Linux 线程同步硬核解析:从条件变量、阻塞队列到信号量环形队列
上篇热文:Linux线程互斥与互斥锁:从抢票Demo到RAII锁的硬核封装
目录
2.生产者消费者模型:3 种关系、2 种角色、1 个交易场所
3.2为什么pthread_cond_wait必须传入互斥锁?
前言
多线程程序最难的地方,从来不是“创建几个线程”,而是让这些线程在共享资源面前既不互相破坏,又能按照正确的顺序协作。线程同步讨论的正是这个问题:当多个执行流同时存在时,如何让它们安全、有序、高效地访问临界资源。
本文围绕 Linux/POSIX 线程同步中最经典的一条主线展开:条件变量 -> 阻塞队列 -> 生产者消费者模型 -> POSIX 信号量 -> 环形队列生产消费模型。文章会从 API 用法讲到工程模型,再进一步拆到 Linux 内核中的 futex、等待队列与调度行为,力求把“为什么这样写”讲透,而不是停留在“代码应该这样背”。
1.互斥和同步
在多线程程序中,只要多个线程会访问同一份资源,这份资源就是共享资源。如果这份共享资源需要被保护,防止多个线程同时修改导致数据错乱,它就是临界资源。访问临界资源的代码区域,叫临界区。
互斥解决的问题:任何时刻,只允许一个执行流进入临界区。
比如多个线程同时操作std::queue,一个线程在push,另一个线程在pop,如果没有锁,队列内部结构可能被破坏,因此就需要互斥锁pthread_mutex_t保护临界区。
同步解决的问题:在保证数据安全的前提下,让线程按照某种特定顺序访问临界资源。
比如消费者线程访问队列时,发现队列为空。此时就算它拿到了锁,也没有数据可以消费。正确做法不是一直占着CPU空转,而是睡眠等待,直到生产者放入数据后再继续执行。
所以,互斥关注的是“同一时刻谁能进”,同步关注的是“什么时候进”。
- 互斥:保护共享资源的安全性。
- 同步:控制多个线程之间的执行顺序。
生产者消费者模型正是互斥与同步结合得最经典的地方。
2.生产者消费者模型:3 种关系、2 种角色、1 个交易场所
理解生产者消费者模型,可以先抓住一个非常清晰的结构:
3 种关系 2 种角色 1 个交易场所
三种关系分别是:
生产者与生产者:竞争关系,需要互斥消费者与消费者:竞争关系,需要互斥生产者与消费者:既有互斥关系,也有同步关系
两种角色是生产者和消费者。
- 生产者负责生成数据、任务或事件。
- 消费者负责取出并处理这些数据、任务或事件。
一个交易场所是中间缓冲区。
- 常见形式包括阻塞队列、任务队列、环形队列、消息队列等。生产者不直接把数据交给消费者,而是把数据放入这个中间容器;消费者也不直接找生产者要数据,而是从这个容器中取数据。
多个生产者同时写队列,必须互斥,否则可能写乱队列结构。多个消费者同时读队列,也必须互斥,否则可能重复消费同一个元素,或者破坏队头状态。
生产者和消费者之间更复杂。它们访问的是同一个容器,所以有互斥关系;同时,消费者必须在“队列有数据”时才能消费,生产者必须在“队列有空间”时才能生产,所以又存在同步关系。
这就是生产者消费者模型的核心结构:
生产者 -> 中间缓冲区 -> 消费者
它带来的好处非常实际:
解耦:生产者和消费者不直接依赖彼此
并发:多个生产者和多个消费者可以同时工作
削峰填谷:缓冲区可以平衡生产速度和消费速度
日志系统、线程池、网络服务器、异步任务框架、消息队列,本质上都大量使用了这种模型。
3.条件变量:等待“条件成立”的同步工具
条件变量不是锁。它不负责保护共享资源,也不保存业务状态。
条件变量的作用:当某个条件不满足时,让线程睡眠;当其他线程改变条件后,再唤醒等待线程。
3.1条件变量函数
POSIX条件变量的核心接口如下:
初始化
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr);参数:cond:要初始化的条件变量。attr:NULL
销毁
int pthread_cond_destroy(pthread_cond_t *cond);等待条件满足
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex); // 等待条件变量,同时释放互斥锁参数:cond:要在这个条件变量上等待。mutex:互斥量。
唤醒等待
int pthread_cond_signal(pthread_cond_t *cond); // 唤醒至少一个等待线程
int pthread_cond_broadcast(pthread_cond_t *cond); // 唤醒所有等待线程注意:线程真正等待的不是条件变量本身,而是某个由共享数据表达出来的条件。
例如消费者等待的条件是:
!queue.empty()生产者等待的条件是:
queue.size() < capacity条件变量只是“睡眠与唤醒”的工具,真正的条件必须由程序员通过共享状态判断。
因此条件变量必须与互斥锁配合使用:
pthread_mutex_lock(&mutex);
while (条件不满足) {
pthread_cond_wait(&cond, &mutex);
}
访问共享资源;
pthread_mutex_unlock(&mutex);3.2为什么pthread_cond_wait必须传入互斥锁?
