数据结构课程虚拟实验环境平台系统
数据结构课程虚拟实验环境:可视化实验、在线代码运行与大模型辅助智能反馈
一、项目简介
本系统面向数据结构课程实验教学,采用前后端分离架构实现一个在线虚拟实验平台。学生可以在浏览器中查看实验任务、操作数据结构可视化组件、编写并运行 Java/Python/C 代码;教师可以发布实验、查看学生进度、统计成绩与常见错误。
相比传统“本地 IDE + 课后批改”的方式,系统的重点在于把“实验说明、代码编辑、沙箱执行、智能反馈、成绩统计”放到同一个闭环里。学生提交代码后,不只看到编译或运行结果,还可以得到面向错误原因的诊断建议,教师端也能沉淀班级错误画像,辅助后续教学。
二、技术栈
前端使用 Vue 3、Element Plus、Vue Router、Pinia、Monaco Editor、D3.js 和 ECharts。Monaco Editor 提供接近本地 IDE 的代码编辑体验,D3.js 用于链表、栈、队列、二叉树、图、排序等数据结构可视化,ECharts 用于教师端统计图表。
后端使用 Spring Boot 3、Spring Security、JWT、MyBatis-Plus、MySQL、Redis。代码执行模块支持进程沙箱模式,也保留 Docker 沙箱模式配置,可以限制运行时间、内存和执行环境,避免学生代码直接影响服务主进程。
三、核心功能
系统按角色划分为学生端、教师端和管理员端。学生端包括实验列表、实验详情、在线代码编辑、运行/提交、我的进度、成绩查询和学习资源;教师端包括实验管理、学生进度、成绩统计、资源管理;管理员端包括用户管理、系统日志和数据备份。
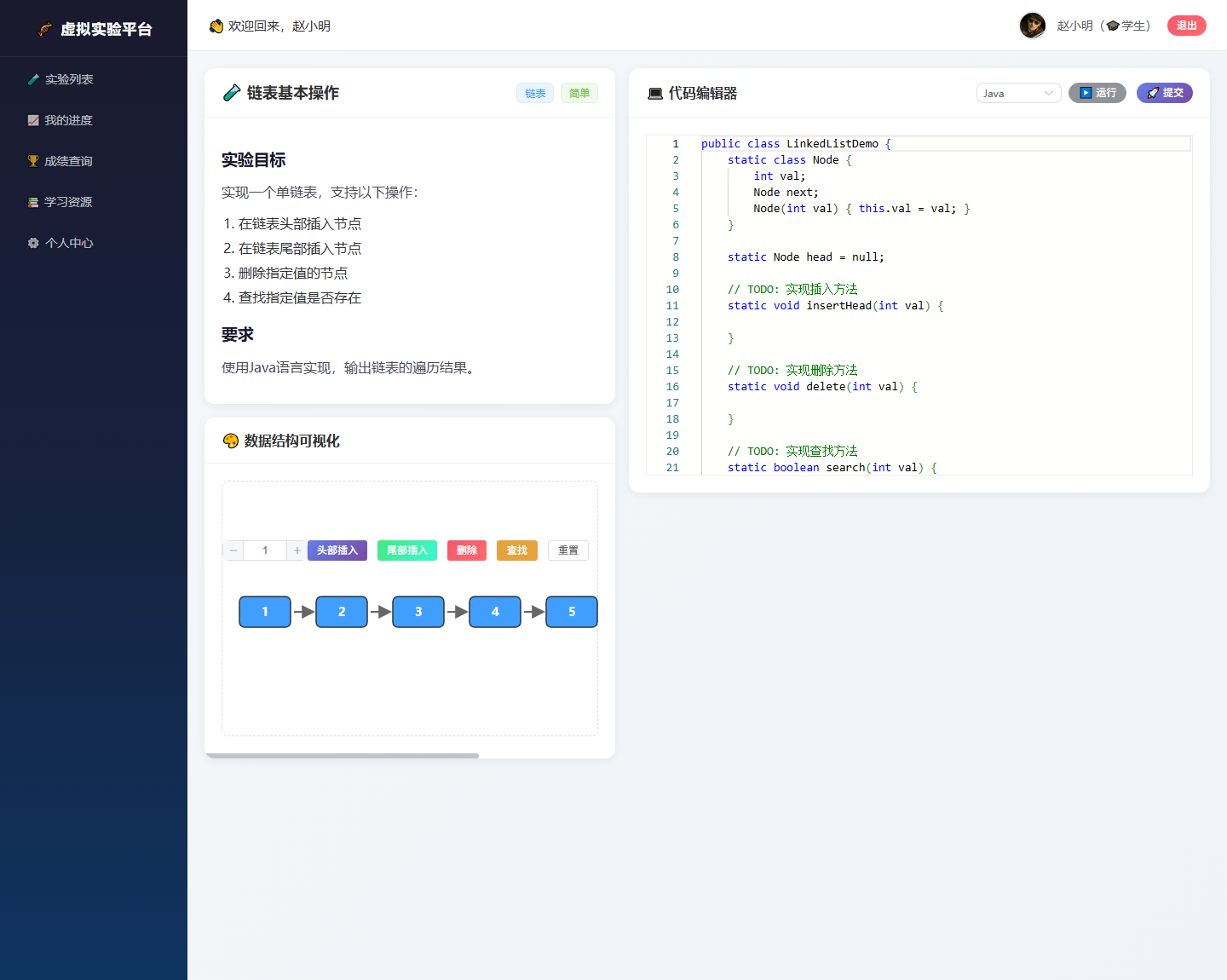
实验详情页将“任务说明 + 数据结构可视化 + 代码编辑器”组合在一个页面中,学生一边看题目,一边观察结构变化,一边调试代码。
四、大模型辅助智能反馈模块
这个系统中最值得展开的是智能反馈模块。它不是把大模型做成一个独立聊天窗口,而是嵌入到代码实验流程里:学生运行代码后,系统自动收集实验上下文、代码执行结果和错误信息,再生成结构化反馈。
智能反馈的输入主要包括:
- 实验信息:实验标题、数据结构类别、难度、实验目标、期望输出。
- 学生代码:当前编辑器中的完整代码。
