第三章 大语言模型基础
第三章 大语言模型基础 — 学习笔记
3.1 语言模型与 Transformer 架构
3.1.1 从 N-gram 到 RNN
N-gram 模型
N-gram 就是把一段文本按照连续的顺序,每 N 个词(或字)切成一组。
-
统计语言
语言模型 (Language Model, LM) 是自然语言处理的核心,其根本任务是计算一个词序列(即一个句子)出现的概率。
在深度学习兴起之前,统计方法是语言模型的主流。其核心思想是,一个句子出现的概率,等于该句子中每个词出现的条件概率的连乘。
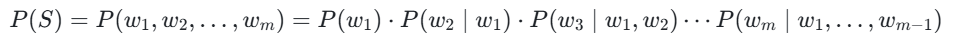
这个公式被称为概率的链式法则。然而,直接计算这个公式几乎是不可能的,因为像
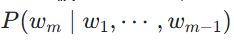 这样的条件概率太难从语料库中估计了,词序列 w1,…,w m-1 可能从未在训练数据中出现过。
这样的条件概率太难从语料库中估计了,词序列 w1,…,w m-1 可能从未在训练数据中出现过。 -
马尔可夫假设
为了解决上面的问题马尔可夫假设 (Markov Assumption) 。其核心思想是:我们不必回溯一个词的全部历史,可以近似地认为,一个词的出现概率只与它前面有限的 n−1n−1n−1 个词有关,如图3.1所示。基于这个假设建立的语言模型,我们称之为 N-gram模型。
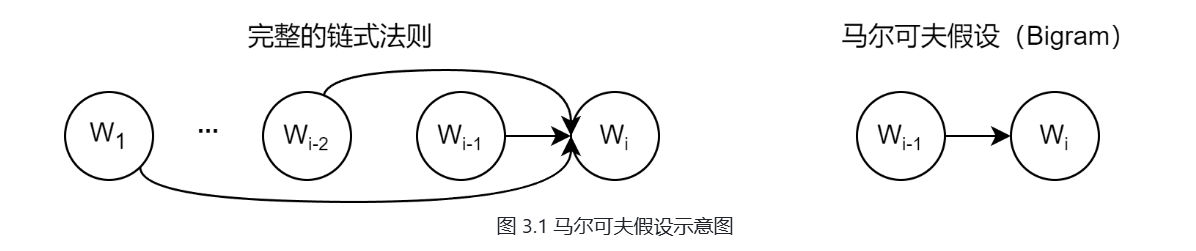
-
最大似然估计
核心思想就一句话:在数据中观察到什么频率最高,就认为它的概率最大。

import collections # 示例语料库,与上方案例讲解中的语料库保持一致 corpus = "datawhale agent learns datawhale agent works" tokens = corpus.split() total_tokens = len(tokens) # --- 第一步:计算 P(datawhale) --- count_datawhale = tokens.count('datawhale') p_datawhale = count_datawhale / total_tokens print(f"第一步: P(datawhale) = {count_datawhale}/{total_tokens} = {p_datawhale:.3f}") # --- 第二步:计算 P(agent|datawhale) --- # 先计算 bigrams 用于后续步骤 bigrams = zip(tokens, tokens[1:]) bigram_counts = collections.Counter(bigrams) count_datawhale_agent = bigram_counts[('datawhale', 'agent')] # count_datawhale 已在第一步计算 p_agent_given_datawhale = count_datawhale_agent / count_datawhale print(f"第二步: P(agent|datawhale) = {count_datawhale_agent}/{count_datawhale} = {p_agent_given_datawhale:.3f}") # --- 