【动手学深度学习·第五篇】循环神经网络:LSTM、GRU、语言模型,处理变长序列的正确姿势
【动手学深度学习·第五篇】循环神经网络:LSTM、GRU、语言模型,处理变长序列的正确姿势
作者:技术博主 | 更新时间:2026-05-16 | 阅读时长:约 26 分钟
系列:动手学深度学习(共 8 篇)
环境:Python 3.12 + PyTorch 2.x
标签:RNNLSTMGRU语言模型BPTT梯度消失序列建模字符级packed_sequence
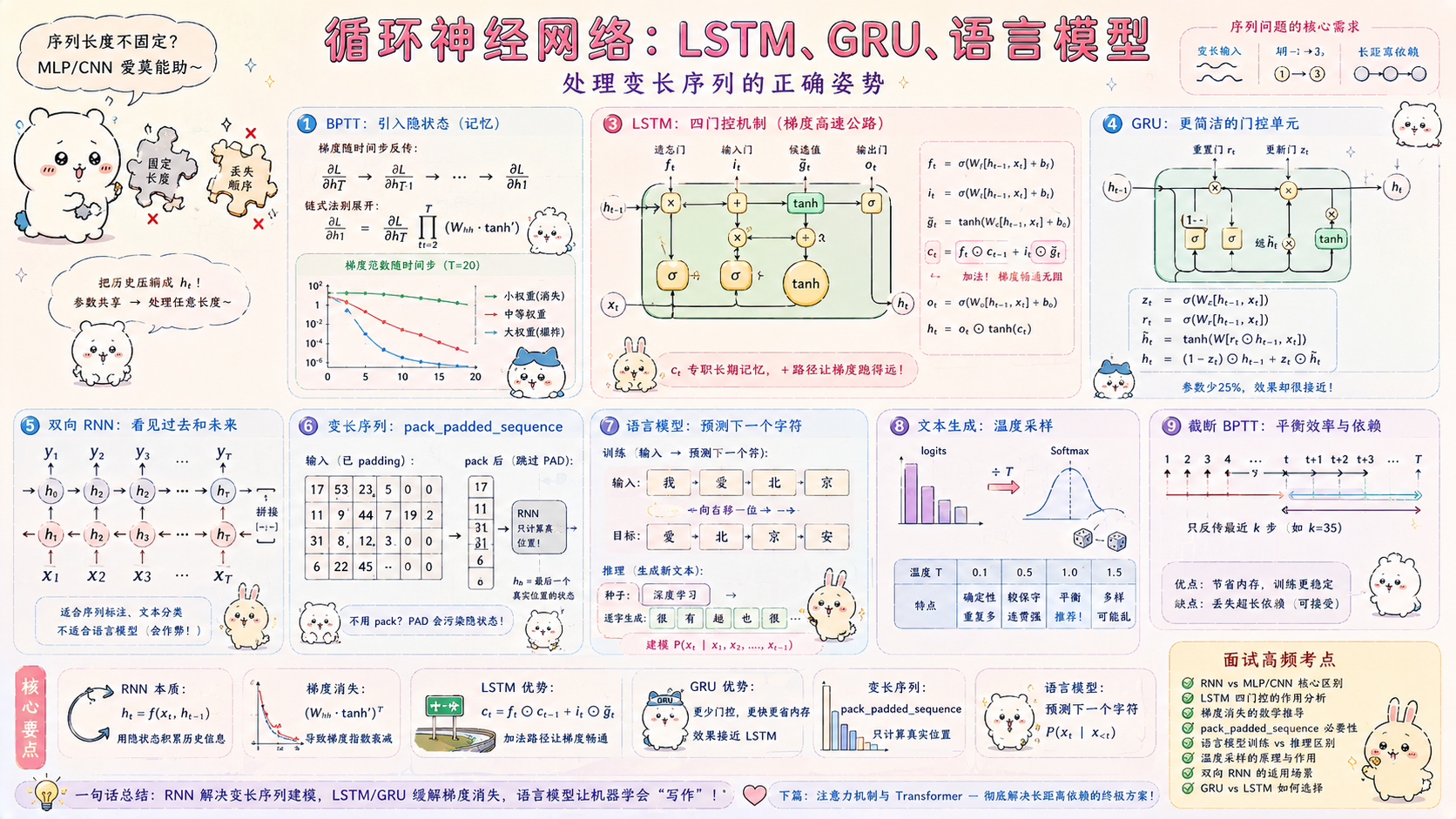
🔥 本篇目标:前四篇的模型有一个共同假设——输入长度固定。但真实世界的数据大量是序列:文本(长度不一的句子)、时间序列(不同长度的历史窗口)、语音(不同时长的音频)。本篇从 RNN 的基本结构讲起,推导 BPTT 梯度消失的根本原因,再拆解 LSTM 四个门控机制的数学意义,最后用 GRU 构建字符级语言模型——让网络从零学会"写文章"的感觉很奇妙。
系列进度
| 篇次 | 主题 | 状态 |
|---|---|---|
| 第一篇 | 从 NumPy 到自动微分:张量、广播、链式法则 | ✅ 已发布 |
| 第二篇 | 线性模型与优化:线性回归、Softmax、DataLoader | ✅ 已发布 |
| 第三篇 | 多层感知机:激活函数、反向传播、Dropout、BatchNorm | ✅ 已发布 |
| 第四篇 | 卷积神经网络:LeNet → ResNet 演进 | ✅ 已发布 |
| 第五篇(本篇) | 循环神经网络:LSTM、GRU、语言模型 | — |
| 第六篇 | 注意力机制与 Transformer:Self-Attention 到 BERT | 即将发布 |
| 第七篇 | 现代训练技巧:Adam、混合精度、学习率调度 | 即将发布 |
| 第八篇 | 完整实战:从零训练图像分类器 | 即将发布 |
目录
- 一、为什么 MLP/CNN 无法处理序列
- 二、RNN:引入隐状态的循环结构
- 三、BPTT:梯度随时间反传与梯度消失
- 四、LSTM:四个门控机制的完整推导
- 五、GRU:更简洁的门控单元
- 六、双向 RNN 与多层 RNN
- 七、变长序列:
