RAG 检索到了还是答错:从一个线上事故讲透 RAG 数据工程全链路
一个合同问答系统的线上事故
某企业法务团队上线了一套合同问答系统。用户问:“渠道商季度返点的计算条件是什么?”
系统返回了三段参考文档,生成了一段看起来完整的回答。法务审核时发现:引用的是 2024 年旧版渠道政策,而 2026 年新版政策已经在知识库里了——只是被排在第 8 条结果,没有进入最终送给模型的上下文窗口。
团队的第一反应是调 top-k、换 embedding 模型、加 reranker。折腾一周后准确率提升了 3 个百分点,但类似问题依然反复出现。
直到有人拉出数据一看:知识库里同一份渠道政策有 5 个版本,从 v1 到 v5 全部被切成了 chunk、全部做了 embedding、全部在向量空间里互相竞争。新版 v5 的向量被 4 个旧版本的相似向量"淹没"了。top-5 召回里有 3 条来自旧版,正确答案根本排不上来。
RAG 的核心不是"把知识塞给模型",而是控制模型在正确的上下文里犯更少的错。如果源头数据就是乱的,后面的检索和生成只是在放大混乱。
这个故事不是个例。2026 年的多项生产实践数据表明,80% 的 RAG 失败可以追溯到数据摄入和分块层,而不是大模型本身。系统返回看似合理的引用,但引用内容支撑不了结论——这是最危险的失败模式,因为它比"没有答案"更难被发现。
这篇文章从这个事故出发,完整拆解一个生产级 RAG 系统的数据工程链路:数据怎么进来、怎么清洗、怎么切分、怎么检索、怎么评测、怎么在上线后持续治理。每一步都会用具体场景说明问题在哪里、解决方案是什么、工程取舍怎么做。
RAG 到底解决什么问题
先把 RAG 的定位讲清楚。大模型本身有三个天然边界:
知识截止。训练数据有截止时间,模型不知道企业最新的产品文档、合同条款、价格政策、组织架构变化。
幻觉。模型在没有答案时,仍然会组织出一段看起来合理的文本。它不是在"说谎",而是在做概率续写——只是续写的内容碰巧不是事实。
知识来源不可控。你不知道某个回答来自训练语料中的哪段内容,也无法要求模型只依据公司授权资料作答。
RAG(Retrieval-Augmented Generation,检索增强生成)本质上是在模型生成之前插入一个"查资料"环节。它不改模型参数,而是让模型在回答前先从外部知识库中检索相关材料,再把这些材料作为上下文送给模型生成答案。
AWS、IBM、Google Cloud 等平台反复强调 RAG 的几个核心价值:引入最新外部数据、减少幻觉、提供引用来源、降低微调成本、让开发者能控制知识来源和权限范围。
但这里有一个容易被忽略的前提:这些价值成立的条件是,检索到的材料本身是正确的、完整的、最新的、有权限边界的。如果检索到的材料本身就有问题,RAG 只会让模型"有根据地犯错"——这比纯幻觉更难察觉,因为回答里有引用、有来源,看起来很专业。
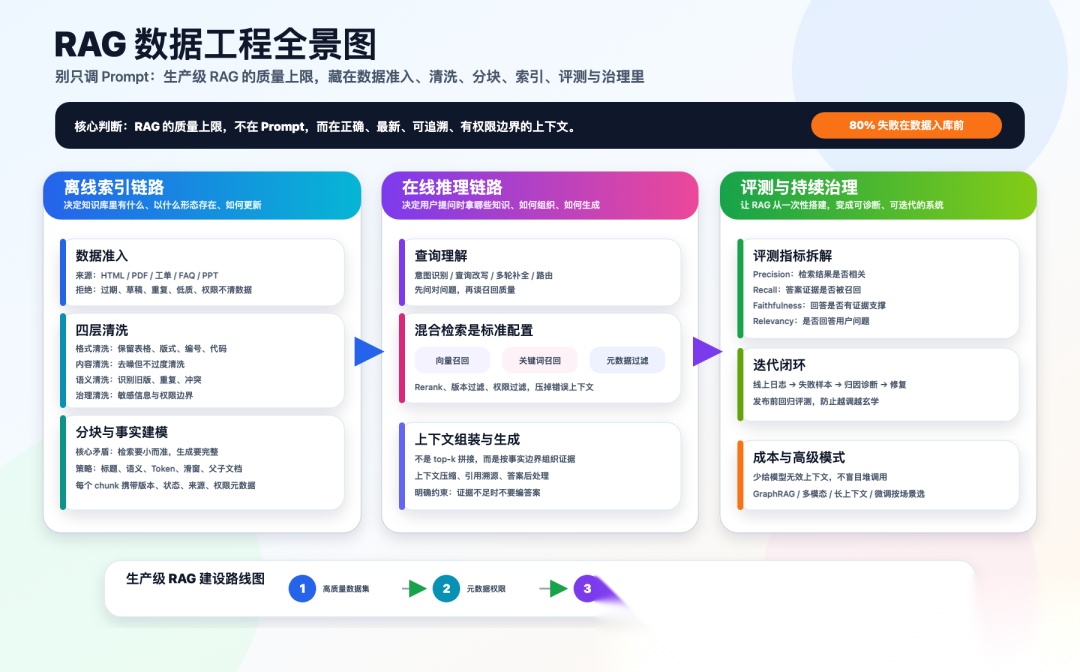
RAG 系统的两条链路:离线数据工程 + 在线推理
很多 RAG 教程从"用户提问 → 向量检索 → LLM 回答"开始讲,这只讲了在线推理的一半。生产级 RAG 必须拆成两条独立但紧密耦合的链路。
离线索引链路决定"知识库里有什么、以什么形式存在、怎么更新"。
在线问答链路决定"用户问问题时拿哪些知识、怎么组织、怎么让模型回答"。
这张图说明 RAG 的离线数据工程和在线推理链路的完整结构,以及二者如何衔接。
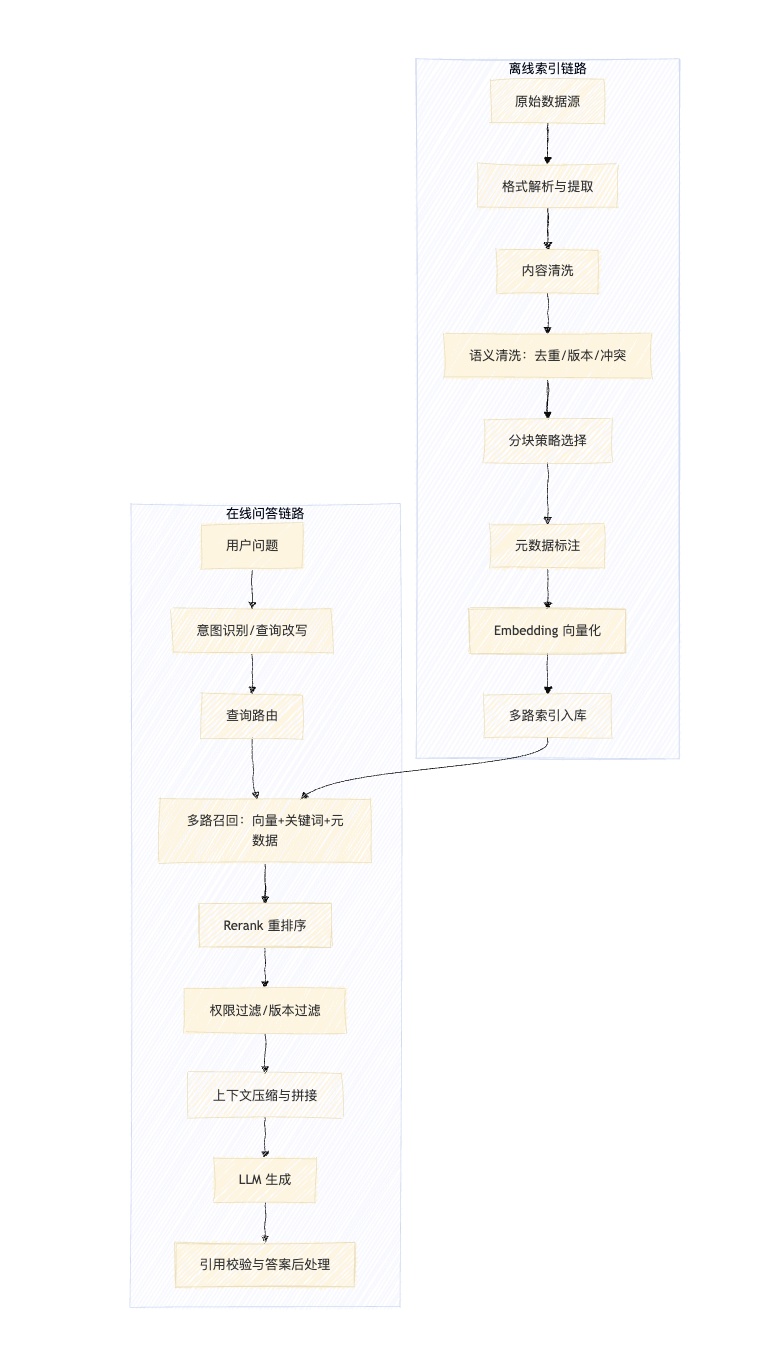
真正决定 RAG 质量上限的,是离线链路。在线链路的检索和生成做得再好,如果知识库本身是脏的、乱的、冗余的,就像在一堆混乱的纸堆里让一个聪明人找答案——他再聪明,纸堆太乱也会找错。
下面按照离线链路的执行顺序,逐步展开每一个关键环节。
数据入库:不是"把文件扔进去",而是建立知识准入门槛
场景:一个 SaaS 产品的售后知识库
假设你在为一个 SaaS 产品搭建售后问答系统,数据来源可能包括:
- • 产品帮助中心的 HTML 页面(约 500 篇)
- • 内部 Confluence 上的技术 FAQ(约 200 篇,但有些是两年前的草稿)
- • 客服工单系统中的历史工单(约 10 万条,格式混乱)
- • 产品更新日志(Markdown,每月更新)
- • 几十份 PDF 版产品手册(不同版本,格式不统一)
- • 销售团队的 PPT 资料(含有截图和表格)
第一个工程决策不是"用什么向量数据库",而是哪些数据可以进知识库,哪些不应该进。
不应该进入 RAG 知识库的数据:
- • 过期文档(旧版产品手册、已废弃的功能说明)
- • 草稿文档(未经审核发布的 Confluence 页面)
- • 重复文档(同一份政策在三个系统里各存了一份)
- • 低质量数据(OCR 质量差的扫描件、格式完全损坏的 PDF)
- • 权限不清晰的数据(不确定哪些用户可以看的合同、薪酬文件)
RAG 的知识库不是网盘。网盘追求存得全,RAG 追求检索时能找到正确事实。把所有文档都导进去再说,是企业 RAG 项目最常见的错误起点。
元数据:不是"好看的标签",而是检索和治理的基础设施
每份文档入库时必须携带结构化元数据,因为它们会直接参与后续的过滤、排序、权限控制、版本淘汰和引用溯源。
{ "document_id": "product_manual_enterprise_v3.2", "title": "企业版产品使用手册 v3.2", "source": "help_center", "owner": "product_doc_team", "version": "3.2", "status": "approved", "supersedes": "product_manual_enterprise_v3.1", "updated_at": "2026-04-15", "permission_groups": ["all_users"], "language": "zh-CN", "business_domain": "product_usage", "content_type": "manual", "expiry_policy": "superseded_by_next_version"}
几个经常被忽略但影响巨大的字段:
- •
supersedes:标记这份文档替代了哪个旧版本。有了它,系统可以自动降权或过滤旧版文档。 - •
status:区分draft、approved、deprecated。检索时默认只命中approved状态的文档。 - •
expiry_policy:定义文档何时过期。"被新版本替代后自动降权"和"每年需要人工确认是否仍然有效"是两种不同的策略。 - •
permission_groups:知识片段本身就应该带着权限进入索引,而不是只在应用层做过滤。
数据清洗:别让模型替你的脏数据背锅
RAG 项目里很多"模型不准"的问题,根源是"数据没洗"。
第一层:格式清洗——把非结构化内容变成可处理的文本
这一步最容易出问题的场景是 PDF 表格。
假设知识库里有一张产品价格表:
| 版本 | 月费 | 用户数上限 | 存储空间 |
|---|---|---|---|
| 基础版 | ¥99 | 10 | 5GB |
| 专业版 | ¥299 | 50 | 50GB |
| 企业版 | ¥899 | 不限 | 500GB |
如果 PDF 解析器把它拍平成一段文本:
基础版 99 10 5GB 专业版 299 50 50GB 企业版 899 不限 500GB
模型看到这段文本后很难知道"299"对应的是哪个版本、"不限"说的是用户数还是存储空间。这种格式损坏会直接导致回答错误,而且很难在生成阶段修复。
解决方案:表格不要拍平,要保留结构并生成可检索的摘要。
一张价格表应该被处理成三层:
- 原始表格对象(保留行列结构、表头、单位)——用于最终引用。
- 表格摘要——“该表描述 2026 年基础版、专业版、企业版的月度订阅价格和功能限制。”——用于语义检索。
- 按行生成的事实陈述——“企业版月费为 ¥899,用户数不限,存储空间 500GB。”——用于精确问答。
这样既能通过摘要进行语义检索,又能在回答时回到原始表格做精确引用。
第二层:内容清洗——去噪但不能过度清洗
去掉的:重复页眉页脚、广告语、无意义导航栏、版权声明、空白字符、HTML 标签残留、乱码。
不能去掉的:法律条款中的编号("第 3.2 条"本身是检索目标)、代码文档中的缩进和格式(影响代码可读性)、API 参数中的大小写(userId 和 userid 可能指不同字段)。
一个常见的错误是用通用的正则表达式批量清洗所有文档,结果把法律文档的条款编号、代码文档的格式化标记、技术文档的版本号一起清掉了。清洗规则必须按文档类型分别定义。
第三层:语义清洗——识别过期、重复和冲突
回到开头的合同问答事故。5 个版本的渠道政策同时存在于知识库中,是"语义清洗"缺失的典型后果。
这一步要解决三个问题:
去重。同一份文档在 Confluence、SharePoint、本地网盘各存了一份,内容几乎相同。15 个近似副本在向量空间中产生 15 个竞争向量,会把正确版本的匹配分数稀释掉。实测数据表明,经过 80%-85% 相似度阈值的语义去重后,知识库体积缩小约 40%,但向量检索准确率反而提升了 13.55%。
