一个小型开发流程。
但开发流程一旦自动化,就必须考虑边界。因为自动化能力越强,误操作成本也越高。
比如:
- 它为了修 bug,顺手重构了一堆无关代码;
- 它为了跑项目,直接安装了新依赖;
- 它以为 dist 是临时目录,结果删掉了重要文件;
- 它不知道项目规范,把 npm 和 pnpm 混着用;
- 它不知道测试命令,改完代码就直接结束。
这些问题不是模型“笨”,很多时候是因为项目规则没有明确告诉它。
从工程角度看,配置的作用就是把临时口头约定变成稳定规则。
这和 Linux 权限管理有点像。普通用户不能随便改系统目录,危险操作要提权,进程访问资源要经过权限检查。不是为了麻烦,而是为了防止错误操作影响整个系统。
Codex 也一样。
它需要知道:
- 哪些文件能读?
- 哪些目录能写?
- 哪些命令能直接执行?
- 哪些操作必须问用户?
- 这个项目的开发规范是什么?
- 当前目录有没有特殊约束?
没有配置时,Codex 只能靠当前对话里的临时上下文。配置写清楚后,它每次进入项目都能先拿到规则,再开始工作。
二、Codex 配置体系整体认识
Codex 配置里最重要的两个文件是:
- config.toml
- AGENTS.md
这两个文件不要混着理解。
config.toml 更偏工具层,控制模型、权限、沙箱、MCP 服务、默认行为等。
AGENTS.md 更偏项目层,告诉 Codex 项目规范、代码风格、测试方式、目录规则等。
