07|Netty 如何处理半包粘包:ByteToMessageDecoder 源码主线
07|Netty 如何处理半包粘包:ByteToMessageDecoder 源码主线
很多人刚开始写 TCP 程序时,都会遇到一个问题:
- 客户端明明发送了两条消息,
- 服务端为什么一次读到了一坨?
或者反过来:
- 客户端明明发送了一条完整消息,
- 服务端为什么分好几次才读到?
这就是常说的:
- 粘包
- 半包
但先纠正一个常见误解:
半包粘包不是 Netty 的 bug,也不是 TCP 的 bug。
它是 TCP 字节流模型的正常结果。
TCP 只保证:
- 字节有序
- 可靠传输
- 不丢不重
更严谨地说,在连接正常、没有异常中断的前提下,TCP 向应用层提供的是可靠有序的字节流语义。
但 TCP 不保证:
应用层一次 send,对端一次 read 就完整收到。
所以网络框架必须解决一个问题:
如何把 TCP 字节流还原成应用层消息?
Netty 的答案是:
ByteToMessageDecoder
以及各种基于它实现的解码器,例如:
LengthFieldBasedFrameDecoderLineBasedFrameDecoderDelimiterBasedFrameDecoderFixedLengthFrameDecoder
这一篇就围绕半包粘包和 ByteToMessageDecoder 源码主线展开。
如果把视角放到业务系统里,半包粘包不是一个孤立的 TCP 小问题,而是在提醒我们:任何跨进程、跨网络、跨系统的通信,都必须有清晰的协议边界。
例如在云边协同系统里,边缘侧可能通过 MQTT 与云端通信,也可能通过 HTTP 上传状态、日志、任务结果,或者调用对象存储上传大文件;云端还可能同时存在外部协议适配入口和内部业务协议入口。外部协议面向设备生态或第三方协议,内部协议面向自己的业务模型,两者之间不能只靠“把 JSON 转发一下”来连接。
真正要设计清楚的是:
- 一条消息从哪里开始,到哪里结束;
- 消息体采用什么结构,如何反序列化;
- 协议是否有版本、类型、来源标记和幂等标识;
- 超长、半截、非法、旧版本消息如何处理;
- 网关到底只是转发,还是承担协议翻译、过滤、反回环和生命周期管理。
所以这一篇看的是 Netty 解码器源码,但底层训练的是架构师对“协议边界”的敏感度。
一、为什么 TCP 会有半包粘包?
假设客户端发送两条消息:
helloworld
服务端不一定读到两次:
helloworld
它可能一次读到:
helloworld
这就是粘包。
也可能分多次读到:
hello world
这就是半包。
原因很简单:
TCP 是字节流协议,不是消息协议。
它只负责传输连续字节,不关心应用层消息边界。
应用层所谓的:
- 一条消息
- 一个请求
- 一个包
对 TCP 来说都只是字节。
TCP 可能因为这些因素合并或拆分数据:
发送缓冲区
接收缓冲区
MSS
Nagle 算法
网络拥塞
应用读取速度
操作系统调度
所以半包粘包不是异常,而是 TCP 编程必须处理的基本问题。
二、解决半包粘包的本质:定义消息边界
既然 TCP 没有消息边界,应用层就必须自己定义边界。
常见方式有几种。
第一种:固定长度。
每条消息固定 128 字节。
优点是简单。
缺点是不灵活,浪费空间。
第二种:分隔符。
hello\nworld\n
以换行符或特殊字符作为消息结束标记。
适合文本协议。
第三种:长度字段。
消息长度 + 消息内容
比如:
4 字节 length + body
这是二进制协议里非常常见的方式。
第四种:协议自身有完整格式。
例如 HTTP 有:
Content-LengthTransfer-EncodingHeader + Body
所以解决半包粘包的本质不是“调大 buffer”。
而是:让应用层协议有清晰的消息边界。
放到业务系统里,这个判断会继续扩大:
| 通信场景 | 表面问题 | 本质边界 |
|---|---|---|
| TCP 自定义协议 | 半包、粘包 | 帧边界 |
| MQTT 消息 | topic 能否路由 | 业务消息边界 |
| 外部协议适配 | 字段能否映射 | 外部语义与内部语义边界 |
| 云边消息转发 | 能否成功投递 | 来源、方向、幂等、反回环边界 |
| 大文件上传 | 能否传完 | 元数据、分片、失败恢复边界 |
这也是为什么 public MQTT / private MQTT 这种分层设计本身是有意义的:外部入口负责适配外部协议,内部入口承载自己的业务协议,中间的转换层应该显式处理序列化、协议版本、来源标记、生命周期和异常策略。
三、Netty 的解码器放在哪里?