向量索引不是硬盘,冗余不会提升召回质量,只会稀释正确答案的信号强度。
版本管理。旧版本不一定要删除(可能有审计需求),但必须打上 deprecated 标记,并在默认检索时降权或过滤。系统应该能通过 supersedes 字段自动识别新旧版本关系。
冲突检测。当两份文档对同一个事实给出不同陈述时(比如 2024 年政策说返点比例是 5%,2026 年政策说是 8%),必须有机制标记冲突,并在上下文拼接时告诉模型优先使用哪份。
第四层:治理清洗——敏感数据和权限
企业 RAG 最怕的事情:一个普通员工通过问答系统看到了高管薪酬方案,因为薪酬文件被"不小心"导入了知识库,且没有权限标注。
规则很简单:敏感数据要脱敏或隔离,权限不明的数据不入库,来源不可信的数据不入主知识库。但执行很难,因为大多数企业的文档管理本身就是混乱的。所以权限治理必须在数据入库阶段就完成,而不是等到查询阶段才去判断。
分块策略:RAG 最容易被低估、影响最大的工程决策
分块(Chunking)是把长文档切成一段段的过程,每段做 embedding 后存入向量库。这个决策听起来很简单,实际上分块配置对检索质量的影响,与 embedding 模型的选择同样大——2025 年的一项研究用 25 种分块配置和 48 种 embedding 模型做交叉测试,证实了这一结论。
核心矛盾:检索要小而准,生成要大而完整
chunk 太大 → 向量语义变得浑浊,一段 2000 token 的文本可能同时涉及安装、权限、计费三个话题,用户问任何一个话题都会召回这段,但大部分内容是噪声。
chunk 太小 → 语义信息不完整,一个 50 token 的片段可能是一句结论,但丢失了前因后果和适用条件。模型拿到它后无法判断是否应该引用。
overlap 太小 → 关键上下文在分块边界处丢失。
overlap 太大 → 重复片段变多,向量空间被相似内容填满,top-k 里多条结果说的是同一件事。
好的分块应该让"检索单元"和"回答所需上下文"尽量对齐。chunk 不是一个存储单位,而是一个知识单位。
六种分块策略对比:不存在"最好的",只有"最适合的"
下表总结了主流分块策略在不同场景下的表现,基于 2026 年的生产实践数据。
| 策略 | 原理 | 适用场景 | 基准准确率 | 计算成本 | 关键限制 |
|---|---|---|---|---|---|
| 固定长度 | 按字符/token 数均匀切分 | 快速 baseline、日志、格式统一文本 | ~69%(512 tokens) | 极低 | 完全忽略文档结构和语义边界 |
| 递归分块 | 按段落→句子→字符层级切分 | 通用文档的默认选择 | 比固定长度提升 5-12% | 低 | 依赖分隔符,对无结构文本效果有限 |
| 结构化分块 | 按 Markdown 标题、HTML DOM、代码函数切分 | API 文档、技术手册、代码库 | 高(结构化文档) | 低 | 要求文档本身有清晰的层级结构 |
| 语义分块 | 计算相邻句子的语义相似度,在话题变化处切分 | 叙事性文档、研究报告 | 比递归分块提升 10-20% | 中(需要 embedding) | 块大小不均匀,平均仅 43 tokens,可能丢失上下文 |
| LLM 分块 | 由大模型判断语义边界 | 高价值场景:法律、医疗、金融文档 | 最高(上下文感知) | 高(每次调用 LLM) | 成本高,速度慢,难以大规模使用 |
| Late Chunking | 先对长文档做完整 embedding,再切分 | 长文档、需要跨 chunk 上下文的场景 | 高 | 中 | 需要支持长上下文的 embedding 模型 |
场景实战:选择分块策略的决策树
场景 A:产品帮助中心(Markdown 格式,结构清晰)
帮助中心文章通常有清晰的标题层级:# 一级标题、## 二级标题、### 步骤。这种文档天然适合结构化分块——按标题层级切分,每个章节是一个 chunk。
from langchain_text_splitters import MarkdownHeaderTextSplitterheaders_to_split_on = [ ("#", "主题"), ("##", "章节"), ("###", "子章节"),]splitter = MarkdownHeaderTextSplitter( headers_to_split_on=headers_to_split_on)chunks = splitter.split_text(markdown_doc)