这是条件变量最重要的底层逻辑。
先看一个错误设计:
pthread_mutex_lock(&mutex);
while (condition_is_false) {
pthread_mutex_unlock(&mutex);
// 准备等待
pthread_cond_wait(&cond, &mutex);
pthread_mutex_lock(&mutex);
}
pthread_mutex_unlock(&mutex);这段代码看起来合理:条件不满足,先解锁,再等待。但是它有一个致命窗口:
线程释放锁之后,还没有真正进入等待队列之前。
假设消费者发现队列为空,于是释放锁,准备进入等待。就这一瞬间,生产者拿到锁,放入数据,并调用pthread_cond_signal。但此时消费者还没有真正到达条件变量上,所以这个唤醒信号丢失了。随后消费者再进入pthread_cond_wait,它可能永远沉默下去。
这就是丢失唤醒,lost wakeup。
所以POSIX要求pthread_cond_wait同时接收条件变量和互斥锁:
pthread_cond_wait(&cond, &mutex);这个函数内部会原子地完成两件事:
- 把当前线程加入条件变量的等待队列
- 释放调用者持有的mutex
当线程被唤醒后,pthread_cond_wait返回之前,还会重新竞争并获得这把mutex。也就是说:
调用 pthread_cond_wait 前:线程必须已经持有锁
等待期间:锁被自动释放
被唤醒后:线程重新竞争锁
函数返回时:线程已经重新持有锁这就是为什么消费者可以写为:
pthread_mutex_lock(&mutex);
while (queue.empty()) {
pthread_cond_wait(&cond_consumer, &mutex);
}
data = queue.front();
queue.pop();
pthread_mutex_unlock(&mutex);看起来线程是在“拿着锁等待”,实际上进入等待后锁已经被释放,生产者仍可以拿着锁并修改队列。
3.3为什么等待条件必须使用while而不是if
很多初学者会写出这样的代码:
if (queue.empty()) {
pthread_cond_wait(&cond, &mutex);
}这在多线程程序中是不安全的。正确写法必须是:
while (queue.empty()) {
pthread_cond_wait(&cond, &mutex);
}原因有三个。
第一,条件变量允许伪唤醒。也就是说,即使没有线程真正发送信号,等待线程也可能从 pthread_cond_wait 返回。因此返回后必须重新检查条件。
第二,多个线程被唤醒后会竞争同一把锁。假设生产者只放入了一个数据,却调用了 pthread_cond_broadcast 唤醒多个消费者。第一个消费者拿到锁后取走数据,后面的消费者虽然也被唤醒了,但它们拿到锁时队列可能已经空了。如果使用 if,后面的消费者会继续执行,访问空队列。
第三,signal 只能表示“条件可能成立”,不能保证“条件一定成立”。条件是否真的成立,必须重新检查共享状态。
因此条件变量的黄金规则是:
等待条件时,永远使用 while,不要使用 if。
3.4从用户态到内核:条件变量最终是如何休眠的?