💡一句话总结:
- config.toml 决定 Codex 能做什么
- AGENTS.md 决定 Codex 应该怎么做
比如你想设置默认模型、是否允许联网、能不能写工作区,这些属于 config.toml。
比如你想告诉 Codex “本项目使用 C++17”“改完运行 make test”“不要做无关重构”,这些属于 AGENTS.md。
常见层级可以这样看:
- ~/.codex/config.toml 用户级工具配置
- 项目目录/.codex/config.toml 项目级工具配置
- ~/.codex/AGENTS.md 用户级长期指令
- 项目根目录/AGENTS.md 项目级开发规范
- 子目录/AGENTS.md 模块级补充规范
这套设计和 Git 配置很像。Git 有系统级、用户级、仓库级配置;Codex 也可以把个人习惯放全局,把项目规则放仓库,把特殊模块规则放子目录。
这样做的好处是清晰。
你的个人习惯可以长期保留:
- 修改前先阅读上下文
- 不要主动引入新依赖
- 能跑测试就跑测试
- 回答先给结论再展开
项目规则则放在项目里:
- 本项目使用 pnpm
- 后端接口改动要更新文档
- 数据库迁移文件不要随便改
- 提交前运行 pnpm test
不同项目加载不同规则,不需要每次都从头交代。
三、config.toml:工具行为的控制中心
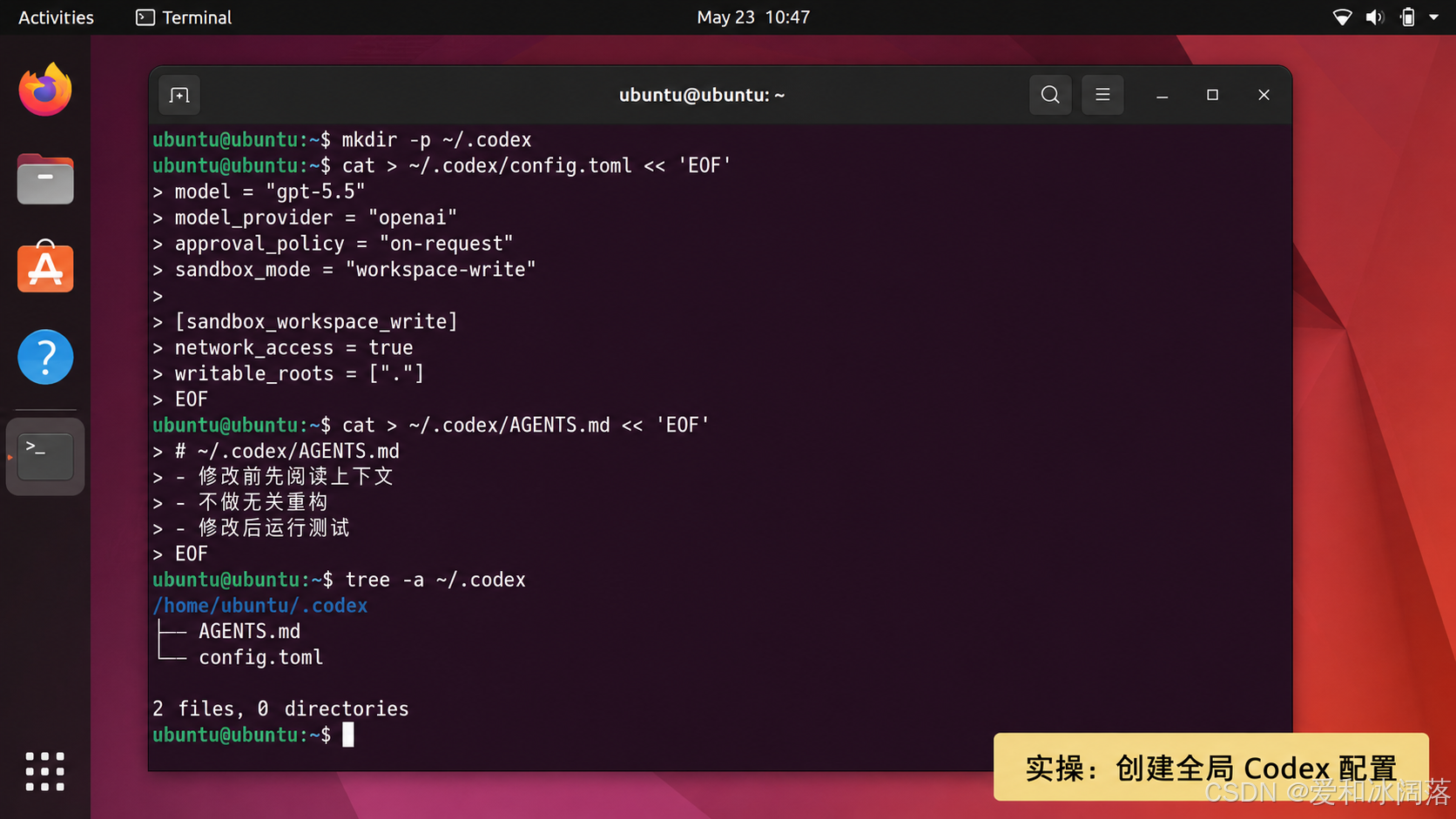