在 Netty 中,解码器通常放在 Pipeline 的 inbound 链路上。
例如:
ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(...));
ch.pipeline().addLast(new MessageDecoder());
ch.pipeline().addLast(new BusinessHandler());
入站数据流大概是:
也就是说:
- 先把 TCP 字节流切成一帧一帧;
- 再把帧解码成业务消息;
- 最后交给业务 Handler。
这里的 FrameDecoder 就是解决半包粘包的关键。
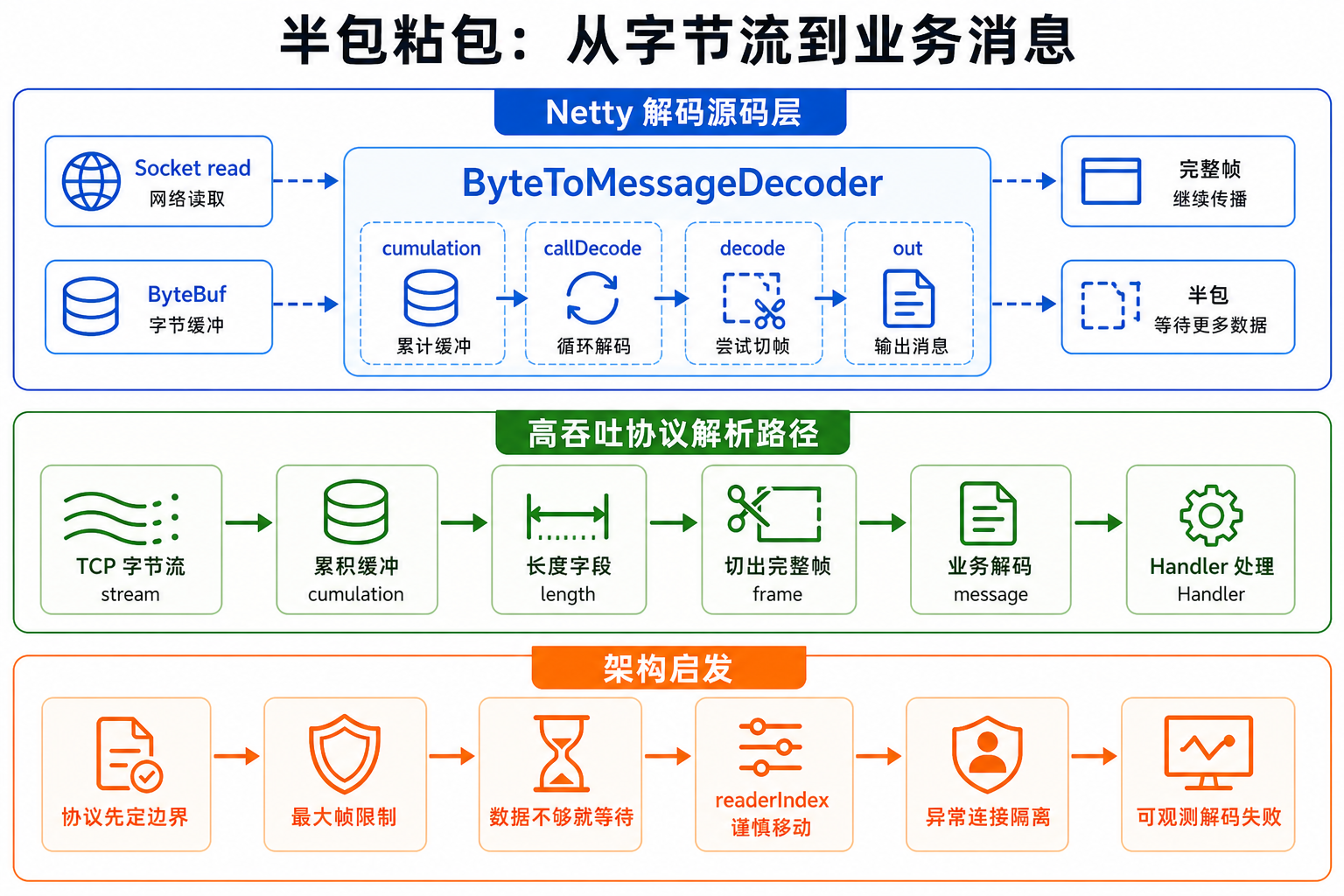
四、ByteToMessageDecoder 是什么?