第三步:计算 P(learns|agent) --- count_agent_learns = bigram_counts[('agent', 'learns')] count_agent = tokens.count('agent') p_learns_given_agent = count_agent_learns / count_agent print(f"第三步: P(learns|agent) = {count_agent_learns}/{count_agent} = {p_learns_given_agent:.3f}") # --- 最后:将概率连乘 --- p_sentence = p_datawhale * p_agent_given_datawhale * p_learns_given_agent print(f"最后: P('datawhale agent learns') ≈ {p_datawhale:.3f} * {p_agent_given_datawhale:.3f} * {p_learns_given_agent:.3f} = {p_sentence:.3f}") >>> 第一步: P(datawhale) = 2/6 = 0.333 第二步: P(agent|datawhale) = 2/2 = 1.000 第三步: P(learns|agent) = 1/2 = 0.500 最后: P('datawhale agent learns') ≈ 0.333 * 1.000 * 0.500 = 0.167 -
两大缺陷:数据稀疏性、泛化能力差
- 缺陷1:数据稀疏性
举例:语料库里从没出现过 “agent eats” 这个词对
P(eats | agent) = Count(agent eats) / Count(agent) = 0/2 = 0
概率直接变 0。但"agent eats"这个组合不是不可能出现,只是语料库太小没覆盖到。这就像你只见过 3 只猫都是橘色的,就断言"世界上不存在黑猫"一样荒谬。 - 缺陷2:泛化能力差
N-gram 把每个词当成独立的符号,不理解词义关系:
语料库里见过:agent learns → P(learns|agent) 有值
语料库里没见过:robot learns → P(learns|robot) = 0
但 agent 和 robot 意思很接近啊!N-gram 不知道这件事,因为对它来说 “agent” 和 “robot” 就是两个完全不同的字符串,没有任何关联。
- 缺陷1:数据稀疏性
-
代码实践:
N_gram.py
词嵌入 (Word Embedding)
解决了 N-gram 的词孤立、 离散的问题
-
高维向量空间映射
-
💡 简明理解: 把每个词变成一个"坐标点",意思相近的词(如"猫"和"狗")在地图上靠得很近,意思远的词(如"猫"和"经济")离得很远。这样计算机就能用数学来理解词义了。
-
-
余弦相似度
-
一旦我们将词转换成了向量,我们就可以用数学工具来度量它们之间的关系。最常用的方法是余弦相似度 (Cosine Similarity) ,它通过计算两个向量夹角的余弦值来衡量它们的相似性。
💡 简明理解: 两个向量夹角越小(方向越一致),余弦值越接近 1,说明它们越相似;方向垂直则为 0(无关),方向相反则为 -1(完全相反)。
