世界动作模型(WAM):让机器人学会“先想象,再行动“的下一代具身大脑
人工智能的浪潮在过去几年以前所未有的速度重塑着世界。大语言模型让机器拥有了"读万卷书"的语言智慧,多模态模型让它学会了"看图说话"。然而,当我们把目光从屏幕里的对话框移向真实的物理世界时,一个根本性的难题浮现出来:一个能写诗、能编程的模型,却未必能稳稳地端起一杯水。让机器人在非结构化的真实环境中感知、推理并行动,始终是通用人工智能(AGI)皇冠上那颗最难摘取的明珠。
近两年,视觉-语言-动作模型(Vision-Language-Action, VLA) 的崛起一度让人看到了曙光:把预训练好的视觉-语言大模型直接"改装"成机器人策略,让它像预测下一个词一样预测下一个动作。RT-2、OpenVLA、π₀ 等工作展示了惊艳的泛化能力——听懂新指令、操作没见过的物体、在不同机器人本体间迁移。但 VLA 有一个与生俱来的"阿喀琉斯之踵":它只学会了从"看到什么"到"做什么"的反应式映射,却从不思考"我这么做了,世界会变成什么样"。
正是为了补上这块拼图,一个新范式正在快速成形。复旦大学、上海创新研究院与新加坡国立大学的研究者们在最新综述中,首次系统性地为这一族方法立名——世界动作模型(World Action Models, WAM)。本文将带你完整梳理这篇综述的核心脉络:WAM 到底是什么、它有哪几种"长相"、用什么数据喂养、如何评判优劣,以及它通往通用具身智能的道路上还横亘着哪些难关。
一、从 VLA 到 WAM:为什么机器人需要"想象力"

VLA 的辉煌与局限
要理解 WAM,必须先理解它要解决的痛点。VLA 模型的本质,是把机器人控制建模为一个多模态序列预测问题。给定当前观测 o 和语言指令 l,模型直接输出动作序列 a,其学习目标可以朴素地写成"在给定上下文下,让正确动作的概率最大"。这套范式继承了大模型的全部红利:海量预训练带来的语义理解,被成功"落地"到了电机指令上。
然而,VLA 学习的是一个直接映射 p(a|o),它的世界里没有"未来"。它不预测"我推这个杯子,杯子会滑到哪里"“我抓这块布,布会怎样褶皱”。这种预测性物理推理的缺失,使得 VLA 在需要预判后果的复杂任务上举步维艰——尤其是在分布外场景、长程任务和富接触操作中,表现往往脆弱。
世界模型:给智能体装上"物理直觉"
与 VLA 互补的,是另一条技术脉络——世界模型(World Model, WM)。它的角色是充当环境的"前向动力学模拟器":给定当前状态 o 和一个假想动作 a,预测出下一个状态 o',即建模 p(o'|o, a)。从经典的基于模型的强化学习(如 PlaNet、Dreamer 系列),到如今由 Sora、Wan 等视频生成大模型驱动的"视频世界模型",世界模型让智能体得以在"脑海中"推演世界的演化。
一个很自然的想法呼之欲出:如果把世界模型的"预见能力"和 VLA 的"行动能力"融为一体,会怎样?
