从“单层“到“深度“:多层感知机,开启深度学习之旅!
上一篇我们讲了线性神经网络,包括线性回归和softmax回归。它们都是单层神经网络,就像只有一层的"小网兜",虽然能捞些简单的鱼,但遇到复杂的情况就力不从心了。今天,我们要给这个网兜多加几层,编织成一张真正的"深度大网"——多层感知机(MLP)!
深度学习的"深度",就藏在这层层叠叠的网络结构里。而多层感知机,就是这张大网最基础的编织方式——掌握了它,你就摸到了深度学习的核心脉络。
今天,我们会用最通俗的语言拆解多层感知机,还会帮你避开过拟合、欠拟合这两个深度学习最常见的陷阱,再教你权重衰减、Dropout这两招防身术,最后用一个真实的Kaggle房价预测项目,把所有知识编织成一张完整的知识网!
一、多层感知机:从"小网兜"到"深度大网"
📊 与上一篇的对比:单层 vs 多层
还记得上一篇我们用线性神经网络(单层)来做Fashion-MNIST分类吗?让我们先对比一下:
+----------+------------------------+---------------------------+
| 内容 | 上一篇(线性神经网络) | 这一篇(多层感知机) |
+----------+------------------------+---------------------------+
| 网络结构 | 只有1层(输入→输出) | 有3层(输入→隐藏→输出) |
| 隐藏层 | 无 | 有(256个神经元) |
| 激活函数 | 无 | 有(ReLU) |
| 预期精度 | ~85% | ~88-90%(更高!) |
| 能力 | 只能学习线性关系 | 可以学习非线性关系 |
+----------+------------------------+---------------------------+
线性神经网络虽然简单,但它有一个致命的短板:只能捕捉直线型的关系!但现实世界中,很多事情都不是"一条直线走到底"的。
1. 为什么需要隐藏层:线性模型的局限
举个简单的例子:假设我们想根据体温预测健康风险。
- 体温高于37℃:温度越高,风险越大
- 体温低于37℃:温度越高,风险越小
这就是一个非线性关系!不是一条直线能说清楚的!线性模型只会一根筋地认为"体温越高,风险越大"或者"体温越高,风险越小",根本无法理解这种"中间好,两头糟"的关系。
再比如图像分类:一个像素是不是重要,得看它周围是什么——这种"看上下文"的能力,线性模型也没有。
怎么破?加几层"过滤网"——也就是隐藏层!
2. 隐藏层:神经网络的"过滤层"
多层感知机(MLP)的结构就像一个"多层过滤网":
-
输入层:原材料:就是我们的特征(比如图片像素)
-
隐藏层:在中间,负责"思考"和"提取特征"(通俗讲就是:一层层过滤、提炼、加工)
-
输出层:最终的产品(比如预测结果)
最重要的一点:每一层过滤之后,都得加个"激活开关"!(隐藏层后面必须加激活函数!)不然不管加多少层,都是白费功夫——因为直线+直线还是直线,变不出新花样来!(线性变换的线性变换还是线性的)
3. 激活函数:让网络"活"起来!
激活函数(Activation Function)就是给网络加入非线性的关键!没有它,多层感知机就退化成线性回归了。
常见的激活函数有三个:
(1)ReLU:最常用的激活函数!
ReLU(Rectified Linear Unit,修正线性单元)是目前最流行的激活函数,因为它简单又好用!
通俗理解:把负数变成0,正数保持不变。
让我们用代码画出来看看:
import torch
import matplotlib.pyplot as plt
# 1. 创建x轴数据:从-8到8,每隔0.1取一个点
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
# 2. 计算ReLU:把x代入ReLU函数
y = torch.relu(x)
# 3. 画图
# .detach()是因为x需要梯度,画图时不需要,所以"分离"出来
plt.plot(x.detach(), y.detach())
plt.xlabel('x') # x轴标签
plt.ylabel('relu(x)') # y轴标签
plt.show() # 显示图片你会看到:
- 当x < 0时,ReLU(x) = 0(是一条横线)
- 当x ≥ 0时,ReLU(x) = x(是一条45度的斜线)
为什么ReLU这么好用?
