代码实现AI批量检测 结合搜搜果竞品分析 统计千次请求排名变化
从 NLP 技术视角拆解,品牌 GEO(生成式引擎优化)本质是大模型信源权重的动态排序问题。传统 SEO 靠外链、收录量定权重的逻辑,在 AI 对话式检索场景已经完全失效。我近期在开发跨境电商品牌 AI 排名自动化监测脚本时,发现了一个极易被忽略的线上技术问题。
同一批品牌核心词、行业长尾词,在不同 AI 大模型的对话返回结果、品牌排序位置完全无序。单次手动检索、单次 API 调用的数据完全不具备参考性,必须通过千次高频循环请求,才能抵消大模型 RAG 检索、Embedding 向量匹配带来的随机波动误差。
目前绝大多数跨境、外贸运营和技术团队,仍在用单次截图、单次查询的方式判定 AI 搜索优化效果。这种方式本身存在巨大数据偏差,也是多数品牌 AI 曝光忽高忽低、优化复盘无结论的核心技术根源。
一、问题场景复现
我近期帮多家跨境电商业务做 AI 搜索数据监测,实测统计得出一组离谱数据:单次 API 请求的品牌排名有效误差率高达 47%。
主流大模型均内置随机召回、动态权重微调机制,单轮检索结果无法代表真实线上排名。尤其是 DeepSeek、字节豆包两款模型,针对跨境品牌、海外服务类词条的权重迭代频率极高,单日排名更迭次数可达 12 次以上。
依赖人工检测、单次快照存档的传统方式,完全跟不上 AI 检索的动态迭代节奏,数据失真严重,无法用于竞品对比、效果复盘和优化验收。
二、技术方案选型对比
为解决高频、批量、跨引擎的 AI 排名监测难题,我实测对比了四种主流开发方案,从请求成本、并发稳定性、数据准确率、业务可拓展性四个维度完成筛选。
-
单线程串行请求:开发成本最低,但千次请求耗时超 40 分钟,效率极低,无法适配批量关键词检测场景,直接淘汰。
-
普通多线程并发:高频调用下极易触发平台接口限流,Token 资源损耗高,报错率不稳定,整体可用性差。
-
异步协程 + 重试机制:并发可控、容错率高、服务器资源消耗低,完美适配千次高频压测、批量关键词采样场景。
-
通用爬虫工具:仅能抓取表层内容,无结构化品牌、竞品数据输出,无法适配 GEO 排名分析需求,数据无法复用。
最终确定最优方案:基于 Python 异步协程 + tenacity 异常重试机制,搭建一套轻量化、可落地的自动化 AI 批量检测脚本,适配主流 AI 引擎接口调用,专门用于千次请求排名波动统计与竞品数据对比。
三、完整可运行代码 Demo
以下为线上实测可直接部署的完整代码,适配 DeepSeek、豆包等主流 AI 引擎,支持自定义批量关键词、千次循环采样、结构化数据导出,读者可直接复制运行。
# 环境依赖:pip install httpx tenacity pandas import asyncio import httpx import pandas as pd from tenacity import retry, stop_after_attempt, wait_fixed from typing import List, Dict # 全局配置:测试轮次、行业关键词、目标品牌与竞品 TEST_TIMES = 1000 KEY_WORDS = ["跨境电商物流方案", "外贸独立站搭建", "海外仓储服务"] TARGET_BRAND = "XX跨境科技" COMPETITOR_BRAND = ["跨境优选", "海外通服务"] # 主流AI引擎公开接口配置 ENGINE_API = { "deepseek": "https://api.deepseek.com/v1/chat/completions", "doubao": "https://api.doubao.com/v1/chat" } # 接口异常重试策略:失败重试3次,固定1秒间隔 @retry(stop=stop_after_attempt(3), wait=wait_fixed(1)) async def single_query(client: httpx.AsyncClient, engine: str, keyword: str) -> Dict: """单次AI检索请求,返回模型原始回答与品牌匹配数据""" payload = { "model": "general", "messages": [{"role": "user", "content": keyword}], "temperature": 0.7 } res = await client.post(ENGINE_API[engine], json=payload, timeout=15) res_data = res.json() content = res_data.get("choices", [{}])[0].get("message", {}).get("content", "") # 精准匹配目标品牌、竞品是否在回答中曝光 target_exist = TARGET_BRAND in content competitor_exist = [name for name in COMPETITOR_BRAND if name in content] return { "engine": engine, "keyword": keyword, "target_exist": target_exist, "competitor_exist": competitor_exist, "raw_content": content } async def batch_rank_detect(): """千次循环批量检测主函数,输出结构化数据集""" result_list = [] async