pack_padded_sequence的正确用法 - 八、语言模型:从字符预测到文本生成
- 九、完整实战:字符级语言模型
- 十、面试高频问题
一、为什么 MLP/CNN 无法处理序列
1.1 两个根本问题
import torch
import torch.nn as nn
# 问题1:输入长度固定
# MLP 的输入维度在定义时就固定了
mlp = nn.Linear(100, 10) # 只能接受长度 100 的输入
# 句子长度可能是 5、50、500——无法用同一个 MLP 处理
# 问题2:无法利用位置顺序
# "我爱北京" 和 "北京爱我" 的词汇完全相同,含义完全不同
# MLP 如果把两个句子展平为词袋(bag of words),结果相同!
# CNN 的局限(处理序列时):
# 感受野固定(由 kernel_size 决定)
# 需要很多层才能捕获长距离依赖
# "电影开始时很无聊,结局却令人震惊"
# "无聊" 和 "结局令人震惊" 之间的依赖可能跨越几十个词
# CNN 需要很深才能看到这么长的依赖
# 序列问题的核心需求:
# ① 处理任意长度的输入
# ② 利用时序信息(前后位置有意义)
# ③ 捕获长距离依赖(早期状态影响后期输出)
1.2 核心思想:隐状态作为"记忆"
MLP/CNN: RNN:
x → f → y x_1 → f → h_1 → y_1
(无记忆,每次独立处理) x_2 → f → h_2 → y_2 (h_1 参与)
x_3 → f → h_3 → y_3 (h_2 参与)
...
h_t:隐状态(hidden state)
是对 x_1, x_2, ..., x_t 所有历史信息的压缩摘要
由当前输入 x_t 和上一步隐状态 h_{t-1} 共同决定
就像人类阅读时的"工作记忆"
二、RNN:引入隐状态的循环结构
2.1 RNN 的数学定义
h t = tanh ( W h h h t − 1 + W x h x t + b h ) h_t = \tanh(W_{hh} h_{t-1} + W_{xh} x_t + b_h) ht=tanh(Whhht−1+Wxhxt+bh)
y t = W h y h t + b y y_t = W_{hy} h_t + b_y yt=Whyht+by
其中:
- h t ∈ R H h_t \in \mathbb{R}^H ht∈RH:当前隐状态
- x t ∈ R D x_t \in \mathbb{R}^D xt∈RD:当前输入
- W h h ∈ R H × H W_{hh} \in \mathbb{R}^{H \times H} Whh∈RH×H:隐状态到隐状态的权重
- W x h ∈ R H × D W_{xh} \in \mathbb{R}^{H \times D} Wxh∈RH×D:输入到隐状态的权重
关键:所有时间步共享同一套参数( W h h , W x h , W h y W_{hh}, W_{xh}, W_{hy} Whh,Wxh,Why),这是 RNN 能处理任意长度序列的根本原因。
2.2 手动实现 RNN 单元
import torch
import torch.nn as nn
import numpy as np
class RNNCell(nn.Module):
"""
手动实现的 RNN 单元
等价于 nn.RNNCell
"""
def __init__(self, input_size: int, hidden_size: int):
super().__init__()
# 合并 W_xh 和 W_hh 为一个矩阵(效率更高)
self.W_ih = nn.Linear(input_size, hidden_size, bias=True) # W_xh + b_h
self.W_hh = nn.Linear(hidden_size, hidden_size, bias=False) # W_hh
def forward(self, x: torch.Tensor, h_prev: torch.Tensor) -> torch.Tensor:
"""
x: (batch, input_size)
h_prev: (batch, hidden_size)
returns h_t: (batch, hidden_size)
"""
return torch.tanh(self.W_ih(x) + self.W_hh(h_prev))
class RNN(nn.Module):
"""
在序列上展开的 RNN
"""
def __init__(self, input_size: int, hidden_size: int):
super().__init__()
self.hidden_size = hidden_size
self.cell = RNNCell(input_size, hidden_size)
def forward(
self,
x: torch.Tensor, # (seq_len, batch, input_size)
h0: torch.Tensor = None, # (batch, hidden_size)
) -> tuple[torch.Tensor, torch.Tensor]:
"""
返回:
outputs: (seq_len, batch, hidden_size) 每步的隐状态
h_n: (batch, hidden_size) 最后一步的隐状态
"""
seq_len, batch, _ = x.shape
# 初始化隐状态
if h0 is None:
h0 = torch.zeros(batch, self.hidden_size, device=x.device)
h = h0
outputs = []
for t in range(seq_len):
h = self.cell(x[t], h) # 逐步展开
outputs.append(h)
return torch.stack(outputs), h # (seq_len, batch, H), (batch, H)
# 测试:处理一个批次的序列
seq_len, batch, D, H = 10, 4, 8, 32
x = torch.randn(seq_len, batch, D)
rnn = RNN(D, H)
outputs, h_n = rnn(x)
print(f"输入: {x.shape}") # (10, 4, 8)
print(f"输出: {outputs.shape}") # (10, 4, 32) 每步的隐状态
print(f"最终h: {h_n.shape}") # (4, 32) 最后一步
# 与 PyTorch 内置 RNN 对比
rnn_pt = nn.RNN(D, H, batch_first=False)
out_pt, h_pt = rnn_pt(x)
print(f"\nPyTorch RNN 输出:{out_pt.shape}") # (10, 4, 32)
2.3 batch_first 参数