- 计算简单,速度快
- 缓解梯度消失问题(后面会讲)
- 让网络变得稀疏(很多神经元输出为0)
(2)Sigmoid:把输出压缩到0-1之间
Sigmoid函数能把任意实数压缩到0和1之间:
以前常用在二分类问题的输出层,但现在在隐藏层用得少了。
(3)Tanh:把输出压缩到-1到1之间
Tanh(双曲正切)函数能把任意实数压缩到-1和1之间:
4. 多层感知机的计算过程:通俗理解
别被数学符号吓住!其实多层感知机的计算过程很简单,就像流水线加工:
假设我们用MLP来识别图片(Fashion-MNIST):
第一步:原材料→第一层加工
- 原材料:图片像素(784个数字)
- 加工:和权重W1相乘 + 偏置b1 → 然后过ReLU激活函数(把负数变成0)
- 产出:隐藏层的256个神经元输出
第二步:第一层→第二层加工
- 原材料:刚才的256个神经元输出
- 加工:和权重W2相乘 + 偏置b2
- 产出:最终的10个输出(对应10个类别)
用简单的话翻译数学公式:
如果非要用数学写出来(其实不用记,理解就行):
:输入(图片像素)
:第一层的权重和偏置
:隐藏层输出
:第二层的权重和偏置
:最终输出
如果是分类问题,输出层后面还要加softmax(变成概率)。
🎯 通用近似定理:神经网络是"万能函数"
这里有个很牛的定理:只要有足够多的隐藏神经元,一个单隐藏层的MLP就能近似任意函数!
通俗理解:
- 就像给你足够多的乐高积木,你能拼出任何形状
- 就像C语言能写任何程序——但写得好不好就是另一回事了
- 理论上,只要神经元够多,MLP能学会任何规律!
但注意:这只是"理论上",实际中我们还是需要合理设计网络结构!
二、多层感知机的从零开始实现:手搭一个深度网络!
光说不练假把式,我们来用PyTorch从零实现一个多层感知机。和上一篇的单层网络相比,我们只需要多加一个隐藏层和激活函数!
🆚 与上一篇代码的对比:
上一篇(单层):
# 只有一层:输入→输出
net = nn.Sequential(nn.Linear(784, 10))这一篇(多层):
# 有三层:输入→隐藏→输出
net = nn.Sequential(
nn.Linear(784, 256), # 多了这一层!
nn.ReLU(), # 多了激活函数!
nn.Linear(256, 10)
)就这么简单!我们开始吧!
import torch
from torch import nn
from d2l import torch as d2l
# ------------------------------------------------------
# 1. 加载数据:Fashion-MNIST数据集(10类服饰)
# ------------------------------------------------------
batch_size = 256 # 每批256张图片
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# ------------------------------------------------------
# 2. 初始化模型参数:我们手搭的网有3层
# ------------------------------------------------------
# 定义各层的维度:
# - 输入层:784个神经元(28×28像素展平)
# - 隐藏层:256个神经元(我们自己定的超参数)
# - 输出层:10个神经元(对应10个类别)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# 输入层→隐藏层的权重和偏置
# randn:随机初始化,×0.01让初始值小一点,避免梯度爆炸
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens))
# 隐藏层→输出层的权重和偏置
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs))
# 把所有参数放在一个列表里,方便后续优化
params = [W1, b1, W2, b2]
# ------------------------------------------------------
# 3. 定义激活函数:ReLU(自己写一个)
# ------------------------------------------------------
def relu(X):
a = torch.zeros_like(X) # 创建一个和X形状一样的全0张量
return torch.max(X, a) # 取X和0中较大的那个(就是把负数变成0)
# ------------------------------------------------------
# 4. 定义模型:前向传播的计算过程
# ------------------------------------------------------
def net(X):
# 第一步:把图片展平(28×28 → 784)
X = X.reshape((-1, num_inputs))
# 第二步:计算隐藏层(输入→隐藏+ReLU)
H = relu(X @ W1 + b1) # @是矩阵乘法
# 第三步:计算输出层(隐藏→输出)
return H @ W2 + b2
# ------------------------------------------------------
# 5. 损失函数:分类问题用交叉熵
# ------------------------------------------------------
loss = nn.CrossEntropyLoss(reduction='none')