config.toml 是 Codex 的核心配置文件之一。
用户级配置一般在:
~/.codex/config.toml
Windows 下通常类似:
C:\Users\你的用户名\.codex\config.toml
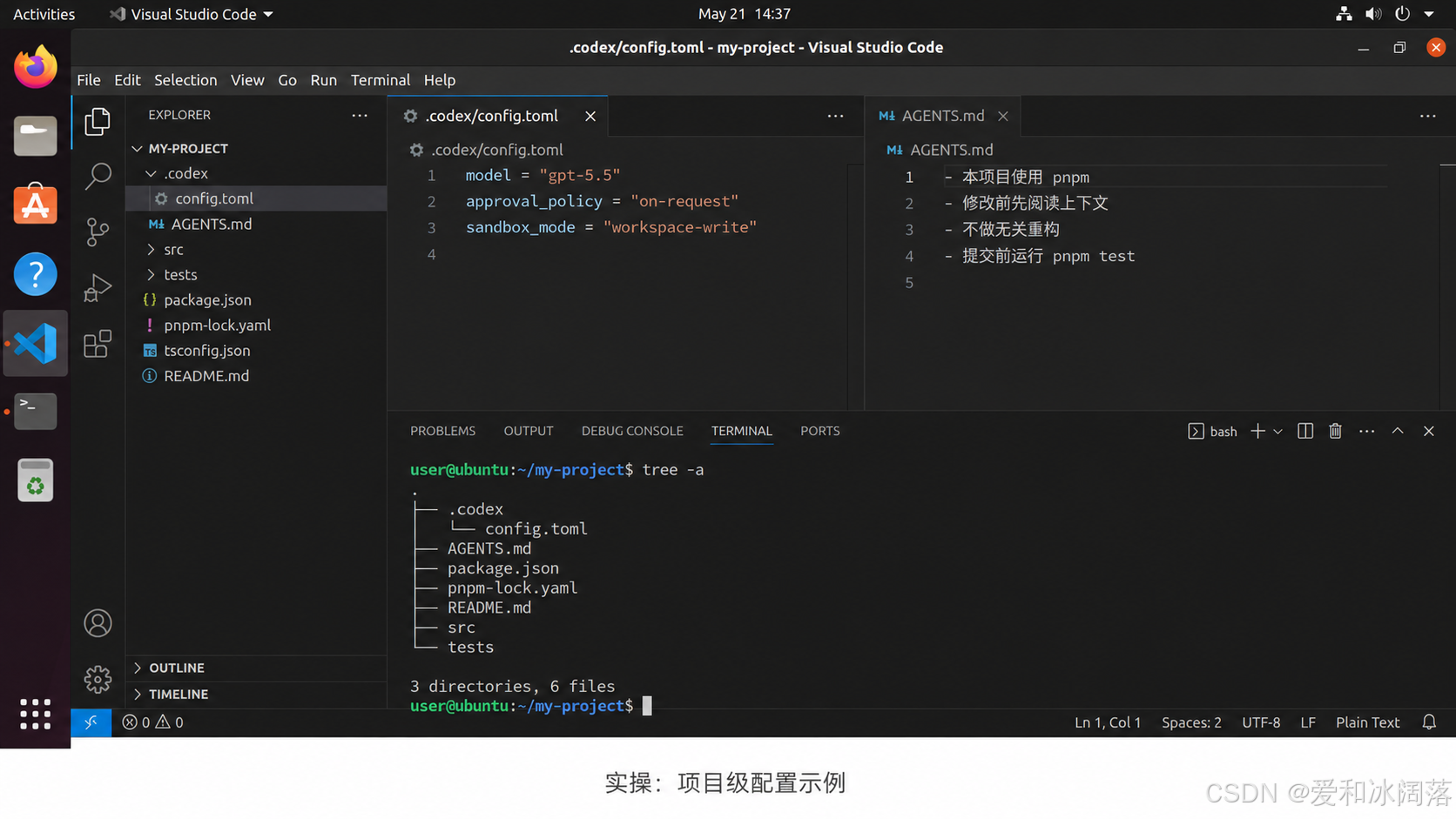
如果某个项目需要单独配置,可以在项目里创建:
.codex/config.toml
一个比较基础的配置如下:
model = "gpt-5.5"
model_provider = "openai"
approval_policy = "on-request"
sandbox_mode = "workspace-write"
这几行已经包含了几个关键点:
- model:默认模型
- model_provider:模型提供方
- approval_policy:审批策略
- sandbox_mode:沙箱模式
TOML 的写法比较适合手写配置。相比 JSON,它不用写一堆括号;相比 YAML,它又不容易因为缩进出问题。
需要注意的是,顶层字段尽量写在表配置前面,例如:
model = "gpt-5.5"
approval_policy = "on-request"
[sandbox_workspace_write]
network_access = true
writable_roots = ["."]
