pdf-to-skill|把高分论文里的方法路线与图表逻辑,转化为可反复调用的Codex Skill模板
想读一篇高分文献,但是不想只得到一份摘要。
想把论文里的研究思路、方法路线、图表逻辑,变成一个可以反复调用的 Codex Skill。
项目地址:
https://github.com/T-Zevin/pdf-to-skill
0. 为什么做这个项目
很多人读文献时,最常见的需求并不是“帮我总结一下这篇论文”,而是:
这篇论文为什么这样设计?
它的研究问题是怎么提出的?
它的图 1 到图 6 是怎么推进证据链的?
它的方法能不能迁移到我的课题?
如果我换一个疾病、队列、数据集或实验体系,应该怎么复用这套思路?
普通 AI 文献总结通常会输出:
研究背景
研究方法
研究结果
研究结论
这当然有用,但它更像是“读懂这篇文章”。
而真正做科研、做课题、写文章时,我们更需要的是:
学会这篇文章的研究设计方式。
所以我做了一个小项目:
pdf-to-skill
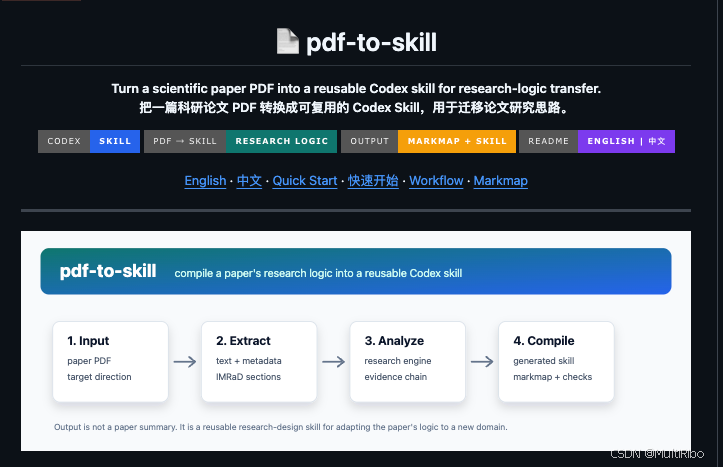
它的目标不是把论文变成摘要,而是把一篇论文变成一个可以反复调用的 Codex Skill。
1. 项目是什么
pdf-to-skill 是一个面向 Codex 的文献研究思路提取工具。
它可以把一篇科研论文 PDF 转换成一个结构化的 Skill,用来辅助后续做:
- 课题迁移;
- 研究设计;
- 技术路线规划;
- 图表逻辑设计;
- 论文结果部分构思;
- 方法学复用;
- 医学、生信、多组学、单细胞、空间转录组、预测模型等方向的选题设计。
项目地址:
https://github.com/T-Zevin/pdf-to-skill
一句话概括:
pdf-to-skill = 论文阅读 → 研究逻辑提取 → 可复用 Codex Skill
2. 它和普通论文总结有什么不同
| 对比项 | 普通论文总结 | pdf-to-skill |
|---|---|---|
| 核心目标 | 读懂论文 | 复用论文研究思路 |
| 输出内容 | 背景、方法、结果、结论 | 研究问题、中心假设、方法主线、图表证据链、迁移规则 |
| 使用方式 | 一次性阅读 | 生成 Skill 后反复调用 |
| 是否适合换方向 | 较弱 | 强 |
| 是否保留图表逻辑 | 通常较少 | 强调 Figure-by-Figure evidence chain |
| 是否关注方法迁移风险 | 很少 | 明确标出哪些能迁移、哪些不能迁移 |
| 适合场景 | 快速读文献 | 学习文章套路、迁移课题设计、搭建论文框架 |
普通总结回答的是:
这篇论文讲了什么?
pdf-to-skill 更关注:
这篇论文是怎么设计出来的?
这套设计能不能迁移到我的方向?
如果迁移,应该保留什么、替换什么、警惕什么?
3. 基本原理
整体流程如下:
科研论文 PDF
│
│ 文本抽取
▼
full_text.txt / metadata.json / sections.json
│
│ Codex 分析论文结构
▼
研究问题 / 中心假设 / 研究设计 / 方法主线 / 图表证据链
│
│ 迁移到目标方向
▼
生成 paper-derived Codex Skill
也可以理解为:
不是把论文“压缩”为摘要,
而是把论文“编译”为 Skill。
4. 它会提取什么
pdf-to-skill 重点提取论文中的这些结构:
| 模块 | 说明 |
|---|---|
| Research problem | 这篇论文解决了什么问题 |
| Central hypothesis | 核心假设是什么 |
| Novelty source | 创新点来自哪里 |
| Study design skeleton | 样本、分组、对照、终点、验证方式 |
| Methods spine | 数据处理、模型、实验、统计方法 |
| Figure evidence chain | 每张图回答什么问题、支撑什么结论 |
| Transfer map | 原论文元素如何迁移到新方向 |
| Failure modes | 哪些地方不能照搬,哪里容易过度推断 |
例如读一篇生信文章时,它不只是告诉你:
作者做了差异分析、富集分析、免疫浸润分析。
而是进一步提取:
为什么先做差异分析?