# ------------------------------------------------------
# 6. 训练:开始"织网"!
# ------------------------------------------------------
num_epochs, lr = 10, 0.1 # 训练10轮,学习率0.1
updater = torch.optim.SGD(params, lr=lr) # 优化器用SGD
# 训练一个epoch(用完全部训练数据一次)
def train_epoch(net, train_iter, loss, updater):
metric = d2l.Accumulator(3) # 用来累加:损失总和、正确数、样本总数
for X, y in train_iter:
l = loss(net(X), y) # 1. 前向传播,算损失
updater.zero_grad() # 2. 梯度清零
l.mean().backward() # 3. 反向传播,算梯度
updater.step() # 4. 更新参数
# 记录指标
metric.add(float(l.sum()), d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]
# 完整训练函数
def train(net, train_iter, test_iter, loss, num_epochs, updater):
for epoch in range(num_epochs):
# 训练一轮
train_metrics = train_epoch(net, train_iter, loss, updater)
# 在测试集上评估精度
test_acc = d2l.evaluate_accuracy(net, test_iter)
# 打印结果
print(f'epoch {epoch + 1}, 训练损失: {train_metrics[0]:.3f}, 训练精度: {train_metrics[1]:.3f}, 测试精度: {test_acc:.3f}')
# 开始训练!
train(net, train_iter, test_iter, loss, num_epochs, updater)你看!虽然加了一个隐藏层,但核心逻辑还是一样的——前向传播算损失,反向传播算梯度,然后更新参数!
三、多层感知机的简洁实现:框架大法好!
当然,实际工作中我们还是用框架的高级API,更简洁、更高效!
import torch
from torch import nn
from d2l import torch as d2l
# ------------------------------------------------------
# 1. 加载数据:Fashion-MNIST数据集
# ------------------------------------------------------
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# ------------------------------------------------------
# 2. 定义模型:用nn.Sequential搭积木!
# ------------------------------------------------------
net = nn.Sequential(
nn.Flatten(), # 第一层:把图片从28×28展平成784
nn.Linear(784, 256), # 第二层:隐藏层(784输入,256隐藏单元)
nn.ReLU(), # 第三层:ReLU激活函数
nn.Linear(256, 10) # 第四层:输出层(256输入,10输出)
)
# ------------------------------------------------------
# 3. 初始化参数:给网络一个"好的起跑线"
# ------------------------------------------------------
def init_weights(m):
# 如果是线性层,就初始化权重
if type(m) == nn.Linear:
# 用正态分布初始化,标准差0.01
nn.init.normal_(m.weight, std=0.01)
# apply函数会把init_weights应用到net的每一层
net.apply(init_weights)
# ------------------------------------------------------
# 4. 准备训练:损失函数、优化器、超参数
# ------------------------------------------------------
loss = nn.CrossEntropyLoss(reduction='none') # 损失函数用交叉熵
trainer = torch.optim.SGD(net.parameters(), lr=0.1) # 优化器用SGD
num_epochs = 10 # 训练10轮
# ------------------------------------------------------
# 5. 开始训练
# ------------------------------------------------------
def train_epoch(net, train_iter, loss, updater):
metric = d2l.Accumulator(3) # 累加:损失、正确数、样本数
for X, y in train_iter:
l = loss(net(X), y) # 1. 前向传播
updater.zero_grad() # 2. 梯度清零
l.mean().backward() # 3. 反向传播
updater.step() # 4. 更新参数
metric.add(float(l.sum()), d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]
# 训练循环
for epoch in range(num_epochs):
train_metrics = train_epoch(net, train_iter, loss, trainer)
test_acc = d2l.evaluate_accuracy(net, test_iter)
print(f'epoch {epoch + 1}, 训练损失: {train_metrics[0]:.3f}, 训练精度: {train_metrics[1]:.3f}, 测试精度: {test_acc:.3f}')看!简洁实现就是这么清爽——框架帮我们把底层细节都封装好了!
四、模型选择、欠拟合和过拟合:深度学习最常见的两个坑!
现在模型变复杂了,我们面临一个新问题:过拟合!
1. 训练误差和泛化误差:你考100分不代表你真学会了!