不要把顶层字段随便插到某个表下面,否则有些配置可能会被解析成表内字段。
可以把 config.toml 理解成 Codex 的启动参数区。Codex 进入项目后,会先读取这些配置,再确定自己以什么模式工作。
四、模型配置:不是越强越好,而是要匹配任务
模型配置通常写在 config.toml 顶层:
model = "gpt-5.5"
model_provider = "openai"
能力强的模型适合做复杂任务,例如:
- 跨文件 bug 分析
- 大型重构
- 测试失败排查
- 架构设计
- 复杂代码迁移
- 多步骤开发任务
速度更快、成本更低的模型适合做轻任务,例如:
- 解释代码
- 补注释
- 生成简单脚本
- 写 README
- 整理日志
- 局部小改动
这和我们平时选数据结构一样。不是所有场景都用红黑树,也不是所有场景都用数组。任务复杂度不同,模型选择也应该不同。
如果只是改一个变量名,用最强模型有点浪费。如果是分析一个跨多个模块的线上 bug,用太弱的模型又容易漏上下文。
还可以配一些推理和输出参数:
model_reasoning_effort = "medium"
model_verbosity = "medium"
model_reasoning_summary = "auto"
大致可以这样理解:
- reasoning_effort:推理强度
- verbosity:输出详细程度
- reasoning_summary:是否展示推理摘要
新手不建议一开始把参数调得很复杂。先用默认值,等你发现某类任务经常不够稳,再针对性调整。
💡我的建议:
- 小改动:medium 就够
- 复杂重构:提高 reasoning effort
- 写文章或解释知识:提高 verbosity
- 自动化任务:输出尽量简洁
配置不是越多越好,能解决问题才是好配置。
五、权限配置:approval_policy 和 sandbox_mode
Codex 配置里最需要认真理解的,就是权限。
因为它直接决定 Codex 能不能改文件、能不能联网、能不能执行命令,以及遇到风险操作时要不要停下来问你。
两个核心字段:
approval_policy = "on-request"
sandbox_mode = "workspace-write"
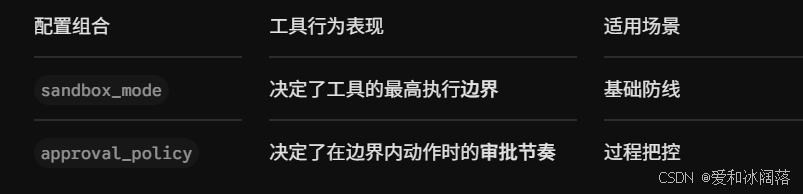
这两个字段分别解决不同问题:
approval_policy:什么时候需要问用户
sandbox_mode:Codex 最大能操作到什么范围
1. approval_policy:刹车系统
approval_policy 可以理解成刹车系统。
approval_policy = "on-request"
这个配置表示:当 Codex 遇到需要更高权限、可能影响系统或项目安全的操作时,会先请求用户确认。
日常开发推荐这个模式。
因为我们既希望 Codex 能主动干活,又不希望它完全不受控制。
还有一种模式是:
approval_policy = "never"
这个表示 Codex 不会主动请求审批。它更适合提前确定好边界的自动化环境,比如临时容器、CI、一次性脚本。普通个人项目不建议默认用它。
2. sandbox_mode:活动范围
sandbox_mode 可以理解成活动范围。
常见有三种:
- read-only:只读
- workspace-write:允许写当前工作区
- danger-full-access:权限基本放开
只想让 Codex 分析项目,不想让它改文件,可以用:
sandbox_mode = "read-only"
日常开发比较推荐:
sandbox_mode = "workspace-write"
这表示 Codex 可以修改当前项目内的文件,但不会随便动系统其它目录。
如果需要允许联网和限制可写目录,可以这样写:
[sandbox_workspace_write]
network_access = true
writable_roots = ["."]
danger-full-access 权限最大,但名字已经提示得很直白:danger。
不是说不能用,而是要知道自己在干什么。真实项目里,不建议新手默认开这个。
3. 两个配置一起看
组合起来看更清楚:

🧱比较稳的日常配置:
approval_policy = "on-request"
sandbox_mode = "workspace-write"
[sandbox_workspace_write]
network_access = true
writable_roots = ["."]