-
-
King - Man + Woman ≈ Queen
-
我们从“国王”这个点出发,减去“男性”的向量,再加上“女性”的向量,最终就抵达了“女王”的位置。这证明了词嵌入能够学习到“性别”、“皇室”这类抽象概念。
-
-
代码实践:
Word_Embedding.py-
import numpy as np embeddings={ "king": np.array([0.9, 0.8]), "queen": np.array([0.9, 0.2]), "man": np.array([0.7, 0.9]), "woman": np.array([0.7, 0.3]) } def cosine_similarity(a,b): # 计算点积 (分子) dot_product = np.dot(a, b) # 计算模长 (分母) norm_a=np.linalg.norm(a) norm_b=np.linalg.norm(b) return dot_product / (norm_a * norm_b) res=embeddings["king"]-embeddings["man"]+embeddings["woman"] sim=cosine_similarity(res,embeddings["queen"]); print(f"king - man + woman 的结果向量: {res}") print(f"该结果与 'queen' 的相似度: {sim:.4f}") >>>> king - man + woman 的结果向量: [0.9 0.2] 该结果与 'queen' 的相似度: 1.0000
-
循环神经网络 (RNN) 与长短时记忆网络 (LSTM)
为了打破固定窗口的限制,循环神经网络 (Recurrent Neural Network, RNN) 应运而生,其核心思想非常直观:为网络增加“记忆”能力[2]。
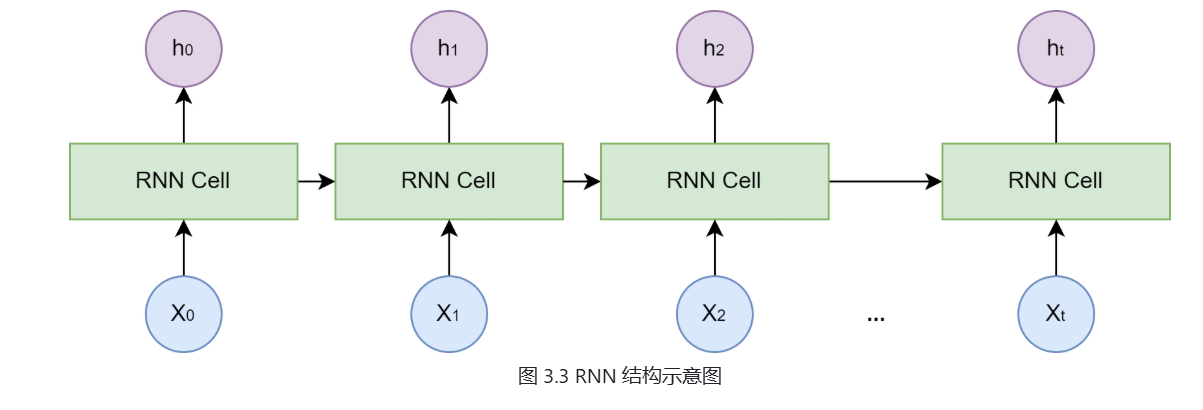
-
隐藏状态作为"记忆"
-
NN 的设计引入了一个隐藏状态 (hidden state) 向量,,然后生成一个新的记忆(即当前时间步的隐藏状态)传递给下一刻。这个循环往复的过程,使得信息可以在序列中不断向后传递。
-
-
梯度消失/爆炸问题
-
长期依赖问题 (Long-term Dependency Problem) 。在训练过程中,模型需要通过反向传播算法根据输出端的误差来调整网络深处的权重。对于 RNN 而言,序列的长度就是网络的深度。当序列很长时,梯度在从后向前传播的过程中会经过多次连乘,这会导致梯度值快速趋向于零(梯度消失)或变得极大(梯度爆炸)。梯度消失使得模型无法有效学习到序列早期信息对后期输出的影响,即难以捕捉长距离的依赖关系。
💡 简明理解: 信号像传话一样,传得太远就"失真"了——梯度消失意味着远处的信息几乎学不到,就像你让10个人依次传一句话,到第10个人时早就不知道原话是什么了。
-
-
LSTM 三门机制:遗忘门、输入门、输出门
-
为了解决长期依赖问题,长短时记忆网络 (Long Short-Term Memory, LSTM) 被设计出来[3]。LSTM 是一种特殊的 RNN,其核心创新在于引入了细胞状态 (Cell State) 和一套精密的门控机制 (Gating Mechanism) 。