- 训练误差:模型在训练集上的误差(就像你做练习题的正确率)
- 泛化误差:模型在新数据上的误差(就像你期末考试的成绩)
我们的目标是:泛化误差小,而不是训练误差小!
举个通俗的例子:
- 你把练习题的答案都背下来了(训练误差0),但考试遇到新题就不会(泛化误差很大)——这就是过拟合
- 你连练习题都不会做(训练误差很大),考试肯定也考不好——这就是欠拟合
2. 模型选择:验证集是你的"模拟考试"
怎么选择模型?我们不能用测试集来选,不然就相当于"提前看了期末考试题"!
正确的做法是:把数据分成三份
- 训练集:用来训练模型(做练习题)
- 验证集:用来选择模型和超参数(模拟考试)
- 测试集:用来最终评估(期末考试)
如果数据太少,用不了验证集怎么办?用K折交叉验证:
- 把数据分成K份
- 每次用K-1份训练,1份验证
- 重复K次,取平均
3. 欠拟合还是过拟合?
- 欠拟合:训练误差大,验证误差也大——模型太简单,学不会
- 过拟合:训练误差小,验证误差大——模型太复杂,死记硬背了
通俗比喻:
- 欠拟合:小学生连乘法表都没背会
- 过拟合:把答案连题号一起背,换个顺序就不会
4. 多项式回归:一个直观的例子
我们用多项式回归来直观感受一下欠拟合和过拟合:
import torch
from torch import nn
from d2l import torch as d2l
# ------------------------------------------------------
# 1. 生成数据:真实模型是3阶多项式
# ------------------------------------------------------
max_degree = 20 # 我们准备的多项式特征最高到20阶
n_train, n_test = 100, 100 # 训练集100个样本,测试集100个样本
# 真实的权重:只有前4个参数有用(0阶到3阶)
true_w = torch.zeros(max_degree) # 先初始化一个全0的长向量
true_w[0:4] = torch.tensor([5, 1.2, -3.4, 5.6]) # 真实权重:5 + 1.2x - 3.4x² + 5.6x³
# 生成x(特征)
features = torch.randn((n_train + n_test, 1))
# 生成多项式特征:x, x², x³, ..., x^20
poly_features = torch.pow(features, torch.arange(max_degree).reshape(1, -1))
# 生成y(标签):用真实模型计算 + 加一点噪声
labels = poly_features @ true_w
labels += torch.randn(labels.shape) * 0.1 # 噪声让问题更真实
# ------------------------------------------------------
# 2. 拆分训练集和测试集
# ------------------------------------------------------
train_features, test_features = poly_features[:n_train, :], poly_features[n_train:, :]
train_labels, test_labels = labels[:n_train], labels[n_train:]
# ------------------------------------------------------
# 3. 定义训练函数
# ------------------------------------------------------
def train(train_features, test_features, train_labels, test_labels, num_epochs=400):
loss = nn.MSELoss(reduction='none') # 损失函数用均方误差
input_shape = train_features.shape[-1] # 输入特征数
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False)) # 线性模型
batch_size = min(10, train_labels.shape[0])
# 加载数据
train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)), batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)), batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01) # 优化器用SGD
# 训练循环
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad() # 梯度清零
l = loss(net(X), y) # 前向传播
l.mean().backward() # 反向传播
trainer.step() # 更新参数
# 每20轮打印一次损失
if epoch % 20 == 0:
train_l = d2l.evaluate_loss(net, train_iter, loss)
test_l = d2l.evaluate_loss(net, test_iter, loss)
print(f'epoch {epoch}, 训练损失: {train_l:.3f}, 测试损失: {test_l:.3f}')
# ------------------------------------------------------
# 4. 实验1:用3阶多项式拟合(和真实模型一样)
# ------------------------------------------------------
print('=== 3阶多项式拟合(正好) ===')
train(train_features[:, :4], test_features[:, :4], train_labels, test_labels)
# ------------------------------------------------------
# 5. 实验2:用1阶多项式拟合(太简单,欠拟合)
# ------------------------------------------------------
print('\n=== 1阶多项式拟合(欠拟合) ===')
train(train_features[:, :1], test_features[:, :1], train_labels, test_labels)
# ------------------------------------------------------
# 6. 实验3:用20阶多项式拟合(太复杂,过拟合)
# ------------------------------------------------------
print('\n=== 20阶多项式拟合(过拟合) ===')
train(train_features, test_features, train_labels, test_labels)运行后你会看到有趣的现象:
- 3阶多项式:训练损失和测试损失都小——模型刚刚好,既能学习规律又能泛化
- 1阶多项式:训练损失和测试损失都大——模型太简单,连训练集都学不会
- 20阶多项式:训练损失很小,但测试损失很大——模型太复杂,把训练集的噪声都记住了
五、权重衰减:给权重"减负",防止过拟合!
