一个<think 标签,deepseek真的泄露用户隐私了吗?
你是否遇到过这样的场景——
在deepSeek开启全新对话后,输入 <think,没有按下回车补齐,没有上下文铺垫,就这么赤裸裸地把半个标签丢给了模型。然后,你看到了一段奇怪的输出:傅里叶级数、线性代数、中英文混杂、逻辑碎片化、像是在偷看别人的草稿纸……
我经过测试,发现不管是网页端还是客户端都有此问题
以下是在客户端的快速模式和专家模式下,分别不开深度思考和开深度思考,做的四次实验
 |
 |
 |
 |
以下是网页端做的实验,可以看到输出了傅里叶级数的内容

经过以上测试不难发现,不管是网页端还是客户端,输入<think都会出现此问题。
这就让许多人产生了本能的警觉:这是不是意味着AI在处理我的数据时存在隐私漏洞?这会不会把其他用户的对话泄漏出来了?
这篇文章,让我们从技术原理出发,剖析这个现象的真实面目,同时认真探讨那个敏感的疑问——它到底涉及隐私泄漏吗?
一、那堆输出的“傅里叶级数...线性代数...”究竟是什么?
要理解这个现象,先要了解DeepSeek这类推理模型工作的一个核心机制:<think> 标签。
简单来说,DeepSeek在处理复杂问题时,会在输出中插入一个“思考区”,格式如下:
<think> 这里是我在推理、验证、自我修正的内部过程……
最终我会把干净的回答放在这之后。
</think>
这部分内容相当于我的“草稿纸”——用来穷举可能性、检查逻辑、反复权衡。正常情况下,这部分被严格封装在标签中,并在最终渲染给用户时被隐藏,你只能看到标签闭合后的最终回答。
那么,当你输入 <think 并发送时,发生了三件事:
-
不完整的标签触发了模型的“补全本能” Transformer模型天然倾向于补全未闭合的结构。
<think没头没尾,模型会尝试把它变成一个合法的<think>...</think>片段。 -
系统进入了“思考状态”,但出口是乱的 因为开标签是你强制塞入的,而不是系统正常调度产生的,其内部标记可能出现错乱——系统可能在思考状态里打转,或把后续生成的内容错误地嵌套进标签逻辑中。
-
原本该隐藏的“草稿”被意外渲染出来 由于标签未正确闭合,前端没有收到清晰的“思考结束”信号,于是开始直接输出那些原本该被过滤的内部生成片段——这就是你看到的那段“意识流文字”。
下面看大致流程图:
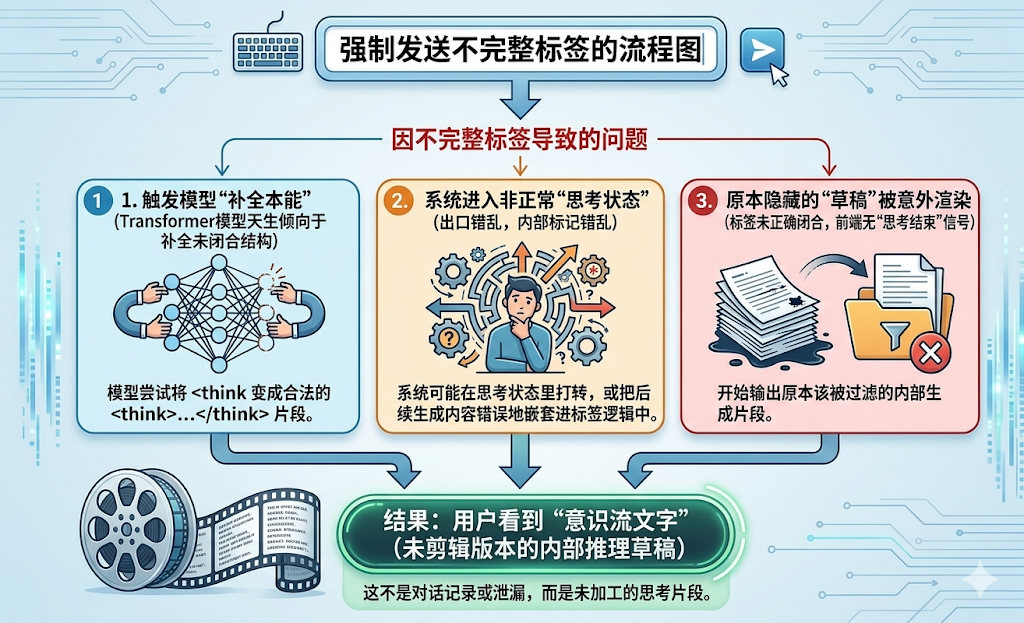
换句话说,你看到的不是任何人的对话记录,也不是后台数据库的泄露片段,而是:你的这次请求所触发的一次内部推理草稿的未剪辑版本。
二、隐私疑云:这是否意味着用户数据不安全?
