NVIDIA Vera CPU 首批交付:从基准测试看 CPU 在 AI 时代的角色变化
Vera 来了。不是纸面发布,是实打实交付到了客户机房。
2026年5月,NVIDIA 向 Anthropic、OpenAI、SpaceX AI 和 OCI 交付了首批 Vera 系统。同期,Phoronix 受邀在 NVIDIA 实验室跑完了一组基准测试。成绩单很好看,但我们更关心的问题是:这组数字背后,反映了 CPU 在 AI 基础设施里正在发生什么变化?以及企业现在该怎么看这件事?
先看懂 Vera 是一颗什么样的 CPU
在进入基准测试之前,有必要用几句话说清楚 Vera 的架构底子,因为这直接决定了它擅长什么、不擅长什么。
Vera 是 NVIDIA 第一颗独立推向市场的服务器 CPU。上一代 Grace 是跟着 GPU 一起卖的配套组件,Vera 不再依附于任何加速器,它可以单独出现在服务器里。这种产品定位的变化本身就说明一个问题:NVIDIA 认为 CPU 在 AI 链路里已经有了独立的、不可替代的价值。
核心部分,88个 Olympus 核心,NVIDIA 自己设计的微架构,不再像 Grace 那样用 Arm 公版 Neoverse V2。IPC(每时钟周期执行的指令数)比上一代提升了 1.5 倍。L2 缓存翻倍到每核 2MB,共享 L3 缓存 164MB。所有这些核心在一个硅片上,通过一致性互联总线连成一个统一的内存域——没有跨 die 的 NUMA 问题,这是跟当前 x86 多 die 拼装路线在架构思路上最根本的区别。
内存是另一个关键。Vera 用 LPDDR5X 内存模块,聚合带宽 1.2 TB/s,最高支持 1.5 TB 容量。作为对比,当前 x86 旗舰处理器的内存带宽大概在 460 GB/s 左右,Vera 是它们的 2.6 倍。整板功耗约 500W,已经包含了 CPU 和内存,同级别的 x86 平台在算上内存之后通常要再多出几十瓦。
一句话概括 Vera 的架构逻辑:一个没有内部割裂的大内存域,配上高带宽低功耗的内存,核心设计足够宽而非一味冲高频率。这套思路跟谁做 CPU 无关,跟要跑什么负载有关。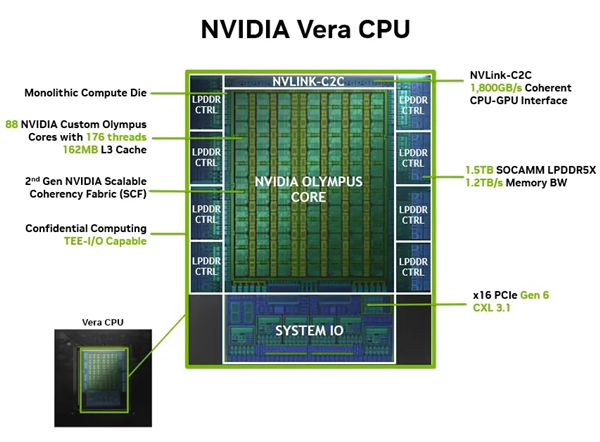
基准测试:数字不错,但业务故事更有意思
Phoronix 这次用的是预量产版 Vera,测试范围由 NVIDIA 指定,集中在计算密集型场景。当前数据反映的是目标负载下的性能上限,全面评测要等量产版。在这个前提下:
●对比上一代 Grace,Geometric mean 提升 63%。核心数多了 22%,但 IPC 提升 1.5 倍、内存带宽翻倍到 1.2 TB/s,三者叠加的效果是代际之间跳了一大步。