差异分析后为什么接富集?
哪一张图负责提出核心现象?
哪一张图负责机制解释?
哪一张图负责外部验证?
如果换成另一个癌种,这套逻辑如何重建?
5. 适合哪些人
这个项目比较适合:
- 医学科研人员;
- 生信分析人员;
- 多组学研究者;
- 单细胞 / 空间转录组方向研究者;
- 临床预测模型方向作者;
- 需要大量阅读文献并迁移研究设计的人;
- 想用 Codex 建立个人科研方法库的人;
- 想把“读过的好论文”沉淀为可复用模板的人。
尤其适合这类场景:
我看到一篇高分论文,想学习它的研究套路,
但是我要做的是另一个疾病 / 数据集 / 课题方向。
6. 项目结构
仓库结构大致如下:
pdf-to-skill/
├── SKILL.md
├── README.md
├── agents/
│ └── openai.yaml
├── assets/
│ ├── workflow.svg
│ └── output-structure.svg
├── references/
│ ├── generated-skill-template.md
│ ├── method-adaptation-rubric.md
│ └── report-template.md
└── scripts/
├── extract_paper.py
└── scaffold_skill.py
其中:
| 文件 | 作用 |
|---|---|
SKILL.md |
Codex Skill 主入口 |
extract_paper.py |
从 PDF / DOCX / TXT / MD 中抽取论文文本和元数据 |
scaffold_skill.py |
生成 paper-derived skill 骨架 |
report-template.md |
研究思路迁移报告模板 |
generated-skill-template.md |
新 Skill 生成模板 |
method-adaptation-rubric.md |
判断方法能否迁移的评价标准 |
assets/ |
README 中的项目流程图 |
7. 安装方式
把项目放到 Codex skills 目录:
mkdir -p ~/.codex/skills
git clone https://github.com/T-Zevin/pdf-to-skill.git ~/.codex/skills/pdf-to-skill
或者如果你已经下载了项目:
mkdir -p ~/.codex/skills
cp -R /path/to/pdf-to-skill ~/.codex/skills/pdf-to-skill
检查是否安装成功:
ls ~/.codex/skills/pdf-to-skill
正常情况下应该能看到:
SKILL.md
README.md
agents
assets
references
scripts
8. 基础用法
8.1 只分析论文,不生成 Skill
用 $pdf-to-skill 分析 /path/to/paper.pdf,
只输出研究思路迁移报告和 markmap。
适合先判断这篇论文值不值得学。
8.2 生成一个新方向 Skill
用 $pdf-to-skill 阅读 /path/to/paper.pdf,
学习它的研究设计,
并生成一个用于“肺腺癌脑转移”的新 skill。
8.3 指定目标方向
用 $pdf-to-skill 阅读 /path/to/paper.pdf,
把这篇论文的研究思路迁移到“结直肠癌空间转录组”方向,
并生成一个新的 Codex Skill。
9. 直接运行脚本
如果只是想测试 PDF 抽取,可以运行:
python3 scripts/extract_paper.py /path/to/paper.pdf
支持格式:
.pdf
.txt
.md
.docx
输出目录:
/tmp/pdf_to_skill_work/
├── full_text.txt
├── metadata.json
└── sections.json
其中:
| 文件 | 内容 |
|---|---|
full_text.txt |
抽取出的论文全文 |
metadata.json |
文件名、页数、词数、token 估算、标题猜测、DOI 猜测 |
sections.json |
粗略识别出的 Abstract / Introduction / Results 等结构 |
10. 生成 Skill 骨架
如果已经知道目标方向,可以先生成一个空 Skill 骨架:
python3 scripts/scaffold_skill.py \
--name luad-brain-metastasis-paper-logic \
--title "Short Paper Title" \
--target "LUAD brain metastasis" \
--out ~/.codex/skills
生成结果类似:
luad-brain-metastasis-paper-logic/
├── SKILL.md
└── references/
├── paper-map.md
├── research-transfer.md
├── figure-evidence-chain.md
└── method-adaptation-checklist.md
11. 一个典型输出应该长什么样
一个 paper-derived skill 不应该只是:
这篇论文主要研究了什么。
而应该包括:
何时使用这个 Skill
原论文的核心研究模式
方向切换工作流
可复用设计模块
不能过度迁移的部分
详细参考文件索引
例如:
原论文:单细胞分析肿瘤免疫微环境
目标方向:肺腺癌脑转移
迁移方式:
- 原始样本:原发肿瘤组织 → 脑转移组织 / 原发-转移配对样本
- 原始表型:免疫治疗响应 → 脑转移风险 / 生存结局
- 原始方法:细胞亚群注释 + 通路分析 → 转移相关细胞生态位分析
- 原始验证:外部队列 → 公共队列 + 组织实验验证
12. 推荐迁移表
使用时可以让 Codex 输出这种表:
| 原论文元素 | 是否保留 | 新方向如何替换 | 风险 |
|---|---|---|---|
| 研究对象 / 样本 | |||
| 疾病 / 场景 | |||
| 暴露因素 / 特征 | |||
| 结局指标 / 表型 | |||
| 数据类型 / 实验技术 | |||
| 统计方法 / 模型 | |||
| 验证方式 | |||
| 图表证据链 |
这个表的价值在于,它强迫我们区分:
哪些是论文真正可迁移的结构,
哪些只是原研究场景下成立的具体细节。
13. 图表证据链
我觉得这个项目里最有用的一点,是强调 Figure Evidence Chain。
读论文时,不只是看:
图 1 画了什么?