优势是每个 chunk 都有完整的语义边界和层级元数据。缺陷是如果某个章节特别长(超过 2500 tokens),需要二次切分——因为研究表明,超过 2500 tokens 后模型的回答质量会出现"上下文悬崖"效应。
场景 B:法务合同(PDF,段落密集,无标题结构)
合同文本通常没有 Markdown 层级,但有严格的条款编号体系(“第 3.2 条”、“附件一”)。这种文档应该先做条款级结构化解析,再做分块。
步骤:
- 用 PDF 解析器提取文本,保留条款编号。
- 按条款编号切分为独立单元。
- 每个条款单元附带元数据:合同编号、条款编号、版本、生效日
- 如果单个条款超长,在内部按句子递归切分。
场景 C:客服工单(短文本,格式混乱,数量巨大)
工单文本通常很短(50-200 字),但数量巨大(数万到数十万条),格式不统一,包含大量口语化表达、错别字、产品型号缩写。
这种数据不适合直接做 embedding 入库。更好的方式是先聚类、再摘要、再入库:
- 用 embedding 对工单做语义聚类。
- 每个聚类抽取高频问题模式和典型解决方案。
- 把聚类结果转化成"问题-答案-证据"的事实单元入库。
- 保留原始工单的链接作为引用来源。
这比把 10 万条工单全部做 embedding 要有效得多。10 万条工单的向量在高维空间中会产生大量语义重叠,检索时 top-k 结果很可能是 5 条说同一件事的工单,而不是覆盖不同角度的答案。
进阶策略:父子文档检索
在生产中使用最广泛的一种折中方案:用小 chunk 做索引,命中后返回大 chunk 给模型。
这张图说明父子文档检索如何同时解决"检索要准"和"生成要完整"的矛盾。
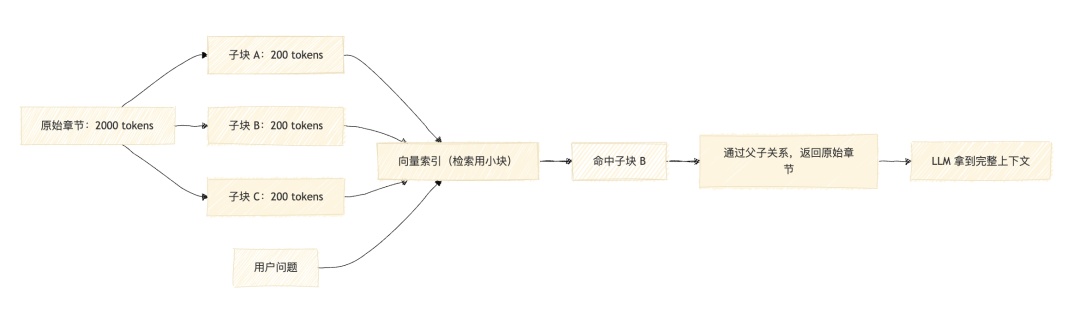
原理:小 chunk(200 tokens)的向量语义更精确,检索时匹配度高;命中后不是把小 chunk 直接给模型,而是回溯到它所属的父章节(2000 tokens),让模型在完整上下文中生成答案。
LangChain 的 ParentDocumentRetriever 和 LlamaIndex 的 AutoMergingRetriever 都实现了这种模式。
更激进的思路:从 Chunk 到事实单元
前面提到的都是在"文档片段"层面做优化。还有一种更根本的思路:不把 chunk 当最终知识单元,而是把文档预处理成"问题-答案-证据"的事实单元。
用户的查询天然是一个问题。如果索引里存的也是问题-答案对,那检索就从"问题匹配一段模糊的叙述文本"变成"问题匹配一个精确的答案单元"——匹配从概率性变成结构性。
{ "question": "企业版月费是多少?", "answer": "企业版月费为 ¥899,用户数不限,存储空间 500GB。", "evidence": "《2026 产品价格表》第 3 行", "source_doc_id": "price_table_2026_v2", "version": "v2", "status": "approved", "permission_groups": ["all_users"], "updated_at": "2026-04-01"}
Twitter 上一篇引发广泛讨论的文章"You’re Doing RAG Wrong"介绍了类似的概念(IdeaBlock):在 Blockify 的内部基准测试中,对 17 份文档、298 页内容做测试,事实单元化后查询到最佳匹配块的平均余弦距离从 0.3624 降到 0.1585,检索距离缩短了 2.29 倍。同时知识库体积缩小了约 40 倍,每次查询的 token 消耗减少了 3 倍。
但这种方式有成本:需要 LLM 或规则来抽取问题-答案对,需要人工校验抽取质量,需要防止抽取过程本身引入错误。所以它适合高价值、高复用、高风险的知识库:客服标准答案、法务政策、产品规格、售前问答。
普通文档库可以先用递归分块 + 元数据治理 + rerank。高价值知识库再做事实单元化。这不是二选一,而是分层策略。
检索层:为什么纯向量搜索在生产中不够用
分块之后,每个知识片段被 embedding 模型转成向量。向量检索通过余弦相似度或近似最近邻算法,在高维空间中找到与查询最接近的片段。
这一步经常被神化,但 embedding 模型本质上只学过大量语义相似模式,它不知道你的业务规则。
三个向量检索必然失败的场景
场景 1:精确标识符。
用户问:“E1027 错误如何处理?”
