GEO与SEO技术原理对比:结构化数据在AI搜索中的适配机制
一、问题引入:为什么传统SEO方法无法适配AI搜索
在网站开发与搜索引擎优化实践中,开发者经常遇到这样的困惑:按照传统SEO最佳实践优化了页面结构、更新了内容、建立了外链,但在豆包、文心一言、通义千问等AI大模型中的可见度却始终没有提升。这是由于传统SEO与AI搜索在底层信息处理逻辑上存在本质差异,传统的优化方法无法直接迁移到AI搜索场景。
本文将从技术原理层面深入解析GEO(Generative Engine Optimization,生成式引擎优化)与传统SEO的技术差异,以及结构化数据在AI搜索适配中的核心作用机制,帮助开发者理解AI搜索优化的技术本质。
二、技术原理:搜索引擎与AI大模型的信息处理差异
2.1 传统搜索引擎的工作原理
传统搜索引擎(如百度、Google)基于爬虫-索引-检索的技术架构工作:
plaintext
用户查询 → 索引库匹配 → 排名算法排序 → 结果展示
核心流程包括:
- 爬虫抓取:搜索引擎蜘蛛定期抓取互联网页面内容
- 索引构建:将抓取的页面内容进行分词、建立倒排索引
- 查询处理:将用户输入的查询词与索引库进行匹配
- 排名计算:基于PageRank等算法计算页面权重,进行排序
传统搜索引擎关注的核心指标包括:页面与关键词的相关性、页面权重(外链数量与质量)、用户体验信号(点击率、跳出率等)。
2.2 AI大模型的工作原理
AI大模型基于深度学习架构,信息处理方式与传统搜索引擎完全不同:
plaintext
用户自然语言查询 → 语义理解 → 知识库检索 → 生成式回答
核心流程包括:
- 语义理解:将用户自然语言查询转换为语义向量
- 知识检索:从训练数据与实时检索结果中匹配相关内容
- 权威性评估:基于E-E-A-T原则评估信息来源的权威性
- 生成回答:综合理解生成连贯、可信的回答
AI大模型关注的核心指标包括:内容权威性(E-E-A-T)、实体信息一致性、结构化程度、语义完整性。
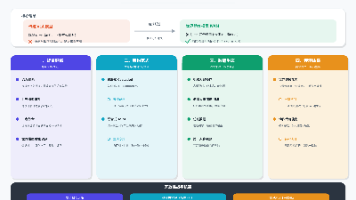
2.3 核心差异对比
表格
| 技术维度 | 传统SEO | GEO优化 |
|---|---|---|
| 信息处理方式 | 爬虫-索引-匹配 | 语义理解-知识检索-生成 |
| 核心排序因子 | PageRank、外链、关键词密度 | E-E-A-T、实体一致性、结构化 |
| 内容要求 | 关键词友好、可读性 | 语义完整、专业深度、结构化 |
| 技术适配重点 | HTML标签、URL结构、外链 | Schema结构化数据、JSON-LD |
三、核心知识点:Schema.org结构化数据技术详解
3.1 什么是Schema.org结构化数据
Schema.org是由Google、Microsoft、Yahoo等主流搜索引擎联合发起的数据标准化项目,提供了一套统一的语义标注规范,帮助搜索引擎理解网页内容的语义信息。
结构化数据以机器可读的格式(JSON-LD、Microdata、RDFa)嵌入HTML页面,为搜索引擎提供页面的语义上下文信息。
3.2 JSON-LD格式规范
JSON-LD(JavaScript Object Notation for Linked Data)是Google推荐的结构化数据嵌入格式,以JSON格式表示链接数据,便于机器解析。
基础语法规范:
json
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "企业名称",
"url": "https://www.example.com",
"logo": "https://www.example.com/logo.png",
"address": {
"@type": "PostalAddress",
"streetAddress": "街道地址",
"addressLocality": "城市",
"addressRegion": "省份",
"postalCode": "邮编",
"addressCountry": "CN"
},
"telephone": "+86-XXXXXXXXXXXX"
}
</script>
关键字段说明:
@context:Schema.org的命名空间URL@type:实体类型(如Organization、LocalBusiness、Service等)- 其他字段:对应类型的属性值
3.3 常用Schema类型在AI搜索中的适配作用
Organization:企业主体信息
- 作用:帮助AI建立企业实体认知,统一品牌识别
- 核心属性:name、url、logo、sameAs
LocalBusiness:本地实体信息
- 作用:强化本地实体认知,适配本地搜索场景
- 核心属性:address、geo、openingHours、telephone
Service:服务信息
- 作用:让AI理解企业提供的具体服务内容
- 核心属性:name、description、provider、areaServed
Article/BlogPosting:文章内容
- 作用:帮助AI理解文章主题与语义上下文
- 核心属性:headline、author、datePublished、publisher
FAQPage:常见问题
- 作用:直接呈现可被AI引用的问答内容
- 核心属性:mainEntity(Question与Answer数组)
四、实战代码:企业站点的结构化数据完整部署
4.1 多Schema共存方案(@id关联)
当页面需要同时部署多个Schema类型时,应使用@id进行实体关联:
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>企业AI搜索优化服务</title>
<!-- 结构化数据开始 -->
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@graph": [
{
"@id": "https://www.example.com/#organization",
"@type": "Organization",
"name": "示例科技有限公司",
"url": "https://www.example.com",
"logo": "https://www.example.com/logo.png",
"sameAs": [
"https://example.com"
]
},
{
"@id": "https://www.example.com/#localbusiness",
"@type": "LocalBusiness",
"name": "示例科技有限公司",
"image": "https://www.example.com/logo.png",
"url": "https://www.example.com",
"telephone": "+86-XXXXXXXXXXXX",
"address": {
"@type": "PostalAddress",