-
💡 简明理解: LSTM 有三个"阀门"(门):遗忘门决定丢掉什么旧记忆,输入门决定存入什么新记忆,输出门决定输出什么记忆。就像你整理笔记本时,会擦掉过时的内容、记下新的重点、然后只翻到需要的那页。
- 遗忘门 (Forget Gate):决定从上一时刻的细胞状态中丢弃哪些信息。
- 输入门 (Input Gate):决定将当前输入中的哪些新信息存入细胞状态。
- 输出门 (Output Gate):决定根据当前的细胞状态,输出哪些信息到隐藏状态。
-
3.1.2 Transformer 架构解析
为了解决 RNN 无法进行大规模的并行计算,在处理长序列时效率低下,这极大地限制了模型规模和训练速度的提升的问题
Encoder-Decoder 整体结构
- 编码器负责"理解",解码器负责"生成"
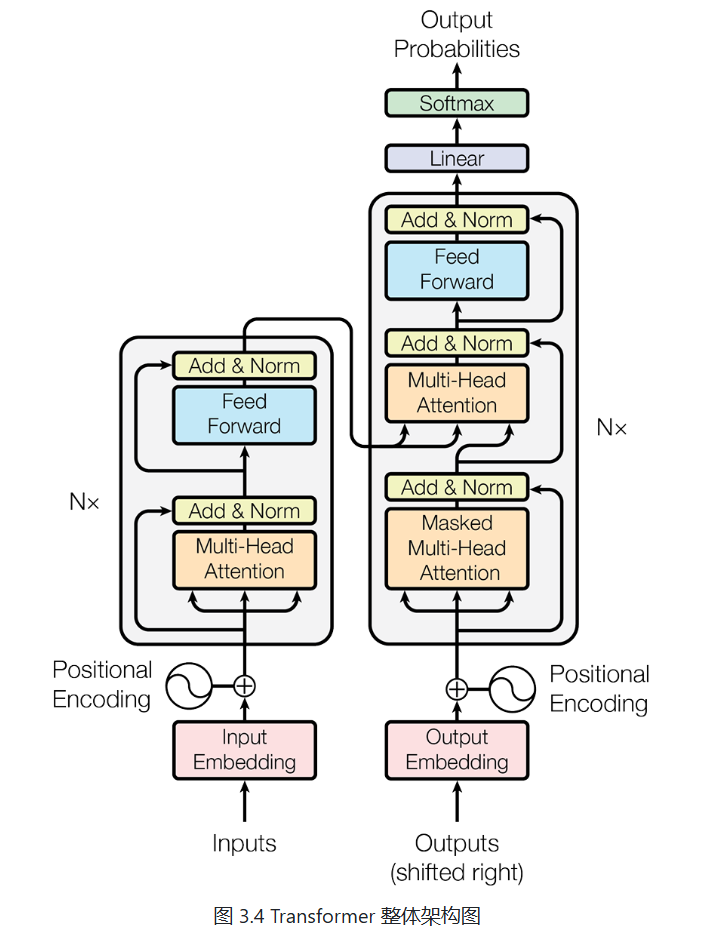
自注意力机制 (Self-Attention)
-
Q/K/V 三角色含义
-
- 查询 (Query, Q):代表当前词元,它正在主动地“查询”其他词元以获取信息。
- 键 (Key, K):代表句子中可被查询的词元“标签”或“索引”。
- 值 (Value, V):代表词元本身所携带的“内容”或“信息”。
-
💡 简明理解: 自注意力就像"开卷考试"——每个词拿着自己的问题(Q),去查所有关键词(K)的标签,找到最相关的词的正文(V),然后按相关性加权拼出自己的新答案。
-
-
核心公式:
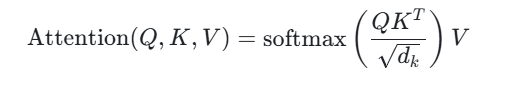
上述的注意力计算(即单头),模型可能会只学会关注一种类型的关联
多头注意力 (Multi-Head Attention)
💡 简明理解: 多头注意力 = 多个"专家"同时看同一个句子,有的关注语法、有的关注指代、有的关注语义,最后把大家的意见汇总。比一个专家看得更全面。
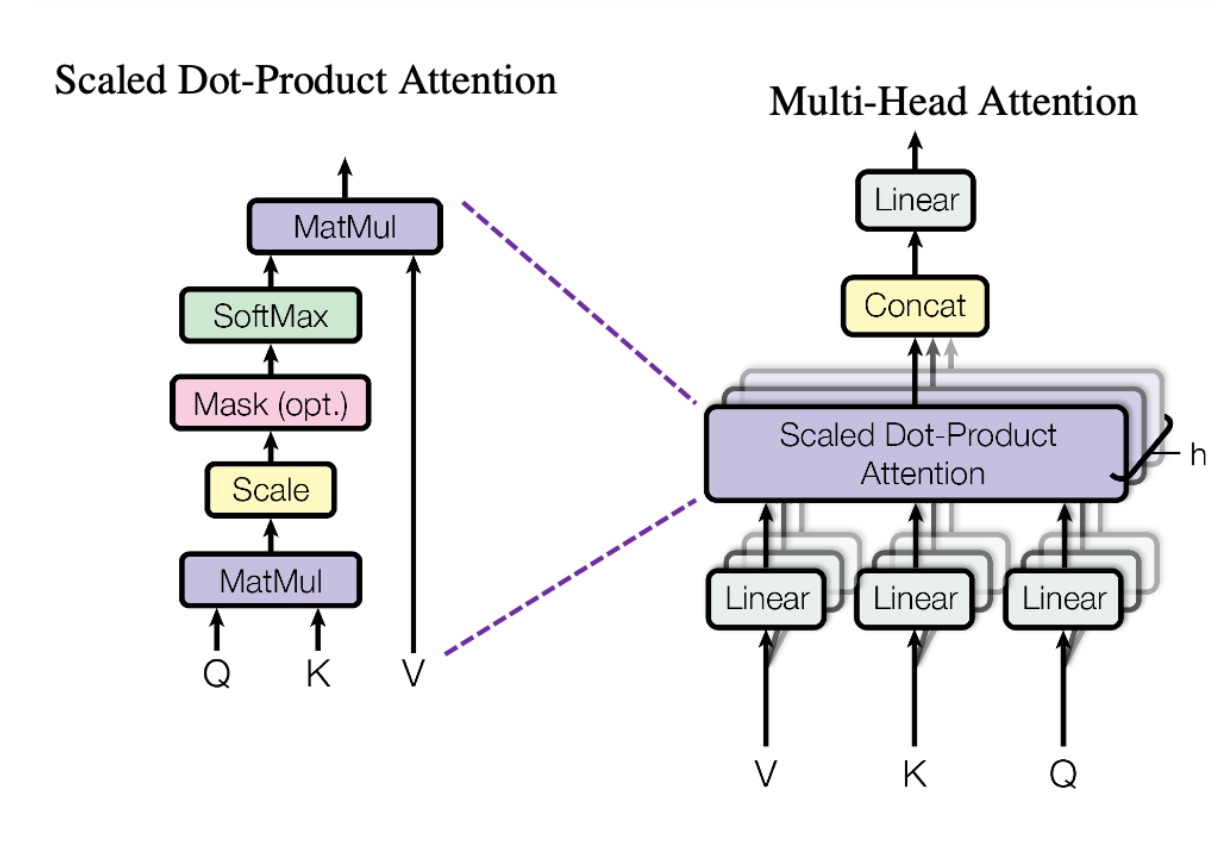
-
多个"专家"从不同角度分析同一句话
-
QKV是什么 ?
-

-
x= 小明在吃饭 这个例子 token分化为 小明 在 吃饭
Q=x* w q 关注的是 现在要找和“小明”相关的信息
K=x* w k 我是‘小明’,谁要找我就看这个 K”
V=x* w v 如果有人找到我,我提供的信息是这个 V
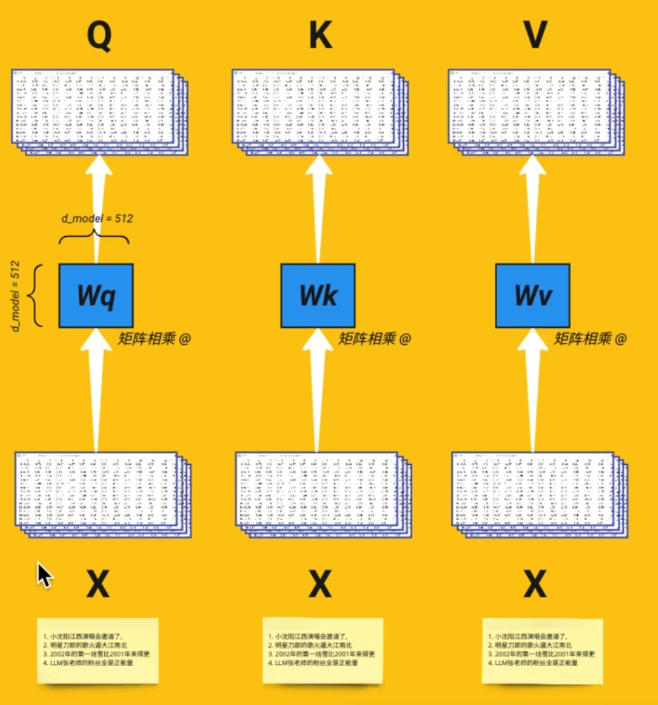
维度提前固定
输入 X 维度 512,就预先定好(W_q、W_k、W_v)的行列尺寸,不会中途改动。
初始数值随机
权重矩阵里初始是随机小数,一般区间接近 0,不是严格 0~1。
训练全程迭代更新
每次前向计算 QKV、注意力得分,算出预测误差;反向传播后,不断微调三个 W 矩阵里的数值,慢慢学到合理的匹配关系。
-
-
接下来 进行Scale
-
scale 就是 这个 Q *K 的一个乘积 ——》如果不处理就会越来越大 这个权重就会两极化没法学习
Scale 就是除以根号 K 的维度
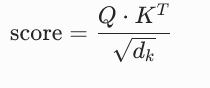
-
-
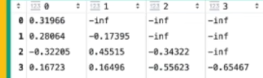
Mask(opt.)