在Linux中,pthread_cond_wait是glibc/NPTL提供的用户态线程库接口。它的底层并不是每次都直接进入内核,而是尽量先在用户态完成状态管理,只有线程真的需要阻塞时,才能进入内核。
Linux中这类同步原语通常依赖futex,即fast userspace mutex。
futex的思想是:
无竞争时:用户态原子操作解决
有竞争时:进入内核睡眠
被唤醒时:内核把线程重新放回可运行队列当线程调用pthread_cond_wait时,glibc会维护条件变量内部的等待状态和序号。如果发现当前线程确实需要阻塞,就会通过 futex 相关系统调用进入内核。内核会把该线程挂到某个 futex key 对应的等待队列上,并把线程状态改为睡眠态。此时调度器不会再给它分配 CPU 时间片。
当另一个线程调用pthread_cond_signal时,glibc更新条件变量状态,并在需要时调用futex wake操作。内核从对应等待队列中唤醒一个或多个线程,被唤醒的线程进入可运行队列,等待调度器调度。被调度后,它还要重新竞争互斥锁,拿到锁之后,pthread_cond_wait才会返回。
条件变量的完整链路大概是:
用户代码检查共享条件
|
v
pthread_cond_wait
|
v
glibc/NPTL 管理条件变量状态
|
v
futex_wait 进入内核阻塞
|
v
内核等待队列 + 调度器
|
v
pthread_cond_signal / futex_wake 唤醒线程内核并不知道queue.empty()是什么,内核只负责睡眠和唤醒,真正的业务条件永远由用户态代码在锁保护下检查。
4.阻塞队列
阻塞队列和普通队列的区别在于:普通队列为空时,取数据可能失败;阻塞队列为空时,消费者会睡眠等待。普通队列满时,插入可能失败;阻塞队列满时,生产者会睡眠等待。
一个典型阻塞队列需要:
一个队列:保存数据
一个容量上限:判断满
一把互斥锁:保护队列
两个条件变量:分别给生产者和消费者等待结构如下:
template<class T>
class BlockQueue
{
private:
std::queue<T> _queue;
unsigned int _cap;
pthread_mutex_t _mutex;
pthread_cond_t _cond_productor;
pthread_cond_t _cond_consumer;
};生产者逻辑:
void Push(const T& in)
{
pthread_mutex_lock(&_mutex);
while (_queue.size() == _cap) {
pthread_cond_wait(&_cond_productor, &_mutex);
}
_queue.push(in);
pthread_cond_signal(&_cond_consumer);
pthread_mutex_unlock(&_mutex);
}消费者逻辑:
void Pop(T* out)
{
pthread_mutex_lock(&_mutex);
while (_queue.empty()) {
pthread_cond_wait(&_cond_consumer, &_mutex);
}
*out = _queue.front();
_queue.pop();
pthread_cond_signal(&_cond_productor);
pthread_mutex_unlock(&_mutex);
}这里的两个条件变量语义非常清晰:
_cond_productor:队列满时,生产者等待;队列有空间后,消费者唤醒生产者
_cond_consumer:队列空时,消费者等待;队列有数据后,生产者唤醒消费者所有对 _queue 的访问都必须在 _mutex 保护下完成,包括 size()、empty()、push()、front() 和 pop()。因为这些操作都依赖或修改队列内部状态。
5.任务队列:生产消费模型真正的工程形态
生产者消费者模型并不只用于传递 int。在真实工程中,队列里通常放的是任务。
例如一个简单任务对象:
class Task
{
public:
Task(int x, int y) : _x(x), _y(y), _res(0) {}
void operator()()
{
_res = _x + _y;
}
int Result() const
{
return _res;
}
private:
int _x;
int _y;
int _res;
};生产者构建任务:
Task t(data, data * 10);
queue.Push(t);消费者取出任务并执行:
Task t;
queue.Pop(&t);
t();进一步抽象,可以直接使用函数对象:
using task_t = std::function<void()>;这就是线程池任务队列的基本形态。生产者投递任务,消费者线程不断从队列中取出任务并执行。从这个角度看,生产者消费者模型不只是一个并发练习,而是线程池、日志系统、异步回调系统的底层原型。