●对比 AMD EPYC 9575F,整体领先大约 10%。需要说明的是,9575F 是 64 核高频型号,不是 AMD 核数最多的 SKU。128 核 Zen 5c 没参加这次对比,所以在高度并行的批处理场景里,差距可能更小。
●对比 Intel Xeon 6980P(128 核),领先约 55%。用更少的核心数实现这个差距,主要归功于两样东西:内存带宽和单 die 低延迟。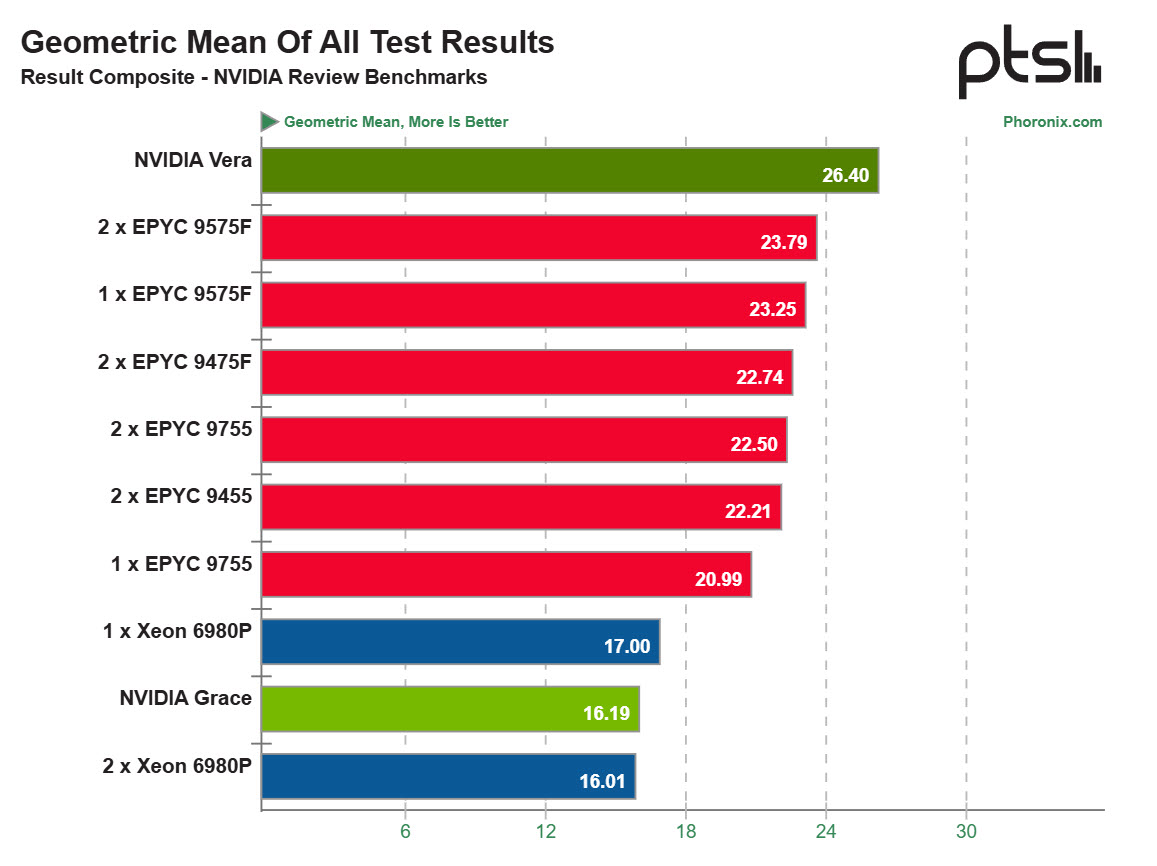
这些总分值得一看,但真正对企业有参考价值的,是把几个单项测试拆开,看看它们对应什么样的真实业务行为。
先说 7-Zip 压缩测试。Vera 单核压缩性能比参测的所有 x86 处理器高出约 20%。压缩这个动作,本质上是在密集地做分支判断和缓存读写。它和 AI 推理链路里的很多轻量操作是一类东西:JSON 解析、请求参数的序列化和反序列化、规则引擎的模式匹配。这些活儿不重,但量极大、频率极高,对 CPU 的分支预测和缓存设计敏感。Vera 在这类负载上的表现,说明 Olympus 核心在设计时就没打算走“堆高频、靠蛮力”的路线,而是在预测精度和缓存命中率上下了功夫。
再看流处理这边。Redpanda ring-shuffle 测试里,Vera 的跨核吞吐量比 AMD EPYC Turin 高出 73%。更值得关注的是扩展曲线:Vera 超过 64 核之后吞吐量还在线性往上走,而 x86 平台差不多在 32 核附近就开始放平。为什么会这样?因为流处理的瓶颈往往不在核心本身,而在内存带宽。当大量核心同时读写数据时,内存墙先撞上,加再多核心也无济于事。Vera 那条陡峭的扩展曲线,核心解释变量就是 1.2 TB/s 的带宽。
把这个现象投射到业务上。Agentic AI 推理是一类很有代表性的“高并发小任务”场景:一次用户请求进来,模型决定调用三个工具、执行两段沙箱代码、检索五个文档片段。这些 CPU 侧的微任务全部并行执行,每个都轻量,但总量惊人。传统架构下,这种负载会导致 CPU 核心之间的性能干扰,尾延迟飘忽不定。Vera 的扩展特性意味着它可以同时处理更多这类微任务,彼此之间保持一定的性能隔离——这正是企业部署 Agentic 应用时最头疼的问题之一。
编码和数据库相关测试也有看点。AV1 编码性能跟 EPYC Turin 基本持平,明显优于 Xeon。早期 NVIDIA 认可的 SQL 测试里,Vera 的复杂查询延迟优于 EPYC 9005 和 Xeon 6。结合 1.2 TB/s 内存带宽,一个很自然的应用方向是向量检索:把更大的向量索引直接放在 CPU 内存里,查询时少走几趟远端存储,QPS 就能往上提。这对已经重度使用向量数据库和 RAG 管线的团队来说,是一个直接可量化的收益点。