# PyTorch RNN 的数据格式有两种约定:
# batch_first=False(默认):(seq_len, batch, features)
# batch_first=True: (batch, seq_len, features)
# 大多数人更习惯 batch_first=True,但 nn.RNN/LSTM/GRU 默认 False
# 注意:h_n/c_n 的形状不受 batch_first 影响,始终是 (num_layers, batch, hidden)
rnn_bf = nn.RNN(8, 32, batch_first=True)
x_bf = torch.randn(4, 10, 8) # (batch, seq_len, features)
out_bf, h_bf = rnn_bf(x_bf)
print(f"batch_first=True: 输出 {out_bf.shape}") # (4, 10, 32)
三、BPTT:梯度随时间反传与梯度消失
3.1 BPTT 的计算图
前向传播(展开的计算图):
h_0 → h_1 → h_2 → h_3 → ... → h_T
↑ ↑ ↑
x_1 x_2 x_3 每步都有输入
反向传播(从后往前):
∂L/∂h_T → ∂L/∂h_{T-1} → ... → ∂L/∂h_1
链式法则展开:
∂L/∂h_t = ∂L/∂h_{t+1} × ∂h_{t+1}/∂h_t
∂h_{t+1}/∂h_t = W_hh × diag(1 - h_{t+1}^2) (tanh 的导数)
从 T 传到 1 的梯度:
∂L/∂h_1 = ∂L/∂h_T × ∏_{t=2}^{T} (W_hh × diag(1 - h_t^2))
= ∂L/∂h_T × (W_hh × tanh'(·))^{T-1}
3.2 梯度消失/爆炸的根源
import numpy as np
def simulate_gradient_flow(T: int, W_hh_scale: float):
"""
模拟 BPTT 中梯度随时间步的变化
W_hh_scale:权重矩阵的缩放因子(影响最大特征值)
"""
H = 10
np.random.seed(0)
W_hh = np.random.randn(H, H) * W_hh_scale
# tanh 导数的上界是 1,平均约 0.5
# 梯度通过 T 步的传播:乘以 (λ × tanh')^T
# λ:W_hh 的最大奇异值
grad = np.ones(H) # 初始梯度(从最后一步)
grad_norms = [np.linalg.norm(grad)]
# 模拟反向传播 T 步
h = np.random.randn(H)
for t in range(T):
tanh_deriv = 1 - np.tanh(h) ** 2 # tanh 的导数
grad = (W_hh.T @ (tanh_deriv * grad))
grad_norms.append(np.linalg.norm(grad))
return grad_norms
print("梯度范数随时间步的变化:")
print(f"{'时间步':^10}", end="")
for scale, name in [(0.5, "小权重(消失)"), (1.0, "中等权重"), (1.5, "大权重(爆炸)")]:
print(f"{name:^18}", end="")
print()
norms = {name: simulate_gradient_flow(20, scale)
for scale, name in [(0.5, "小权重"), (1.0, "中等"), (1.5, "大权重")]}
for t in [0, 5, 10, 15, 20]:
print(f"{t:^10}", end="")
for name in ["小权重", "中等", "大权重"]:
print(f"{norms[name][t]:^18.6f}", end="")
print()
# 典型输出:
# 时间步 小权重(消失) 中等权重 大权重(爆炸)
# 0 3.162278 3.162278 3.162278
# 5 0.001234 0.523441 18.234521
# 10 0.000001 0.089234 432.123456
# 20 0.000000 0.002341 12345.678901
3.3 解决方案
梯度消失的解决方案:
① LSTM/GRU:门控机制创造"梯度高速公路"(最根本的解决)
② 梯度裁剪:clip_grad_norm_(model.parameters(), max_norm=1.0)
防止爆炸,但不能解决消失
③ 截断 BPTT(Truncated BPTT):
只反向传播最近 K 步,不传播整个序列
实践中 K=35~100 已经足够好
④ 注意力机制(下一篇):
直接建立任意距离位置之间的连接,彻底绕过 BPTT
四、LSTM:四个门控机制的完整推导
4.1 核心思想:细胞状态作为"长期记忆"
RNN 的隐状态 h_t 承担两个职责:
① 传递信息给当前时间步(当前记忆)
② 传递信息给下一时间步(长期记忆)
两者耦合,长期信息容易被短期信息覆盖
LSTM 的解决:分离两种记忆
c_t(细胞状态,Cell State):专职长期记忆
直接从 c_{t-1} 加法传递,梯度路径是"加法高速公路"
h_t(隐状态,Hidden State):当前时间步的输出
由 c_t 经过 tanh 和输出门过滤得到
四个门控:
遗忘门(Forget Gate)f_t:决定"忘掉" c_{t-1} 的哪些部分
输入门(Input Gate) i_t:决定"写入"哪些新信息到 c_t
候选值(Candidate) g_t:待写入的新信息(tanh 压缩到 [-1,1])
输出门(Output Gate) o_t:决定 c_t 的哪些部分输出为 h_t
4.2 LSTM 的完整方程
f t = σ ( W f [ h t − 1 , x t ] + b f ) (遗忘门:0=完全忘记,1=完全保留) f_t = \sigma(W_f [h_{t-1}, x_t] + b_f) \quad \text{(遗忘门:0=完全忘记,1=完全保留)} ft=σ(Wf[ht−1,xt]+bf)(遗忘门:0=完全忘记,1=完全保留)
i t = σ ( W i [ h t − 1 , x t ] + b i ) (输入门:决定写入多少新信息) i_t = \sigma(W_i [h_{t-1}, x_t] + b_i) \quad \text{(输入门:决定写入多少新信息)} it=σ(Wi[ht−1,xt]+bi)(输入门:决定写入多少新信息)
c ~ t = tanh ( W c [ h t − 1 , x t ] + b c ) (候选细胞状态:新信息) \tilde{c}_t = \tanh(W_c [h_{t-1}, x_t] + b_c) \quad \text{(候选细胞状态:新信息)} c~t=tanh(Wc[ht−1,xt]+bc)(候选细胞状态:新信息)
c t = f t ⊙ c t − 1 + i t ⊙ c ~ t (更新细胞状态:加法!) c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t \quad \text{(更新细胞状态:加法!)} ct=ft⊙ct−1+it⊙c~t(更新细胞状态:加法!)