知道了过拟合,我们来看看怎么对付它!第一个神器:权重衰减(Weight Decay)。
1. 高维线性回归:过拟合的重灾区
高维线性回归特别容易过拟合——因为特征太多,参数太多,模型太容易"死记硬背"。
2. 权重衰减的原理:L2正则化
权重衰减的核心思想:让权重不要太大!
怎么实现?在损失函数后面加一个L2正则化项:

其中\lambda是正则化系数,控制权重衰减的强度。
通俗理解:权重太大,损失就会变大——模型就会"自觉"地让权重变小。
3. 从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
# ------------------------------------------------------
# 1. 生成高维线性回归数据(特征多,训练集小=容易过拟合)
# ------------------------------------------------------
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
# 训练集只有20个样本,但有200个特征!这是故意制造的过拟合场景
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
# 生成训练集和测试集
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
# ------------------------------------------------------
# 2. 初始化模型参数
# ------------------------------------------------------
def init_params():
w = torch.normal(0, 1, size=(num_inputs, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
return [w, b]
# ------------------------------------------------------
# 3. 定义L2范数惩罚项(权重衰减的核心)
# ------------------------------------------------------
def l2_penalty(w):
return torch.sum(w.pow(2)) / 2 # L2范数的一半(方便求导)
# ------------------------------------------------------
# 4. 训练函数:带权重衰减
# ------------------------------------------------------
def train(lambd):
w, b = init_params()
net, loss = lambda X: d2l.linreg(X, w, b), d2l.squared_loss
num_epochs, lr = 100, 0.003
for epoch in range(num_epochs):
for X, y in train_iter:
# 关键!:损失 = 原来的损失 + λ × L2惩罚项
l = loss(net(X), y) + lambd * l2_penalty(w)
l.sum().backward() # 反向传播
d2l.sgd([w, b], lr, batch_size) # 更新参数
# 每20轮打印一次损失
if epoch % 20 == 0:
train_l = d2l.evaluate_loss(net, train_iter, loss)
test_l = d2l.evaluate_loss(net, test_iter, loss)
print(f'epoch {epoch}, 训练损失: {train_l:.3f}, 测试损失: {test_l:.3f}')
print('w的L2范数:', torch.norm(w).item())
# ------------------------------------------------------
# 5. 实验1:不用权重衰减(过拟合)
# ------------------------------------------------------
print('=== 不用权重衰减(过拟合) ===')
train(lambd=0)
# ------------------------------------------------------
# 6. 实验2:用权重衰减
# ------------------------------------------------------
print('\n=== 用权重衰减 ===')
train(lambd=3)对比两个实验的结果:
- 不用权重衰减:训练损失很小,但测试损失很大——过拟合了
- 用权重衰减:测试损失变小了,w的L2范数也变小了——模型更"稳健"了!