-
掩码挡住后文,模型只能依据已出现的字词,推算后续每个字出现的概率。
实际操作是把后续的设置为负无穷值 让他看到了也等于无效
-
时序遮蔽规则
逐 token 递进计算:
- 第 1 个词小明:只能看自己,预测下一个词
- 第 2 个词在:只能看小明、在,看不到后面吃、饭
- 第 3 个词吃:仅可见前面两个词
- 第 4 个词饭:能看到全部前文
-
-
-
SoftMax
-
-
作用:把所有注意力分数,转换成总和为 1的概率分布
-
运算逻辑
所有数值套指数函数,再除以总和,负数会变小趋近 0,但不会直接清零;原本偏大的分值,概率占比会拉高。
结合掩码场景:被遮位置分数是负无穷,经过 softmax 后概率直接无限趋近 0,彻底不参与加权。
-
-
前馈网络 (FFN)
作用 1. 让每个词 独立思考
2.放大和提取重要的特征
// 输入:初步理解 {0.1, -0.5, 0.8, -0.3, 0.2} // FFN加工后 {0.0, 0.0, 1.5, 0.0, 0.6} // 负数清零,重要特征放大
💡 简明理解: 前馈网络就像一个"加工站"——每个词经过注意力聚合后,都要单独通过这个站做一次"深度加工"(升维→激活→降维),提炼出更丰富的特征。所有词共用同一个加工站,所以参数不会爆炸。
-
逐位置、共享权重
-
逐位置就是 挨个处理
多头注意力子层之后都跟着一个逐位置前馈网络(Position-wise Feed-Forward Network, FFN)
共享权重 减少参数量
// 共享权重 = 学到的加工规则对所有词都适用 FFN学到的规则: - 名词要这样处理 - 动词要那样处理 - 形容词要另一种处理 这些规则可以应用到: - "猫"(名词)✅ - "狗"(名词)✅ - "跑"(动词)✅ - "快"(形容词)✅
-
-
两个线性层 + ReLU
- // 典型配置
- //输入: 512维 线性层1: 512 → 2048维
- // 放大4倍!
- // ReLU: 过滤负数
- //线性层2: 2048 → 512维
- // 压缩回来 输出: 512维
残差连接与层归一化 Add & Norm
-
残差解决梯度消失
-
该操作将子模块的输入
x直接加到该子模块的输出Sublayer(x)上。这一结构解决了深度神经网络中的梯度消失 (Vanishing Gradients) 问题。 -
第1个人说:“今天天气真好” ↓ 第2个人传 ↓ 第3个人传 ↓ …(传了50层) ↓ 最后变成:“猫在跑” ← 信息完全失真了!
// ❌ 没有残差连接(信息容易丢失) output = layer(input);
// ✅ 有残差连接(保留原始信息) output = layer(input) + input; // ← 关键:加上原始输入!
-
Add Output=x+Sublayer(x)。
-
-
层归一化稳定训练
-
解决的问题:数据尺度不稳定,训练困难
-
层归一化怎么处理?
两步走:
第1步:减去平均值(让数据以0为中心)
javadouble[] 特征 = {1000, -500, 2000, -800}; // 算平均值 double 平均值 = (1000 + (-500) + 2000 + (-800)) / 4 = 175; // 每个数减去平均值 double[] 中心化 = {825, -675, 1825, -975}; // 现在数据围绕0分布了第2步:除以标准差(让数据范围统一)
java// 标准差 ≈ 1200(表示数据的波动大小) // 每个数除以标准差 double[] 归一化 = {0.69, -0.56, 1.52, -0.81}; // 看!所有数字都在 -2 到 2 之间了!
-
位置编码 (Positional Encoding)
解决的问题 transformer 不知道词的位置 如 :狗咬我 和 我咬狗
-
sin/cos 函数生成位置向量位置编码
-
位置编码的解决方案
核心思路:给每个词贴上"位置标签"
// 原始词向量 "猫": {0.2, 0.5, -0.3, 0.8} "追": {0.1, 0.4, 0.2, 0.6} "狗": {0.3, 0.6, -0.1, 0.7} // 加上位置信息后 位置0-猫: {0.2, 0.5, -0.3, 0.8} + {位置0的编码} 位置1-追: {0.1, 0.4, 0.2, 0.6} + {位置1的编码} 位置2-狗: {0.3, 0.6, -0.1, 0.7} + {位置2的编码} -
位置编码具体怎么做?