向量模型可能觉得"登录失败处理办法"在语义上很接近,但真正的答案在"错误码 E1027:证书链验证失败"。E1027 是一个精确标识符,语义检索对它无能为力,必须靠关键词精确匹配。
场景 2:业务近义词陷阱。
"退款政策"和"退货政策"在语义空间中距离很近,但在业务上可能完全不同——退款涉及资金流转,退货涉及物流和库存。纯向量检索容易把二者混淆。
场景 3:多义词。
"额度冻结"在金融系统里涉及风控,在云资源系统里涉及账单。embedding 模型不知道用户当前的业务场景。
混合检索:生产级 RAG 的标准配置
生产系统很少只靠纯向量搜索。更常见的架构是多路召回 + 融合排序。
这张图说明生产级 RAG 的检索不是单路向量召回,而是多路召回加融合排序加权限过滤。
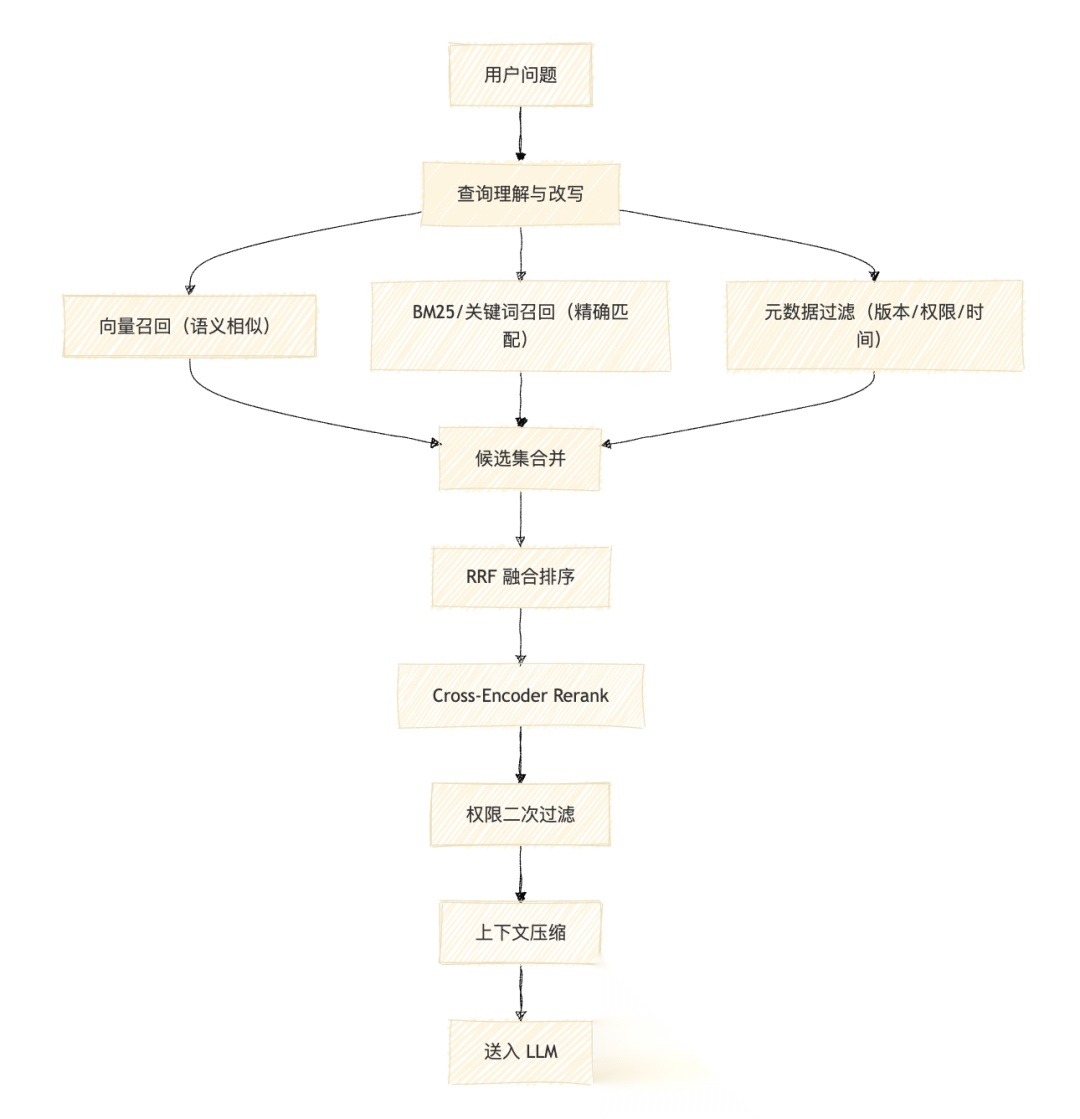
向量召回负责语义相似——“怎么配置 SSL 证书"可以匹配到"HTTPS 证书安装指南”。
BM25/关键词召回负责精确匹配——“E1027”、“API-KEY-INVALID”、"第 3.2 条"这类精确标识符必须靠关键词。
元数据过滤负责业务约束——只搜索 status=approved 且 version=latest 的文档,只返回用户有权限查看的内容。
**RRF(Reciprocal Rank Fusion)**把多路召回的结果按排名倒数融合成统一排序,不需要训练,简单有效。
Cross-Encoder Rerank是精排阶段。初步召回通常拿 20-100 条候选,reranker 逐一计算查询和每条候选的精确相关度,选出最终进入上下文的 3-10 条。Reranker 的计算成本比 embedding 高得多(是 cross-attention 而非 bi-encoder),但它能修正初步召回中的排序错误。
向量检索适合找"意思相近",关键词检索适合找"字面必须命中"。生产级 RAG 通常需要两者同时存在,再加上元数据过滤和重排。
实战:查询改写为什么重要
用户的原始查询经常不是好的检索查询。
用户在多轮对话中问:“这个能报销吗?” ——"这个"指的是什么,取决于上下文。系统需要把多轮对话改写成独立查询:“员工出差期间购买高铁票是否可以按公司差旅制度报销?”