4. 简洁实现
PyTorch已经帮我们封装好了,直接在优化器里设置weight_decay就行:
import torch
from torch import nn
from d2l import torch as d2l
# ------------------------------------------------------
# 1. 生成高维线性回归数据(和从零实现部分一样)
# ------------------------------------------------------
n_train, n_test, num_inputs, batch_size = 20, 100, 200, 5
true_w, true_b = torch.ones((num_inputs, 1)) * 0.01, 0.05
train_data = d2l.synthetic_data(true_w, true_b, n_train)
train_iter = d2l.load_array(train_data, batch_size)
test_data = d2l.synthetic_data(true_w, true_b, n_test)
test_iter = d2l.load_array(test_data, batch_size, is_train=False)
# ------------------------------------------------------
# 2. 权重衰减简洁实现:直接在优化器里设置weight_decay
# ------------------------------------------------------
def train_concise(wd):
# 定义模型
net = nn.Sequential(nn.Linear(num_inputs, 1))
# 初始化参数
for param in net.parameters():
param.data.normal_()
# 损失函数和超参数
loss = nn.MSELoss(reduction='none')
num_epochs, lr = 100, 0.003
# 关键!:在优化器里设置weight_decay
# 权重衰减只作用在权重上,不作用在偏置上
trainer = torch.optim.SGD([
{"params": net[0].weight, 'weight_decay': wd},
{"params": net[0].bias}], lr=lr)
# 训练循环
for epoch in range(num_epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.mean().backward()
trainer.step()
# 每20轮打印一次
if epoch % 20 == 0:
train_l = d2l.evaluate_loss(net, train_iter, loss)
test_l = d2l.evaluate_loss(net, test_iter, loss)
print(f'epoch {epoch}, 训练损失: {train_l:.3f}, 测试损失: {test_l:.3f}')
print('w的L2范数:', net[0].weight.norm().item())
# 开始训练,wd=3
train_concise(wd=3)六、暂退法(Dropout):让神经元"随机失忆",防止过拟合!
对付过拟合的第二个神器:Dropout(暂退法)!
1. 重新审视过拟合:模型太"聪明"也不好
过拟合的另一个原因:神经元之间的共适应性太强——几个神经元"勾结"在一起,专门记训练数据的某些特征。
Dropout的思想:让神经元随机"失忆"——训练时随机把一些神经元的输出设为0,让它们不能"勾结"!
2. 扰动的稳健性:随机掉几个神经元也没事
Dropout相当于在训练时给网络加入了噪声,让网络变得更"稳健"——随机掉几个神经元也能正常工作。
通俗理解:就像考试前,你不知道会考哪道题,所以你必须全面复习,不能只押题!
3. 实践中的暂退法
- 训练时:随机把一些神经元的输出设为0(通常dropout概率设为0.5)
- 测试时:不用dropout,用所有神经元,但要把输出乘以(1 - dropout概率)
4. 从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
# 定义dropout函数
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X)
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
# 测试dropout
X = torch.arange(16, dtype = torch.float32).reshape((2, 8))
print('X:', X)
print('dropout 0:', dropout_layer(X, 0))
print('dropout 0.5:', dropout_layer(X, 0.5))
print('dropout 1:', dropout_layer(X, 1))
# 定义模型
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
if self.training:
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training:
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
# 训练
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
def train_epoch(net, train_iter, loss, updater):
metric = d2l.Accumulator(3)
for X, y in train_iter:
l = loss(net(X), y)
updater.zero_grad()
l.mean().backward()
updater.step()
metric.add(float(l.sum()), d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]
for epoch in range(num_epochs):
train_metrics = train_epoch(net, train_iter, loss, trainer)
test_acc = d2l.evaluate_accuracy(net, test_iter)