WAM 的定义:联合建模"未来"与"动作"
这正是 WAM 的核心思想。综述给出了一个清晰的形式化定义:WAM 是一类将预测性状态建模(世界建模)与运动控制(动作生成)相统一的具身基础模型,它的目标不再是单独建模动作,而是去刻画未来状态与动作的联合分布:
WAM 的学习目标:
p(o', a | o, l)——在给定当前观测与指令下,同时预测"世界会变成什么样"和"我该怎么做"。
综述进一步明确,一个合格的 WAM 必须满足两条核心标准:
- 前向预测建模:模型必须生成或利用一种可量化的未来状态
o'表征。这既可以是显式的视觉预测(像素级视频帧、稠密光流),也可以是隐式的物理表征(以物理为基础的潜在空间)。 - 耦合式动作生成:模型必须把它的动作指令
a与所预期的未来状态o'严格对齐。换言之,动作不是凭空生成的,而是"看着想象中的未来"做出的决策。
正是这一步从"映射"到"联合预测"的跨越,让 WAM 得以利用丰富的时空先验,实现更深层的物理理解和更强的零样本泛化。
正本清源:WAM 与几个近义词的辨析
新范式诞生之初,命名往往是混乱的。综述特意厘清了几组容易混淆的概念,这对入门者尤为重要:
- 视频-动作模型(VAM):通常特指"用视频预测来对齐动作"的模型。而 WAM 是一个更广、与模态无关的超集——视频只是建模世界的"一种代理",WAM 还可以用点云、触觉、力反馈等作为预测目标。"World"强调的是对物理规律与因果动力学的内化,而非对像素视频格式的执着。
- 视频策略(Video Policy):指那些借用视频生成架构(如 Diffusion Transformer)作主干、却仍然只做
p(a|o)直接映射的模型。它们没有"主动的预测承诺"——而 WAM 必须由一个世界建模目标显式监督。 - 动作世界模型(AWM):早期用语。综述选用"WAM"而非"AWM",是一次微妙的定位转变——把系统从"被增强的模拟器"重新定位为"一个完整的智能体类别",让"世界"(预测性物理)与"动作"(运动控制)成为同等地位的组成部分,确立 WAM 作为 VLA 谱系的"直接继承者"身份。
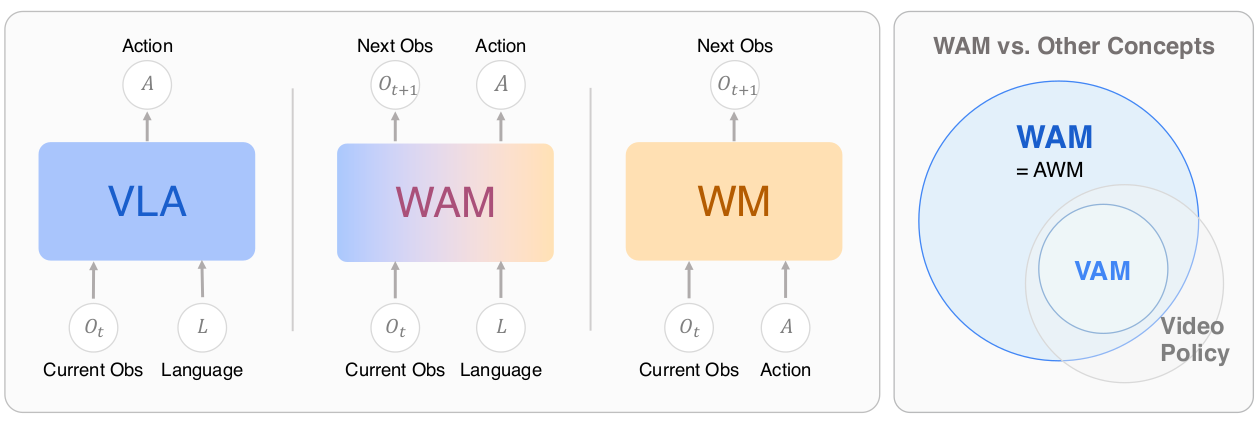
图 1:WAM 与 VLA、WM 的输入输出对比——VLA 输入观测与语言、只输出动作;WM 输入观测与动作、只输出下一观测;而 WAM 同时输出动作与未来观测,这正是它的独特之处。
