efficientteacher 高效教师:面向 YOLOv5 的半监督目标检测
·
一、论文信息
- 论文题目:Efficient Teacher: Semi-Supervised Object Detection for YOLOv5
- 论文作者:Bowen Xu Mingtao Chen Wenlong Guan Lulu Hu
- 发表单位:Alibaba Group
二、研究背景
尽管半监督目标检测已经取得巨大进展,但依然有三个关键问题:
- 经典的一阶段锚框检测器因采用多锚框机制,使预测框极为密集,导致监督训练过程中正负样本不均衡以及伪标签质量差
- 伪标签不一致问题严重
当前主流方法采用师生模型互相学习的模式,教师模型生成的伪标签数量和质量波动大,低质量伪标签还会误导训练更新 - 现有方法精度与效率不可兼得
三、本文创新点
- 首次将SSOD成功用于YOLOv5,填补一阶段锚框检测器半监督检测空白
- 提出Dense Dector:融合YOLOv5稠密采样与目标置信度分支,提升伪标签质量
- 设计Pseudo Label Assigner:双阈值划分可靠/不可靠伪标签,用软损失缓解伪标签不一致问题
- 提出Epoch Adaptor:结合领域适应与分布适应,实现稳定高效端到端训练
四、具体方法
4.1 框架概述
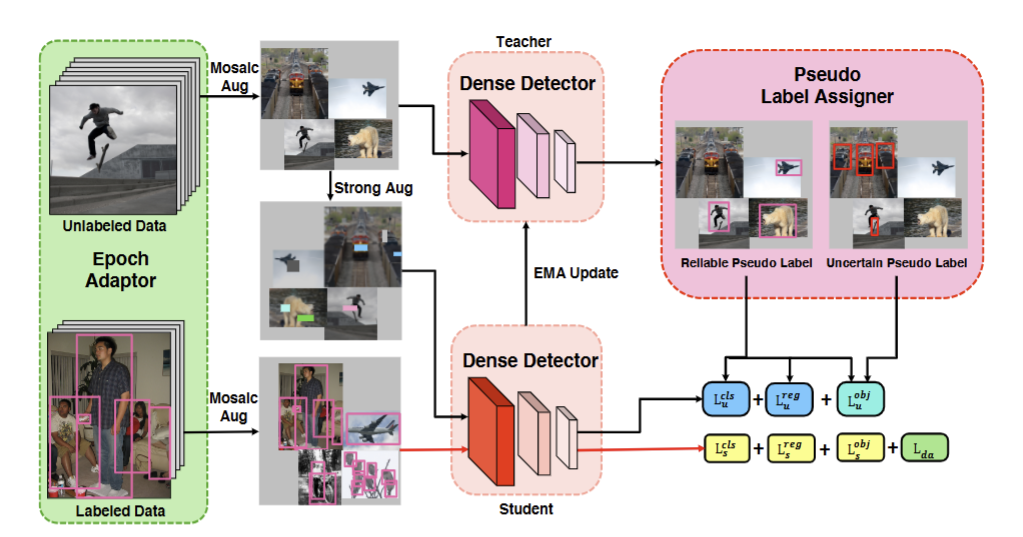
- Epoch Adaptor(数据与训练调度器)
- 有标注数据:经过Mosaic增强后输入学生模型,提供监督信号
- 无标注数据:用Mosaic增强后再做一次强增强,分别送入教师模型和学生模型
- 教师学生双Dense Dector
- Dense Dector:本文提出的核心一阶段锚框检测器,基于RetinaNet融合YOLOv5优化的高效检测模型
- 学生模型:接收有/无标注数据,负责学习检测任务
- 教师模型:学生通过指数移动平均更新权重,不参与反向传播,只生成伪标签
- Pseudo Label Assigner(伪标签生成器)
教师模型为无标注数据生成检测结果后,这里会进行处理:
- 置信度高于高阈值的伪标签直接作为强监督信号参与分类损失 LuclsL_{u}^{cls}Lucls、回归损失 LuregL_{u}^{reg}Lureg 和目标置信度损失 LuobjL_{u}^{obj}Luobj
- 置信度介于高低阈值的检测框,不参与分类和回归损失,仅用目标置信度损失做软监督,避免错误标签影响训练
- 两个损失函数
- 无标签损失函数:来自可靠伪标签,包括分类损失、框回归损失、目标置信度
- 有标注数据损失:来自人工标注,LsclsL_{s}^{cls}Lscls、LsregL_{s}^{reg}Lsreg、LsobjL_{s}^{obj}Lsobj,再加上 LdaL_{da}Lda(领域对抗损失,缩小有标/无标数据分布差异)
4.2 Dense Dector密集检测器
- YOLO v5之所以效果好,是因为它的“稠密输入”、更简单的结构、目标置信度分支。所以改造了RetinaNet变成了Dense Dector:
- FPN特征金字塔输出从5层减到3层,降低计算量
- 取消检测头权重共享,让每个检测头更灵活,精度更高
原因:
不同尺度特征差异太大,不能共用一套参数;一阶段检测器的预测很密集,正负样本分布不平衡,并且对框回归、置信度、分类都很敏感,只有每一层用不同标准才能学习的更好 - 输入分辨率从1333降到640,大幅提速更适合工业场景
- 新增目标置信度(objectness,衡量框位置质量)分支,直接衡量框的质量
- 但是同时发现,一阶段和二阶段检测器的处理标签逻辑不同,效果不好,所以催生出后面的伪标签分配器(PLA)
4.3 Pseudo Label Assigner(PLA伪标签分配器)
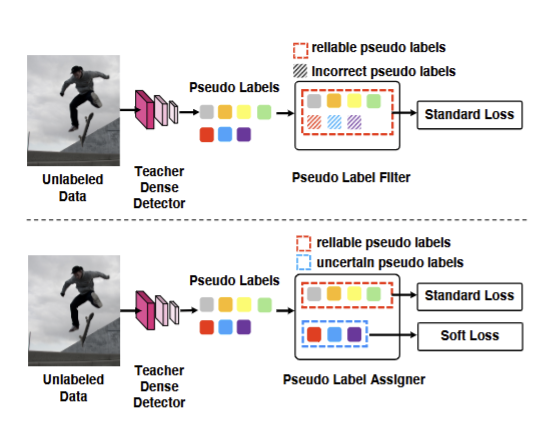
传统伪标签过滤方法只有一个阈值,导致训练过程中错误预测的伪标签分数也会变高,导致错误标签被当成正确的训练,导致偏差。
- 核心改进:双阈值+三类伪标签处理
- 可靠伪标签,分类+回归+目标置信度损失
- 不确定伪标签,只做目标置信度软损失,不强行分类/回归损失
- 背景/低质量伪标签,只做目标置信度的背景损失
- 关键点:用软损失处理不确定的伪标签
- 对框准但类别不确定的伪标签(目标置信度 > 0.99):额外做回归损失,先把框的位置优化好,等模型更准了再判断类别。
- 对类别分数高但框不确定的伪标签:只做目标置信度的软损失,让模型自己慢慢判断是不是目标,不强行给硬标签。
- 总损失:L=Ls+λLuL = L_s + \lambda L_uL=Ls+λLu
总损失=有标注损失+无标注损失(带权重λ\lambdaλ)
- LsL_sLs:人工标注图的正常监督损失
- LuL_uLu:无标注图用伪标签的半监督损失
- λ=3.0\lambda=3.0λ=3.0:让模型更重视无标注数据
- 有标注数据损失 LsL_sLs
Ls=∑h,w(CE(X(h,w)cls,Y(h,w)cls)+CIoU(X(h,w)reg,Y(h,w)reg)+CE(X(h,w)obj,Yh,wobj)) L_s = \sum_{h,w} \left( CE\left( X_{(h,w)}^{cls}, Y_{(h,w)}^{cls} \right) + CIoU\left( X_{(h,w)}^{reg}, Y_{(h,w)}^{reg} \right) + CE\left( X_{(h,w)}^{obj}, Y_{h,w}^{obj} \right) \right) Ls=h,w∑(CE(X(h,w)cls,Y(h,w)cls)+CIoU(X(h,w)reg,Y(h,w)reg)+CE(X(h,w)obj,Yh,wobj))
- 有标注损失=分类损失+框回归损失+目标置信度损失
- 目标置信度损失:交叉熵损失,衡量预测的 “目标存在概率” 和真实标注的匹配度,用来区分前景和背景。
- 无标注总损失 LuL_uLu
Lu=Lucls+Lureg+Luobj L_u = L_{u}^{cls} + L_{u}^{reg} + L_{u}^{obj} Lu=Lucls+Lureg+Luobj