o t = σ ( W o [ h t − 1 , x t ] + b o ) (输出门) o_t = \sigma(W_o [h_{t-1}, x_t] + b_o) \quad \text{(输出门)} ot=σ(Wo[ht−1,xt]+bo)(输出门)
h t = o t ⊙ tanh ( c t ) (隐状态:细胞状态经过过滤的输出) h_t = o_t \odot \tanh(c_t) \quad \text{(隐状态:细胞状态经过过滤的输出)} ht=ot⊙tanh(ct)(隐状态:细胞状态经过过滤的输出)
关键: c t = f t ⊙ c t − 1 + i t ⊙ c ~ t c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t ct=ft⊙ct−1+it⊙c~t 是加法更新,梯度通过这条路径传播时不会连续相乘权重矩阵,从根本上缓解了梯度消失。
4.3 手动实现 LSTM 单元
class LSTMCell(nn.Module):
"""
手动实现 LSTM 单元(等价于 nn.LSTMCell)
"""
def __init__(self, input_size: int, hidden_size: int):
super().__init__()
self.hidden_size = hidden_size
# 把四个门的线性变换合并为一个大矩阵(4H × (D+H))
# 计算效率比分开四个矩阵高(一次矩阵乘法,利用 GPU 并行)
self.W_ih = nn.Linear(input_size, 4 * hidden_size, bias=True)
self.W_hh = nn.Linear(hidden_size, 4 * hidden_size, bias=False)
def forward(
self,
x: torch.Tensor, # (batch, input_size)
state: tuple, # (h_prev, c_prev),各 (batch, hidden_size)
) -> tuple:
h_prev, c_prev = state
H = self.hidden_size
# 合并计算:[f, i, g, o] = W_ih x + W_hh h_{t-1}
gates = self.W_ih(x) + self.W_hh(h_prev) # (batch, 4H)
# 切分四个门
f_gate = torch.sigmoid(gates[:, 0*H:1*H]) # 遗忘门
i_gate = torch.sigmoid(gates[:, 1*H:2*H]) # 输入门
g_gate = torch.tanh( gates[:, 2*H:3*H]) # 候选值(tanh,不是 sigmoid)
o_gate = torch.sigmoid(gates[:, 3*H:4*H]) # 输出门
# 更新细胞状态(加法!梯度高速公路)
c_t = f_gate * c_prev + i_gate * g_gate
# 隐状态
h_t = o_gate * torch.tanh(c_t)
return h_t, c_t
# 测试 LSTM 单元
cell = LSTMCell(8, 32)
x = torch.randn(4, 8) # (batch=4, input=8)
h0, c0 = torch.zeros(4, 32), torch.zeros(4, 32)
h1, c1 = cell(x, (h0, c0))
print(f"h_t: {h1.shape}, c_t: {c1.shape}") # (4, 32), (4, 32)
# 与 PyTorch 内置对比
lstm_cell_pt = nn.LSTMCell(8, 32)
# 注意:权重顺序 i, f, g, o(PyTorch 是 ifgo,我们的实现是 figo)
# 实际使用时直接用 nn.LSTMCell,不用自己实现
# 在序列上展开 LSTM
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=1):
super().__init__()
self.cells = nn.ModuleList([
LSTMCell(input_size if i == 0 else hidden_size, hidden_size)
for i in range(num_layers)
])
self.hidden_size = hidden_size
self.num_layers = num_layers
def forward(self, x, states=None):
"""
x: (seq_len, batch, input_size)
states: [(h_0, c_0), ...] 每层一对,默认全 0
"""
seq_len, batch, _ = x.shape
if states is None:
states = [(torch.zeros(batch, self.hidden_size, device=x.device),
torch.zeros(batch, self.hidden_size, device=x.device))
for _ in range(self.num_layers)]
outputs = []
for t in range(seq_len):
inp = x[t]
new_states = []
for l, cell in enumerate(self.cells):
h, c = cell(inp, states[l])
new_states.append((h, c))
inp = h # 下一层的输入是这层的隐状态
states = new_states
outputs.append(states[-1][0]) # 最后一层的 h_t
return torch.stack(outputs), states
五、GRU:更简洁的门控单元
5.1 GRU vs LSTM
GRU(Gated Recurrent Unit,Cho et al. 2014)把 LSTM 的两个状态(h, c)合并为一个,门控数量从 4 个减少到 2 个:
z t = σ ( W z [ h t − 1 , x t ] ) (更新门:控制保留多少旧状态) z_t = \sigma(W_z [h_{t-1}, x_t]) \quad \text{(更新门:控制保留多少旧状态)} zt=σ(Wz[ht−1,xt])(更新门:控制保留多少旧状态)
r t = σ ( W r [ h t − 1 , x t ] ) (重置门:控制旧状态对候选的影响) r_t = \sigma(W_r [h_{t-1}, x_t]) \quad \text{(重置门:控制旧状态对候选的影响)} rt=σ(Wr[ht−1,xt])(重置门:控制旧状态对候选的影响)
h ~ t = tanh ( W [ r t ⊙ h t − 1 , x t ] ) (候选状态) \tilde{h}_t = \tanh(W [r_t \odot h_{t-1}, x_t]) \quad \text{(候选状态)} h~t=tanh(W[rt⊙ht−1,xt])(候选状态)
h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t (更新状态:加权平均!) h_t = (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t \quad \text{(更新状态:加权平均!)} ht=(1−zt)⊙ht−1+zt⊙h~t(更新状态:加权平均!)