二、WAM 的两大架构范式:级联式 vs 联合式
WAM 的方法图景虽然繁杂,但综述用一条清晰的主轴把它们归为两大范式:世界预测与动作生成"如何耦合"。
级联式 WAM(Cascaded):先预测未来,再解码动作
级联式的思路最为直观,它把目标显式分解为两步流水线:p(o', a|o, l) = p(a|o', o, l) · p(o'|o, l)。第一阶段,一个世界模型先"画出"预期的未来(通常是一段执行视频或潜在表征);第二阶段,一个独立的动作模型再从这段"剧本"里解码出可执行的机器人指令。
这种解耦带来了天然的归纳偏置:世界模型无需操心机器人的运动学,动作模型也无需求解长程的场景预测。按中间表征的不同,它又分两支:
- 基于像素空间的显式规划:直接用 RGB 视频帧作为中间载体,可解释性强,还能充分调用互联网规模预训练的视频大模型。其中又分为两种动作提取路线——一是学习式动作提取,用逆动力学模型(IDM)从相邻帧回归动作(如开创性的 UniPi,以及 VLP、RoboEnvision、TesserAct、Vidar、Gen2Act、π₀.₇ 等);二是几何式动作提取,把动作提取从"学习问题"变成"解析几何问题",通过光流(AVDC、Im2Flow2Act、3DFlowAction)或物体位姿跟踪(Dreamitate、RIGVid)来反推动作,很多甚至无需动作标注、零训练即可运行。
- 基于潜在表征的隐式规划:像素级视频合成太慢,是实时部署的最大瓶颈。这一支干脆跳过"解码回像素"这一步,直接在压缩的潜在空间里做规划。VPP 首次让规划推理速度逼近实时控制;S-VAM 用自蒸馏弥合效率与保真度的鸿沟;LAPA、villa-X 则从无标注视频中学习"潜在动作",大幅降低标注需求;MWM 用语义掩码替代 RGB 预测,在剧烈视觉扰动下依然鲁棒。
联合式 WAM(Joint):一个模型同时产出未来与动作
如果说级联式是"分工协作",联合式则是"一脑多用"。它在单一统一模型内同时预测未来世界状态和动作,二者在共享表征空间中被协同优化,迫使模型内化环境动力学与控制信号之间的因果依赖。按生成方式,它分为两条路线:
- 自回归生成:把异构变量(视觉、动作)序列化到 token 空间,用因果的、从左到右的方式逐个预测。代表作从 GR-1、GR-2(用未来视觉预测作为动作生成的"正则化器"),到 CoT-VLA(先自回归"幻想"出视觉思维链,再切换全注意力预测动作)、WorldVLA、RynnVLA-002、ℱ1(用 Transformer 混合体把动作生成重构为"以预见为引导的逆动力学问题"),再到 VLA-JEPA(彻底放弃像素生成,在抽象潜在空间里做预测对齐)。自回归的软肋在于误差累积和顺序解码的延迟。
- 基于扩散的生成:用多步去噪并行地生成未来状态和动作序列,天然适合高频闭环控制。综述按"预测流如何耦合"进一步细分:统一流架构把世界与动作变量塞进单个 DiT 主干(如 PAD、UWM 用独立噪声调度实现"一模多态"、Cosmos Policy 让单个模型同时充当策略/世界模型/价值函数、DreamZero 把推理推向 7Hz);多流架构则用多个协调的分支(视频 DiT + 动作 DiT),通过交叉注意力耦合(CoVAR、LDA-1B、DUST、Motus)、隐藏状态耦合(DiT4DiT、Fast-WAM、WAV、Act2Goal)或共享表征(UVA、PhysGen)来交换信息。
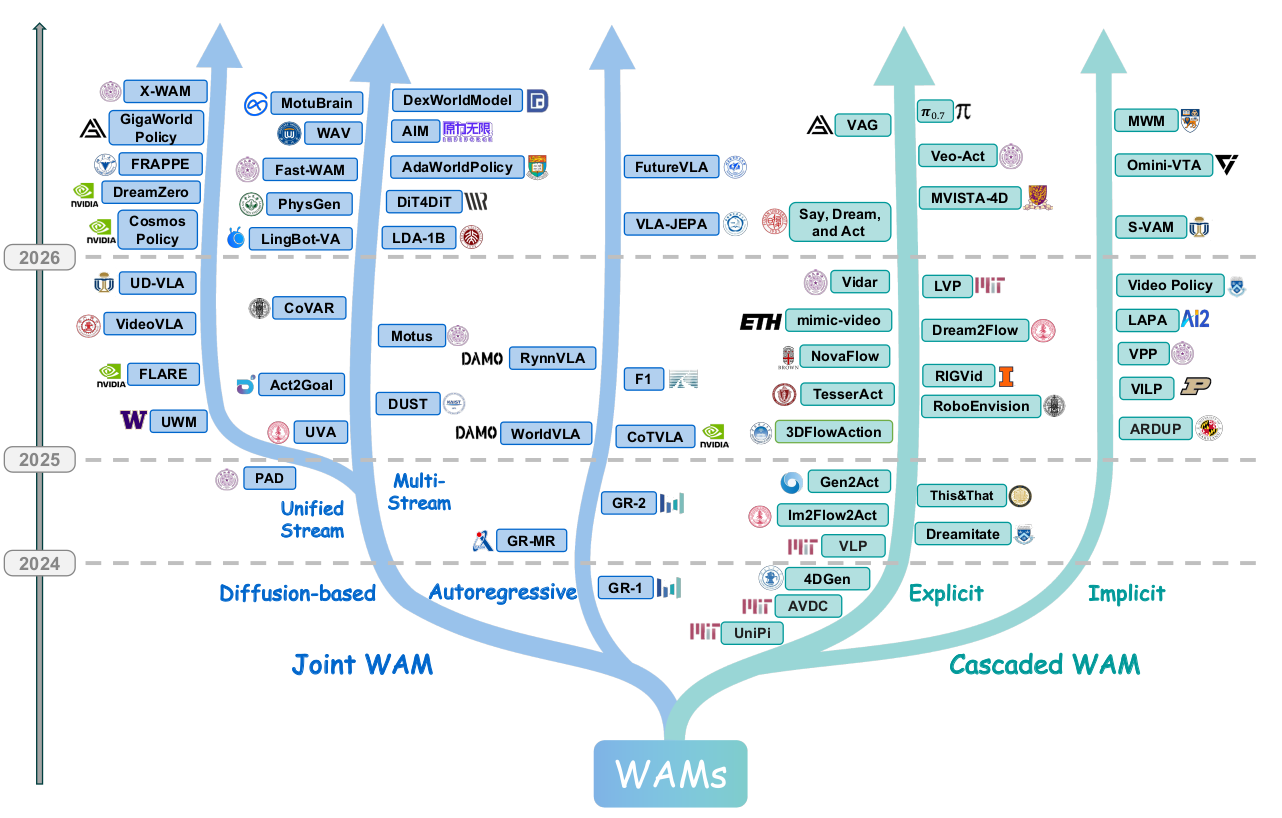
图 2:WAM 的架构分类树。左侧为联合式(自回归 / 扩散,扩散又分统一流与多流),右侧为级联式(显式 / 隐式表征对齐)。这两条主轴代表了当前领域在"架构耦合"上的主导探索方向。
一言以蔽之:级联式胜在模块清晰、可复用强大的视频大模型,但两阶段间的误差会传导;联合式胜在耦合紧密、闭环高效,但训练与架构设计更具挑战。 二者孰优孰劣,至今仍无定论——这也正是后文"开放挑战"的伏笔。
三、喂养 WAM 的"四口奶":具身数据生态
巧妇难为无米之炊。综述用一整章强调:训练鲁棒、可泛化的 WAM,从根本上受制于具身数据的可得性与质量。 与靠"被动抓取"互联网文本就能茁壮成长的大语言模型不同,WAM 需要严格的物理接地。更妙的是,WAM 有一项独门优势——它能统一消化"配对"与"非配对"两类数据:既能用高质量的 (o, a, o') 三元组紧密耦合内部表征,又能通过联合训练吸纳海量无动作标注的视频。综述将数据来源归为四大范式:
- 以机器人为中心的遥操作数据:由人类操作员遥控真机采集,提供严格对齐、高频的"动作-状态"配对,几乎没有仿真-现实差距,是不可替代的"黄金数据"。从 QT-Opt、RT-1,到聚合超百万条轨迹的 Open-X Embodiment(OXE)、野外采集的 DROID,再到百万级的 AgiBot World,规模与本体多样性不断突破。缺点是采集昂贵、受限于实验室、本体单一。