- 无标注损失=分类损失+回归损失+目标置信度损失
- 给无标注图用伪标签监督,但是看分数决定算哪些部分
- 无标注分类损失
Lucls=∑h,w(1{p(h,w)≥τ2}CE(X(h,w)cls,Y^(h,w)cls)) L_{u}^{cls} = \sum_{h,w} \left( \mathbb{1}_{\{p_{(h,w)} \ge \tau_2\}} CE\left( X_{(h,w)}^{cls}, \hat{Y}_{(h,w)}^{cls} \right) \right) Lucls=h,w∑(1{p(h,w)≥τ2}CE(X(h,w)cls,Y^(h,w)cls))
- Y:是教师模型生成的伪标签类别
- 只有分数大于等于高阈值才计算分类损失
- 只相信高分可靠伪标签,防止学错类别
- 无标注回归损失
Lureg=∑h,w(1{p(h,w)≥τ2 or obj(h,w)>0.99}CIoU(X(h,w)reg,Y^(h,w)reg)) L_{u}^{reg} = \sum_{h,w} \left( \mathbb{1}_{\{p_{(h,w)} \ge \tau_2 \text{ or } obj_{(h,w)} > 0.99\}} CIoU\left( X_{(h,w)}^{reg}, \hat{Y}_{(h,w)}^{reg} \right) \right) Lureg=h,w∑(1{p(h,w)≥τ2 or obj(h,w)>0.99}CIoU(X(h,w)reg,Y^(h,w)reg))
- 分数高于高阈值/目标置信度>0.99(框位置特别准)任意满足其一就计算回归损失
- 解决大量不确定伪标签“框不准”的问题
- 无标注目标置信度损失
Luobj=∑h,w(1{p(h,w)≤τ1}CE(X(h,w)obj,0)+1{p(h,w)≥τ2}CE(X(h,w)obj,Y^(h,w)obj)+1{τ1<p(h,w)<τ2}CE(X(h,w)obj,obj^(h,w))) L_{u}^{obj} = \sum_{h,w} \left( \mathbb{1}_{\{p_{(h,w)} \le \tau_1\}} CE\left( X_{(h,w)}^{obj}, 0 \right) + \mathbb{1}_{\{p_{(h,w)} \ge \tau_2\}} CE\left( X_{(h,w)}^{obj}, \hat{Y}_{(h,w)}^{obj} \right) + \mathbb{1}_{\{\tau_1 < p_{(h,w)} < \tau_2\}} CE\left( X_{(h,w)}^{obj}, \hat{obj}_{(h,w)} \right) \right) Luobj=h,w∑(1{p(h,w)≤τ1}CE(X(h,w)obj,0)+1{p(h,w)≥τ2}CE(X(h,w)obj,Y^(h,w)obj)+1{τ1<p(h,w)<τ2}CE(X(h,w)obj,obj^(h,w)))