-
正弦余弦编码
方法1:最简单的方式(但不实用)、 // 直接用数字表示位置 位置0: 0 位置1: 1 位置2: 2 // 问题: // 位置0和位置1000差距太大 // 模型学不好 方法2:正弦余弦编码 // 用正弦和余弦函数生成位置编码 // 这样位置信息是周期性的,更平滑 位置编码公式: PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model)) // pos = 位置索引(0, 1, 2, ...) // i = 维度索引(0, 1, 2, ...) // d_model = 向量维度(比如512) 具体例子 假设 d_model = 4(简化版) java // 位置0的编码 pos=0: 维度0: sin(0/10000^0) = sin(0) = 0 维度1: cos(0/10000^0) = cos(0) = 1 维度2: sin(0/10000^(2/4)) = sin(0) = 0 维度3: cos(0/10000^(2/4)) = cos(0) = 1 位置0编码: {0, 1, 0, 1} // 位置1的编码 pos=1: 维度0: sin(1/10000^0) = sin(1) ≈ 0.84 维度1: cos(1/10000^0) = cos(1) ≈ 0.54 维度2: sin(1/10000^(2/4)) = sin(0.01) ≈ 0.01 维度3: cos(1/10000^(2/4)) = cos(0.01) ≈ 1.0 位置1编码: {0.84, 0.54, 0.01, 1.0} // 位置2的编码 pos=2: 维度0: sin(2/10000^0) = sin(2) ≈ 0.91 维度1: cos(2/10000^0) = cos(2) ≈ -0.42 维度2: sin(2/10000^(2/4)) = sin(0.02) ≈ 0.02 维度3: cos(2/10000^(2/4)) = cos(0.02) ≈ 1.0 位置2编码: {0.91, -0.42, 0.02, 1.0} -
完整流程
输入句子: "猫 追 狗" 步骤1:词嵌入(Word Embedding) "猫" → {0.2, 0.5, -0.3, 0.8} "追" → {0.1, 0.4, 0.2, 0.6} "狗" → {0.3, 0.6, -0.1, 0.7} 步骤2:位置编码(Positional Encoding) 位置0 → {0, 1, 0, 1} 位置1 → {0.84, 0.54, 0.01, 1.0} 位置2 → {0.91, -0.42, 0.02, 1.0} 步骤3:相加 猫(位置0) = {0.2, 0.5, -0.3, 0.8} + {0, 1, 0, 1} 追(位置1) = {0.1, 0.4, 0.2, 0.6} + {0.84, 0.54, 0.01, 1.0} 狗(位置2) = {0.3, 0.6, -0.1, 0.7} + {0.91, -0.42, 0.02, 1.0} 步骤4:输入给 Transformer 现在模型知道每个词的位置了!
-
-
代码实践:
class PositionalEncoding(nn.Module): """ 为输入序列的词嵌入向量添加位置编码。 """ def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000): super().__init__() self.dropout = nn.Dropout(p=dropout) # 创建一个足够长的位置编码矩阵 position = torch.arange(max_len).unsqueeze(1) div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)) # pe (positional encoding) 的大小为 (max_len, d_model) pe = torch.zeros(max_len, d_model) # 偶数维度使用 sin, 奇数维度使用 cos pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) # 将 pe 注册为 buffer,这样它就不会被视为模型参数,但会随模型移动(例如 to(device)) self.register_buffer('pe', pe.unsqueeze(0)) def forward(self, x: torch.Tensor) -> torch.Tensor: # x.size(1) 是当前输入的序列长度 # 将位置编码加到输入向量上 x = x + self.pe[:, :x.size(1)] return self.dropout(x)
3.1.3 Decoder-Only 架构
抛弃编码器 只保留解码器 这就是 Decoder-Only 架构的由来。
GPT 核心思想
- 语言模型 = 预测下一个词
💡 简明理解: 生成第3个词时,模型不能偷看第4、5、6个词的答案。掩码自注意力通过把"未来位置"的分数设为负无穷,让 Softmax 后概率变成0,从数学上杜绝"作弊"。
自回归生成
- 一个词一个词往后接
- 给模型一个起始文本(例如 “Datawhale Agent is”)。
- 模型预测出下一个最有可能的词(例如 “a”)。
- 模型将自己刚刚生成的词 “a” 添加到输入文本的末尾,形成新的输入(“Datawhale Agent is a”)。
- 模型基于这个新输入,再次预测下一个词(例如 “powerful”)。
- 不断重复这个过程,直到生成完整的句子或达到停止条件。
掩码自注意力
-
防止"偷看"未来信息
-