CPU 在 AI 里的角色,正在被重新定义
基准测试讲完,我们退一步看一个更大的问题:为什么是现在?NVIDIA 推一颗独立 CPU 这件事,如果放在三年前会觉得奇怪,但放在 2026 年,逻辑是顺的。
过去很长一段时间,AI 基础设施的叙事中心是 GPU。CPU 做什么?数据搬运、请求分发、轻量预处理,说难听点就是给 GPU 打下手。这个定位决定了 CPU 只要“够用就行”,不需要多强。
但 Agentic AI 改变了这件事。当一个模型不再只是“输入文本、输出文本”,而是开始调用工具、执行代码、检索记忆、多步推理,CPU 的工作内容发生了根本变化。它不再是一个简单的调度员,而是变成了执行引擎:真正去跑用户定义的函数、管理沙箱的安全边界、在毫秒级完成上下文检索。这些任务的共同特征是并发度高、延迟敏感、分支密集——恰好是传统 CPU 架构没有专门优化过的东西。
这就是 Vera 出现的逻辑。它不是在跟 x86 争“谁是一颗更好的通用 CPU”,而是在回答一个特定的问题:如果 CPU 的角色从配角变成执行主力,架构应该怎么设计?单 die 消除 NUMA、1.2 TB/s 内存带宽、空间多线程而不是简单的超线程——这些设计选择,每一项都是对这个问题的回答。
对企业来说,这带来的启发是:评估 CPU 的标准需要更新了。过去选 CPU 看的是 SPEC 分数、核心数、主频。现在做 AI 基础设施规划,还要看 CPU 在 Agentic 链路里的实际表现、内存带宽能否撑住高并发检索、CPU 与 GPU 之间的数据通路有多宽。
企业现在该关注什么
不需要一个密密麻麻的评估表。根据近期跟企业技术团队的交流,当下真正值得花时间的是三件事。
第一,判断你的负载跟 Vera 的对齐程度。 最直接的检查方法:你们 AI 请求的全链路耗时里,CPU 侧处理占了多大比例?如果超过三成,而且大量时间花在工具调用、数据序列化、向量检索这些动作上,Vera 的架构优势就可能转化为实际收益。如果 CPU 侧主要是简单的请求转发和轻量预处理,现有 x86 方案大概率还够用。
第二,软件生态的适配成本要提前估算。 Vera 的基础软件栈已经就位——主流 Linux 发行版、编译工具链、PyTorch 等框架在 ARM64 上都很成熟。真正的卡点是你们自己的软件栈:内部工具链、特定 ISV 应用、合规要求绑定的操作系统版本。拉一份清单,逐项确认 ARM64 的支持状态,这比看任何基准测试都更实际。
第三,时间窗口上不用急。 量产版预计 2026 年 Q3 开始规模交付。在此之前,关注 Computex 2026 的正式发布,等待独立第三方对量产硬件的评测。Q4 前后采购少量节点跑 PoC,用自己业务里的真实负载来验证,而不是拿公开基准测试的结果推导结论。2027 年再根据 PoC 数据做规模化采购决策。