这个配置既不会让 Codex 完全不能动,也不会把系统权限全部交出去。
六、AGENTS.md:项目规矩写在这里
如果说 config.toml 管的是工具行为,那 AGENTS.md 管的就是项目规矩。
很多时候,Codex 写得不符合预期,不是因为它不会,而是因为它不知道你的项目规则。
比如:
- 不能随便新增依赖
- 修改公共接口要更新文档加粗样式
- 改完代码要跑测试
- 不要修改 migrations 目录
- C++ 项目要保持头文件依赖简洁
- Linux 示例代码要写清楚返回值
这些都适合写进 AGENTS.md。
项目根目录可以放:
AGENTS.md
示例:
# AGENTS.md
## 项目规则
- 修改代码前先阅读相关模块,不要直接猜实现。
- 保持当前项目已有代码风格,不做无关重构。
- 不要随意新增第三方依赖,确实需要时先说明原因。
- 修改公共接口时,同步更新接口文档。
- 能运行测试时,修改后必须运行测试。
这份文件就像给 Codex 准备的项目说明书。
你也可以写全局的:
~/.codex/AGENTS.md
全局文件适合放个人长期偏好:
# ~/.codex/AGENTS.md
## 我的通用习惯
- 回答先给结论,再说明细节。
- 修改代码前先搜索上下文。
- 不做无关重构。
- 修改后说明改了哪些文件。
- 如果无法运行测试,需要说明原因。
项目文件适合放项目特有规则:
# AGENTS.md
## 本项目规则
- 本项目使用 pnpm,不要使用 npm。
- 前端代码在 apps/web。
- 后端代码在 services/api。
- 修改接口后更新 openapi.yaml。
- 提交前运行 pnpm lint 和 pnpm test。
AGENTS.md 的关键不是写得多,而是写得具体。
“写高质量代码”这种话太虚。
“修改后运行 pnpm test,不要新增依赖,不要改 migrations 目录”才是真正能执行的规则。
七、AGENTS.md 的层级加载
AGENTS.md 不是只能放一个,它可以按目录分层。
假设项目结构如下:
project/
├── AGENTS.md
├── frontend/
│ └── AGENTS.md
└── backend/
└── payment/
└── AGENTS.override.md
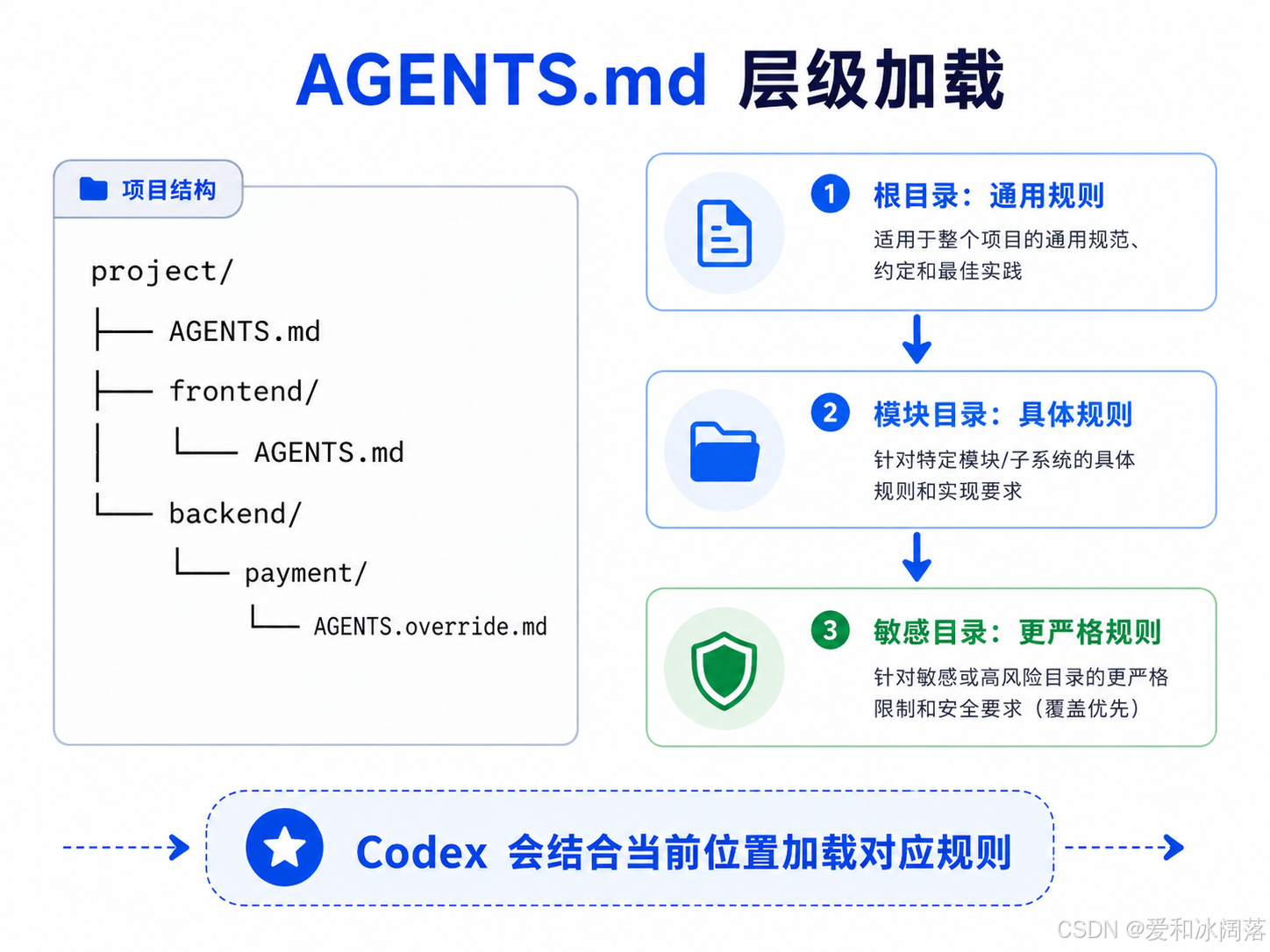
根目录写通用规则,frontend 写前端规则,payment 写支付模块特殊规则。
比如根目录:
- 保持原有代码风格。
- 修改后运行测试。
- 不做无关重构。
支付目录可以更严格:
- 不要修改签名算法,除非任务明确要求。
- 不要在日志中输出 token、密钥、手机号。