- 按分数分三段处理:
分数<低阈值:强制做背景,目标=0
分数>高阈值:正常监督训练
分数居中:用软标签学习 - 软标签:不判断对错,用软损失学习
4.4 Epoch Adaptor训练周期适配器
- PLA 解决了半监督目标检测(SSOD)中的伪标签不一致问题,但训练的稳定性和效率仍是挑战。为此,本文提出 Epoch Adaptor(EA),它结合了 ** 领域适应(Domain Adaptation)和分布适应(Distribution Adaptation)** 技术,实现快速且稳定的 SSOD 训练。目标是:
- 缩小有标注数据和无标注数据的分布差异
- 在每个训练轮次动态估计伪标签的阈值
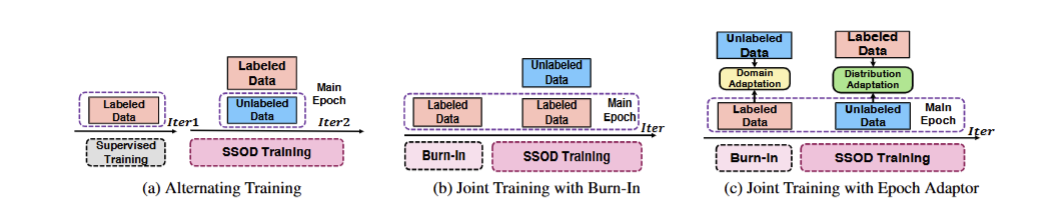
- (a)交替训练:先只用有标注数据做监督训练,再切换到无标注数据做半监督训练,来回交替。
缺点:预热阶段只看有标注数据,很容易过拟合,泛化能力差;训练模式来回切换,不稳定,伪标签更新也容易出问题 - (b)带预热的联合训练:先只用有标注数据做 Burn-In 预热,然后进入主训练阶段,有标注和无标注数据一起训练。
训练不用来回切模式,流程更稳定。
缺点:预热阶段还是只看有标注数据,过拟合问题没解决;有标 / 无标数据分布差异没处理好,伪标签阈值固定,适配性差。 - (c)带 Epoch Adaptor 的联合训练:
-
- Domain Adaptation(领域适应)在预热阶段就把无标注数据和有标注数据一起喂给模型,通过梯度反转层(GRL)让模型分不清数据来源,缩小两类数据的分布差异,缓解过拟合。
-
- Distribution Adaptation(分布适应)在主训练阶段,根据当前训练轮次和类别分布,动态计算伪标签的高低阈值,让阈值能跟着模型和数据分布一起变化,不用人工固定调参。
- 领域适应损失函数(训练一个领域分类器,可以区分输入是有无标注数据)
Lda=−∑h,w[Dlogp(h,w)+(1−D)log(1−p(h,w))] L_{da} = -\sum_{h,w} \left[ D \log p_{(h,w)} + (1-D) \log\left(1 - p_{(h,w)}\right) \right] Lda=−h,w∑[Dlogp(h,w)+(1−D)log(1−p(h,w))]
- p(h,w)p_{(h,w)}p(h,w):领域分类器的输出;
- D=0D=0D=0:有标注数据; D=1D=1D=1:无标注数据
- 使用了梯度反转层(GRL):领域分类器正常做梯度下降训练,而在反向传播通过 GRL 层时,梯度符号被反转,以此优化基础网络,让它无法区分数据来源。
- 预热阶段的监督损失