用户用口语化表达:“为啥我的 key 用不了?” ——系统需要改写为:“API Key 无法使用的常见原因和排查步骤。”
查询改写可以用 LLM 做(把对话历史和当前问题发给模型,要求输出一个独立的检索查询),也可以用规则(关键词扩展、同义词替换、指代消解)。在延迟敏感场景下,规则比 LLM 快,但覆盖面窄;在精度优先场景下,LLM 改写效果更好但增加 100-300ms 延迟。
上下文组装与生成:不是把 top-k 拼进 prompt 就完事
检索和重排完成后,下一步是把选出的知识片段组装成 LLM 的上下文。这一步有很多人忽略的细节。
上下文不是越多越好
一个常见的误解是"多塞一些总比少塞好"。实际上:
- • 上下文越长,LLM 的注意力越分散。研究表明 LLM 存在"Lost in the Middle"效应——排在中间的信息更容易被忽略。
- • 无关内容会干扰模型,增加幻觉风险。模型可能从一段不相关的上下文中"提取"出一个看似合理但实际上不存在的答案。
- • 更长的上下文意味着更高的 token 成本和更大的延迟。
策略:不要按固定 top-k 塞入全部结果,而是设定一个 token 预算(比如 3000 tokens),在预算内优先放入 rerank 得分最高的片段,直到预算用完。同时对冗余内容做去重——如果两个 chunk 说的是同一件事,只保留得分更高的那个。
Prompt 设计:约束模型的事实边界
一个生产可用的 RAG prompt 不只是说"请基于以下材料回答"。它需要:
你是企业知识库问答助手。请严格遵守以下规则:1. 只基于【参考资料】回答用户问题。2. 如果参考资料不足以支持结论,请回答"当前资料不足以确认"。3. 回答中涉及制度条款、金额、日期、版本、操作步骤时,必须标注引用来源。4. 如果多份资料之间存在冲突,优先采用 status=approved 且 updated_at 最新的资料, 并在回答中说明存在版本差异。5. 不要编造参考资料中没有出现的政策、数字、链接或联系方式。6. 如果问题超出参考资料的覆盖范围,明确告知用户并建议咨询相关部门。
这些规则不是为了"让模型更礼貌",而是在生成空间里设定事实边界。但必须清楚:prompt 不是保险箱。对于高风险场景(法务、金融、医疗),需要在生成后做答案后处理——提取回答中的每个关键声明,逐一检查是否有上下文片段支持。
引用溯源:让每个答案都可以被追责
生产级 RAG 的回答不能只是一段文本。它必须带有:
- • 引用片段的文档 ID、版本、页码/章节
- • 引用片段的原文(让用户可以点击查看原始出处)
- • 置信度信号(如果参考资料覆盖度低,应该有提示)
没有引用溯源的 RAG 回答,和裸模型的回答在可信度上没有本质区别。
评测:没有评测集的 RAG 调优是玄学
为什么手动试几个问题不够
很多团队调 RAG 的方式是找 10 个问题手工试一试,看看回答对不对。这在 demo 阶段可以,在生产阶段不行。
原因:你不知道改了分块策略后,那 10 个问题之外的 1000 个问题受到了什么影响。可能你优化了 3 个问题,但悄悄地搞坏了 15 个。没有回归评测集,调参就是蒙着眼睛开车。
RAGAS 评测框架:把 RAG 的好坏拆成可诊断的指标
RAGAS(Retrieval Augmented Generation Assessment)是目前最广泛使用的 RAG 评测框架,它的核心思想是把"答案对不对"这个笼统问题,拆成检索层和生成层的 4 个独立指标。
这张图说明 RAGAS 如何定位 RAG 错误发生在链路的哪一段。
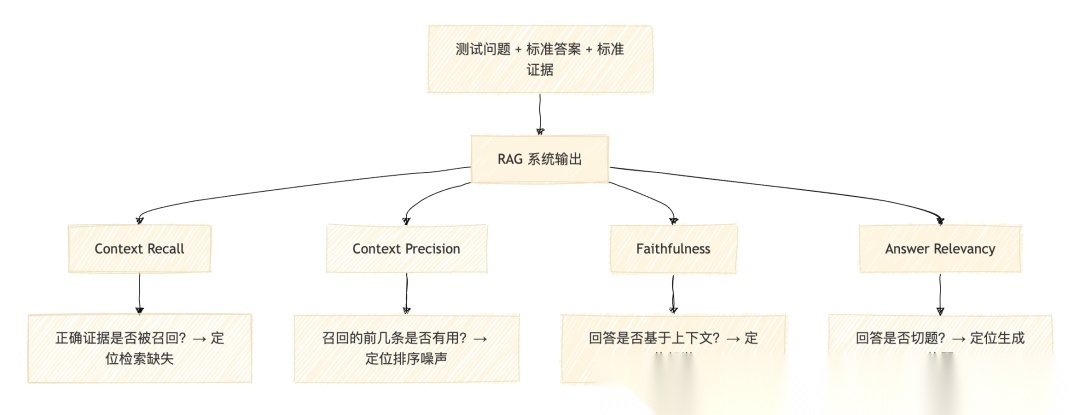
Context Recall(上下文召回率):标准答案中的事实声明,有多少百分比被检索到的上下文覆盖了。低分意味着检索器漏掉了关键信息。
Context Precision(上下文精度):召回的前几条结果中,有用的占比多少。低分意味着检索结果中噪声太多,正确答案虽然被召回了但排不到前面。
Faithfulness(忠实度):模型生成的回答中,每个事实声明是否都能被上下文支持。低分意味着模型在幻觉——它说了上下文里没有的东西。生产系统的 Faithfulness 目标应该在 0.80 以上。
Answer Relevancy(答案相关性):回答是否真正回应了问题。低分意味着回答可能事实正确但文不对题。
构建业务评测集:不只是"正确问题"
一套有效的评测集至少应该包含以下几类样本:
| 类别 | 样本说明 | 为什么需要 |
|---|---|---|
| 高频正样本 | 用户最常问的问题 | 保证核心场景准确 |
| 长尾正样本 | 不常见但重要的问题 | 防止边缘场景崩溃 |
| 负样本 | 知识库里没有答案的问题 | 测试系统是否能正确说"不知道" |
| 版本冲突样本 | 新旧版本给出不同答案的问题 | 测试版本治理是否生效 |