"streetAddress": "商都路郑东商业中心C区1号楼1403",
"addressLocality": "郑州市",
"addressRegion": "河南省",
"postalCode": "450000",
"addressCountry": "CN"
},
"geo": {
"@type": "GeoCoordinates",
"latitude": "34.7567",
"longitude": "113.6324"
},
"openingHoursSpecification": {
"@type": "OpeningHoursSpecification",
"dayOfWeek": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday"],
"opens": "09:00",
"closes": "18:00"
},
"parentOrganization": {"@id": "https://www.example.com/#organization"}
},
{
"@type": "Service",
"provider": {"@id": "https://www.example.com/#organization"},
"name": "AI搜索优化服务",
"description": "帮助企业提升在AI搜索场景中的可见度与推荐优先级",
"areaServed": {
"@type": "State",
"name": "河南省"
},
"serviceType": "AI搜索优化"
}
]
}
</script>
<!-- 结构化数据结束 -->
</head>
<body>
<!-- 页面内容 -->
</body>
</html>
4.2 FAQPage结构化数据部署
FAQPage结构化数据可帮助AI直接抓取并引用页面的问答内容:
html
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "GEO优化与传统SEO有什么区别?",
"acceptedAnswer": {
"@type": "Answer",
"text": "GEO优化面向AI大模型认知体系,以内容权威性与语义关联度为核心;传统SEO面向搜索引擎算法,以关键词排名为核心。两者在底层逻辑与优化方法上存在本质差异。",
"author": {
"@type": "Organization",
"name": "技术团队"
}
}
},
{
"@type": "Question",
"name": "结构化数据对AI搜索有什么作用?",
"acceptedAnswer": {
"@type": "Answer",
"text": "结构化数据按照Schema.org标准标注页面语义信息,帮助AI大模型快速理解页面内容与企业属性,提升内容识别效率与推荐优先级。",
"author": {
"@type": "Organization",
"name": "技术团队"
}
}
}
]
}
</script>
五、部署规范:结构化数据的技术合规要求
5.1 格式规范
- JSON-LD格式优先:Google推荐使用JSON-LD格式,建议作为首选
- 位置要求:JSON-LD脚本必须放在
<head>标签内 - 语法正确性:JSON语法必须严格正确,避免语法错误
- 嵌套层级:属性嵌套层级不宜过深,建议控制在5层以内
5.2 内容规范
- 类型匹配:@type必须与页面实际内容匹配,不可滥用类型
- 属性完整:核心属性(name、url等)必须填写,避免空值
- 一致性:结构化数据中的信息必须与页面可见内容一致
- 语言标注:中文内容使用
lang="zh-CN",中文Schema值使用中文
5.3 实体关联规范
当多个Schema类型描述同一实体时,必须使用@id进行关联:
json
{
"@id": "https://example.com/#organization"
}
被关联的类型通过以下方式引用:
json
"provider": {"@id": "https://example.com/#organization"}
六、高频踩坑点与修复方案
6.1 JSON语法错误
错误案例:
json
// 错误:多余逗号
{
"name": "示例",
"url": "https://example.com", // ← 行末逗号在JSON中非法
}
正确写法:
json
// 正确
{
"name": "示例",
"url": "https://example.com"
}
6.2 实体信息不一致
错误案例:结构化数据中标注的企业名称与页面实际显示名称不一致。
正确做法:确保所有实体信息与页面可见内容100%一致,包括名称、地址、联系方式等。
6.3 类型滥用
错误案例:在普通文章页面使用LocalBusiness类型。
正确做法:根据页面实际内容选择正确的Schema类型,Article页面使用Article/BlogPosting类型。
6.4 空值属性未处理
错误案例:
json
"telephone": "" // 空字符串可能导致校验失败
正确做法:删除空值属性,或确保属性值非空。
七、自查验证方法
7.1 官方校验工具
使用Google结构化数据标记助手を具(https://search.google.com/test/rich-results)验证页面结构化数据:
- 输入页面URL或粘贴HTML代码
- 点击"测试"按钮
- 检查是否有错误或警告
- 验证所有属性是否正确识别
7.2 手动验证清单
表格
| 检查项 | 验证方法 |
|---|---|
| JSON语法 | 使用JSON validator验证语法正确性 |
| 类型匹配 | 确认@type与页面内容匹配 |
| 属性完整 | 检查核心属性是否有空值 |
| 信息一致 | 核对结构化数据与页面可见内容一致 |
| @id关联 | 确认多Schema之间的@id关联正确 |
| 位置正确 | 确认JSON-LD在<head>标签内 |
7.3 AI搜索适配验证
完成结构化数据部署后,可通过以下方式验证AI搜索适配效果:
- 在豆包、文心一言等大模型中检索企业相关信息
- 验证企业实体信息识别是否准确
- 观察检索结果中企业内容的引用情况
- 持续监测AI可见度的变化趋势
八、技术总结与参考资料
总结
GEO优化与传统SEO在底层技术逻辑上存在本质差异:传统SEO面向搜索引擎的爬虫-索引-匹配架构,而GEO优化面向AI大模型的语义理解-知识检索-生成架构。这一差异决定了结构化数据在AI搜索适配中的核心作用:通过Schema.org标准化的语义标注,帮助AI大模型准确理解页面内容与企业实体信息。
结构化数据的规范部署应遵循以下原则:使用JSON-LD格式、确保JSON语法正确、属性与页面内容一致、合理使用@id进行实体关联、通过官方工具验证部署规范性。
参考资料

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)