ByteToMessageDecoder 是 Netty 中非常核心的解码器基类。
它的定位是:
把入站 ByteBuf 字节流解码成一个或多个消息对象。
核心方法是:
protected abstract void decode(
ChannelHandlerContext ctx,
ByteBuf in,
List<Object> out
) throws Exception;
其中:
in:
当前累积到的字节数据。out:
解码出来的消息列表。
如果当前数据不够一条完整消息,就什么都不放进 out。
如果够一条消息,就解析出来并加入 out。
如果够多条消息,可以一次加入多个对象。
所以 decode 的基本逻辑通常是:
if (in.readableBytes() < headerLength) {
return;
}
int length = in.getInt(in.readerIndex());
if (in.readableBytes() < headerLength + length) {
return;
}
in.skipBytes(headerLength);
ByteBuf frame = in.readRetainedSlice(length);
out.add(frame);
注意这里有两个关键点:
- 数据不够时 return;
- 不要错误移动 readerIndex。
五、ByteToMessageDecoder 如何累积半包?
如果一次 socket read 只读到半条消息,怎么办?
Netty 会把这部分数据累积起来。
ByteToMessageDecoder 内部有一个累积缓冲区,常见叫:
cumulation
当新的 ByteBuf 到来时,它会和旧的半包数据合并或组合。
源码主线大致是:
所以半包处理的核心是:
- 不完整的数据先留在 cumulation 里;
- 等下一次读到更多字节后继续解码。
这就是为什么业务 Handler 通常不应该直接处理裸 ByteBuf 字节流。
应该先经过解码器,把字节流变成完整消息。
六、callDecode() 的循环逻辑
ByteToMessageDecoder 的核心源码之一是:
callDecode()
它会循环调用用户实现的 decode()。
主线可以简化成:
while (in.isReadable()) {
int oldInputLength = in.readableBytes();
int oldOutputSize = out.size();
decode(ctx, in, out);
if (out.size() > oldOutputSize) {
fireChannelRead(out);
out.clear();
}
if (in.readableBytes() == oldInputLength) {
break;
}
}
真实源码更严谨,会处理:
Handler 被移除
decode 没读数据却产出消息
decode 读了数据但没产出消息
单次解码控制
异常传播
但主旨是:
只要还有可读数据,就尝试继续解码。
为什么要循环?
因为一次 socket read 可能读到多条完整消息。
比如:
msg1msg2msg3
如果只 decode 一次,就只能解出一条,剩下的要等下一次 IO 事件。
循环解码可以在一次 read 事件里尽量把完整消息都解出来。
七、decode 时为什么不能乱动 readerIndex?
写自定义解码器时,最容易犯的错误是:
- 数据还不够一条完整消息,
- 但已经移动了 readerIndex。
比如:
int length = in.readInt();
if (in.readableBytes() < length) {
return;
}
这段代码有问题。
因为 readInt() 已经移动了 readerIndex。
如果 body 不完整,直接 return,下一次再来数据时,长度字段已经被消费掉了。
正确做法之一是使用:
int length = in.getInt(in.readerIndex());
getInt 不会移动 readerIndex。
确认完整包到齐以后,再真正读取:
in.skipBytes(4);
ByteBuf body = in.readRetainedSlice(length);
out.add(body);
也可以使用:
markReaderIndex()
resetReaderIndex()
但最核心原则是:
不确定完整消息到齐之前,不要破坏读指针。
八、LengthFieldBasedFrameDecoder 解决什么?
