大模型入门:从 MHA 到 GQA,一次讲清 KV Cache 为什么能省显存
大模型入门:从 MHA 到 GQA,一次讲清 KV Cache 为什么能省显存
摘要:上一篇讲 MHA 时,我们已经知道 KV Cache 会缓存每一层历史 token 的 K/V。继续往下看,问题就变成了:为什么很多大模型的 Query Head 数量和 KV Head 数量不一样?本文从 KV Cache 的显存公式开始,拆清 MHA、MQA、GQA 的张量形状、显存差异、手写实现和 PyTorch 接口用法。

一、推理显存经常卡在 KV Cache
很多人第一次跑本地大模型,会以为显存主要被模型参数吃掉。
这当然没错。一个 7B 模型即使用 FP16,也要十几 GB 级别的参数显存。
但进入真实推理后,你会发现另一个东西也会涨得很快:
prompt 越长,KV Cache 越大
batch 越大,KV Cache 越大
上下文窗口越长,KV Cache 越大
并发请求越多,KV Cache 越难管理
模型参数是加载时就基本固定的;KV Cache 是生成过程中随着请求、长度和 batch 增长的。
这也是为什么服务端推理框架会认真做 KV Cache 管理,vLLM 的 PagedAttention、Hugging Face 的 DynamicCache/StaticCache/QuantizedCache,本质上都在处理同一类问题:怎么让历史 K/V 既能被快速读取,又不要把显存撑爆。
而 GQA 正好站在这个问题中间。
一句话理解:
GQA 让多个 Query Head 共享较少的 Key/Value Head,从而减少 KV Cache 的存储和读取压力。

1. 先回忆:KV Cache 到底缓存了什么
Decoder-only 大模型推理时,一般分成两个阶段:
| 阶段 | 输入 | 主要动作 |
|---|---|---|
| Prefill | 完整 prompt | 一次性计算 prompt 的每层 K/V,并写入 cache |
| Decode | 当前新 token | 只算新 token 的 Q/K/V,用新 Q 查询历史 K/V |
Hugging Face 的缓存文档也强调:自回归生成是一个 token 一个 token 往后预测,KV Cache 会保存过去 token 在注意力层里的 K/V,后续 token 可以复用它们,避免重复计算。
上一篇文章里,我们用的 MHA 张量形状是:
q.shape == [batch, num_heads, seq_len, head_dim]
k.shape == [batch, num_heads, seq_len, head_dim]
v.shape == [batch, num_heads, seq_len, head_dim]
每一层要缓存的是历史 token 的 k 和 v:
past_k.shape == [batch, num_heads, past_len, head_dim]
past_v.shape == [batch, num_heads, past_len, head_dim]
注意这里缓存的是每一层的 K/V。一个 32 层模型,就有 32 份这样的缓存。
所以 KV Cache 的显存可以粗略估算为:
KV Cache bytes
= batch_size
* seq_len
* num_layers
* 2
* num_kv_heads
* head_dim
* bytes_per_element
这里的 2 表示 K 和 V 两份。
公式里最容易被忽略的是 num_kv_heads。
MHA 里:
num_kv_heads = num_query_heads
GQA 里:
num_kv_heads < num_query_heads
这就是 GQA 能省显存的入口。

2. 用一组数字算清楚
假设有一个简化配置:
batch_size = 1
seq_len = 8192
num_layers = 32
num_query_heads = 32
head_dim = 128
dtype = fp16 # 2 bytes
如果是传统 MHA:
num_kv_heads = 32
KV Cache 大约是:
1 * 8192 * 32 * 2 * 32 * 128 * 2 bytes
= 4 GiB
如果换成 GQA,假设:
num_kv_heads = 8
KV Cache 大约是:
1 * 8192 * 32 * 2 * 8 * 128 * 2 bytes
= 1 GiB
同样的 Query Head 数量,同样的上下文长度,只是把 KV Head 从 32 降到 8,缓存就变成原来的四分之一。
如果是 MQA:
num_kv_heads = 1
KV Cache 会进一步降到:
128 MiB
这只是一个教学估算,真实框架还会受到 allocator、block size、padding、并发调度、量化和 kernel 实现影响。但作为面试和工程理解,这个公式足够抓住核心。

3. MHA、MQA、GQA 的区别
可以先用一张表记住:
| 结构 | Query Head | KV Head | 直觉 |
|---|---|---|---|
| MHA | 多个 | 和 Query 一样多 | 每个 Q head 独享一组 K/V |
| MQA | 多个 | 1 个 | 所有 Q head 共享同一组 K/V |