💡 简明理解: 生成第3个词时,模型不能偷看第4、5、6个词的答案。掩码自注意力通过把"未来位置"的分数设为负无穷,让 Softmax 后概率变成0,从数学上杜绝"作弊"。
3.2 与大语言模型交互
3.2.1 提示工程
模型采样参数
-
Temperature:低精准、中平衡、高发散
- 低温(0.1–0.3)→ 精准、保守
- 几乎只选概率最高的词,输出固定、重复、可靠。
- 适合:代码生成、事实问答、法律 / 医疗严谨回答。
- 缺点:易模板化、缺创意。
- 中温(0.5–0.8)→ 平衡、通用
- 在准确与多样间折中,有变化但不跑偏。
- 适合:日常对话、文案起草、一般问答(模型默认常用 0.7)。
- 高温(1.0–1.5)→ 发散、创意
- 拉平概率,低频词也易被选中,脑洞大、易幻觉。
- 适合:写诗、故事、头脑风暴、角色扮演。
- 缺点:逻辑易断、胡说概率上升。
原理:Temperature → 0 接近 “贪心解码”(只选最优);T → ∞ 接近随机乱选。
- 低温(0.1–0.3)→ 精准、保守
-
Top-k / Top-p:
-
二者都是只保留高概率候选、砍掉不靠谱长尾,防止生成乱码。
-
候选词截断策略
-
参数 控制逻辑 特点 推荐值 Top-k 固定k 个候选 简单、固定、不灵活 k=30–100 Top-p 固定累积概率 p 自适应、质量更稳 p=0.7–0.95
-
零样本、单样本与少样本提示
- Zero-shot / One-shot / Few-shot
模型提前学习海量文本,内置通用语言逻辑与知识
Zero-shot
无示例,直接依据自身知识库推理选词,候选范围偏小
One-shot
给到 1 个范例,模型捕捉句式、答题规则,扩大可选词汇范围
Few-shot
多个范例强化规律认知,允许更多合理表达,选词自由度拉满
实操逻辑
示例越多,模型判定合法候选词越多,对应 Top-k 数值逐步调高
指令调优
- 从"文本补全"到"听指令"
基础提示技巧
-
角色扮演
-
通过赋予模型一个特定的角色,我们可以引导它的回答风格、语气和知识范围,使其输出更符合特定场景的需求。
# 案例 你现在是一位资深的Python编程专家。请解释一下Python中的GIL(全局解释器锁)是什么,要让一个初学者也能听懂。
-
-
上下文示例
-
这与少样本提示的思想一致,通过在提示中提供清晰的输入输出示例,来“教会”模型如何处理我们的请求,尤其是在处理复杂格式或特定风格的任务时非常有效。
# 案例 我需要你从产品评论中提取产品名称和用户情感。请严格按照下面的JSON格式输出。 评论:这款“星尘”笔记本电脑的屏幕显示效果惊人,但我不太喜欢它的键盘手感。 输出:{"product_name": "星尘笔记本电脑", "sentiment": "混合"} 评论:我刚买的“声动”耳机音质很棒,续航也超出了我的预期! 输出:
-
思维链 (Chain-of-Thought)
-
“请一步一步思考”,提升推理能力
-
对于需要逻辑推理、计算或多步骤思考的复杂问题,直接让模型给出答案往往容易出错。思维链 (Chain-of-Thought, CoT) 是一种强大的提示技巧,它通过引导模型“一步一步地思考”,提升了模型在复杂任务上的推理能力。
实现 CoT 的关键,是在提示中加入一句简单的引导语,如“请逐步思考”或“Let’s think step by step”。
# 思维链提示 一个篮球队在一个赛季的80场比赛中赢了60%。在接下来的赛季中,他们打了15场比赛,赢了12场。两个赛季的总胜率是多少? 请一步一步地思考并解答。 >>> (模型可能会输出) 好的,我们来一步步计算。 第一步:计算第一个赛季赢得的比赛数。 80场 * 60% = 48场。 第二步:计算两个赛季的总比赛数和总胜利数。 总比赛数 = 80 + 15 = 95场。 总胜利数 = 48 + 12 = 60场。 第三步:计算总胜率。 总胜率 = (总胜利数 / 总比赛数) * 100% = (60 / 95) * 100% ≈ 63.16%。 所以,两个赛季的总胜率约为63.16%。通过显式地展示其推理过程,模型不仅更容易得出正确的答案,也让它的回答变得更可信、更易于我们检查和纠正。
-
3.2.2 文本分词
这个将文本序列转换为数字序列的过程,就叫做分词 (Tokenization) 。分词器 (Tokenizer) 的作用,就是定义一套规则,将原始文本切分成一个个最小的单元,我们称之为词元 (Token) 。
为何需要分词
- 按词分词:OOV 问题
- 按字符分词:语义缺失
- 子词分词:兼顾词表大小和语义
BPE 算法
💡 简明理解: BPE 算法就是"哪两个字最常挨在一起,就合并成一个词"——反复合并最高频的相邻字符对,直到词表达到目标大小。常见的词保留完整,罕见的词拆成碎片。
-
迭代合并最高频相邻词元对
-
过程
-
案例 假设我们的迷你语料库是
{"hug": 1, "pug": 1, "pun": 1, "bun": 1},并且我们想构建一个大小为 10 的词表。BPE 的训练过程可以用下表3.1来表示: -

-
训练结束后,词表大小达到 10,我们就得到了新的分词规则。现在,对于一个未见过的词 “bug”,分词器会先查找 “bug” 是否在词表中,发现不在;然后查找 “bu”,发现不在;最后查找 “b” 和 “ug”,发现都在,于是将其切分为
['b', 'ug']。
-
-
代码实践:
BPE.py-