Ls=∑h,w(CE(X(h,w)cls,Y(h,w)cls)+CIoU(X(h,w)reg,Y(h,w)reg))+CE(X(h,w)obj,Yh,wobj)+λLda \begin{aligned} L_{s} &= \sum_{h,w} \left( CE\left( X_{(h,w)}^{cls}, Y_{(h,w)}^{cls} \right) + CIoU\left( X_{(h,w)}^{reg}, Y_{(h,w)}^{reg} \right) \right) \\ &+ CE\left( X_{(h,w)}^{obj}, Y_{h,w}^{obj} \right) + \lambda L_{da} \end{aligned} Ls=h,w∑(CE(X(h,w)cls,Y(h,w)cls)+CIoU(X(h,w)reg,Y(h,w)reg))+CE(X(h,w)obj,Yh,wobj)+λLda
λ\lambdaλ 是控制领域适应损失贡献的超参数,本文设为 0.1。让检测器在预热阶段就看到无标注数据,能增强模型的表达能力。
- LsL_sLs = 分类损失 + 回归损失 + 目标置信度损失
- 预热阶段就把无标注数据加进来,让模型一开始就适应无标注数据的分布
- 现有方法是利用有标签数据的标签分布先验来计算阈值,但无法用于本文Dense Detector,因为Mosaic增强会破坏标签分布比例。所以本文基于 LabelMatch 的重分布方法,实现了分布适应:
在第k轮训练中,高低阈值由此公式确定:
τ1k=Pck[nck⋅NuNl] \tau_{1}^{k} = P_{c}^{k} \left[ n_{c}^{k} \cdot \frac{N_{u}}{N_{l}} \right] τ1k=Pck[nck⋅NlNu]
τ2k=Pck[α%⋅nck⋅NuNl], \tau_{2}^{k} = P_{c}^{k} \left[ \alpha\% \cdot n_{c}^{k} \cdot \frac{N_{u}}{N_{l}} \right], τ2k=Pck[α%⋅nck⋅NlNu],
- 可靠率 α\alphaα 在所有实验中设为 60:在第ccc类的伪标签分数列表中,取第α%⋅nck⋅NuNl\alpha\% \cdot n_{c}^{k} \cdot \frac{N_{u}}{N_{l}}α%⋅nck⋅NlNu个位置的分数作为阈值
- PckP_{c}^{k}Pck:第kkk轮中第ccc类的伪标签分数列表
- NlN_{l}Nl:有标注数据的数量
- NuN_{u}Nu:无标注数据的数量
- nckn_{c}^{k}nck:EA在第kkk轮统计的第ccc类真实标注的数量
五、实验
5.1 总体对比
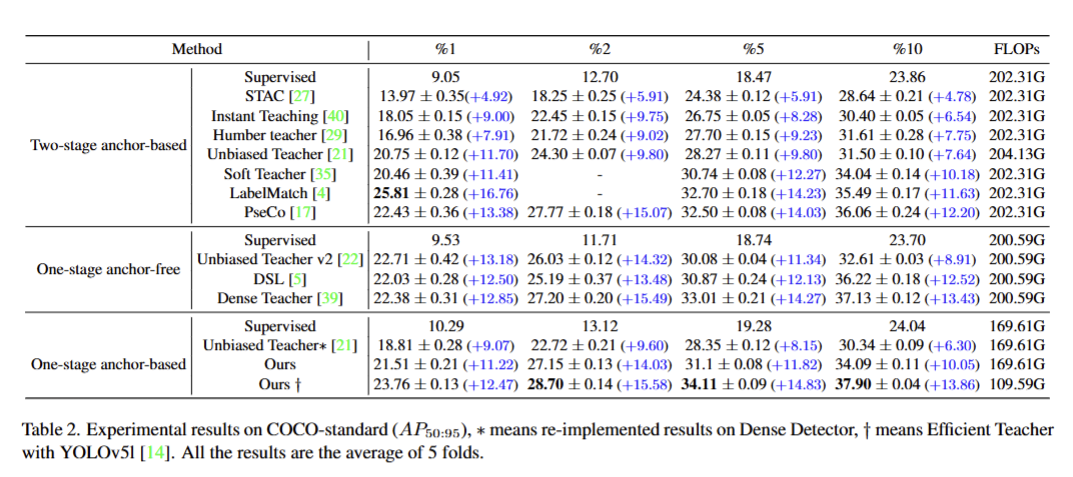
- 论文在COCO-standard半监督目标检测任务上的对比实验结果表,核心是展示本文方法(Efficient Teacher)在不同标注比例下的性能表现,以及和其他主流方法的对比。
- 相对于纯监督基线的提升幅度
- FLOPs:模型的计算量(越低越好,代表推理更快)
- 结论:本文方法有效性;性能与效率平衡;不同比例的泛化性
5.2 COCO-additional 数据集表现
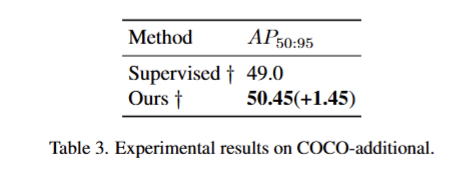