| GQA | 多个 | 介于 1 和 Query Head 之间 | 一组 Q head 共享一组 K/V |
假设:
num_query_heads = 32
num_kv_heads = 8
group_size = num_query_heads // num_kv_heads # 4
那么 GQA 的意思是:
Q heads: 0 1 2 3 | 4 5 6 7 | ... | 28 29 30 31
KV head: 0 | 1 | ... | 7
每 4 个 Query Head 共享 1 个 KV Head。
它不像 MQA 那样把所有 Query Head 都压到同一个 KV Head 上,也不像 MHA 那样每个 Query Head 都保留独立 K/V。
GQA 原论文的动机也在这里:MQA 可以显著提升 decoder 推理速度,但可能带来质量下降;GQA 使用介于 1 和 Query Head 数之间的 KV Head 数量,在效果和推理效率之间做折中。
4. 张量形状怎么变
MHA 的投影通常是:
q_proj: hidden_dim -> num_q_heads * head_dim
k_proj: hidden_dim -> num_q_heads * head_dim
v_proj: hidden_dim -> num_q_heads * head_dim
GQA 的投影变成:
q_proj: hidden_dim -> num_q_heads * head_dim
k_proj: hidden_dim -> num_kv_heads * head_dim
v_proj: hidden_dim -> num_kv_heads * head_dim
也就是说,Q 还是很多头,K/V 变少了。
假设:
batch = 2
seq_len = 5
num_q_heads = 32
num_kv_heads = 8
head_dim = 128
那么:
q.shape == [2, 32, 5, 128]
k.shape == [2, 8, 5, 128]
v.shape == [2, 8, 5, 128]
但 attention 计算时,q @ k.transpose(-2, -1) 要求 head 维度能对齐。
一个教学版做法是把 K/V 按组展开:
k_expanded.shape == [2, 32, 5, 128]
v_expanded.shape == [2, 32, 5, 128]
PyTorch 的 scaled_dot_product_attention(enable_gqa=True) 文档里也展示了类似逻辑:启用 GQA 时,会按 Query Head 和 KV Head 的比例对 key/value 做 repeat_interleave。
但要注意,真实高性能实现不一定真的物理复制 K/V。服务端推理更关心 cache 布局、访存和 kernel 的实现方式。

5. 手写一个最小 GQA
下面这份代码只保留核心逻辑,适合面试讲法:
- Q Head 数可以大于 KV Head 数;
- KV Head 必须能整除 Query Head;
- K/V 先按较少 head 存储;
- 计算 attention 前按组展开;
- cache 里只缓存较少的 KV Head。
import math
import torch
from torch import nn
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
# x: [B, H_kv, T, D]
if n_rep == 1:
return x
batch, num_kv_heads, seq_len, head_dim = x.shape
x = x[:, :, None, :, :]
x = x.expand(batch, num_kv_heads, n_rep, seq_len, head_dim)
return x.reshape(batch, num_kv_heads * n_rep, seq_len, head_dim)
class GroupedQueryAttention(nn.Module):
def __init__(
self,
hidden_dim: int,
num_q_heads: int,
num_kv_heads: int,
dropout: float = 0.0,
):
super().__init__()
assert hidden_dim % num_q_heads == 0
assert num_q_heads % num_kv_heads == 0
self.hidden_dim = hidden_dim
self.num_q_heads = num_q_heads
self.num_kv_heads = num_kv_heads
self.head_dim = hidden_dim // num_q_heads
self.num_groups = num_q_heads // num_kv_heads
self.q_proj = nn.Linear(hidden_dim, num_q_heads * self.head_dim)
self.k_proj = nn.Linear(hidden_dim, num_kv_heads * self.head_dim)