实际项目里,最常用的拆包器之一是:
LengthFieldBasedFrameDecoder
它适合这种协议:
长度字段 + 消息体
比如协议格式:
魔数 magic 2 字节
版本 version 1 字节
类型 type 1 字节
长度 length 4 字节
消息体 body N 字节
那么 length 字段从偏移 4 开始,占 4 字节。
可以配置:
new LengthFieldBasedFrameDecoder(
maxFrameLength,
lengthFieldOffset,
lengthFieldLength,
lengthAdjustment,
initialBytesToStrip
);
这些参数看着绕,但它们都围绕一个问题:
如何根据长度字段算出完整帧的边界。
九、LengthFieldBasedFrameDecoder 参数怎么理解?
几个核心参数:
maxFrameLength:
单帧最大长度,防止异常大包撑爆内存。lengthFieldOffset:
长度字段的起始偏移。lengthFieldLength:
长度字段占几个字节。lengthAdjustment:
长度字段表示的长度和整帧长度之间的修正值。initialBytesToStrip:
解码后要跳过多少字节再传给下一个 Handler。
举个简单协议:
length(4 字节) + body
length 表示 body 长度。
那么:
new LengthFieldBasedFrameDecoder(
1024 * 1024,
0,
4,
0,
4
);
含义是:
最大帧 1MB
长度字段从 0 开始
长度字段 4 字节
length 只表示 body 长度,不需要修正
解码后去掉前 4 字节 length,只把 body 交给后续 Handler
如果 length 表示的是整帧长度,而不是 body 长度,lengthAdjustment 就要调整。
所以使用这个解码器时,一定要先明确:
- 长度字段到底表示 body 长度,还是整帧长度?
- 长度字段前面有没有 magic/version/type?
- 后续 Handler 是否还需要看到 header?
十、为什么需要 maxFrameLength?
maxFrameLength 很重要。
它不是随便填的。
如果没有最大帧限制,攻击者可以伪造一个超大 length:
length = 2GB
服务端如果一直等待这么大的包,就可能导致:
- 内存占用暴涨
- 连接长期占用
- 资源被拖死
所以拆包器必须限制最大帧。
超过最大帧时,Netty 会触发异常,例如:
TooLongFrameException
这是一种协议层自我保护。
高并发服务器不能相信客户端一定守规矩。
十一、LineBasedFrameDecoder 和 DelimiterBasedFrameDecoder
除了长度字段,Netty 还提供基于分隔符的解码器。
例如:
LineBasedFrameDecoder
适合:
一行一条消息
比如:
PING\r\nPONG\r\n
还有:
DelimiterBasedFrameDecoder
可以自定义分隔符。
它们适合文本协议或简单命令协议。
但分隔符协议也有风险:
如果一直找不到分隔符,缓冲区会持续增长。
所以同样需要最大长度限制。
十二、业务解码器和帧解码器要分开
一个常见好设计是把解码拆成两层:
FrameDecoder:
解决半包粘包,输出完整帧。MessageDecoder:
把完整帧解析成业务对象。
例如:
这样职责更清楚。
LengthFieldBasedFrameDecoder 不关心业务字段。
它只负责:
切出完整消息帧。
RpcMessageDecoder 再负责:
解析 magic、version、type、requestId、body。
这种分层能让协议处理更稳定,也更容易测试。
十三、MessageToByteEncoder:出站编码
解码是入站。
编码是出站。
Netty 常用:
MessageToByteEncoder
它负责把业务对象编码成 ByteBuf。
例如:
protected void encode(
ChannelHandlerContext ctx,
RpcResponse msg,
ByteBuf out
) {
out.writeShort(MAGIC);
out.writeByte(VERSION);
out.writeByte(msg.getType());
out.writeInt(msg.bodyLength());
out.writeBytes(msg.body());
}
然后后续 outbound 流程会把这个 ByteBuf 写出去。
所以完整协议链路是:
入站:
ByteBuf -> 完整帧 -> 业务请求对象出站:
业务响应对象 -> ByteBuf -> socket
十四、编解码器和 ByteBuf 生命周期
编解码器里必须注意 ByteBuf 生命周期。
比如:
ByteBuf frame = in.readRetainedSlice(length);
out.add(frame);
这里使用 readRetainedSlice,意味着切出来的 frame 会 retain。
后续 Handler 消费完后,需要按照 Netty 规则释放。
如果使用 readSlice,它只是共享视图,不增加引用计数,生命周期更容易踩坑。
如果使用 copy,会复制数据,安全但有额外拷贝。
所以解码器里要清楚:
- 我是传递视图?
- 还是传递保留引用?
- 还是复制一份新数据?