- 论文在 COCO-additional 数据集上的实验结果表,展示了 Efficient Teacher 方法在全标注场景下的性能提升。
- 从 IoU=0.5 到 0.95,每隔 0.05 取一个阈值,把这 10 个 AP 加起来取平均 , 就是 AP₅₀:₉₅
- 即使在全标注数据下,Efficient Teacher 也能带来性能提升
- 这说明论文提出的伪标签分配(PLA)和训练调度(EA)模块,不仅能利用无标注数据,还能通过更优的训练策略,进一步挖掘有标注数据的潜力。
5.3 VOC 数据集
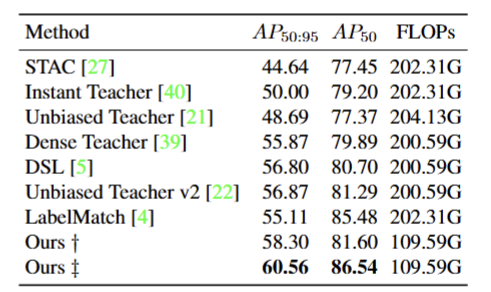
- 论文在VOC 数据集上的对比实验结果表,展示了 Efficient Teacher 方法和主流半监督检测方法的性能对比。
- Ours †:基于 YOLOv5l 的 Efficient Teacher
- Ours ‡:更强配置的 Efficient Teacher
- AP 50:95:严格指标,衡量框位置和分类的综合精度
- AP 50:宽松指标,衡量目标是否被正确识别
- 我们的方法性能领先,效率也高
六、消融实验
6.1 PLA(伪标签分配器)消融实验表
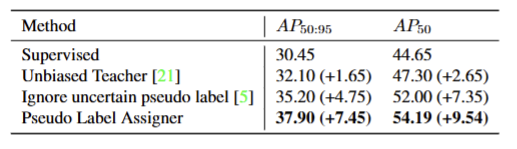
Supervised(纯监督基线)
Unbiased Teacher(传统半监督方法)
Ignore uncertain pseudo label(仅丢弃不确定伪标签)
Pseudo Label Assigner(本文的 PLA)
- 在Dense Detector 上直接套用 Unbiased Teacher 仅提升 1.65 个百分点,说明传统方法在一阶段锚框检测器上适配性很差,验证了论文开头的痛点。
- 相比 Unbiased Teacher,单纯把不确定伪标签直接扔掉,AP 50:95就从 32.10 提升到 35.20,说明 “错误伪标签污染训练” 确实是主要问题。
- 在 “丢弃不确定伪标签” 的基础上,PLA 通过软损失机制利用不确定伪标签,进一步将 AP 从 35.20 提升到 37.90,提升幅度达到 7.45 个百分点。
6.2 固定阈值 VS EA模块动态阈值
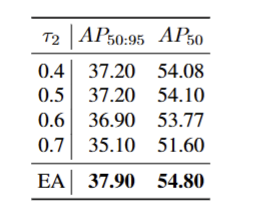
- 固定阈值存在短板,不存在一个固定的阈值可以在不同训练阶段、不同类别效果都很好
- EA动态阈值策略能根据训练过程和数据分布,自动适配最合适的伪标签阈值,避免了固定阈值 “一刀切” 的问题。
6.4 三种半监督训练策略的收敛曲线
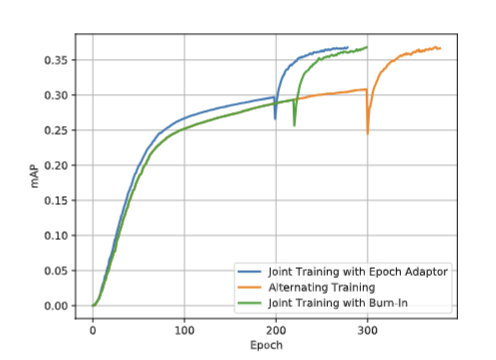
- 各项指标
- 蓝色线:本文方法
- 绿色线:传统联合训练
- 橙色线:交替训练
- 横轴:训练轮次;纵轴:检测精度
- 结论
- 收敛速度:蓝色最快,橙色最慢
- 最终性能:蓝色最高,橙色最低
- 曲线波动:橙色和绿色都有 “掉点”,说明不够稳定

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)