self.v_proj = nn.Linear(hidden_dim, num_kv_heads * self.head_dim)
self.o_proj = nn.Linear(num_q_heads * self.head_dim, hidden_dim)
self.dropout = nn.Dropout(dropout)
def _split_heads(self, x: torch.Tensor, num_heads: int) -> torch.Tensor:
batch, seq_len, _ = x.shape
x = x.view(batch, seq_len, num_heads, self.head_dim)
return x.transpose(1, 2) # [B, H, T, D]
def _merge_heads(self, x: torch.Tensor) -> torch.Tensor:
batch, heads, seq_len, head_dim = x.shape
x = x.transpose(1, 2).contiguous()
return x.view(batch, seq_len, heads * head_dim)
def forward(
self,
x: torch.Tensor,
attn_mask: torch.Tensor | None = None,
past_key_value: tuple[torch.Tensor, torch.Tensor] | None = None,
use_cache: bool = False,
):
q = self._split_heads(self.q_proj(x), self.num_q_heads)
k = self._split_heads(self.k_proj(x), self.num_kv_heads)
v = self._split_heads(self.v_proj(x), self.num_kv_heads)
if past_key_value is not None:
past_k, past_v = past_key_value
k = torch.cat([past_k, k], dim=2)
v = torch.cat([past_v, v], dim=2)
present_key_value = (k, v) if use_cache else None
k_for_attn = repeat_kv(k, self.num_groups)
v_for_attn = repeat_kv(v, self.num_groups)
scores = q @ k_for_attn.transpose(-2, -1)
scores = scores / math.sqrt(self.head_dim)
if attn_mask is not None:
scores = scores.masked_fill(attn_mask, float("-inf"))
weights = torch.softmax(scores, dim=-1)
weights = self.dropout(weights)
out = weights @ v_for_attn
out = self._merge_heads(out)
out = self.o_proj(out)
return out, weights, present_key_value
测试一下形状:
x = torch.randn(2, 5, 4096)
gqa = GroupedQueryAttention(
hidden_dim=4096,
num_q_heads=32,
num_kv_heads=8,
)
out, weights, cache = gqa(x, use_cache=True)
print(out.shape) # [2, 5, 4096]
print(weights.shape) # [2, 32, 5, 5]
print(cache[0].shape) # [2, 8, 5, 128]
print(cache[1].shape) # [2, 8, 5, 128]
关键点在最后两行。
注意力权重仍然是 32 个 Query Head:
weights.shape == [2, 32, 5, 5]
但缓存里只有 8 个 KV Head:
cache[0].shape == [2, 8, 5, 128]
cache[1].shape == [2, 8, 5, 128]
这就是 GQA 在 KV Cache 上省显存的直接体现。
6. 用 PyTorch 接口怎么写
PyTorch 的 torch.nn.functional.scaled_dot_product_attention 已经有 enable_gqa 参数。
一个最小示例:
import torch
import torch.nn.functional as F
query = torch.randn(2, 32, 5, 128, device="cuda", dtype=torch.float16)
key = torch.randn(2, 8, 5, 128, device="cuda", dtype=torch.float16)
value = torch.randn(2, 8, 5, 128, device="cuda", dtype=torch.float16)