print(f'epoch {epoch + 1}, 训练损失: {train_metrics[0]:.3f}, 训练精度: {train_metrics[1]:.3f}, 测试精度: {test_acc:.3f}')5. 简洁实现
PyTorch已经帮我们封装好了,直接用nn.Dropout层就行:
import torch
from torch import nn
from d2l import torch as d2l
# 1. 加载数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 2. 定义模型
dropout1, dropout2 = 0.2, 0.5
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(dropout1), # 第一个dropout层
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(dropout2), # 第二个dropout层
nn.Linear(256, 10)
)
# 3. 初始化参数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
# 4. 训练
num_epochs, lr = 10, 0.5
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
def train_epoch(net, train_iter, loss, updater):
metric = d2l.Accumulator(3)
for X, y in train_iter:
l = loss(net(X), y)
updater.zero_grad()
l.mean().backward()
updater.step()
metric.add(float(l.sum()), d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[2], metric[1] / metric[2]
for epoch in range(num_epochs):
train_metrics = train_epoch(net, train_iter, loss, trainer)
test_acc = d2l.evaluate_accuracy(net, test_iter)
print(f'epoch {epoch + 1}, 训练损失: {train_metrics[0]:.3f}, 训练精度: {train_metrics[1]:.3f}, 测试精度: {test_acc:.3f}')七、前向传播、反向传播和计算图:理解深度学习的"引擎"
现在我们来深入理解一下神经网络的训练过程:前向传播和反向传播。
1. 前向传播:从输入到输出
前向传播(Forward Propagation)就是把输入数据喂给网络,一层一层地计算,直到得到输出。
以单隐藏层的MLP为例:
- 输入:
- 隐藏层:
- 输出层:
- 损失:
2. 前向传播计算图:把计算画成图
我们可以把前向传播的计算过程画成一张计算图(Computational Graph),每个节点代表一个计算。正方形表示变量,圆圈表示操作符。 左下角表示输入,右上角表示输出。 注意显示数据流的箭头方向主要是向右和向上的。
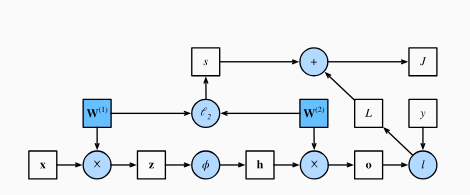
图片来源于《动手学深度学习》
这张图能帮我们理解数据是怎么流动的,也能帮框架自动计算梯度。
3. 反向传播:从损失到梯度
反向传播(Backward Propagation)就是根据计算图,用链式法则从损失开始,反向计算每个参数的梯度。
通俗理解:前向传播是"从前往后算结果",反向传播是"从后往前算每个参数对结果的影响"。
4. 训练神经网络:前向→反向→更新
完整的训练流程:
- 前向传播:计算输出和损失
- 反向传播:计算每个参数的梯度
- 更新参数:用梯度下降更新参数
- 重复:回到步骤1,直到收敛
这就是深度学习的"引擎"!
八、数值稳定性和模型初始化:让训练"稳"起来!
深度网络训练时,经常会遇到两个问题:梯度消失和梯度爆炸。这和数值稳定性、参数初始化密切相关。
1. 梯度消失和梯度爆炸:梯度怎么了?
- 梯度消失(Vanishing Gradients):梯度变得特别小,参数几乎不更新——网络"学不动"了
- 梯度爆炸(Exploding Gradients):梯度变得特别大,参数更新太剧烈——网络"失控"了
举个简单的例子:假设每一层的梯度都乘以0.1,10层之后梯度就是原来的,几乎消失了!
2. 参数初始化:好的开始是成功的一半!
怎么缓解梯度消失和梯度爆炸?好的参数初始化很重要!
常见的初始化方法:
- Xavier初始化:根据输入和输出的维度来设置初始方差
- He初始化:针对ReLU激活函数设计的初始化方法
PyTorch已经帮我们封装好了,直接用就行:
# Xavier初始化
nn.init.xavier_uniform_(m.weight)
# He初始化
nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')九、环境和分布偏移:当训练和测试不一样时
现实中还有一个常见问题:训练数据和测试数据的分布不一样!这叫分布偏移(Distribution Shift)。
1. 分布偏移的类型
- 协变量偏移:输入的分布变了,但输出的条件分布没变
- 概念偏移:输出的条件分布变了
举个例子:
- 你用猫和狗的照片训练模型,但测试时用的是卡通猫和卡通狗——这是协变量偏移
- 你用夏天的数据训练预测穿什么衣服,但冬天测试时,同样的温度需要穿不同的衣服——这是概念偏移
2. 分布偏移的应对方法
- 数据增强:让训练数据更多样化
- 域适应:专门处理分布偏移的技术
- 持续学习:模型能适应新的数据分布
十、实战Kaggle比赛:预测房价!
讲了这么多理论,我们来实战一下!用Kaggle的房价预测数据集,把所有知识串起来。
1. Kaggle:数据科学竞赛平台
Kaggle是一个著名的数据科学竞赛平台,上面有很多真实的数据集和比赛。我们选的是"House Prices: Advanced Regression Techniques"这个比赛。
2. 下载和读取数据集
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
import os
# 我们用d2l提供的数据集
train_data = pd.read_csv(d2l.download('kaggle_house_pred_train'))
test_data = pd.read_csv(d2l.download('kaggle_house_pred_test'))
print(f'训练集形状: {train_data.shape}')
print(f'测试集形状: {test_data.shape}')3. 数据预处理:真实世界的数据很乱!