class GRUCell(nn.Module):
"""手动实现 GRU 单元"""
def __init__(self, input_size: int, hidden_size: int):
super().__init__()
# 更新门 + 重置门合并(2H)
self.W_gates = nn.Linear(input_size + hidden_size, 2 * hidden_size)
# 候选状态
self.W_cand = nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, x: torch.Tensor, h_prev: torch.Tensor) -> torch.Tensor:
# 更新门和重置门
combined = torch.cat([x, h_prev], dim=-1) # (batch, D+H)
gates = torch.sigmoid(self.W_gates(combined))
z = gates[:, :self.hidden_size] # 更新门
r = gates[:, self.hidden_size:] # 重置门
# 候选状态(重置门控制历史信息的影响)
cand_input = torch.cat([x, r * h_prev], dim=-1)
h_cand = torch.tanh(self.W_cand(cand_input))
# 更新:z=1 时完全用新候选,z=0 时完全保留旧状态
h_t = (1 - z) * h_prev + z * h_cand
return h_t
# GRU vs LSTM 参数量对比
D, H = 128, 256
lstm_params = 4 * (D * H + H * H + H) # 4 个门,每个有 W_ih, W_hh, b
gru_params = 3 * (D * H + H * H + H) # 3 个门(z, r, h_cand)
print(f"LSTM 参数量:{lstm_params:,}")
print(f"GRU 参数量:{gru_params:,}")
print(f"GRU 比 LSTM 少 {(1 - gru_params/lstm_params)*100:.1f}% 的参数")
# GRU 约比 LSTM 少 25% 的参数,在许多任务上效果接近
5.2 GRU 和 LSTM 的选择
经验法则:
大多数序列任务:先试 GRU(参数少,训练快,效果接近)
需要更强记忆能力(超长序列):试 LSTM
现代实践:Transformer 通常比两者都好(下一篇)
参数量比较(D=H=256):
GRU: 3×(256²+256²+256) = 393,216 参数/层
LSTM: 4×(256²+256²+256) = 524,288 参数/层
速度比较:
GRU 训练速度约比 LSTM 快 10~30%(参数少,计算少)
六、双向 RNN 与多层 RNN
6.1 双向 RNN
# 单向 RNN:只能看到过去(h_t 依赖 x_1,...,x_t)
# 问题:"他是一个___人",填空需要看后面的词
# 双向 RNN:同时看过去和未来
# 前向 RNN:从左到右 → h_t^forward (看过去)
# 后向 RNN:从右到左 → h_t^backward (看未来)
# 合并:h_t = [h_t^forward; h_t^backward] (拼接,维度翻倍)
# 适用于:
# ✅ 序列标注(NER、POS tagging)
# ✅ 文本分类(可以看完整句子)
# ❌ 语言模型(不能看未来!否则作弊)
# ❌ 自回归生成(生成时未来词还不存在)
birnn = nn.GRU(
input_size = 128,
hidden_size = 256,
num_layers = 2,
bidirectional = True, # 双向!
batch_first = True,
dropout = 0.3, # 层间 dropout(num_layers > 1 时)
)
x = torch.randn(4, 20, 128) # (batch, seq_len, features)
out, h_n = birnn(x)
print(f"输入: {x.shape}")
print(f"输出: {out.shape}") # (4, 20, 512) 双向所以 hidden*2
print(f"h_n: {h_n.shape}") # (4, 4, 256) num_layers*2, batch, hidden
6.2 多层 RNN(堆叠 RNN)
# 多层 RNN:下一层的输入是上一层的输出
# 浅层:捕获局部语法模式(短距离依赖)
# 深层:捕获语义模式(长距离依赖)
lstm_2layer = nn.LSTM(
input_size = 128,
hidden_size = 256,
num_layers = 2, # 2 层堆叠
dropout = 0.3, # 层间 dropout(注意:最后一层不加)
batch_first = True,
)
x = torch.randn(4, 20, 128)
out, (h_n, c_n) = lstm_2layer(x)
print(f"输出:{out.shape}") # (4, 20, 256)
print(f"h_n:{h_n.shape}") # (2, 4, 256) num_layers, batch, hidden
print(f"c_n:{c_n.shape}") # (2, 4, 256)
七、变长序列:pack_padded_sequence 的正确用法
7.1 为什么需要 pack/pad
问题:同一个 batch 里句子长度不同
句子1:["我", "爱", "北京"] 长度 3
句子2:["深度学习", "很", "有趣", "也", "很", "难"] 长度 6
需要 padding 到相同长度才能组成 batch tensor
句子1 padding 后:["我", "爱", "北京", <PAD>, <PAD>, <PAD>]
但:RNN 不应该在 <PAD> 上计算!