| 权限测试样本 | 不同角色看到不同答案的问题 | 测试权限过滤是否正确 |
| 多跳推理样本 | 需要综合多篇文档的问题 | 测试跨文档关联能力 |
| 口语化样本 | 真实用户的原始问法 | 测试查询改写是否有效 |
大模型评测如果没有业务负样本,分数越高,线上误判可能越隐蔽。一个总是回答"知道"的系统,在正样本上得分很高,但在负样本上可能灾难性地编造答案。
评测驱动的迭代循环
每次修改分块策略、embedding 模型、rerank 模型、prompt 模板、知识库内容,都应该跑一次完整的评测集,记录每个指标的变化。
如果 Context Recall 下降了 → 分块可能切断了关键信息,或者新数据没有正确入库。
如果 Context Precision 下降了 → 知识库可能引入了太多噪声数据,或去重没做好。
如果 Faithfulness 下降了 → prompt 约束可能松了,或者上下文太长导致模型注意力分散。
如果 Answer Relevancy 下降了 → 查询改写可能有问题,或者召回了相关但不切题的内容。
成本与延迟:RAG 不是越复杂越好
RAG 系统每一步都有成本。
离线阶段:文档解析 + 清洗 + 分块 + embedding + 建索引。对于大型知识库,这个过程可能需要几个小时,embedding 调用也是按 token 计费的。
在线阶段:查询改写(可能调用 LLM)+ 向量检索 + 关键词检索 + rerank + 上下文拼接 + LLM 生成。
如果每次请求都召回 50 个 chunk、经过 rerank、再塞 20 个 chunk 给大模型,延迟和 token 成本会快速膨胀。
优化的方向不是"少调用模型",而是"少给模型无效上下文"
方向 1:分层检索。先用成本极低的 BM25 和向量召回做粗筛(毫秒级),再用成本较高的 cross-encoder reranker 精排(几十到几百毫秒),最后只把少量高质量上下文给 LLM(占总成本 80% 以上)。
方向 2:按问题复杂度路由。简单的 FAQ 类问题(“企业版月费多少”)可以直接走缓存或简单检索,不需要复杂的多路召回和 rerank。复杂的综合性问题才走完整链路。
方向 3:答案缓存。高频问题缓存检索结果或最终答案,但必须绑定文档版本——一旦知识更新,缓存立即失效。
方向 4:上下文压缩。不是把 chunk 原文全部塞进 prompt,而是用轻量模型提取每个 chunk 中与查询最相关的句子,压缩后再拼接。这可以在不损失相关性的前提下大幅减少 token 消耗。
方向 5:监控 token 消耗。很多团队只监控 API 调用次数,不监控每次调用的输入 token 数。一个输入 8000 tokens 的请求和一个输入 2000 tokens 的请求,成本差 4 倍。要监控的关键指标:输入 token 数、输出 token 数、检索片段数、rerank 耗时、端到端延迟、缓存命中率。
RAG 的成本优化不是少调用模型,而是少给模型无效上下文。一个精心设计的检索链路,可以让模型用更少的 token 给出更好的回答。
高级 RAG 模式:什么时候需要超越"向量 + 关键词"
GraphRAG:当问题需要跨文档关系推理
普通 RAG 擅长回答"某份文档里写了什么"。但它不擅长回答需要跨文档综合的问题:
- • “过去一年客户投诉最多的三个产品问题是什么?”
- • “这个供应商和哪些项目、合同、风险事件有关?”
- • “这批研究报告里反复出现的技术趋势是什么?”
这类问题不只是找相似片段,而是要理解实体之间的关系和全局结构。
GraphRAG 的思路是先从文档中抽取实体和关系,构建知识图谱,再结合图结构进行检索和生成。微软在 2024 年提出的 GraphRAG 框架表明,它在全局性、探索性问题上的回答全面性(72-83%)和多样性(62-82%)显著优于传统 RAG,同时根级别摘要所需的 token 量减少了 97%。
IBM 也指出,Shorthills AI 用 RAG + 知识图谱 + watsonx.data 构建的法律搜索系统,在数十万份法律文档上的召回率和精度提升超过 60%。
这张图说明 GraphRAG 如何把"文本片段集合"提升为"实体关系网络"。

但 GraphRAG 不是免费的升级:
- • 实体和关系抽取本身依赖 LLM,成本远高于普通分块。
- • 抽取错误会直接污染图谱,而且在图中传播(一个错误的关系边可能导致一连串错误的推理路径)。
- • 需要图数据库(Neo4j、ArangoDB 等)的运维能力。
- • 对于简单的"从文档找答案"场景,是严重的过度工程。
决策建议:先判断你的问题是不是"找一段文档"就能回答。如果是,普通 RAG 足够。如果问题需要跨文档关系推理、全局总结或多跳推理,再考虑 GraphRAG。
多模态 RAG:图片和表格不能只当文本
很多企业知识不在纯文本里:产品手册有截图,财务资料有表格,医疗资料有影像说明,制造业有设备图纸。