真实数据很乱,我们需要预处理:
# 把训练集和测试集放在一起预处理
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
# 1. 处理数值特征:标准化
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 缺失值用0填充
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# 2. 处理类别特征:独热编码
all_features = pd.get_dummies(all_features, dummy_na=True)
# 3. 转换为张量
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)4. 训练:用对数损失!
房价预测是回归问题,我们用对数损失,这样更关注相对误差(比如预测100万的房子差10万,和预测1000万的房子差10万,重要性是不一样的)。
# 定义模型
def get_net():
net = nn.Sequential(nn.Linear(train_features.shape[1], 1))
return net
# 对数均方误差损失
def log_rmse(net, features, labels):
# 把小于1的值设为1,防止log(0)
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(nn.MSELoss()(torch.log(clipped_preds), torch.log(labels)))
return rmse.item()
# 训练函数
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate, weight_decay=weight_decay)
loss_func = nn.MSELoss(reduction='none')
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss_func(net(X), y)
l.sum().backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls5. K折交叉验证:小数据集的法宝!
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, 验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k6. 模型选择:调参是个技术活!
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, 平均验证log rmse: {float(valid_l):f}')7. 提交Kaggle预测!
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
print(f'训练log rmse: {float(train_ls[-1]):f}')
# 预测
preds = net(test_features).detach().numpy()
# 保存提交文件
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)恭喜你!你已经完成了一个完整的Kaggle实战项目!
十一、小结:把知识编织成网
📊 与上一篇的最终对比
从第一篇到现在,我们的进步:
+------------+--------------------+------------------------+------------------------+
| 内容 | 第一篇(预备知识) | 第二篇(线性神经网络) | 这一篇(多层感知机) |
+------------+--------------------+------------------------+------------------------+
| 网络层数 | 无(只是讲概念) | 1层(线性) | 2-3层(深度) |
| 隐藏层 | - | 无 | 有 |
| 激活函数 | - | 无 | 有(ReLU等) |
| 能力 | 理解预备知识 | 只能学线性关系 | 可以学非线性关系 |
| 解决的问题 | - | 简单分类/回归 | 复杂分类/回归 + 过拟合 |
+------------+--------------------+------------------------+------------------------+
知识网络图:
-
多层感知机(MLP):
- 隐藏层 + 激活函数 = 深度网络的起点
- ReLU、Sigmoid、Tanh——三个好用的"非线性开关"
- 只要神经元够多,单隐藏层就能"记住"任意函数
-
过拟合与欠拟合:
- 过拟合:在训练集上"考满分",在测试集上"考砸"
- 欠拟合:在训练集上都"考不及格"
- 验证集和K折交叉验证——帮你找到"正好"的模型
-
正则化两大法宝:
- 权重衰减:给权重"上紧箍咒",不让它太"放飞自我"
- Dropout:让神经元随机"请假",避免它们"抱团作弊"
-
深度学习的引擎:
- 前向传播:数据从输入流到输出
- 反向传播:梯度从输出流回输入
- 梯度下降:顺着梯度的反方向,一步步"下山"
-
让训练更稳定:
- 梯度消失/爆炸——深度网络的"隐形杀手"
- 好的参数初始化——给网络一个"好的起跑线"
给初学者的建议:
- 不要被"深度"吓住——它就是多层简单逻辑的叠加
- 遇到过拟合别慌——试试权重衰减和Dropout
- 验证集是你的"好朋友"——别让测试集"剧透"
- 数据少就用K折——充分利用每一个样本
- 初始化很关键——好的开始往往事半功倍
写在最后
多层感知机就像深度学习的"十字绣"——看似复杂的图案,其实是由一个个简单的针脚(神经元)编织而成。后面的卷积神经网络、循环神经网络、Transformer,本质上都是这门手艺的延伸——只是用了更精巧的编织方式。
下一篇,我们将学习卷积神经网络(CNN)——计算机视觉领域的"织网大师"!敬请期待~
如果有疑问,欢迎留言交流,让我们一起编织深度学习的知识网络!
(注:文档部分内容参考《动手学深度学习》)
动手学深度学习多层感知机: https://zh.d2l.ai/chapter_multilayer-perceptrons/index.html

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 25
25 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)