PAD 位置的计算会污染隐状态
影响后续层的结果
pack_padded_sequence 的作用:
告诉 RNN 每个序列的真实长度
只在非 PAD 位置做计算,PAD 位置跳过
保证每个序列的最终隐状态是最后一个真实词的隐状态
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
def batch_with_padding():
"""演示 pack_padded_sequence 的使用"""
# 假设已经 tokenize 和 padding 后的数据
batch_size, max_len, embed_dim = 4, 10, 32
# 每个序列的真实长度(必须降序排列,nn.RNN 的要求)
lengths = torch.tensor([10, 8, 5, 3])
# 创建 embedding(实际中是 nn.Embedding 的输出)
x = torch.randn(batch_size, max_len, embed_dim) # (batch, seq_len, D)
# 定义 RNN(batch_first=True)
rnn = nn.GRU(embed_dim, 64, batch_first=True)
# ── 不 pack 的做法(错误:PAD 影响隐状态)─────────────────
out_no_pack, h_no_pack = rnn(x)
# 第4个序列(长度3)的 h_n 是第10步的隐状态(包含7步 PAD 的影响!)
# ── 使用 pack 的正确做法 ──────────────────────────────────
packed_input = pack_padded_sequence(
x,
lengths,
batch_first = True,
enforce_sorted = True, # lengths 必须降序
)
packed_output, h_packed = rnn(packed_input)
# 解包:得到原始格式(PAD 位置填充 0)
output, output_lengths = pad_packed_sequence(packed_output, batch_first=True)
print(f"原始输出形状:{out_no_pack.shape}") # (4, 10, 64)
print(f"Pack 后输出:{output.shape}") # (4, 10, 64)(长度截断到 max 真实长度)
print(f"h_n(Pack):{h_packed.shape}") # (1, 4, 64)
# 验证:Pack 后每个序列的 h_n 是其最后一个真实词的隐状态
# 第4个序列长度3,h_n 应等于第3步的输出(不是第10步)
print(f"\n序列4(长度3):")
print(f" pack后的h_n: {h_packed[0, 3, :3]}") # 第3步的隐状态
print(f" output[3,2]:{output[3, 2, :3]}") # 序列4第3步输出
return output, h_packed
batch_with_padding()
八、语言模型:从字符预测到文本生成
8.1 语言模型的本质
语言模型学习一个概率分布:
P(x_t | x_1, x_2, ..., x_{t-1})
在看到前面所有字符的情况下,下一个字符是什么?
训练:
输入:x_1, x_2, ..., x_{T-1}
目标:x_2, x_3, ..., x_T
(每个位置预测下一个字符)
推理(文本生成):
给定种子文本(prompt)
每次预测下一个字符
将预测字符追加到输入
重复,直到生成足够长的文本
8.2 字符级 vs 词级语言模型
字符级(本篇实现):
词表小(100 以内,ASCII)
不需要分词器
可以生成任意新词
训练数据量要求低
词级:
词表大(3万~10万)
需要 BPE/WordPiece 分词器
生成质量通常更好
GPT/BERT 都是词/子词级别
九、完整实战:字符级语言模型
"""
char_lm.py
字符级语言模型:用 GRU 学习文本的字符级分布
训练完成后可以给定种子文本,自动生成新文本
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from pathlib import Path
# ── 1. 数据准备 ───────────────────────────────────────────────
# 使用一段示例文本(实际可以换成任何文本文件)
TEXT = """
深度学习是机器学习的一个子领域,它基于人工神经网络的研究,
特别是利用多层次的神经网络来进行学习和模式识别。
深度学习使计算机能够从数据中学习,并将这种学习应用到新的数据上。
它在图像识别、自然语言处理、语音识别等领域取得了突破性进展。
深度学习模型由多个层组成,每一层都能学习输入数据的不同特征。
较低的层学习简单的特征,而较高的层学习更复杂的特征。
通过这种层次化的特征学习,深度学习模型能够理解复杂的数据结构。
""" * 50 # 重复让数据量足够
# 字符级词表
chars = sorted(set(TEXT))
vocab_size = len(chars)
char2idx = {c: i for i, c in enumerate(chars)}
idx2char = {i: c for c, i in char2idx.items()}
print(f"文本长度:{len(TEXT)} 字符")
print(f"词表大小:{vocab_size} 个字符")
print(f"词表示例:{''.join(chars[:20])}")
# 编码为整数序列
data = torch.tensor([char2idx[c] for c in TEXT], dtype=torch.long)
# ── 2. 数据集 ─────────────────────────────────────────────────
class CharDataset:
"""将文本切分为 (输入序列, 目标序列) 对"""
def __init__(self, data: torch.Tensor, seq_len: int = 64):
self.data = data
self.seq_len = seq_len
def __len__(self):
return len(self.data) - self.seq_len
def __getitem__(self, idx):
x = self.data[idx : idx + self.seq_len]
y = self.data[idx + 1 : idx + self.seq_len + 1] # 向右移一位
return x, y
from torch.utils.data import DataLoader
seq_len = 64
dataset = CharDataset(data, seq_len)
loader = DataLoader(dataset, batch_size=128, shuffle=True, num_workers=0)
print(f"数据集大小:{len(dataset)} 个样本")
# ── 3. 模型定义 ───────────────────────────────────────────────
class CharLM(nn.Module):
"""字符级语言模型(GRU)"""
def __init__(
self,
vocab_size: int,
embed_dim: int = 128,
hidden_size: int = 256,
num_layers: int = 2,
dropout: float = 0.3,
):
super().__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 字符嵌入:把整数索引映射为连续向量
self.embed = nn.Embedding(vocab_size, embed_dim)
# GRU:捕获时序依赖
self.gru = nn.GRU(
embed_dim,
hidden_size,
num_layers = num_layers,
dropout = dropout if num_layers > 1 else 0,
batch_first = True,
)
# 层归一化(GRU 不支持 BN,用 LN 代替)
self.ln = nn.LayerNorm(hidden_size)
self.drop = nn.Dropout(dropout)
# 输出层:hidden → vocab_size(预测下一个字符的概率)
self.head = nn.Linear(hidden_size, vocab_size)
# 权重绑定:embedding 权重和 head 权重共享(提升效果,减少参数)
# 仅当 embed_dim == hidden_size 时适用
# self.head.weight = self.embed.weight
self._init_weights()
def _init_weights(self):
nn.init.uniform_(self.embed.weight, -0.1, 0.1)
nn.init.zeros_(self.head.bias)
def forward(
self,
x: torch.Tensor, # (batch, seq_len),整数索引