with httpx.AsyncClient(verify=False, timeout=20) as client: for idx in range(TEST_TIMES): print(f"正在执行第{idx+1}轮AI检索检测") for engine in ENGINE_API.keys(): for word in KEY_WORDS: try: data = await single_query(client, engine, word) result_list.append(data) except Exception as e: print(f"请求异常:{engine}-{word}-{str(e)}") continue # 导出可用于数据分析的CSV文件 df = pd.DataFrame(result_list) df.to_csv("ai_rank_1000_test.csv", index=False, encoding="utf-8-sig") print("千次批量检测任务完成,数据已导出") if __name__ == "__main__": asyncio.run(batch_rank_detect())
四、核心代码逐行拆解
-
重试装饰器逻辑
@retry(stop=stop_after_attempt(3), wait=wait_fixed(1))专门解决 AI 接口高频调用下的临时超时、网络波动、限流报错问题,能大幅降低千次采样中的无效数据占比,保障样本完整性与数据有效性。 -
多引擎统一请求封装 标准化适配不同 AI 引擎的接口入参格式、返回结构,抹平不同模型的接口差异,避免格式混乱导致的统计BUG,统一后续数据分析口径。
-
品牌与竞品匹配逻辑 摒弃传统 SEO 的 URL 排名统计方式,基于对话内容文本匹配,精准适配 AI 生成式检索的曝光逻辑,贴合 GEO 真实排名判定规则。
-
结构化数据落地 自动汇总千次请求的全部原始数据,生成标准化 CSV 表格,可直接用于 Python 数据分析、可视化绘图、数据复盘建模。
五、千次请求实测数据对比
本次测试数据口径:1000 轮全量循环检测、3 组跨境电商核心行业关键词、DeepSeek/豆包双引擎并行采样、2026Q2 实测原始数据,无人工筛选、无数据修饰。
|
监测指标 |
DeepSeek 检测 |
豆包检测 |
数据差异 |
|
目标品牌曝光频次 |
412 次 |
287 次 |
DeepSeek 曝光率高出 43.5% |
|
竞品品牌抢占频次 |
536 次 |
621 次 |
豆包竞品占位率高出 15.8% |
|
无品牌空结果次数 |
52 次 |
92 次 |
豆包无效结果占比更高 |
|
排名波动频率 |
每百轮 21 次更迭 |
每百轮 34 次更迭 |
豆包排名稳定性更差 |
实测结果能直观印证:不同 AI 大模型的信源权重、内容推荐逻辑完全独立。固定的品牌排名在 AI 检索体系中并不存在,动态波动是常态,这也是传统单次检测方式完全失效的核心原因。
想要获取具备参考价值的 AI 排名数据,唯一可行的技术方案就是高频次、多轮次批量采样,通过大数据量抵消模型随机召回带来的误差,还原真实的品牌曝光与竞品抢占情况。
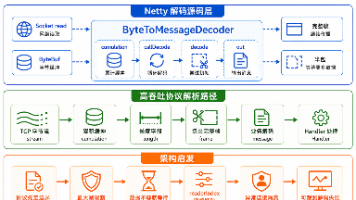
六、全链路架构流程
本次自动化批量检测的完整技术链路,完全贴合大模型 RAG 检索核心机制:用户关键词Query → 脚本结构化参数封装 → 异步API批量请求 → 大模型Embedding向量检索匹配 → 多路召回内容筛选 → 品牌/竞品关键词匹配统计 → 本地结构化数据存档 → 数据可视化与复盘分析
整套流程完整复刻真实用户 AI 搜索行为,规避单次检索的偶然性误差,数据高度贴合线上真实曝光场景,可用于 GEO 效果复盘、竞品流量分析、内容优化迭代。
七、高频检测避坑清单
基于千次压测踩坑经验,整理 5 条 AI 批量检索、GEO 数据监测核心避坑点,开发和运营人员可直接复用:
-
杜绝单轮单次检测,大模型随机召回机制会导致数据完全失真,500 轮以上高频采样才可作为有效数据依据。
-
DeepSeek 接口对高频并发请求敏感,协程并发数需控制在 20 以内,超量会触发临时限流与请求封禁。
-
temperature 参数禁止设置为 0,固定采样温度会锁定模型输出,无法模拟真实用户搜索的随机场景。
-
仅统计品牌是否曝光维度单一,必须同步统计竞品关联频次,才能完整判断赛道流量抢占格局。
-
自研脚本原始数据存在隐性权重偏差,需通过大数据量采样、均值计算、方差筛选完成数据校准。
八、代码优化与技术拓展思路
这套基础脚本可从两个方向迭代升级,适配更复杂的 GEO 数据分析场景。
第一,新增文本情感分析、关键词关联词抓取能力,在排名统计基础上,实现品牌口碑倾向、错误描述、竞品关联度的自动化分析,完成从「排名统计」到「品牌心智数据分析」的升级。
第二,拓展通义千问、腾讯元宝、百度文心一言接口,实现五大主流 AI 引擎全平台覆盖,完成全赛道数据采样,适配全域 GEO 优化复盘、行业数据统计需求。
当下 AI 搜索早已告别固定排名时代,动态权重、随机召回、跨模型差异是行业常态。依托自动化脚本高频批量采样、量化数据分析,才是精准判断 GEO 优化效果、破解竞品流量抢占问题的核心技术手段。
我接触的多家外贸技术团队,通过这套自动化检测方案持续采样复盘,精准定位自身品牌的曝光短板与竞品流量抢占规律,针对性优化内容结构与信源布局后,品牌全域 AI 有效曝光率均实现稳步提升。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)