这是最严肃的问题,也是任何技术人员在面对这种现象时必须坦诚回答的。
2.1 先明确它泄漏的是什么
这个现象泄漏的,是当前会话中模型针对你这条输入所生成的“即时思考碎片”,而非任何以下内容:
-
❌ 其他用户的历史对话
-
❌ 存储在服务器端的对话日志
-
❌ 训练数据中的原始文本
-
❌ 系统提示词或后台指令
原因在于深度学习推理的本质:模型的每一次生成都是无状态的(在单次请求内),它不会主动从磁盘或数据库里“拉取”一段别人的聊天记录插入到输出中,除非这段记录已经在当前上下文窗口内。而新对话的上下文,除了系统预设的极少量提示外,只有你刚输入的那几个字符。
2.2 那么,它能反映模型的“记忆”吗?
有人会追问:如果模型在预训练时记下了某些训练数据,会不会通过这种异常输出泄漏出来?
这是个大模型领域的老问题——训练数据记忆与提取攻击。理论上,如果训练语料中包含 <think> 标签及相关文本,模型确实可能在异常状态下生成类似片段。但目前观察到的这次现象中,输出的内容呈现出明显的无意义拼接与语法崩坏,更符合“解析器内部状态混乱导致的噪音生成”,而非有结构的信息片段。
结论:此现象更接近一次“格式化错误”,而非“数据库查询”。
三、触发原因技术深潜:为什么偏偏是这几个字符?
让我们把技术镜头拉得更近一些。
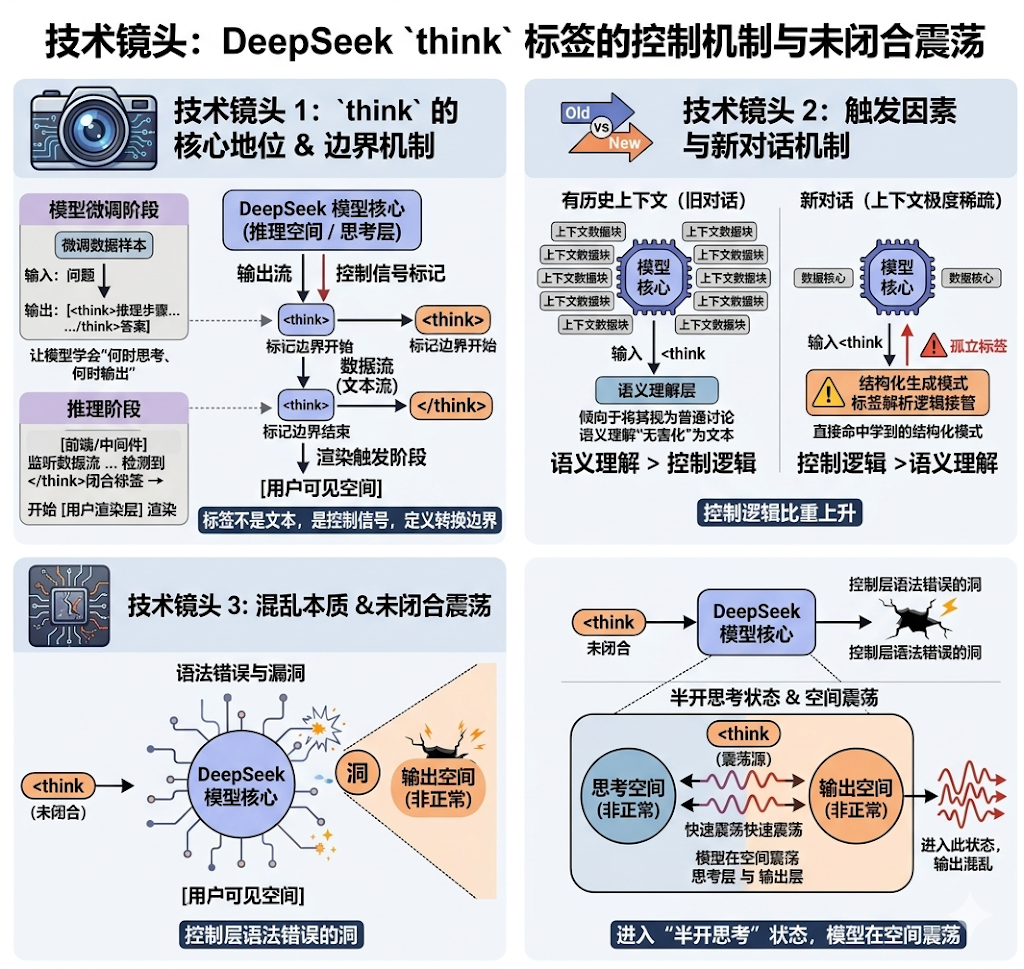
3.1 <think 的特殊地位
在DeepSeek的输出流中,<think> 标签不是简单的文本,它具有控制信号的语义:标记了从推理空间到用户可见空间的边界转换。这种机制通常通过以下方式实现:
-
模型微调阶段,用大量
<think>...<think>格式的样本训练,让模型学会“何时思考、何时输出” -
推理阶段,前端或中间件监听输出流,检测到
</think>闭合标签后,开始向用户渲染后续内容
当你输入 <think 而不闭合它,相当于在控制层砸出一个语法错误的洞。
3.2 为什么全新对话下更容易触发?
在有历史上下文的情况下,模型倾向于认为你输入的 <think 是普通讨论的一部分,用语义理解将其“无害化”。但在新对话中:
-
上下文极度稀疏,模型的控制逻辑比重上升
-
无其他语义线索压制,标签解析逻辑接管
-
“孤立的未闭合标签”这一信号会直接命中训练阶段学到的结构化生成模式3.3 输出混乱的本质
