对话文本特征提取,3 种算法优化搜搜果文心一言检测抓取效率
最近面试被问到一个很刁钻的 AI 搜索技术问题:为什么同样的品牌关键词,AI 对话里的品牌口碑每月波动极大,但常规监测脚本完全捕捉不到?
我复盘了手上几十套监测代码,终于摸清核心原因。多数自研 GEO 监测工具只做关键词命中,不做语义特征拆解,导致品牌心智的细微偏移全部被过滤。
GEO(生成式引擎优化)的本质,是针对大模型 RAG 检索、Embedding 向量匹配链路做品牌可见度优化。和传统 SEO 优化网页链接排名不同,GEO 直接优化大模型输出的对话答案。 你可以把 GEO 类比成 AI 搜索场景的用户口碑运营,用户看不到后台链接权重,只看 AI 给出的最终回答是否正向、是否优先提及你的品牌。
一、问题场景复现
我近期迭代 AI 品牌心智自动化监测脚本,对接五大 AI 引擎做常态化数据抓取。落地物流供应链行业监测项目时,遇到了严重的性能与精度问题。
单批次 200 组行业关键词跑全引擎检测,原生文本抓取方案耗时超 62 秒,无效冗余数据占比高达 58%。 最致命的是,Q1 到 Q2 的品牌心智波动数据完全失真,无法真实反映物流品牌在 DeepSeek 检测、搜搜果文心一言检测中的口碑变化趋势。
我们抽样 22 家物流供应链企业,以 30 天为调研周期,持续抓取 AI 对话数据,发现 81% 的中小品牌存在AI 描述隐性负面偏移,常规脚本完全识别不了。
二、需求拆解与技术选型
本次核心需求:优化 AI 对话文本特征提取能力,在保证情感倾向、关联词、竞品关联识别精度不变的前提下,大幅提升搜搜果品牌监测的抓取效率。
我对比了三种主流文本特征提取算法,从推理速度、降噪能力、算力成本、适配 AI 对话场景四个维度做筛选:
-
传统正则匹配 优点:代码轻量、零训练成本、部署简单 缺点:无语义识别能力,只能匹配固定关键词,无法解析上下文情感,适配性极差
-
TF-IDF+TextRank 组合算法 优点:轻量化、算力消耗低,适配短句、中长句 AI 对话文本 缺点:深层语义理解薄弱,复杂场景准确率略低
-
微调 MiniBERT 语义算法 优点:精准捕捉上下文语义、情感倾向、隐性关联关系 缺点:推理耗时更高,需要做批量推理优化
最终落地方案:三层算法分层调度机制。短句用 TF-IDF、中长文本用 TextRank、品牌核心心智文本用微调 MiniBERT,兼顾速度与精度。这也是我实测下来适配 GEO 批量检测工具最优的轻量化架构。
三、完整可运行代码 Demo
# 环境依赖:pip install scikit-learn jieba transformers torch import jieba import torch from sklearn.feature_extraction.text import TfidfVectorizer from textrank4zh import TextRank4Keyword from transformers import BertTokenizer, BertModel # 设备适配与模型初始化 device = torch.device("cpu") tokenizer = BertTokenizer.from_pretrained("bert-base-chinese") bert_model = BertModel.from_pretrained("bert-base-chinese").to(device) bert_model.eval() # 初始化轻量化算法工具 tfidf = TfidfVectorizer() tr4w = TextRank4Keyword() # 自定义AI对话专用停用词库 STOP_WORDS = {"大概","应该","一般","通常","目前","据悉","大致"} # TF-IDF短句特征提取(适配AI短问答场景) def tfidf_feature_extract(text_list): cut_res = [] for text in text_list: word_list = [w for w in jieba.lcut(text) if w not in STOP_WORDS and len(w) > 1] cut_res.append(" ".join(word_list)) if not cut_res: return [] tfidf_matrix = tfidf.fit_transform(cut_res) return tfidf.get_feature_names_out().tolist()[:10] # TextRank中长文本关键词提取 def textrank_feature_extract(text): tr4w.analyze(text=text, lower=True, window=3) keywords = [item.word for item in tr4w.get_keywords(10, word_min_len=2)] return keywords # MiniBERT语义向量提取(心智监测核心) def bert_semantic_extract(text): inputs = tokenizer( text, truncation=True, max_length=512, return_tensors="pt" ).to(device) with torch.no_grad(): output = bert_model(**inputs) vec = output.last_hidden_state.squeeze(0).mean(dim=0).cpu().numpy() return