import re, collections def get_stats(vocab): """统计词元对频率""" pairs = collections.defaultdict(int) for word, freq in vocab.items(): symbols = word.split() for i in range(len(symbols)-1): pairs[symbols[i],symbols[i+1]] += freq return pairs def merge_vocab(pair, v_in): """合并词元对""" v_out = {} bigram = re.escape(' '.join(pair)) p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)') for word in v_in: w_out = p.sub(''.join(pair), word) v_out[w_out] = v_in[word] return v_out # 准备语料库,每个词末尾加上</w>表示结束,并切分好字符 vocab = {'h u g </w>': 1, 'p u g </w>': 1, 'p u n </w>': 1, 'b u n </w>': 1} num_merges = 4 # 设置合并次数 for i in range(num_merges): pairs = get_stats(vocab) if not pairs: break best = max(pairs, key=pairs.get) vocab = merge_vocab(best, vocab) print(f"第{i+1}次合并: {best} -> {''.join(best)}") print(f"新词表(部分): {list(vocab.keys())}") print("-" * 20) >>> 第1次合并: ('u', 'g') -> ug 新词表(部分): ['h ug </w>', 'p ug </w>', 'p u n </w>', 'b u n </w>'] -------------------- 第2次合并: ('ug', '</w>') -> ug</w> 新词表(部分): ['h ug</w>', 'p ug</w>', 'p u n </w>', 'b u n </w>'] -------------------- 第3次合并: ('u', 'n') -> un 新词表(部分): ['h ug</w>', 'p ug</w>', 'p un </w>', 'b un </w>'] -------------------- 第4次合并: ('un', '</w>') -> un</w> 新词表(部分): ['h ug</w>', 'p ug</w>', 'p un</w>', 'b un</w>'] --------------------
-
分词器对开发者的意义
-
上下文窗口限制
模型单次最多读取处理的最大 token 总数,超限会截断内容;文本越长,中间信息越容易丢失,运算速度变慢。
- Token 换算(经验值):
- 英文:1 token ≈ 0.75 单词
- 中文:1 汉字 ≈ 1.5–2 token
- Token 换算(经验值):
-
API 成本
按输入、输出词元数量分别计费,生成回答单价更高;对话越多、文本越长,花费越高。
-
模型表现异常
超长文本易遗忘前文、答非所问、逻辑错乱;平台限流降配也会导致回答质量下降。
3.2.3 调用开源大语言模型
HuggingFace Transformers
-
AutoModelForCausalLM / AutoTokenizer
-
AutoTokenizer:文本 ↔ 模型能看懂的数字 ID(分词 / 编码 / 解码)。
AutoModelForCausalLM:加载因果语言模型(Causal LM),用于文本生成 / 对话 / 续写。
-
-
代码实践:
Qwen.py
3.2.4 模型的选择
选型维度
- 性能、成本、速度、上下文窗口、部署方式、生态、可微调性、安全性
闭源模型
- GPT / Gemini / Claude / 国内模型
开源模型
- Llama / Mistral / Qwen / ChatGLM
3.3 大语言模型的缩放法则与局限性
3.3.1 缩放法则
💡 简明理解: 参数量、数据量、算力三者同步增长,模型性能就会稳定提升——就像盖楼,砖头、工人、设备要一起增加才能盖得更高更快。而且当规模够大时,模型会突然冒出小模型完全没有的能力(涌现)。
幂律关系
- 参数量、数据量、算力同步增长 → 性能稳定提升
Chinchilla 定律
- 参数量和数据量有最优配比
能力涌现
- 规模到阈值后突然出现新能力
3.3.2 模型幻觉
定义与类型
- 事实性幻觉 (Factual Hallucinations) : 模型生成与现实世界事实不符的信息。
- 忠实性幻觉 (Faithfulness Hallucinations) : 在文本摘要、翻译等任务中,生成的内容未能忠实地反映源文本的含义。
- 内在幻觉 (Intrinsic Hallucinations) : 模型生成的内容与输入信息直接矛盾。
缓解方法
-
数据层面: 通过高质量数据清洗、引入事实性知识以及强化学习与人类反馈 (RLHF) 等方式,从源头减少幻觉。
-
模型层面: 探索新的模型架构,或让模型能够表达其对生成内容的不确定性。
-
推理与生成层面:
-
检索增强生成 (Retrieval-Augmented Generation, RAG) [14]: 这是目前缓解幻觉的有效方法之一。RAG 系统通过在生成之前从外部知识库(如文档数据库、网页)中检索相关信息,然后将检索到的信息作为上下文,引导模型生成基于事实的回答。
-
💡 简明理解: RAG 就是"先查资料再答题"——模型回答问题前,先去知识库里搜相关内容,然后带着"参考答案"来生成回复,这样就不容易瞎编了
-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)