6.条件变量封装:RAII与同步原语的工程化
直接使用 pthread 原生接口容易出现资源忘记释放、异常路径忘记解锁等问题。因此 C++ 中通常会做 RAII 封装。
互斥锁封装:
class Mutex
{
public:
Mutex()
{
pthread_mutex_init(&_lock, nullptr);
}
void Lock()
{
pthread_mutex_lock(&_lock);
}
void Unlock()
{
pthread_mutex_unlock(&_lock);
}
pthread_mutex_t* Native()
{
return &_lock;
}
~Mutex()
{
pthread_mutex_destroy(&_lock);
}
private:
pthread_mutex_t _lock;
};锁守卫封装:
class LockGuard
{
public:
LockGuard(Mutex* mutex) : _mutex(mutex)
{
_mutex->Lock();
}
~LockGuard()
{
_mutex->Unlock();
}
private:
Mutex* _mutex;
};条件变量封装:
class Cond
{
public:
Cond()
{
pthread_cond_init(&_cond, nullptr);
}
void Wait(Mutex& mutex)
{
pthread_cond_wait(&_cond, mutex.Native());
}
void NotifyOne()
{
pthread_cond_signal(&_cond);
}
void NotifyAll()
{
pthread_cond_broadcast(&_cond);
}
~Cond()
{
pthread_cond_destroy(&_cond);
}
private:
pthread_cond_t _cond;
};使用RAII后,临界区可以写得更安全:
void Push(const T& in)
{
LockGuard lock(&_mutex);
while (_queue.size() == _cap) {
_cond_productor.Wait(_mutex);
}
_queue.push(in);
_cond_consumer.NotifyOne();
}注意:LockGuard与pthread_cond_wait并不冲突,LockGuard负责作用域结束时释放锁,而pthread_cond_wait负责等待期间临时释放锁、被唤醒后重新加锁。
7.条件变量与信号量
条件变量模型中,资源状态由程序员维护:
queue.empty()
queue.size() == cap条件变量本身不计数,它只是让线程睡眠和唤醒。
信号量则不同,信号量内部自带资源计数。
POSIX信号量接口如下:
初始化信号量
#include <semaphore.h>
int sem_init(sem_t *sem, int pshared, unsigned int value);
参数:pshared:0表示线程间共享,非零表示进程间共享;value:信号量初始值。
销毁信号量
int sem_destroy(sem_t *sem);等待信号量
int sem_wait(sem_t *sem);功能:等待信号量,会将信号量的值减1
发布信号量
功能:发布信号量,表示资源使用完毕,可以归还资源了,将信号量加1
int sem_post(sem_t *sem);其中:
sem_wait:P 操作,申请资源,资源数量减 1;如果资源为 0,则阻塞
sem_post:V 操作,释放资源,资源数量加 1;如果有等待者,则唤醒简单封装:
class Semaphore
{
public:
Semaphore(int value)
{
sem_init(&_sem, 0, value);
}
void P()
{
sem_wait(&_sem);
}
void V()
{
sem_post(&_sem);
}
~Semaphore()
{
sem_destroy(&_sem);
}
private:
sem_t _sem;
};条件变量适合表达:
某个共享状态发生变化后,再重新检查条件。
信号量适合表达:
当前可用资源数量是多少,线程能否申请一个资源。
7.环形队列:固定容量缓冲区的生产消费模型
7.1了解环形队列
阻塞队列通常基于 std::queue,逻辑比较直观。环形队列则基于固定大小数组或 std::vector,通过模运算让下标循环前进。
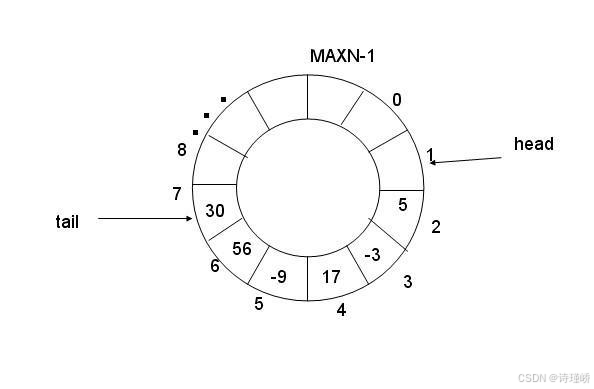
假设容量为 5:
0 1 2 3 4生产下标每次写入后前进:
_p_step++;