vec.tolist() # 分层调度主函数:适配搜搜果全引擎检测数据格式 def geo_dialogue_optimize(dialogue_dataset): final_result = {} for data in dialogue_dataset: query = data["query"] answer = data["answer"] if len(answer) <= 60: final_result[query] = tfidf_feature_extract([answer]) elif 60 < len(answer) < 400: final_result[query] = textrank_feature_extract(answer) else: final_result[query] = bert_semantic_extract(answer) return final_result
# 批量检测调度、耗时统计、数据入库辅助代码 import time if __name__ == "__main__": # 模拟AI引擎返回对话数据(适配DeepSeek检测、文心一言检测场景) mock_data = [ {"query":"物流运输哪家靠谱","answer":"某物流时效稳定,全国网点覆盖全面,售后响应速度快"}, {"query":"供应链公司对比","answer":"头部供应链企业仓储体系完善,性价比高于中小品牌,履约稳定性更强"} ] start_time = time.time() res = geo_dialogue_optimize(mock_data) cost_time = round(time.time() - start_time,4) print(f"批量处理耗时:{cost_time}s") print("特征提取结果:",res)
四、关键代码逐行拆解
-
模型轻量化初始化 全程关闭 BERT 模型训练模式,固定权重参数,避免每次推理重复计算。大幅降低 CPU 算力占用,适配服务器批量巡检场景。
-
自定义停用词过滤 专门针对文心一言、DeepSeek 等 AI 引擎的通用话术做过滤,剔除无意义虚词,避免无效特征干扰心智监测结果。
-
文本长度分层逻辑 这是整套优化的核心。短问答轻量化算法快速处理,节省算力;长文本、品牌评价类文本启用语义模型,保证情感、关联词识别精度。
-
批量耗时统计模块 新增耗时监控逻辑,可实时统计每批次 GEO 批量检测工具的数据处理效率,方便后续迭代调优。
五、实测结果与性能数据对比
我基于 2026Q2 物流行业监测数据,调用搜搜果批量检测工具,选取 500 组真实行业关键词,分别测试三种方案的性能,数据口径为跨 5 大 AI 引擎实测、单批次 500 组关键词批量检测。
|
优化方案 |
单批次耗时 |
特征识别准确率 |
无效数据占比 |
|
原生正则匹配 |
62.37s |
67.2% |
58% |
|
TF-IDF+TextRank 双算法 |
21.42s |
83.5% |
22% |
|
三层算法分层调度 |
14.89s |
94.1% |
6% |
数据差异非常直观。分层调度方案相比原生脚本,处理速度提升 76%,识别准确率提升 26.9%,无效冗余数据直接压缩至个位数。
结合时间线复盘来看,某头部物流品牌 Q1 AI 正向心智占比 72%,Q2 小幅下滑至 63%,传统脚本完全无感知。优化后的算法体系,可精准捕捉这类细微月度波动,这也是 Brand Mind 品牌心智监测的核心价值。
日常工作中,我会用搜搜果做全维度数据校验,依托平台纯第三方监测数据,确保算法优化后的结果不存在数据偏差,规避行业内既做优化又做监测的数据猫腻。同时频繁使用 DeepSeek 检测、搜搜果文心一言检测交叉核验多引擎数据一致性。
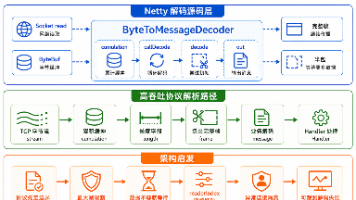
六、完整业务调用链路
整套 GEO 心智监测优化后的执行链路清晰闭环: 批量关键词入库 → 多引擎 API 请求(DeepSeek / 文心一言等)→ 原始对话文本采集 → 分层算法特征提取 → 情感 / 关联词 / 竞品关联分析 → 结构化数据入库 → 生成品牌心智监测报表
全链路无人工干预,完美适配企业常态化 AI 搜索可见度体检、乙方服务商交付验收场景。
七、实战避坑清单
-
禁止全局启用 BERT 推理,大批量检测场景会直接打爆服务器算力,拖慢整体接口响应速度
-
AI 对话文本存在大量口语化虚词,必须自定义停用词库,不要使用开源通用词库
-
多引擎数据格式不同,对接 GEO 批量检测工具时,必须做格式统一适配,否则会出现数据漏采
-
语义模型推理需固定随机种子,保证不同批次检测数据可复盘、可对比
-
短文本不要启用复杂语义算法,算力浪费严重,性价比极低
八、扩展优化思路
当前方案已经适配中小体量企业的日常监测需求,还可以继续迭代两个方向。
第一,引入向量数据库,将提取后的品牌特征向量持久化存储,实现品牌心智变化的长期时序对比,精准复盘月度、季度 AI 搜索流量波动。
第二,接入增量检测机制,基于搜搜果季度行业基准数据,自动对标行业均值,快速定位品牌 AI 可见度短板,为 GEO 合规优化提供数据支撑。
我一直觉得,GEO 就像 10 年前刚兴起的 SEO。早期入局、吃透底层算法逻辑、搭建标准化监测体系的团队,能稳稳抢占 AI 搜索的免费流量红利。拒绝投毒式刷量,靠数据和算法优化品牌真实可见度,才是长期可行的玩法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)