- 执行结果:编译错误、运行异常、输出内容、执行时间、内存使用。
- 错误上下文:异常类型、错误行号、堆栈信息、期望输出与实际输出差异。
反馈输出则保持结构化,便于前端直接展示:
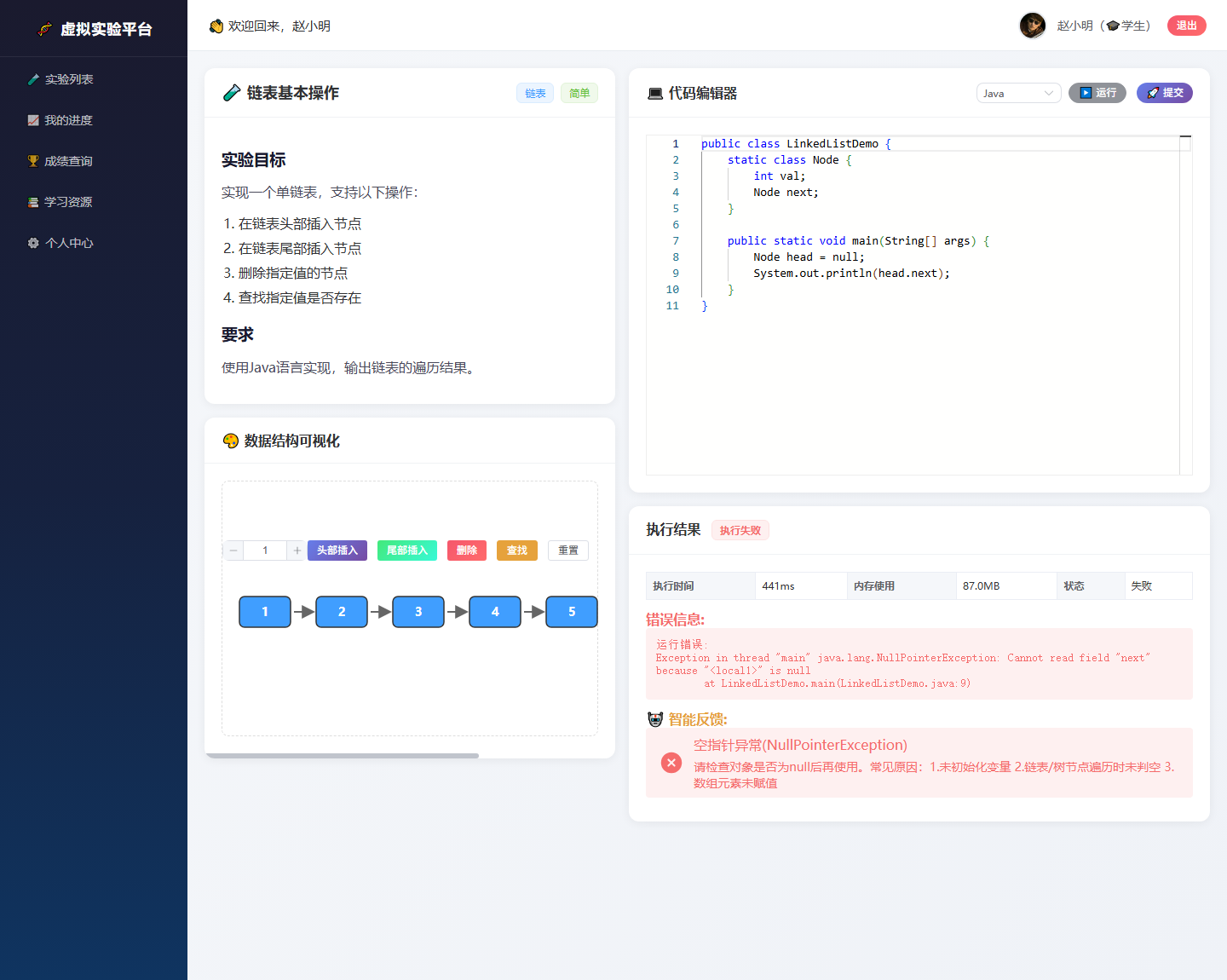
{
"type": "ERROR",
"message": "空指针异常(NullPointerException)",
"lineNumber": 9,
"suggestion": "请检查对象是否为 null 后再使用,链表或树节点遍历时尤其需要先判空。"
}
从产品体验上看,学生不需要自己从长堆栈里筛选关键信息。系统会把异常类型、错误原因和修改方向整理成更适合初学者阅读的提示,例如空指针、数组越界、栈溢出、死循环/超时、编译错误等。
五、智能反馈流程设计
智能反馈模块的处理链路如下:
- 学生点击“运行”或“提交”。
- 后端根据语言类型选择 Java、Python 或 C 的执行流程。
- 沙箱编译并运行代码,记录标准输出、错误输出、运行耗时和内存使用。
- 如果执行成功,则对比期望输出,判断是否通过。