out = F.scaled_dot_product_attention(
query,
key,
value,
is_causal=True,
enable_gqa=True,
)
print(out.shape) # [2, 32, 5, 128]
官方文档里有两个约束很重要:
number_of_heads_query % number_of_heads_key_value == 0
number_of_heads_key == number_of_heads_value
也就是说:
- Query Head 数必须能被 KV Head 数整除;
- Key Head 数和 Value Head 数必须相同;
enable_gqa目前仍是实验特性,后端支持和张量类型有限制。
还有一个容易踩坑的点:PyTorch 这个函数里的布尔 attn_mask 语义,和一些 MHA 接口的 padding mask 语义相反。scaled_dot_product_attention 里 True 表示参与 attention,迁移代码时要小心。
7. 为什么 GQA 主要影响推理
如果只做一次完整 forward,而且不使用 KV Cache,GQA 对峰值显存的影响没有 KV Cache 场景那么直观。
真正的收益集中在自回归 decode:
每一步都要读历史 K/V
历史越长,读得越多
并发越高,cache 越多
KV Head 越少,cache 越小
Hugging Face 的优化文档也提到,减少 KV 向量数量只有在使用 KV Cache 的自回归解码场景里才特别有意义,因为 decode 阶段会反复读取历史 K/V,内存带宽很容易成为瓶颈。
所以可以这样理解:
| 场景 | GQA 价值 |
|---|---|
| 训练全序列并行 | 不是主要优化目标 |
| Prefill | 可以减少写入 cache 的 K/V 体积 |
| Decode | 最关键,减少每步读取的历史 K/V |
| 长上下文服务 | 价值更明显 |
| 高并发服务 | 价值更明显 |
这也是为什么讲 GQA 时,不能只画 attention 公式。要把它放回推理服务的 KV Cache 场景里看。
8. 和 vLLM、PagedAttention 有什么关系
GQA 解决的是:
每个 token、每一层、每个请求,要存多少 KV Head。
PagedAttention 解决的是:
这些 KV Cache 在显存里怎么分配、分页、复用和读取。
二者不是同一层优化,但会一起影响推理效率。
vLLM 的 PagedAttention 文档里提到,key/value cache 会被拆成 block,每个 block 存固定数量 token 的 cache。这样做的目标是用更适合服务端调度的方式管理 KV Cache,而不是把每个请求都当成一大段连续显存。
可以把它们放到同一张图里:
GQA:减少每个 token 的 KV 体积
PagedAttention:管理很多 token 的 KV 存放方式
Quantized Cache:降低每个元素的字节数
Offloaded Cache:把部分 cache 放到 CPU
如果只看单次模型结构,GQA 像是 attention 结构变化。
如果从推理系统看,GQA 是 KV Cache 成本控制的一环。
9. 常见坑
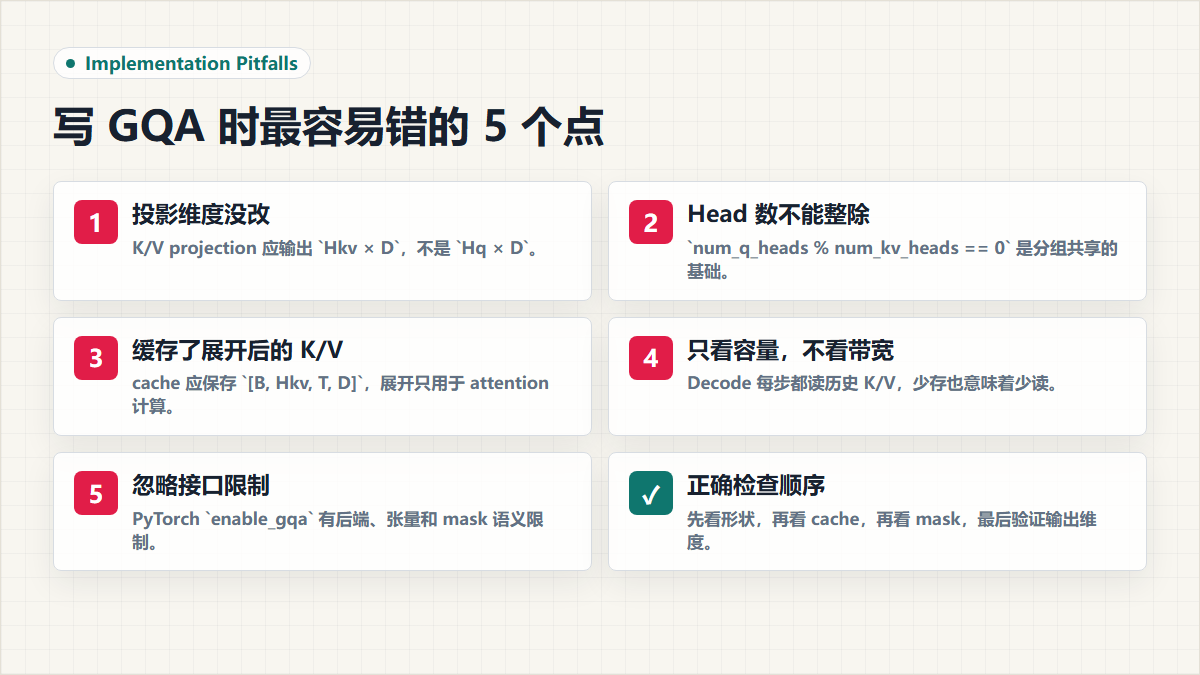
坑 1:只改 num_kv_heads,忘了改投影层输出维度
GQA 里 Q/K/V 的 projection 输出维度不一样:
q_proj -> num_q_heads * head_dim
k_proj -> num_kv_heads * head_dim
v_proj -> num_kv_heads * head_dim
如果还把 K/V 投影到 num_q_heads * head_dim,cache 就没有省下来。
坑 2:num_q_heads 不能整除 num_kv_heads
GQA 要按组共享 K/V,所以通常要求:
num_q_heads % num_kv_heads == 0
否则每组 Query Head 没法均匀映射到 KV Head。
坑 3:把 repeat 后的 K/V 当成 cache 存
教学代码为了看懂,会在 attention 前做 repeat_kv。
但 cache 里应该保留较少的 KV Head:
cache_k.shape == [B, H_kv, T, D]
如果把展开后的 K/V 存进去:
cache_k.shape == [B, H_q, T, D]
显存又回到 MHA 级别了。
坑 4:只算 cache 容量,不看内存带宽
KV Cache 不只是占显存。Decode 每一步都要读取历史 K/V,所以内存带宽也会成为瓶颈。
GQA 的价值不只是少存,也包括少读。
坑 5:把 GQA 当成无损替换
GQA 是效果和效率的折中。GQA 原论文的结论是,GQA 相比 MQA 更能保留 MHA 的质量,同时接近 MQA 的速度收益。但具体效果仍然取决于模型、训练方式、上采样策略和任务。
工程上不要把结构变化理解成“免费优化”。它通常是在模型设计或训练阶段就确定好的。
10. 面试怎么讲
如果面试官问:“GQA 和 MHA 有什么区别?”