这和上一篇 ByteBuf 的引用计数是连在一起的。
十五、半包粘包和背压的关系
半包粘包看起来是协议问题,但它也和资源控制有关。
如果客户端一直发送不完整数据:
只发 header,不发 body
服务端的 cumulation 就可能一直保留半包。
连接多了以后,就会消耗大量内存。
所以协议层需要:
最大帧长度
读超时
空闲检测
异常连接关闭
限流
Netty 里常见组件包括:
IdleStateHandlerReadTimeoutHandler- LengthFieldBasedFrameDecoder 的 maxFrameLength
高并发系统不能只考虑“正常客户端”。
还要考虑:
慢客户端
恶意客户端
半开连接
异常大包
永远不完整的包
十六、一个推荐的自定义协议 Pipeline
假设我们设计一个 RPC 协议:
magic 2 字节
version 1 字节
type 1 字节
requestId 8 字节
length 4 字节
body N 字节
Pipeline 可以这样组织:
pipeline.addLast(new IdleStateHandler(0, 0, 60));
pipeline.addLast(new LengthFieldBasedFrameDecoder(
1024 * 1024,
12,
4,
0,
0
));
pipeline.addLast(new RpcMessageDecoder());
pipeline.addLast(new RpcMessageEncoder());
pipeline.addLast(new RpcBusinessHandler());
这里 lengthFieldOffset = 12,因为 length 前面有:
magic(2) + version(1) + type(1) + requestId(8) = 12 字节
initialBytesToStrip = 0 表示不剥掉 header,而是把完整帧继续交给 RpcMessageDecoder,让后者解析 magic、version、type、requestId、length 和 body。
这里:
IdleStateHandler:
处理空闲连接。LengthFieldBasedFrameDecoder:
根据 length 字段切出完整帧。RpcMessageDecoder:
把帧转成请求对象。RpcMessageEncoder:
把响应对象转成 ByteBuf。RpcBusinessHandler:
执行业务逻辑。
这就是 Netty Pipeline 的价值:
每一层只做一件事。
十七、结论
半包粘包不是异常,而是 TCP 字节流模型的正常结果。
解决它的关键不是调大 buffer,而是:
定义清晰的应用层消息边界。
Netty 通过:
ByteToMessageDecoder
cumulation
callDecode
LengthFieldBasedFrameDecoder
MessageToByteEncoder
把字节流转换成应用层消息。
核心主线可以记成:
写自定义解码器时,最重要的原则是:
- 数据不够就 return;
- 不要错误移动 readerIndex;
- 必须限制最大帧长度;
- 明确 ByteBuf 生命周期。
理解了编解码,再看 Netty 的 HTTP、RPC、WebSocket、游戏协议、IM 协议,就能看出它们本质上都在做同一件事:把无边界的 TCP 字节流,变成有边界的应用层消息。
对我的架构判断有什么用?
这篇文章真正要沉淀的不是“Netty 如何解决半包粘包”这一道面试题,而是一个更大的判断:系统边界越多,协议边界就越要显式。
在边缘侧、云端、设备接入、媒体链路这类系统里,至少会同时存在几种不同边界:
- 控制指令边界:一条指令什么时候算完整,是否允许重复执行;
- 状态消息边界:一次上报包含哪些字段,旧版本字段如何兼容;
- 协议适配边界:外部协议字段如何转换为内部业务对象;
- 网关转发边界:哪些消息只消费,哪些消息继续转发,如何避免回环;
- 视频流边界:媒体帧、编码格式、转封装和播放协议各自有边界;
- 大文件边界:文件元数据、分片、上传状态和失败恢复不能混在普通消息里。
所以以后评审一个通信设计时,我不会只问“这个消息能不能收到”,而会问:
- 消息边界在哪里定义?
- 谁负责把字节、文本或 JSON 还原成业务对象?
- 协议有没有版本、类型、来源、幂等标识?
- 超长、非法、半截、旧版本消息怎么处理?
- 外部协议和内部协议之间有没有明确的翻译层?
- 网关是在转发消息,还是在承担协议治理?
能回答这些问题,才说明一个系统的通信模型不是靠经验堆出来的,而是有可演进的协议边界。
下一篇我们继续看:
Reactor Netty 和 Spring Cloud Gateway 是如何站在 Netty 之上的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)