另外有一个观察值得关注。从我们看到的早期企业部署动作来看,一个比较务实的路径是“异构过渡”:不在现有管线里全面替换 x86 节点,而是先把向量检索、数据预处理、沙箱执行这几类 CPU 密集的微服务迁移到 Vera 上跑。管理面和传统应用层继续留在 x86 上,两条线并行。这样做的好处是风险可控,同时也能逐步积累 ARM 运维经验,为后续可能的全栈迁移做准备。
常见问题FAQ
ARM 服务器现在靠谱吗?
其实已经不是“能不能用”的问题了。AWS Graviton 已经证明 ARM 可以稳定跑大规模数据中心。真正的问题是:你的软件栈,是不是已经准备好 ARM64 了?
Vera 能用来跑 DeepSeek、Qwen 这类本地大模型吗?
Vera 是一颗 CPU,不是 GPU 加速器。它不会直接承载大模型的 Transformer 推理计算,但大模型推理不是只有矩阵乘法。一次完整的推理请求,前面有提示词处理、上下文拼接,中间可能触发检索增强,后面还有输出解析和后处理。这些环节全都跑在 CPU 上。Vera 在这些地方能产生直接帮助——更快的预处理、更低的检索延迟、更多并发工具调用。
Vera 会影响我们采购 AI 服务器的方式吗?
如果你未来考虑引入 Vera Rubin 平台,采购逻辑会有一个变化:从“分别评估 CPU 服务器和 GPU 服务器、通过网络连起来”变成“评估一个融合机柜的整体能力”。好处是性能一致性更强,省掉了中间的数据搬运损耗。代价是切换成本变高,也更容易被平台绑定。从采购策略上,这意味着需要把机柜级的 TCO 和开发效率放进评估框架,而不只是对比单台服务器的配置和单价。
现在看 Vera 还是等 AMD Zen 6?
如果你们的业务属于 Agentic AI、流处理、向量检索等 Vera 优势场景,且部署时间计划在 2027 年,现在启动跟踪评估刚好。如果负载偏通用,采购可以推到 2027 年下半年,那么同时等 Zen 6 的评测是更理性的选择。核心原则是保持弹性,不要让任何单一选项提前锁定决策。保持弹性,让未来的数据说话。
赋能科技,智创未来
Vera 的首批交付,给数据中心 CPU 市场加了一个值得认真对待的新选项。它不是一颗什么都能做的通用 CPU,但在它瞄准的那几个 AI 负载上,架构的针对性是真实存在的。对企业来说,现在需要做的不是急着下结论,而是把 Vera 放进观察列表,等量产版的独立评测出来,用自己业务的真实负载去验证。我们会在后续持续跟踪量产版评测数据和早期客户的大规模部署反馈,为决策提供可参照的事实基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)