处理方式通常有三种层次:
层次 1:转文本。用文档解析器(Docling、Unstructured、Marker)把 PDF/PPT 中的图片、表格转成结构化文本后进入文本 RAG 链路。
层次 2:多模态 embedding。用 CLIP 等多模态 embedding 模型把图片和文本映射到同一向量空间,支持"用文字搜图片"“用图片搜文档”。
层次 3:视觉理解。检索到图片或表格后,把原始视觉内容一起送给多模态大模型(如 GPT-4o、Gemini)理解。
层次 1 最简单、成本最低,但会丢失视觉信息;层次 3 效果最好,但成本和延迟最高。大多数生产系统从层次 1 开始,在关键场景(比如含有复杂图表的技术文档)引入层次 3。
RAG、微调和长上下文怎么选
这是最常被问到的问题之一。答案不是"三选一",而是每种方案解决的问题不同。
| 需求 | 最佳方案 | 原因 |
|---|---|---|
| 模型不知道最新政策/产品信息 | RAG | 外部知识更新,不改模型 |
| 模型总是不按要求的格式输出 | 微调 | 改变模型行为和风格 |
| 需要一次性读完一整份临时报告 | 长上下文 | 放得下,不需要检索 |
| 需要从几十万份文档中精确回答 | RAG | 找得准,可治理,可更新 |
| 既要稳定的输出格式,又要最新知识 | 微调 + RAG | 微调管"怎么答",RAG 管"依据什么答" |
长上下文模型(128K、200K、甚至 1M tokens)的出现并没有让 RAG 过时。原因有三:
- 长上下文解决"放得下",RAG 解决"找得准"。把 50 万份文档全塞进上下文窗口既不现实(token 成本、延迟),效果也不好(Lost in the Middle 效应更严重)。
- RAG 提供可治理性。你可以控制哪些知识可以被检索、谁有权看、什么时候过期、新版本何时生效。长上下文做不到。
- RAG 提供可追溯性。每个回答可以标注引用来源。长上下文的回答你无法知道模型依据的是窗口里的哪一段。
微调教模型"怎么答",RAG 告诉模型"依据什么答",长上下文让模型"一次看更多"。这三个问题不要混在一起解决。
生产级 RAG 建设路线图
如果你从零开始搭建,建议按这个顺序,每一步验证后再往下走。
这张图展示了一个 RAG 系统从选型到持续运营的完整建设路线。
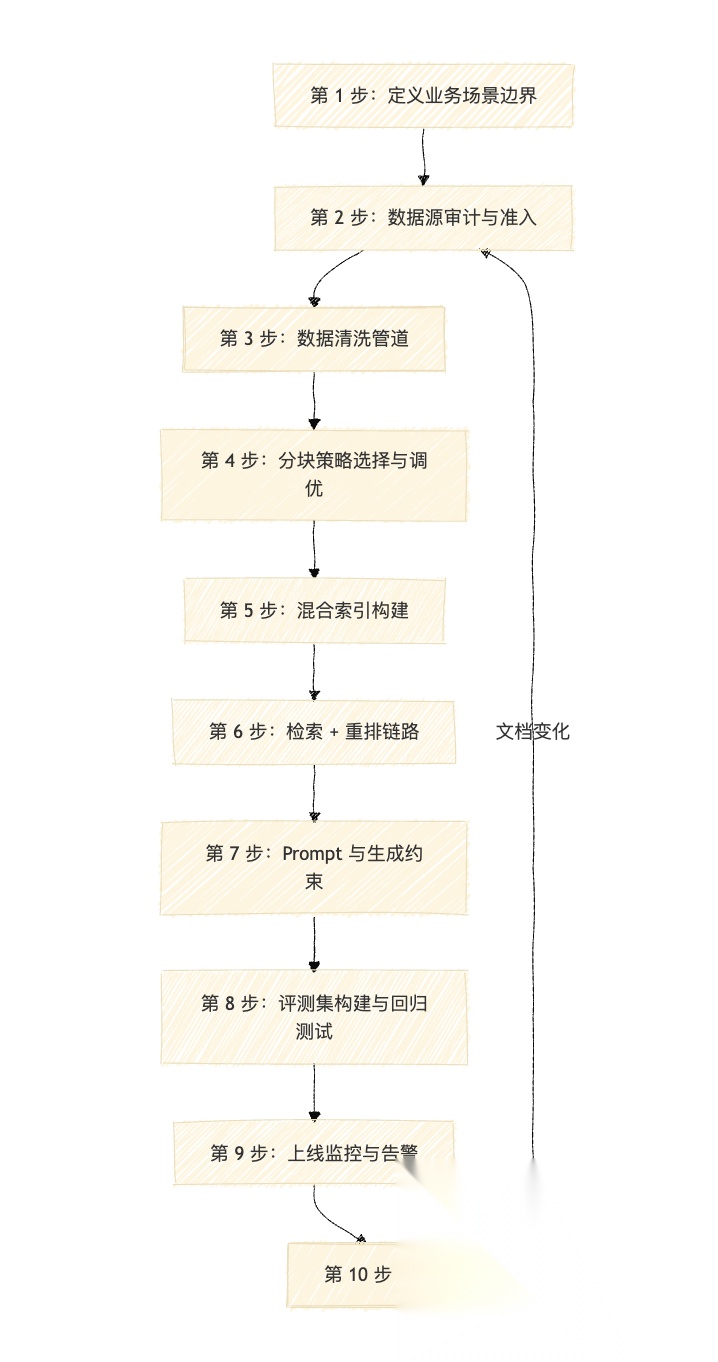
第 1 步:不要一上来做"公司全部知识问答"。先选一个边界清楚、数据质量高、用户需求明确的场景(比如售后 FAQ),跑通全链路。
第 2 步:明确哪些文档权威、哪些是草稿、哪些过期、谁负责更新、哪些需要权限隔离。
第 3 步:建立 ingestion 管道——支持多格式解析、内容清洗、语义去重、版本管理、权限标注、增量更新。
第 4 步:通用文档用递归分块(512 tokens,10-25% overlap),结构化文档按层级切,高价值文档做事实单元化。
第 5 步:同时建立向量索引和关键词索引(BM25),附带元数据字段索引。
第 6 步:多路召回 + RRF 融合 + cross-encoder rerank + 权限过滤。
第 7 步:设计严格的生成 prompt,包含引用要求、冲突处理规则、"不知道"的边界。
第 8 步:用真实问题构建评测集,覆盖正样本、负样本、版本冲突、权限边界、口语化查询。每次改动跑回归。
第 9 步:监控召回率、无答案率、用户反馈、延迟、token 成本、引用命中率、旧版本命中率。
第 10 步:RAG 不是一次性项目。文档会变、业务会变、用户问法会变。没有持续运营,知识库迟早变成"向量垃圾场"。
RAG 的尽头不是向量库,而是知识治理
很多团队第一次做 RAG,会把重点放在向量数据库选型、embedding 模型对比、LangChain vs LlamaIndex 上。这些都重要,但它们不是核心。
真正决定 RAG 上限的,是你能否回答以下问题:
- • 你是否知道每个回答的引用来自哪份文档的哪个版本?
- • 你是否能让旧版本在新版本发布后自动降权?
- • 你是否能证明某个用户不该看到某段资料?
- • 你是否能评估改了分块策略后准确率提升还是下降了多少?
- • 你是否能在文档更新后让所有相关答案同步更新?
- • 你是否能让模型在资料不足时承认"不知道",而不是编造一个看似合理的答案?
如果这些做不到,RAG 只是一个"会搜文档的聊天机器人"。如果做到了,RAG 才是企业知识系统的一层可信赖的智能入口。
RAG 最有价值的地方,不是让模型看起来更聪明,而是让模型的每一个回答都可溯源、可更新、可追责。这是从 demo 到生产的分水岭。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献188条内容
已为社区贡献188条内容

所有评论(0)