- 便携式人类演示数据(UMI 式):用轻便的手持夹爪加可穿戴相机,让普通人在真实环境里直接采集操作轨迹。UMI 开创了这一方向,FastUMI、RealOmin(百万规模、3000+ 家庭场景)、RDT2(约 1 万小时)等迅速扩展。它兼具第一人称视频的环境多样性与厘米级的动作约束,是连接"结构化遥操作"与"互联网视频"的关键桥梁。
- 仿真数据:物理引擎本质上就是一个精确的计算式世界模型,能提供真实数据难以企及的"特权信息"——完美深度、精确 6D 位姿、无遮挡多视角。从 MimicGen 的程序化扩增,到生成千万级抓取轨迹的 SynGrasp-1B、120 个真实厨房场景的 RoboCasa,再到面向 4D 时空建模的 TesserAct。代价是仿真-现实的视觉差距,但底层物理规律严格一致,配合域随机化可大幅降低真机微调需求。
- 人类与第一人称数据:互联网规模的人类视频蕴含近乎无限的任务、环境与物理交互多样性,是教 WAM 学会"直观物理"的海量先验库。从 SSv2、Ego4D(3600+ 小时)、HowTo100M(1.36 亿片段),到提供毫米级手物网格的 Ego-Exo4D、ARCTIC,再到面向灵巧控制、保持高保真 3D 手指跟踪的 EgoDex。最新趋势是把这些异构数据聚合成面向通用预训练的混合数据引擎。
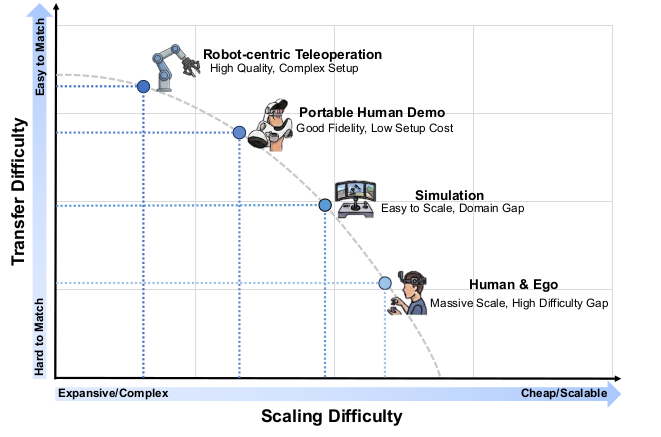
图 3:具身数据全景,按"迁移难度"(纵轴)与"扩展难度"(横轴)两轴排布。机器人遥操作位于"高质量、难扩展"一角,互联网人类视频位于"易扩展、难迁移"另一角——WAM 的使命,正是战略性地混合这两端。
构建 WAM 的数据版图,绝不只是"把机器人数据做大",而是要把严格耦合的演示与不受约束的观测巧妙地混合起来,以弥合"精确低层控制"与"开放世界泛化"之间的鸿沟。
四、如何评判一个 WAM?三维评测体系
一个 WAM 好不好,既要看它"想得准不准",也要看它"做得成不成"。综述指出当前评测普遍采用解耦范式,并沿两条互补轴线展开。
世界建模能力:想得逼真,更要想得合理