- 修改支付状态流转时,必须补充边界测试。
这样 Codex 在支付模块工作时,会同时理解通用规则和局部规则。
这个设计很适合大项目。
因为大项目里不同目录规则往往不一样。前端关心组件、样式、交互;后端关心接口、数据库、鉴权;支付模块又额外关心安全和状态流转。
如果所有内容都塞进根目录一个 AGENTS.md,要么文件特别长,要么约束不够精确。
更好的方式是:
根目录写通用规则
模块目录写具体规则
敏感目录写更严格规则
这就是“配置靠近使用位置”。
八、MCP:给 Codex 扩展外部工具
Codex 本身能读写文件、执行命令,但如果想连接更多外部工具,就需要 MCP。
可以把 MCP 理解为工具接入协议。通过 MCP,Codex 可以连接 GitHub、浏览器、数据库、文档系统等。
示例配置:
[mcp_servers.github]
command = "npx"
args = ["-y", "@modelcontextprotocol/server-github"]
startup_timeout_sec = 10
tool_timeout_sec = 60
这段配置大致表示:启动一个名为 github 的 MCP 服务。
字段含义:
command:启动命令
args:启动参数
startup_timeout_sec:启动超时时间
tool_timeout_sec:工具调用超时时间
如果需要 token,不建议直接写死在配置文件里:
token = "ghp_xxxxxxxxx"
这样很危险,容易被误提交。
更推荐通过环境变量:
env = { GITHUB_TOKEN = "GITHUB_TOKEN" }
MCP 的价值在于让 Codex 不只看本地代码。
比如:
接 GitHub:读 issue、PR、仓库信息
接浏览器:检查页面效果、调试交互
接数据库:看表结构、辅助写 SQL
接文档系统:读取团队规范
但 MCP 不是越多越好。
每接一个工具,就多一份权限风险。我的建议是按需接入:确实能提升效率再配,不熟悉的服务不要随便开,敏感权限一定要控制好。
九、推荐一套新手配置
如果你刚开始用 Codex,不建议上来就配得很复杂。
先用一套稳的:
model = "gpt-5.5"
model_provider = "openai"
approval_policy = "on-request"
sandbox_mode = "workspace-write"
model_reasoning_effort = "medium"
model_verbosity = "medium"
[sandbox_workspace_write]
network_access = true
writable_roots = ["."]