_p_step %= _cap;消费下标每次读取后前进:
_c_step++;
_c_step %= _cap;当下标走到末尾后,又回到 0:
0 -> 1 -> 2 -> 3 -> 4 -> 0 -> 1 ...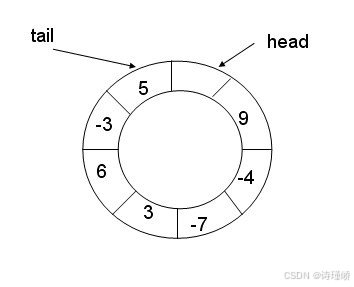
这就是环形队列。
环形队列有一个经典难题:如果只看生产下标和消费下标,当二者相等时,队列可能是空,也可能是满。
_p_step == _c_step到底表示空还是满?仅靠两个下标无法区分。
常见解决办法有:
增加元素计数器
增加标志位
预留一个空槽位
使用信号量记录资源数量在生产者消费者模型里,用信号量是非常自然的方案。
7.2两个信号量:一个表示空间,一个表示数据
环形队列中可以使用两个信号量:
Semaphore _space_sem; // 空间资源
Semaphore _data_sem; // 数据资源初始化时队列为空:
_space_sem(cap);
_data_sem(0);含义是:
一开始有 cap 个空位
一开始有 0 个数据
生产者生产数据时:先申请一个空位,写入数据,再发布一个数据资源。
消费者消费数据时:先申请一个数据,读取数据,再归还一个空位。
对应代码:
void Enqueue(const T& in)
{
_space_sem.P();
// 写入环形队列
_data_sem.V();
}void Pop(T* out)
{
_data_sem.P();
// 读取环形队列
_space_sem.V();
}这里的顺序绝对不能乱。
生产者必须先 P(space),确保有空位,再写数据,最后 V(data) 告诉消费者数据增加了。
消费者必须先 P(data),确保有数据,再读数据,最后 V(space) 告诉生产者空间增加了。
如果生产者先 V(data) 再写数据,消费者可能被提前唤醒,读到尚未写好的槽位。
如果消费者先 V(space) 再读数据,生产者可能提前覆盖消费者还没读完的数据。
8.多生产多消费
多生产多消费下需要两把锁,信号量解决的是生产者和消费者之间的同步问题,也就是:有没有空间,有没有数据。
但信号量不解决生产者之间的互斥,也不解决消费者之间的互斥。
多个生产者会同时修改生产下标_p_step,然后写入同一个位置,导致数据覆盖。
多个消费者会同时修改消费下标_c_step:
*out = _ringqueue[_c_step];
_c_step++;
_c_step %= _cap;如果没有锁,两个消费者可能同时读取同一个位置,导致重复消费。
所以多生产多消费模型需要两把锁:
pthread_mutex_t _p_mutex; // 保护生产者之间的竞争
pthread_mutex_t _c_mutex; // 保护消费者之间的竞争完整结构如下:
template<typename T>
class RingQueue
{
public:
RingQueue(int cap)
: _ringqueue(cap),
_cap(cap),
_p_step(0),
_c_step(0),
_space_sem(cap),
_data_sem(0)
{}
void Enqueue(const T& in)
{
_space_sem.P();
{
LockGuard lock(&_p_mutex);
_ringqueue[_p_step] = in;
_p_step++;
_p_step %= _cap;
}
_data_sem.V();
}
void Pop(T* out)
{
_data_sem.P();
{
LockGuard lock(&_c_mutex);
*out = _ringqueue[_c_step];
_c_step++;
_c_step %= _cap;
}
_space_sem.V();
}
private:
std::vector<T> _ringqueue;
int _cap;
int _p_step;
int _c_step;
Semaphore _space_sem;
Semaphore _data_sem;
Mutex _p_mutex;
Mutex _c_mutex;
};这个模型非常精妙,因为它把三种关系拆的很干净:
生产者与生产者:由 _p_mutex 互斥
消费者与消费者:由 _c_mutex 互斥
生产者与消费者:由 _space_sem 和 _data_sem 同步生产者和消费者之间不需要共用同一把大锁。只要信号量保证“可写位置”和“可读位置”的资源数量正确,生产者写生产下标,消费者读消费下标,二者可以有更高并发度。
9.从内核看POSIX信号量
POSIX信号量和条件变量一样,通常也是用户态优先,内核兜底。
当线程执行:
sem_wait(&sem);如果信号量当前值大于 0,线程可以在用户态通过原子操作把计数减 1,然后直接返回,不需要进入内核。