- 视觉保真度:最基础的一层。像素级用 PSNR、SSIM;感知与语义层面用 LPIPS、DreamSim、DINO 相似度;分布层面用最广泛使用的 FVD(在预训练视频特征空间里计算真实与生成视频分布的 Fréchet 距离)。
- 物理常识:比"看着真"更深一层——“行为是否符合物理”。VideoPhy、PhyGenBench、VBench-2.0、WorldModelBench(以牛顿第一定律、质量守恒、不可穿透性等五条物理律打分)、Physics-IQ 等,专门检验生成世界是否保持物体连续性、是否遵循接触/碰撞/因果时序,以及运动轨迹是否平滑可控。
- 动作合理性:最具 WAM 特色的一维——"生成的视频里是否保留了足够的动作信息,能被翻译回可执行控制?“WorldSimBench 引入"隐式操作评测”,而 Wow, wo, val! 提出的"逆动力学图灵测试"更是一针见血:用 IDM 从生成视频反推动作并在真机上执行,结果发现许多视觉上以假乱真的模型,成功率几乎归零——这揭示了"视觉合理"与"可执行"之间的巨大鸿沟。
动作策略能力:从仿真到真机的 40+ 基准
综述系统梳理了 2019–2026 年间 40 多个主流基准,按机器人形态与操作场景分为五类:通用操作(MetaWorld、RLBench、LIBERO、ManiSkill 系列、SimplerEnv 等,主体)、双臂与人形(RoboTwin、HumanoidBench)、移动操作(HomeRobot、BEHAVIOR-1K)、接触与形变操作(SoftGym、TacSL 等,从"视觉主导"走向"视触觉融合"),以及直接在真机上评测的 真机基准(RoboArena、Maniparena)。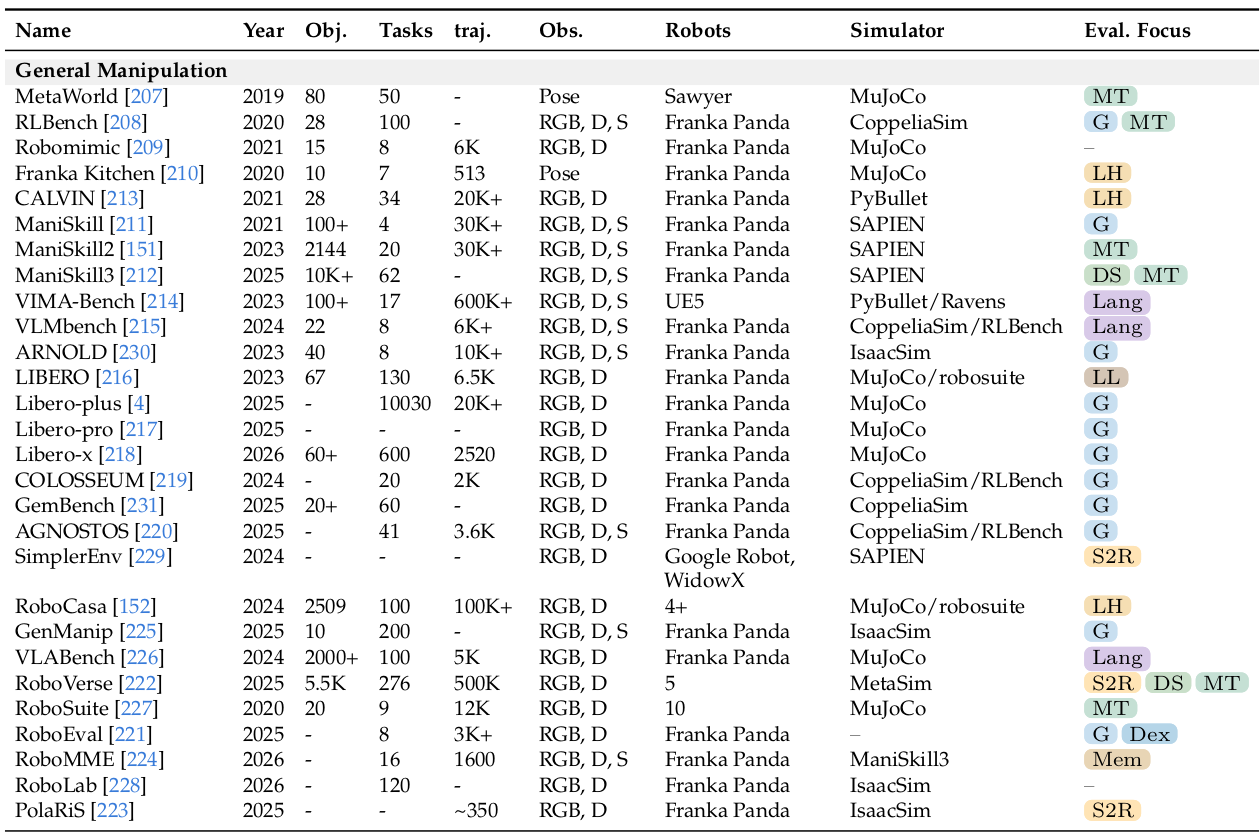
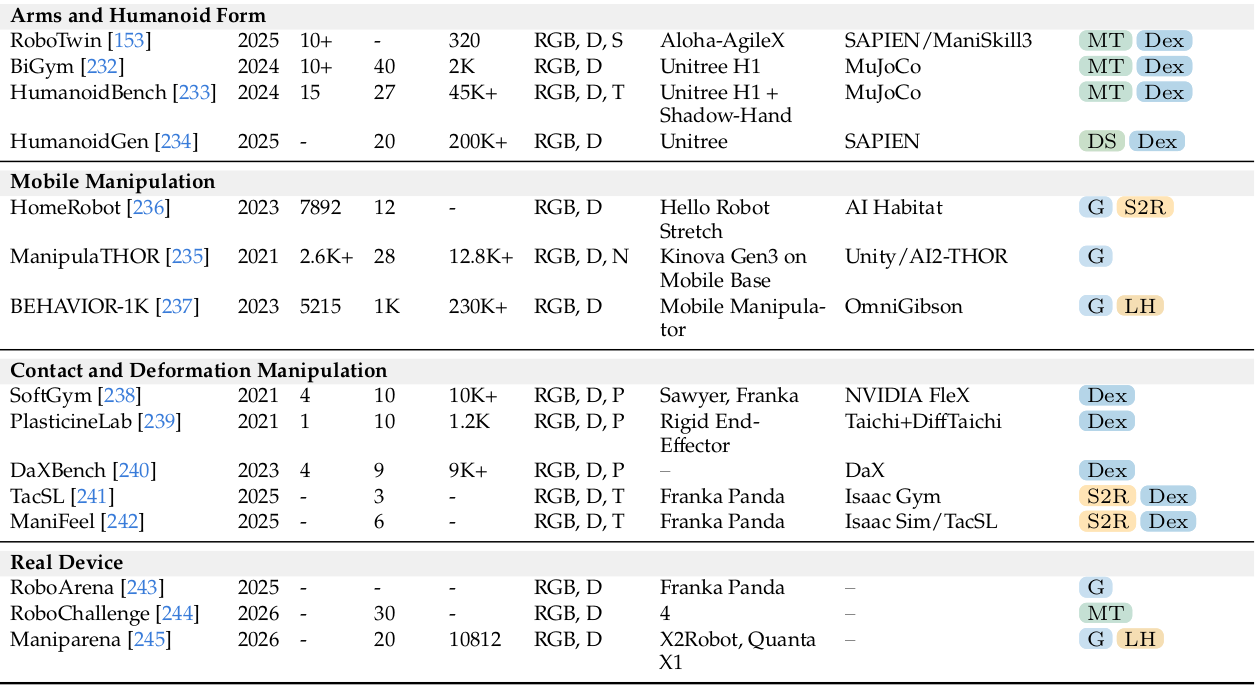
值得警惕的是,综述尖锐地指出当前评测的割裂之痛:世界建模常用 PSNR、FVD 等只看"视觉像不像"、却放任"悬浮的物体、违反重力的流体"得高分;动作生成则只看下游任务成功率。二者之间"想象的未来"与"实际的动作"是否因果一致,几乎无人评测。
五、开放挑战与未来机遇
WAM 标志着具身智能从"token 级预测"向"状态级预测"的关键转向,但通往通用物理智能的道路依然崎岖。综述凝练出几个将定义下一阶段研究的命题:
- 架构耦合之争:级联式、联合扩散、离散 token、隐式对齐……百花齐放,却没有一项在同等规模、数据、协议下的受控对比研究。显式的像素预测,真的是物理接地所必需的吗? 越来越多证据表明,世界建模的好处也许主要来自训练时的"辅助梯度",而非推理时真的去生成未来帧——这为 JEPA 式的潜在预测范式打开了大门:与其重建高维像素,不如在潜在空间里预测未来状态的抽象表征,绕开像素预测的瓶颈。
- 多模态物理状态表征:现有 WAM 几乎都在 RGB 视觉模态里预测未来,可对富接触操作最关键的触觉分布、接触力、声学特征却在像素空间里几乎不可见。把 WAM 扩展到联合预测触觉、力、本体感受的未来状态,是一片重要而尚未开垦的疆域。理想的未来架构应具备模态自适应预测能力——有丰富传感器时做物理接地的预测,没有时则优雅地退化为纯视觉推理。
- 数据利用与混合配方:人类视频到底贡献了什么?是语义还是动力学?训练课程该如何从"互联网先验"过渡到"精确动作标注"?综述提出把人类视频的价值理解为一个可迁移知识的层级——低层物理先验、中层因果动力学、高层任务逻辑——并呼吁发展具备形体感知的过滤机制,从多样来源中蒸馏通用物理律、同时抑制与目标机器人运动学不兼容的行为。
- 长程规划与时间抽象:WAM 多在短程任务上评测,但真正的具身通才需要跨越长时程的持续推理。分布漂移、误差累积、长轨迹的计算开销都是拦路虎。一个连接"高层语义任务分解"与"低层物理预测"的层级化世界-动作建模框架,仍是关键的开放挑战。
- 推理延迟与计算效率:世界预测带来沉重的"延迟税"。DreamZero 通过算法加速与底层 CUDA 优化把推理推到 7Hz,但相比非生成式 VLA 策略的 50Hz 标准仍有显著差距。一个少有人触及的理论问题是:下游控制究竟需要多高的预测保真度? 这指向任务自适应预测保真度——按任务需求动态调整预测的深度与分辨率。
- 评测方法学:未来基准亟需引入耦合指标,探测视觉预测与物理执行之间的因果链。例如"反事实一致性"(动作如何随想象未来的扰动而适应)、“以预见为条件的成功率”(执行轨迹是否严格遵循生成的视觉规划)。社区需要一个把"世界预测质量"与"动作质量"联合评估的共享框架。
- 安全与可靠的物理部署:一个自信地"想象"出错误未来的模型,可能会执行一连串难以中断的危险动作。但反过来,WAM 的预测能力也提供了预测集成的安全机制——在执行前,先把对想象未来的不确定性估计当作安全监控的"一等输入",用世界预测不仅指导动作、更去验证动作。