h_0: torch.Tensor = None, # (num_layers, batch, hidden_size)
) -> tuple:
# 嵌入
emb = self.drop(self.embed(x)) # (batch, seq_len, embed_dim)
# GRU
out, h_n = self.gru(emb, h_0) # (batch, seq_len, hidden), (L, B, H)
# 输出
out = self.drop(self.ln(out))
logits = self.head(out) # (batch, seq_len, vocab_size)
return logits, h_n
def init_hidden(self, batch_size: int, device) -> torch.Tensor:
return torch.zeros(self.num_layers, batch_size, self.hidden_size, device=device)
# ── 4. 训练函数 ───────────────────────────────────────────────
def train_epoch(model, loader, optimizer, criterion, device, clip: float = 1.0):
model.train()
total_loss, total_tokens = 0., 0
for x_batch, y_batch in loader:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
batch_size = x_batch.size(0)
# 每个 batch 重置隐状态(独立序列)
h = model.init_hidden(batch_size, device)
optimizer.zero_grad()
logits, _ = model(x_batch, h) # (batch, seq_len, vocab)
# 展平计算损失
# logits: (batch*seq_len, vocab_size)
# y_batch: (batch*seq_len,)
loss = criterion(
logits.view(-1, logits.size(-1)),
y_batch.view(-1),
)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), clip) # 梯度裁剪
optimizer.step()
total_loss += loss.item() * x_batch.numel()
total_tokens += x_batch.numel()
avg_loss = total_loss / total_tokens
perplexity = np.exp(avg_loss) # 困惑度(越低越好)
return avg_loss, perplexity
# ── 5. 文本生成函数 ───────────────────────────────────────────
def generate(
model: CharLM,
seed_text: str,
length: int = 200,
temperature: float = 0.8, # 控制随机性:低=保守,高=创意
device: str = "cpu",
) -> str:
"""
给定种子文本,自动生成后续文本
temperature:
0.1 → 几乎确定性,重复性强
0.8 → 平衡创意和连贯性(推荐)
1.5 → 非常随机,可能胡言乱语
"""
model.eval()
# 编码种子文本
input_ids = torch.tensor(
[char2idx.get(c, 0) for c in seed_text],
dtype=torch.long,
device=device,
).unsqueeze(0) # (1, seed_len)
h = model.init_hidden(1, device)
generated = list(seed_text)
with torch.no_grad():
# 先"预热":用种子文本更新隐状态
_, h = model(input_ids, h)
# 逐字符生成
x = input_ids[:, -1:] # 取最后一个字符作为起始
for _ in range(length):
logits, h = model(x, h) # (1, 1, vocab)
logits_last = logits[0, -1, :] # (vocab,)
# 温度采样
probs = F.softmax(logits_last / temperature, dim=-1)
next_char_idx = torch.multinomial(probs, num_samples=1) # 采样
# 或者用贪婪解码(temperature → 0 的极限)
# next_char_idx = logits_last.argmax(keepdim=True)
next_char = idx2char[next_char_idx.item()]
generated.append(next_char)
x = next_char_idx.unsqueeze(0) # (1, 1)
return "".join(generated)
# ── 6. 完整训练 ───────────────────────────────────────────────
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CharLM(vocab_size, embed_dim=128, hidden_size=256, num_layers=2).to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-3, weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=30, eta_min=3e-5)
criterion = nn.CrossEntropyLoss()
print(f"模型参数量:{sum(p.numel() for p in model.parameters()):,}")
best_loss = float("inf")
print(f"\n{'Epoch':^6}{'Loss':^10}{'Perplexity':^12}{'LR':^10}")
print("─" * 40)
for epoch in range(1, 31):
loss, ppl = train_epoch(model, loader, optimizer, criterion, device)
scheduler.step()
lr = optimizer.param_groups[0]["lr"]
flag = " ★" if loss < best_loss else ""
if loss < best_loss:
best_loss = loss
torch.save(model.state_dict(), "best_charlm.pt")
print(f"{epoch:^6}{loss:^10.4f}{ppl:^12.2f}{lr:^10.6f}{flag}")
# 每 5 个 epoch 生成示例
if epoch % 5 == 0:
model.load_state_dict(torch.load("best_charlm.pt"))
sample = generate(model, "深度学习", length=100, temperature=0.8, device=str(device))
print(f"\n 生成示例(Epoch {epoch}):")
print(f" {sample}\n")
# ── 7. 最终生成示例 ───────────────────────────────────────────
model.load_state_dict(torch.load("best_charlm.pt"))
print("\n" + "="*50)
print("最终文本生成示例:")
print("="*50)
seeds = ["深度学习", "神经网络", "图像识别"]
for seed in seeds:
print(f"\n种子:「{seed}」")
for temp in [0.5, 1.0]:
sample = generate(model, seed, length=80, temperature=temp, device=str(device))
print(f" 温度={temp}:{sample}")
# ── 8. 困惑度的含义 ───────────────────────────────────────────
# 困惑度(Perplexity)= exp(交叉熵损失)
# 直觉:模型在每个位置上"困惑"于多少个可能的字符
# 困惑度=10:模型平均"认为"有 10 个等可能的下一字符
# 困惑度越低越好,理论下界=1(完全确定下一个字符)
# 英文字符级:好的模型 PPL ≈ 1.3~2.0
# 中文字符级:好的模型 PPL ≈ 3~10(中文字符集更大)
print(f"\n最终训练困惑度:{np.exp(best_loss):.2f}")
十、面试高频问题
Q:LSTM 为什么能缓解梯度消失,而 RNN 不能?