如果信号量当前值为 0,说明资源不可用,线程需要阻塞。此时线程库可能通过 futex wait 进入内核,内核把当前线程挂到等待队列上,并让调度器切换到其他可运行线程。
当另一个线程执行:
sem_post(&sem);信号量计数增加。如果发现有线程正在等待,线程库会通过 futex wake 唤醒等待者。被唤醒的线程重新进入可运行队列,等待调度器调度。
所以信号量的底层链路大致是:
sem_wait
|
|-- 资源数 > 0:用户态原子减 1,直接返回
|
|-- 资源数 == 0:futex_wait 进入内核阻塞
sem_post
|
|-- 用户态原子加 1
|
|-- 如果有等待线程:futex_wake 唤醒这与mutex、condition variable的实现思想一致:
快路径在用户态
慢路径进内核这也是futex名字中fast的含义:无竞争场景不要频繁陷入内核,只有需要阻塞或唤醒时才让内核参与。
10.阻塞队列和环形队列对比
阻塞队列版本通常是:
数据结构:std::queue
同步工具:mutex + condition variable
状态判断:empty / full 由队列自身状态判断
资源计数:程序员通过 size 判断
锁粒度:通常一把锁保护整个队列
环形队列版本通常是:
数据结构:固定大小数组或 vector
同步工具:semaphore + mutex
状态判断:space_sem / data_sem
资源计数:信号量内部维护
锁粒度:生产锁和消费锁分离
阻塞队列的优点是直观、通用、容易扩展。
环形队列的优点是固定容量、缓存友好、并发粒度更细、适合高频生产消费。
但环形队列也有明显约束:
容量固定,需要提前规划
写入位置会被循环复用,必须严格保证读写顺序
多生产多消费必须额外保护生产下标和消费下标
线程退出和队列析构时要处理阻塞线程
在日志缓冲、网络收发包、音视频缓冲、高性能任务队列中,环形队列非常常见,因为它避免频繁动态内存分配,内存连续,CPU 缓存命中率更好。
11. 线程取消、阻塞点与工程收尾
很多书本上的代码会用:
pthread_cancel(tid);停止线程。短程序里这样做可以演示效果,但真实工程中需要谨慎。
因为线程可能阻塞在:
pthread_cond_wait
sem_wait这些位置通常是取消点。线程被取消时,可能还持有某些资源,或者正处于某个状态更新的中间阶段。如果没有清理逻辑,就可能造成锁未释放、资源泄漏、状态不一致。
更稳妥的做法是设计退出协议:
设置 stop 标志
唤醒所有等待线程
线程醒来后检查 stop 状态
自行跳出循环并 return
主线程 join 回收
线程池、任务队列、日志系统中尤其需要这一点。生产消费模型不仅要能跑起来,还要能停得干净。
12.模型运行模拟
消费者访问阻塞队列时,如果队列为空,流程是:
消费者拿锁
检查队列为空
调用 pthread_cond_wait
线程加入等待队列
互斥锁被原子释放
线程阻塞,CPU 让给其他线程
生产者生产数据后:
生产者拿锁
向队列 push 数据
调用 pthread_cond_signal
等待消费者被唤醒
生产者释放锁
消费者重新竞争锁
消费者检查队列非空
消费者取出数据
环形队列中,消费者访问空队列时:
消费者执行 data_sem.P()
发现数据资源为 0
线程阻塞
生产者写入数据后:
生产者执行 space_sem.P()
获得空位
写入环形队列
执行 data_sem.V()
唤醒消费者
二者表面写法不同,本质都依赖:
共享状态
原子操作
阻塞等待
唤醒通知
调度器重新调度
条件变量强调“条件变化”;信号量强调“资源计数”。
阻塞队列强调“状态判断”;环形队列强调“资源配额”。
互斥锁保护临界区;同步原语控制线程时序。
13.结论
生产者消费者模型不是一个简单的队列练习,而是多线程同步中最核心的工程模型之一。
要真正掌握它,需要同时理解四层内容:
第一层:业务模型
生产者、消费者、中间缓冲区,三者解耦协作。
第二层:线程关系
生产者之间互斥,消费者之间互斥,生产者和消费者之间同步。
第三层:同步原语
mutex 保护共享资源,condition variable 等待条件变化,semaphore 表达资源数量。
第四层:内核机制
无竞争时用户态原子操作解决,有竞争时通过 futex 进入内核等待队列,由调度器完成阻塞与唤醒。
如果使用条件变量,要牢记:
条件变量必须配合互斥锁
pthread_cond_wait 会原子释放锁并睡眠
被唤醒后会重新竞争锁
等待条件必须用 while
signal 只表示条件可能成立
从 std::queue 阻塞队列到固定容量环形队列,从 pthread_cond_wait 到 sem_wait,从用户态同步对象到内核 futex 等待队列,贯穿其中的只有一个目标:
让多个线程在共享资源面前,既安全,又有序,还尽可能高效。
这就是 Linux 线程同步真正的核心。
本章完。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)