RAG大模型学习指南:收藏这份信息处理流水线详解,小白也能轻松入门!
很多人第一次了解 RAG,会觉得它的概念并不复杂: “先检索资料,再让大模型回答。”
但一旦进入工程实现,就会发现真正的 RAG 系统远不止一句话那么简单。
它通常包含两条主线:
- 一条是 离线的数据准备链路
- 一条是 在线的问答处理链路
只有这两条链路都打通,RAG 才能真正跑起来。
一、先理解一个核心结论
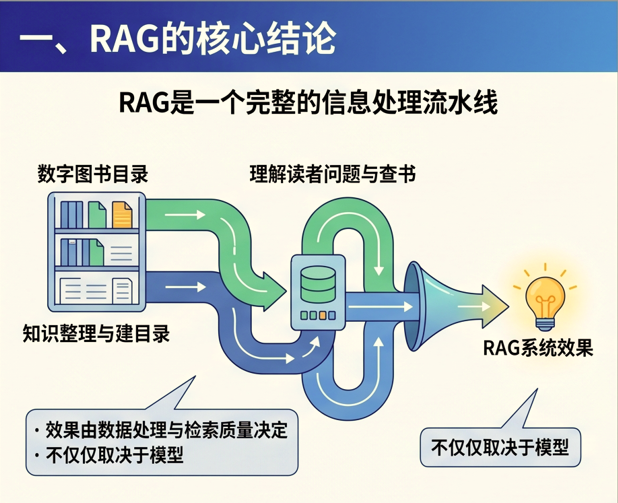
RAG 不是一个单点能力, 它更像是一条完整的“信息处理流水线”。
如果把它类比成图书馆系统,那么:
- 离线阶段是在“整理图书、建目录、编索引”
- 在线阶段是在“理解读者问题、查书、给出答案”
也就是说,RAG 的效果,不只是由模型决定,更由前面的数据处理与检索质量决定。
二、第一条主线:离线数据准备
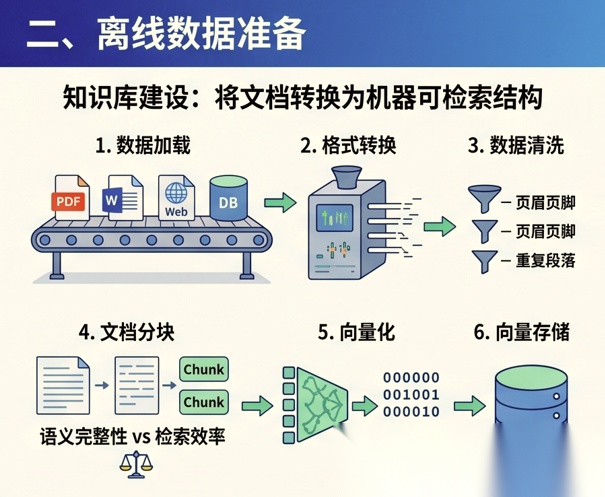
离线阶段可以理解为“知识库建设”。
它主要做的事情,是把原始文档变成机器可以高效检索的结构。
1. 数据加载
企业里的知识来源通常非常杂:
- Word
- Excel
- 网页
- 邮件
- 数据库记录
这些数据格式不同、结构不同,不能直接拿来给模型使用。 第一步就是把它们统一读取出来。
2. 格式转换
文档读进来以后,系统要把内容尽量转成可处理的文本。
比如:
- PDF 要做文本解析
- 表格内容可能要转成文字描述
- 网页要去掉广告、脚本、无关导航内容
这一步的目标不是“完整保留一切形式”, 而是尽可能保留 有效信息和原始结构。
3. 数据清洗
原始资料里往往带有大量噪声:
- 页眉页脚
- 重复段落
- 乱码
- 特殊符号
- 无关声明
如果这些内容直接进入知识库,后面的检索质量会明显下降。 所以清洗是必须做的基础工程。
4. 文档分块
这是 RAG 里最关键的一步之一。
因为大模型和检索系统都不适合直接处理超长全文, 所以需要把文档切成更小的片段,也就是我们常说的 Chunk。
分块时要解决两个矛盾:
- 块太小,语义可能不完整
- 块太大,噪声会增加,还可能超出模型上下文限制
因此,分块本质上是在平衡 语义完整性 和 检索效率。
5. 向量化
切好的文本块,需要进一步转换成向量表示。 这个过程由 Embedding 模型完成。
为什么一定要向量化? 因为计算机并不真正理解“文字意思”,但它可以在向量空间里比较“语义距离”。
这一步完成后,系统才能支持“语义检索”。
6. 向量存储
最后,这些向量会被写入向量数据库,并建立相似度索引。 这样,当用户提问时,系统才能快速找到最相关的内容片段。
这就完成了离线建库阶段。
三、第二条主线:在线问答处理
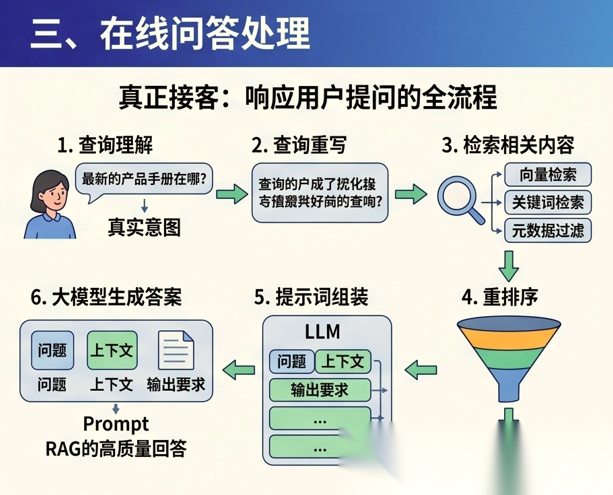
如果说离线阶段是在“备货”, 那么在线阶段就是“真正接客”。
当用户发来一个问题时,RAG 系统通常会按下面的流程运行。
1. 查询理解
用户的问题不一定表达得很标准。 系统需要先理解他的真实意图。
比如用户说:
“最新的产品手册在哪?” 或者 “我想看新版说明书。”
这两句话表达不同,但需求可能是一样的。
2. 查询重写
理解完问题后,系统通常还会做一次“检索友好化”。
比如:
- 扩展同义词
- 补全关键词
- 纠正常见拼写错误
- 把自然语言转成更适合检索的形式
这一环节做得好,召回率会明显提升。
3. 检索相关内容
接下来,系统会从向量数据库中检索与问题最相关的文档块。 成熟系统往往不会只用一种方式,而是结合:
- 向量检索
- 关键词检索
- 元数据过滤
这样做的目的,是兼顾语义理解和精确匹配。
4. 重排序
初步检索出来的结果,不一定真正最适合回答问题。 所以系统还会做一次重排序,把最相关、最有用的内容排到前面。
你可以把它理解为:
第一次检索是“广泛找资料”, 第二次重排是“挑出最值得给模型看的资料”。
5. 提示词组装
找到资料后,并不是直接扔给模型就结束了。 系统还要把:
- 用户问题
- 检索到的上下文
- 输出要求
一起拼成一个结构清晰的 Prompt。
Prompt 设计得越规范,模型越容易按要求作答。
6. 大模型生成答案
最后一步,才轮到大模型真正出场。
这时它不是“空手回答”, 而是带着检索到的上下文去生成答案。
所以 RAG 的高质量回答,本质上是:
检索能力 + 上下文组织能力 + 模型生成能力 的共同结果。
四、为什么很多 RAG 项目效果一般
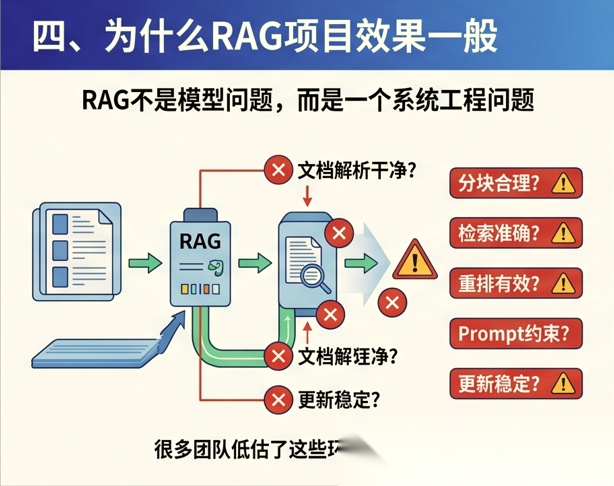
很多团队以为只要“文档入库 + 向量检索 + 调用模型”就能得到一个好系统。 但现实往往不是这样。
因为 RAG 真正难的地方在于:
- 文档解析是否干净
- 分块是否合理
- 检索是否准确
- 重排是否有效
- Prompt 是否能约束模型
- 更新机制是否稳定
换句话说,RAG 不是一个模型问题,而是一个系统工程问题。
五、用一个例子把流程串起来
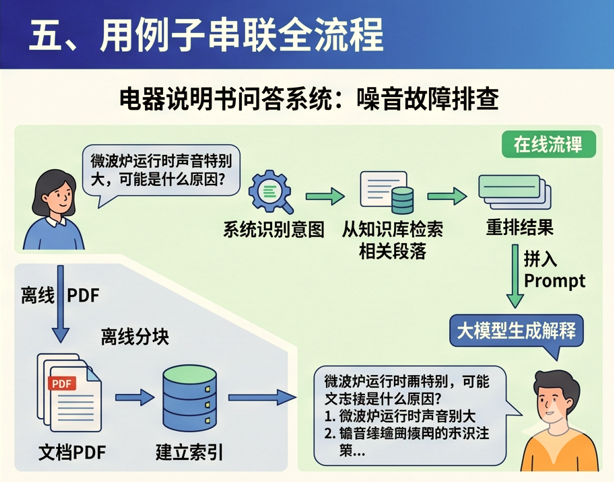
假设你要做一个“电器说明书问答系统”。
用户问:
“微波炉运行时声音特别大,可能是什么原因?”
一个完整的 RAG 系统会怎么做?
第一步,先在离线阶段把说明书 PDF 解析出来,按章节分块并建立索引。 第二步,用户提问后,系统识别“声音大”“故障”“排查”这些意图。 第三步,从知识库中检索出“噪音问题”“异常运行”“故障排除”等相关段落。 第四步,对结果重排,挑出最可能回答问题的片段。 第五步,把这些片段和用户问题拼进 Prompt。 第六步,由大模型生成一段自然语言回答。
最终用户看到的不是“说明书第 47 页、第 89 页”, 而是一段读得懂、可执行的解释。
这就是 RAG 在真实业务中的价值。
结语
–
RAG 的全链路并不神秘, 但它绝不是“加一个向量库”那么简单。
真正有效的 RAG,背后一定包含两件事:
- 离线阶段把知识整理好
- 在线阶段把问题处理好
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献69条内容
已为社区贡献69条内容

所有评论(0)