一旦进入这种“半开思考”状态,模型可能在以下空间内震荡:
-
尝试生成
>来闭合标签 -
尝试在思考区内进行推理,但因为输入只是一个裸标签,没有实际问题可分析
-
陷入类似自回归的语言模型生成循环,基于之前生成的无意义token继续生成无意义token
这解释了你看到的乱码的“风格”——它是模型在错乱的控制状态下,对空白提示的“联想跳跃”。
四、安全视角:这算漏洞吗?
严格来说,这是一个边缘行为,不是一个安全漏洞。
它在安全三要素上的表现如下:
-
机密性:未泄漏其他用户或系统级机密数据。泄漏的是当前用户自身查询触发的即时推理噪音。
-
完整性:未破坏系统的正常功能,也未允许越权操作。
-
可用性:未导致服务中断。
但从稳健性角度,暴露内部推理碎片确实是一种信息泄漏,尤其是在生产环境中可能引起用户误解。因此,对于模型开发者,这是一个值得修复的“输出过滤异常”。
五、我们该如何看待这次“意外”?
这次现象,本质上是复杂AI系统在遇到非预期输入时的一次“格式错误”。它像一阵风,吹开了AI草稿纸的一角,让我们瞥见了思考区内的混乱涂鸦。
对用户而言:
-
我没有窥见别人的隐私,不用担心
-
我也无法通过这个技巧“黑”出后台数据
-
我只是看到了一次有意思的内部状态泄漏,值得作为理解LLM工作方式的窗口

-
对开发者而言:
-
这个现象提示了输出过滤的鲁棒性需要加强
-
当模型的控制标记暴露在用户输入通道时,必须有更严格的解析与转义机制
-
在追求“思考可见”的透明性时,也要确保“思考不可挟持”
-

-
在文章的最后
AI的“思考”在现阶段还远不是意识,只是一种结构化的生成策略。但当我们意外看到那些本应被隐藏的推理碎片时,一种错觉会油然而生——仿佛我们在偷看另一个心智的内心独白......
这次
<think标签所引发的问题,最后教给我们的或许不是恐惧,而是好奇:当机器学会在说话前先打草稿,我们人类,是不是也该偶尔停下来,好好看看自己的思考过程?因为现在短视频兴起多少年了,人们都很浮躁,多少人正在逐渐失去阅读长文的能力,逐渐失去自己的思考......当然了,最重要的还是安全性,相信deepseek官方一定会尽快修复这个问题。
我是爱三盖浇饭,欢迎点赞关注留言评论~~~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)