图 2 画了什么?
而是看:
图 1 解决什么问题?
图 2 为什么必须接在图 1 后面?
图 3 是否提出机制?
图 4 是否做验证?
图 5 是否证明临床价值?
一个典型图表链可以这样拆:
| 图表 | 回答的问题 | 方法 | 支撑的结论 | 如何迁移 |
|---|---|---|---|---|
| Fig. 1 | 研究对象和总体设计是什么 | 队列流程图 / 数据概览 | 证明研究设计成立 | 换成目标疾病队列 |
| Fig. 2 | 是否存在关键差异 | 差异分析 / 聚类 / 比较 | 找到核心现象 | 换成目标表型 |
| Fig. 3 | 关键机制或模型是什么 | 通路 / 网络 / 模型 | 提出核心解释 | 替换为目标机制 |
| Fig. 4 | 是否能验证 | 外部数据 / 实验验证 | 增强可信度 | 设计外部验证 |
| Fig. 5 | 是否有应用价值 | 预测模型 / DCA / 干预实验 | 证明实际意义 | 换成目标应用场景 |
14. Markmap 示例
每次分析后,可以输出一个 markmap 思维导图:
# pdf-to-skill
## 输入
### 科研论文 PDF
### 目标研究方向
## 抽取
### full_text.txt
### metadata.json
### sections.json
## 研究发动机
### 研究问题
### 中心假设
### 创新来源
### 研究设计
### 方法主线
### 验证逻辑
## 迁移
### 原始人群 -> 目标人群
### 原始变量 -> 目标变量
### 原始终点 -> 目标终点
### 原始验证 -> 目标验证
### 原始图表逻辑 -> 目标图表方案
## 输出
### 研究思路迁移报告
### 新 Codex Skill
### 图表证据链
### 方法适配检查清单
15. 适合的论文类型
比较适合:
- 生信分析论文;
- 单细胞论文;
- 空间转录组论文;
- 多组学论文;
- 临床预测模型论文;
- 机制实验论文;
- 干预研究论文;
- 算法或方法学论文。
不太适合:
- 纯综述;
- 信息量很少的短文;
- 方法部分过于简略的论文;
- 扫描版且无法 OCR 的 PDF;
- 没有清晰研究设计或验证链条的文章。
16. 安全和版权建议
使用时建议注意:
- 不要把未公开论文 PDF 上传到公开仓库;
- 不要把受版权保护的全文抽取结果提交到 GitHub;
- 生成 Skill 时尽量保留结构化总结,不要复制论文长段原文;
- 如果论文来自合作课题或内部资料,应遵守数据和文献使用约定;
- 公开分享时,建议只分享工具代码、模板和使用方法。
17. 项目地址
GitHub:
https://github.com/T-Zevin/pdf-to-skill
如果你也经常遇到这种情况:
读了一篇好文章,
但是过几天只记得结论,
忘了它真正厉害的研究设计。
可以试试这个项目。
它的目标很简单:
把一篇好论文,变成一个可复用的研究思路模板。
总结
pdf-to-skill 想解决的问题是:
不要只让 AI 帮我们总结论文,
而是让 AI 帮我们沉淀论文背后的研究方法。
一篇论文真正值得学习的地方,往往不只是结论,而是:
怎么提出问题
怎么搭建证据链
怎么安排图表
怎么做验证
怎么控制风险
怎么把方法迁移到新方向
如果这些结构能被保存成一个 Skill,后续做课题设计、论文构思、图表规划和方法迁移时,就可以反复调用。
项目地址:
https://github.com/T-Zevin/pdf-to-skill
欢迎 star、试用、提 issue,也欢迎一起把它改得更适合科研工作流。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)