可以这样回答:
MHA 里 Query、Key、Value 的 head 数通常一样,每个 Query Head 都有独立的 K/V Head。GQA 保留较多 Query Head,但减少 Key/Value Head,让一组 Query Head 共享一组 K/V。这样 attention 仍然有多个 Query 子空间,但 KV Cache 只需要存较少的 K/V Head。
如果继续问:“为什么能省显存?”
可以接:
KV Cache 每层都会存历史 token 的 K/V,大小和
num_kv_heads成正比。MHA 里num_kv_heads = num_q_heads,GQA 里num_kv_heads更小,所以 cache 的 K/V 张量更小。比如 32 个 Query Head、8 个 KV Head 时,KV Cache 大约是 MHA 的四分之一。
如果问:“GQA、MQA 怎么区分?”
可以答:
MQA 是所有 Query Head 共享一个 KV Head,省得最多,但表达能力可能受影响。GQA 是折中方案,多个 Query Head 分组共享多个 KV Head,通常在效率和效果之间更平衡。
如果问:“代码里最容易错在哪里?”
可以答:
第一,Q/K/V 投影维度不同;第二,Query Head 数要能整除 KV Head 数;第三,cache 里存的是未展开的 K/V,不要把 repeat 后的 K/V 存进 cache;第四,使用 PyTorch
enable_gqa=True时要注意 mask 语义和后端限制。
11. 一张速记表

| 问题 | 关键回答 |
|---|---|
| GQA 改了什么? | Query Head 多,KV Head 少 |
| 为什么能省显存? | KV Cache 大小和 num_kv_heads 成正比 |
| MHA 的 KV Head 数? | 通常等于 Query Head 数 |
| MQA 的 KV Head 数? | 1 个 |
| GQA 的 KV Head 数? | 介于 1 和 Query Head 数之间 |
| 代码核心约束? | num_q_heads % num_kv_heads == 0 |
| cache 里存什么? | 未展开的 K/V,形状是 [B, H_kv, T, D] |
| attention 前做什么? | 把 K/V 按组映射到 Query Head |
| 最适合讲的场景? | 长上下文、自回归 decode、高并发推理 |
| PyTorch 接口? | scaled_dot_product_attention(..., enable_gqa=True) |
总结
GQA 可以用三句话记住:
- MHA 每个 Query Head 通常都有自己的 K/V,KV Cache 按 Query Head 数增长。
- GQA 让一组 Query Head 共享较少的 K/V Head,KV Cache 按 KV Head 数增长。
- 它的主要价值出现在自回归推理,尤其是长上下文和高并发服务里。
所以,学 GQA 不要只记住一个缩写。
真正要记住的是这条线:
MHA 张量形状 -> KV Cache 显存公式 -> KV Head 数量 -> Decode 访存压力 -> GQA
这条线讲清楚了,GQA、MQA、KV Cache、长上下文推理优化,就能串起来。
参考资料
- Joshua Ainslie et al.:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
https://arxiv.org/abs/2305.13245 - PyTorch:
torch.nn.functional.scaled_dot_product_attention
https://docs.pytorch.org/docs/main/generated/torch.nn.functional.scaled_dot_product_attention.html - Hugging Face Transformers:Caching
https://huggingface.co/docs/transformers/main/cache_explanation - Hugging Face Transformers:KV cache strategies
https://huggingface.co/docs/transformers/main/kv_cache - Hugging Face Transformers:Optimizing LLMs for Speed and Memory
https://huggingface.co/docs/transformers/v4.35.2/llm_tutorial_optimization - vLLM:Paged Attention
https://docs.vllm.ai/en/latest/design/paged_attention/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)