这套配置的特点:
允许 Codex 修改当前项目
高风险操作会问你
允许联网
写入范围限制在工作区
模型和输出保持中等强度
再配一个全局 AGENTS.md:
# ~/.codex/AGENTS.md
## 通用规则
- 修改前先阅读上下文。
- 优先保持原有代码风格。
- 不做无关重构。
- 不主动新增依赖。
- 修改后说明核心逻辑。
- 能运行测试时必须运行测试。
项目里再放一个 AGENTS.md:
# AGENTS.md
## 项目规则
- 本项目使用 pnpm。
- 修改前端后运行 pnpm lint。
- 修改后端后运行 pnpm test。
- 不要修改生产配置文件。
- 不要随意调整目录结构。
这就是一个最小闭环。
先不要追求复杂,先把边界和项目规则讲清楚。等你用熟了,再慢慢加 MCP、profiles、不同模型策略。
十、常见误区
误区一:把所有东西都写进 config.toml
config.toml 适合写结构化配置,不适合写一大段项目规范。
项目规则建议放 AGENTS.md。
正确分工:
工具行为写 config.toml
项目规范写 AGENTS.md
误区二:权限直接开最大
有些同学为了方便直接写:
sandbox_mode = "danger-full-access"
approval_policy = "never"
这样确实爽,但风险也高。
真实项目里更建议:
sandbox_mode = "workspace-write"
approval_policy = "on-request"
误区三:AGENTS.md 太空
只写一句:
请写出高质量代码。
基本没用。
因为“高质量”不可执行。
应该写成:
- 修改后运行 pnpm test。
- 不要新增依赖。
- 不要修改 migrations 目录。
- 保持原有代码风格。
误区四:AGENTS.md 太长
也不要把所有业务文档都塞进去。
太长会稀释重点。
更好的方式是:
AGENTS.md 写规则
docs 写详细文档
需要时让 Codex 去读 docs
误区五:把密钥写进配置文件
不要把 token、key、password 直接写进仓库里的配置。
真实密钥走环境变量,不要进 Git。
总结
Codex 的强大之处,不只是会写代码,而是可以通过配置变成更懂项目的开发助手。
这套配置体系可以概括成几句话:
config.toml 控制工具行为
AGENTS.md 固化项目规则
approval_policy 控制审批节奏
sandbox_mode 限制权限边界
MCP 扩展外部工具能力
如果用操作系统来类比:
config.toml 像系统配置
AGENTS.md 像项目说明书
sandbox_mode 像权限隔离
approval_policy 像 sudo 确认
MCP 像外接工具驱动
真正好用的 Codex,不是默认状态下的 Codex,而是被你配置过的 Codex。
默认状态下,它只是一个能力很强的通用助手。配置完成后,它才会更像一个懂你项目、守你规矩、知道边界在哪里的开发搭子。
刚开始使用时,记住这套顺序就够了:
1. 先配 ~/.codex/config.toml
2. 再写 ~/.codex/AGENTS.md
3. 重要项目单独写 AGENTS.md
4. 默认使用 workspace-write
5. 高风险操作保留审批
6. MCP 按需开启,不要贪多
AI 编程工具不是让开发者完全不思考,而是把重复、繁琐、机械的部分交给工具,把架构判断、边界设计和核心逻辑留给人。
会用 Codex,只是第一步。
会配置 Codex,才是真正把它变成生产力工具的开始。
参考资料
- OpenAI Codex 配置基础文档:https://developers.openai.com/codex/config-basic
- OpenAI Codex 配置参考文档 :https://developers.openai.com/codex/config-reference
- OpenAI Codex AGENTS.md 文档:https://developers.openai.com/codex/guides/agents-m
- OpenAI Codex 权限说明 :https://developers.openai.com/codex/permissions

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)