- 如果执行失败,则进入错误分析流程,识别异常类型并生成修复建议。
- 前端将执行结果、错误信息和智能反馈以卡片形式展示。
- 提交数据沉淀到数据库,供学生成绩页和教师统计页使用。
这里的设计重点是“即时性”和“教学语境”。普通编译器只告诉学生程序错在哪里,但系统需要进一步解释为什么错、应该从哪个数据结构操作去排查。例如链表题出现 NullPointerException 时,反馈会引导学生检查节点是否为空、遍历时是否先判断 next、删除节点时是否处理头节点和尾节点边界。
六、为什么要把大模型能力放进实验闭环
数据结构课程的错误往往不是简单语法问题,而是和抽象结构有关。例如:
- 链表删除节点时漏掉前驱指针。
- 二叉搜索树插入时只处理左子树,忘记右子树。
- 递归遍历缺少终止条件导致栈溢出。
- 排序算法边界控制错误导致输出不完整。
- 图遍历没有维护 visited 集合导致重复访问或死循环。
这类问题如果只返回一段编译器错误,学生很难快速建立“错误现象”和“数据结构知识点”的联系。智能反馈模块的价值就在于把运行时错误翻译成课程语言,帮助学生从“代码报错”回到“算法思路”。
七、学生端学习分析
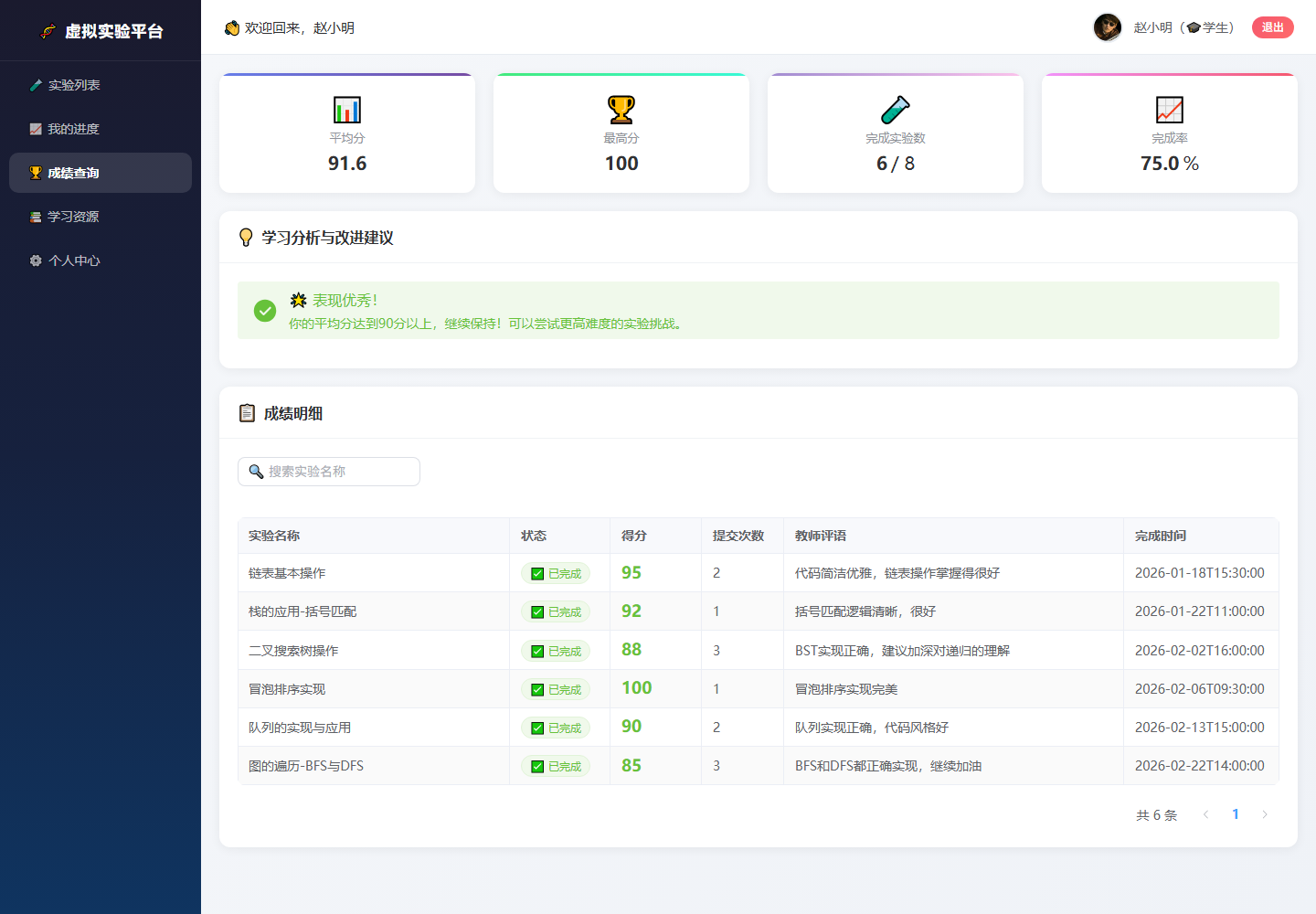
学生完成实验后,可以在成绩查询页看到平均分、最高分、完成实验数、完成率以及每个实验的成绩明细。系统会根据成绩表现给出学习建议,帮助学生判断当前是继续挑战高难度实验,还是回到学习资源补基础。
八、教师端错误统计
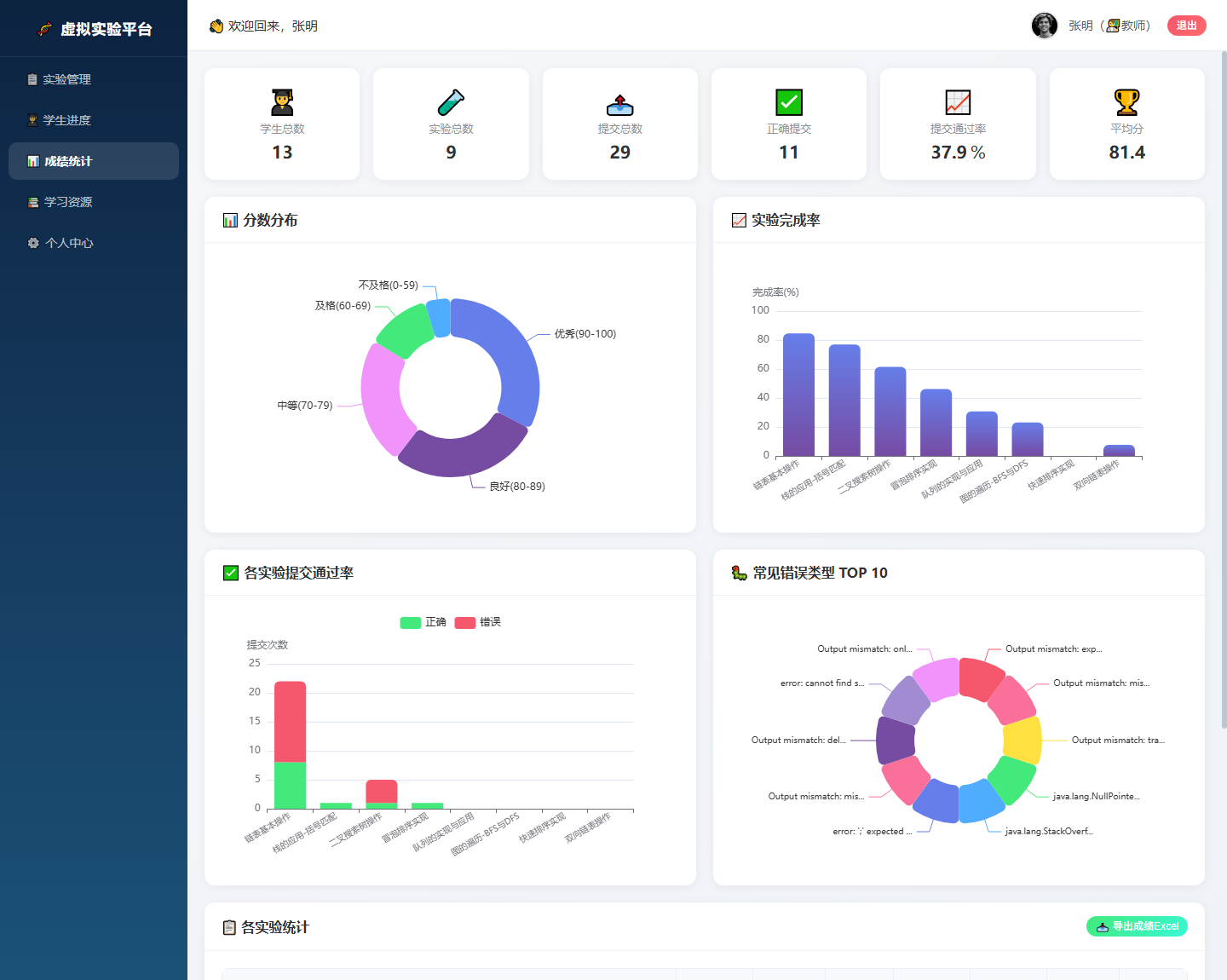
教师端的统计页会聚合全班实验数据,包括学生总数、实验总数、提交总数、正确提交数、提交通过率、平均分、分数分布、实验完成率、各实验提交通过率和常见错误类型 TOP 10。
这部分和智能反馈模块形成闭环:学生端解决个体问题,教师端观察群体问题。例如某个实验的错误次数明显偏高,或者某类错误在 TOP 10 中频繁出现,教师就可以针对性补充讲解。
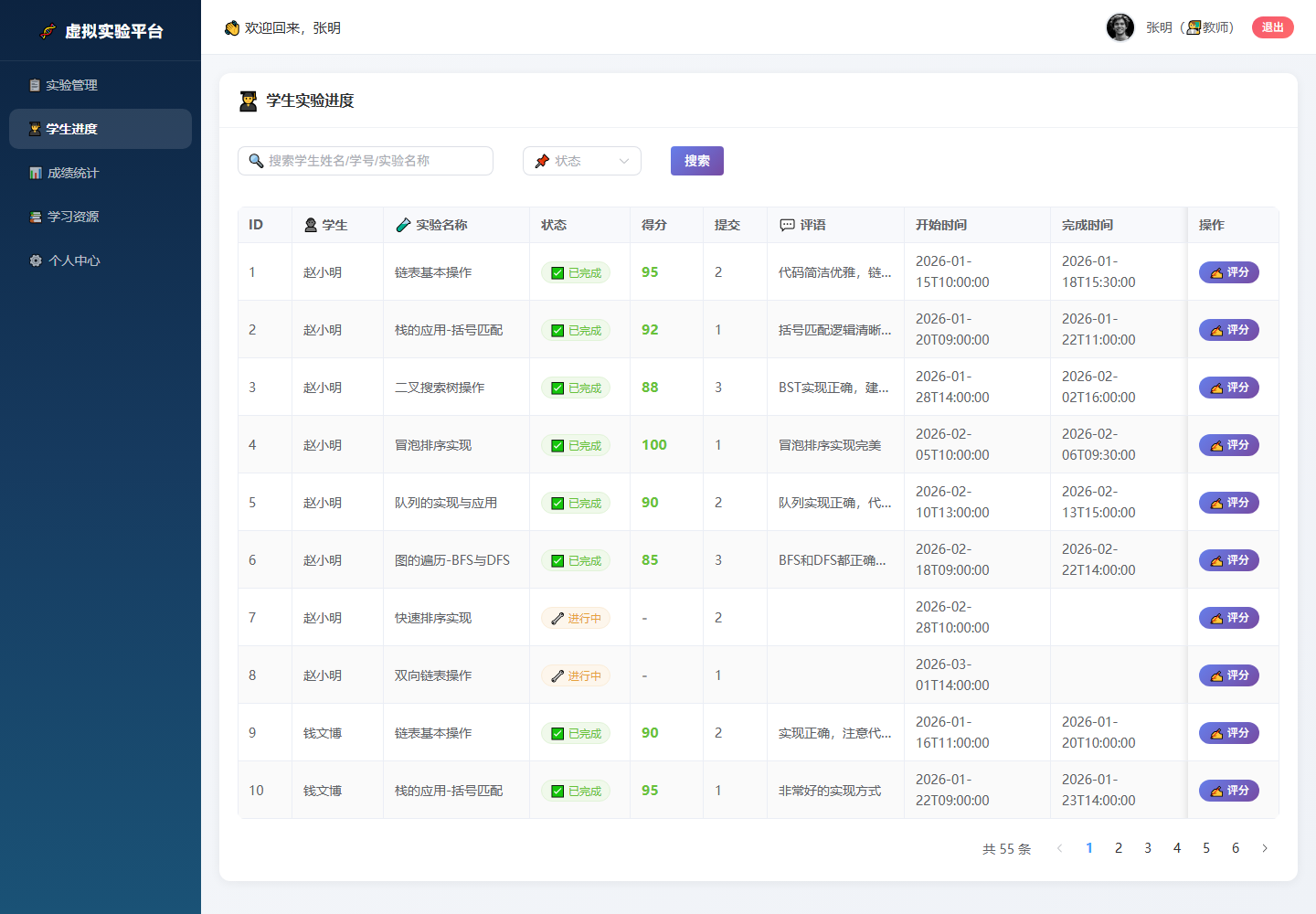
教师也可以查看学生实验进度,了解每位学生的完成状态、得分、提交次数和教师评语。
九、系统亮点总结
- 可视化与代码实验结合:学生既能观察数据结构形态,又能在编辑器里实现算法。
- 在线沙箱运行:无需本地配置 Java、Python、C 环境,浏览器中即可完成实验。
- 智能反馈及时返回:错误信息不再只是一段堆栈,而是转化为可理解的修改建议。
- 教学数据可沉淀:提交记录、成绩、错误类型都能用于后续分析。
- 角色权限清晰:学生练习、教师管理、管理员维护分别对应不同功能边界。
十、后续优化方向
后续可以继续增强大模型能力:将实验内容、学生代码、错误堆栈、历史提交记录一起作为上下文,调用外部大模型生成更细粒度的诊断建议;也可以让模型输出“提示级别”分层反馈,先给思路提示,再给关键代码修改方向,避免学生直接复制答案。
此外,还可以把教师端常见错误统计和大模型结合起来,自动生成课堂讲解建议,例如“本周链表删除操作错误集中在非头节点删除和空指针判断,可以增加边界案例演示”。
整体来看,这套数据结构虚拟实验环境不仅解决了在线实验和教学管理问题,也为大模型辅助编程教学提供了一个比较完整的落地点。
十一、联系我们获取更多资料


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)