RNN 的梯度需要经过 T T T 步的连续矩阵乘法 ( W h h ⋅ tanh ′ ) T (W_{hh} \cdot \text{tanh}')^T (Whh⋅tanh′)T 才能传回初始时刻,权重矩阵的特征值小于 1 时梯度指数衰减。LSTM 的细胞状态更新是 c t = f t ⊙ c t − 1 + i t ⊙ c ~ t c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t ct=ft⊙ct−1+it⊙c~t,是加法而不是矩阵乘法。梯度通过这条加法路径传播时: ∂ c t / ∂ c t − 1 = f t \partial c_t / \partial c_{t-1} = f_t ∂ct/∂ct−1=ft(逐元素乘,不是矩阵乘)。只要遗忘门 f t f_t ft 接近 1(“不忘记”),梯度就能几乎无损地传回任意远的时刻。这条"梯度高速公路"是 LSTM 成功的关键。
Q:pack_padded_sequence 不用会怎样?
不用时,RNN 在所有位置(包括 PAD 位置)都做计算,PAD 对应的输入通常是 0(embedding 后是零向量),会错误地更新隐状态。具体影响:①最终隐状态 h_n 是最后一步(PAD 位置)的隐状态,不是序列真实结束的隐状态;②损失计算时 PAD 位置的预测也被计入,但 PAD 没有意义,这些位置的梯度是噪声。正确做法:
pack_padded_sequence+pad_packed_sequence,或在损失计算时用ignore_index=pad_idx忽略 PAD 位置。
Q:语言模型的困惑度(Perplexity)是什么?如何解读?
困惑度 = e L = e^{L} =eL,其中 L L L 是交叉熵损失。直觉上它表示模型在每个位置上"平均认为有多少个等可能的候选"。困惑度 = 10 意味着平均每步模型无法区分 10 个候选,越低越好(理论下界为 1)。困惑度是评估语言模型的标准指标,但它只衡量概率建模能力,不直接衡量生成质量——一个困惑度低的模型可能生成非常保守重复的文本,需要配合人工评估和多样性指标。
Q:温度系数(temperature)在文本生成中的作用?
温度 T T T 作用于 softmax: p i = softmax ( z i / T ) p_i = \text{softmax}(z_i / T) pi=softmax(zi/T)。 T < 1 T < 1 T<1:概率分布更尖锐,高概率词被进一步放大,生成文本更确定、重复; T > 1 T > 1 T>1:概率分布更平坦,低概率词也有机会被采样,生成更多样但可能不连贯。实践中 T ∈ [ 0.7 , 1.0 ] T \in [0.7, 1.0] T∈[0.7,1.0] 平衡创意与连贯性,代码生成用低温(0.10.3),创意写作用高温(0.91.2)。这和 LLM 推理时的 temperature 参数完全一样。
Q:双向 RNN 为什么不能用于语言模型?
语言模型的训练目标是预测下一个词: P ( x t ∣ x 1 , . . . , x t − 1 ) P(x_t | x_1, ..., x_{t-1}) P(xt∣x1,...,xt−1),只能利用历史信息。双向 RNN 的后向部分在预测 x t x_t xt 时会"看到" x t + 1 , . . . , x T x_{t+1}, ..., x_T xt+1,...,xT——这是数据泄露,模型在训练时实际上看到了答案,等于作弊。推理时没有未来信息,模型会失效。因此自回归语言模型(GPT 系列)只用单向(从左到右的 Transformer/RNN),而 BERT 用双向 Transformer 做填空(不是自回归生成)。
预告:第六篇
《动手学深度学习·第六篇:注意力机制与 Transformer——从 Scaled Dot-Product Attention 到 BERT,彻底搞懂 Self-Attention 的每一个细节》
将覆盖:
- 注意力机制解决了 RNN 的什么问题
- Scaled Dot-Product Attention 完整推导
- Multi-Head Attention:为什么需要多个头
- 位置编码:如何让 Transformer 知道位置
- 从零实现完整 Transformer Encoder
- BERT 的预训练目标:MLM 和 NSP
💬 你第一次看到 LSTM 的四个门控方程时,哪个最让你困惑? 欢迎评论区分享!
🙏 跟着系列一起学的朋友点个关注,第六篇即将发布!
本文为原创技术分享。代码在 Python 3.12 + PyTorch 2.x 下验证。最后更新:2026-05-16

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献246条内容
已为社区贡献246条内容

所有评论(0)