六、结语:通向通用具身智能的新范式
回望全文,WAM 的真正意义,在于它把"世界"重新请回了机器人的决策回路。VLA 教会了机器人"看一眼就动手",而 WAM 让机器人在动手之前,先在脑海中"预演"一遍物理世界的演化——这是从条件反射到深思熟虑的跃迁。
这篇综述的价值,不仅在于首次为这一散落的领域立名、厘清术语边界,更在于它系统地勾勒出 WAM 的架构设计空间(级联式与联合式)、数据生态(遥操作、人类演示、仿真、第一人称视频四足鼎立)与评测体系(视觉保真度、物理常识、动作合理性三维并举),并诚实地指出了横亘前路的七道难关。
随着生成式世界建模与机器人学的持续融合,WAM 研究蕴含着巨大的潜力。当机器人不仅能听懂我们的语言、看懂眼前的场景,更能预见自己行动的物理后果时,通用具身智能的图景,或许就不再遥远。这需要持续的研究投入与跨学科的协作——而我们,正站在这场变革的起点。
七、延伸资源
- 原论文:《World Action Models: The Next Frontier in Embodied AI》(arXiv:2605.12090),复旦大学 / 上海创新研究院 / 新加坡国立大学。
- 项目主页:https://openmoss.github.io/Awesome-WAM
- 持续更新的论文清单(Awesome-WAM):https://github.com/OpenMOSS/Awesome-WAM
- 奠基性 VLA 工作:RT-2、OpenVLA、π₀。
- 代表性世界模型:PlaNet、Dreamer 系列、V-JEPA、iVideoGPT、Genie;视频大模型 Sora、Wan、Veo、Kling。
- 关键数据集与基准:OXE、DROID、AgiBot World(遥操作);UMI、EgoDex、Ego4D(人类/第一人称);RoboCasa、SynGrasp-1B、RoboTwin(仿真);LIBERO、ManiSkill、SimplerEnv、WorldModelBench(评测)。
- 值得关注的顶级会议:CoRL、ICRA、IROS、RSS(机器人);NeurIPS、ICLR、ICML、CVPR(机器学习与视觉)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)