[智能体-100]:采样策略深度详解:temperature /top_p/top_k
三者都是大模型解码阶段的采样规则,决定模型从候选词(token)里「选哪个词往下生成」,直接控制回答的确定性、流畅度、创造性、随机性。结合原理、场景、对比、实操示例完整讲解,同时讲清为什么官方建议 temperature 和 top_p 尽量二选一。
前置基础:Token 候选池原理
大模型每生成一步,都会输出全量 Token 词汇表的概率分布:词汇表里成千上万个候选 token,每个都有一个 P(概率),概率越高,模型认为这个词 “接下来出现的可能性越大”。采样策略,就是对这个概率池做筛选 + 加权,再从中挑选最终输出的 token。
举例:输入
春天来了,花园里开满了?模型算出候选:
花朵(0.7)、鲜花(0.2)、野草(0.05)、冰雪(0.03)、飞鸟(0.02)不同采样参数,会从这批候选里选出不同结果。
一、temperature 温度系数(最常用)
1. 核心原理
temperature(简称 temp)本质是对原始概率分布做「平滑 / 锐化」缩放,公式简化理解:
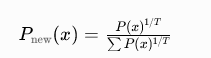
- T = temperature 温度值
- T 越小:概率分布越尖锐,高概率 token 优势被放大,模型优先选最稳妥的词
- T 越大:概率分布越平缓,高低概率差距缩小,低概率冷门词也有机会被选中,随机性变强
2. 取值区间与行为(0.0 ~ 2.0)
① temperature = 0.0 (零度,贪心采样)
- 规则:永远选择当前概率最高的 token,完全无随机。
- 表现:回答固定、逻辑严谨、几乎不会跑偏,多次请求同一问题,输出完全一致。
- 适用场景:代码编写、数学计算、逻辑推理、指令执行、标准化问答、JSON 结构化输出。
- 反例效果:创意内容会极度单调、重复、死板。
实操示例提问:1+1等于几?temp=0 → 固定输出:1+1等于2,无论调用多少次结果不变。
② temperature = 0.6 ~ 0.8 (均衡区间,默认常用)
- 规则:小幅放大随机性,优先选高概率词,偶尔穿插自然变体。
- 表现:流畅自然、有少量表达变化,逻辑不跑偏,兼顾自然度与稳定性。
- 适用场景:日常对话、知识问答、办公文案、总结翻译(绝大多数业务场景)。
实操示例提问:简单介绍一下人工智能
- 第 1 次:
人工智能是利用计算机模拟人类智能的技术…… - 第 2 次:
人工智能指机器模仿人类思考与行为的相关技术……内容核心一致,句式略有区别,自然不生硬。
③ temperature = 1.0 (默认值)
- 规则:使用模型原生概率分布,不做额外缩放。
- 表现:随机性正常,创意与稳定性持平。
④ temperature = 1.2 ~ 2.0 (高温度,高发散)
- 规则:概率被大幅拉平,冷门、低概率 token 被选中概率剧增。
- 表现:想象力强、句式多变、文采丰富,但逻辑易断裂、容易出现幻觉、答非所问。
- 适用场景:写诗、故事创作、脑洞文案、角色扮演、创意发散。
实操示例提问:写一句描写晚霞的短句temp=1.8
- 版本 1:
晚霞揉碎了落日,把橘色温柔洒向整片天际 - 版本 2:
天边燃起火红云霞,晚风携着余晖漫过街巷 - 极端情况(temp=2.0):可能出现语义不通的句子。
3. 关键总结
- 控整体随机程度的万能参数;
- 越低越稳、越高越放飞;
- 工业级标准化接口、高精度场景优先拉低温度。
二、top_p 核采样(Nucleus Sampling,推荐替代高 temp)
1. 核心原理
不再看单个 token 概率,而是从概率累积总和达到 top_p 的候选集合里采样,也叫「阈值截断采样」。执行步骤:
- 把所有 token 按概率从高到低排序;
- 从第一名开始累加概率,直到累计和 ≥
top_p,停止; - 只在这一部分候选池里随机选词,后面低概率的 token 直接丢弃。
取值范围:0.0 ~ 1.0,默认 1.0(不做截断,使用全量候选)。
2. 典型取值与示例
示例场景
候选 token 及原始概率(从高到低):A(0.6)、B(0.2)、C(0.1)、D(0.06)、E(0.04)
① top_p = 0.9(最经典配置)
逐步累加:0.6(A)+0.2(B)+0.1(C)=0.9
- 候选池:仅保留 A、B、C;D、E 被直接过滤。
- 效果:只保留高概率、高质量的候选词,剔除边缘冷门词;在保证流畅度的前提下增加少量变化。
- 特点:相比拉高
temperature,top_p=0.9更不容易出现病句、幻觉,是业界公认「流畅 + 创意」的平衡方案。
② top_p = 0.5(严格截断)
累加至 0.5 停止,仅保留高概率头部 token。
- 效果:输出非常保守、变化极少,接近低温效果。
③ top_p = 1.0(默认)
不做任何截断,使用全部候选 token。
3. 适用场景 & 优缺点
✅ 优点:
- 优先淘汰低质量、低概率的生僻词,幻觉、语病概率远低于高 temperature;
- 不强行扭曲原始概率分布,更贴合模型本身的语言习惯。
❌ 缺点:极致创意场景表现力不如高 temperature。
4. 经典用法
日常对话、文案、长文本生成:top_p = 0.8 ~ 0.95,搭配 temperature=1.0(只开 top_p)。
三、top_k 前 K 采样(小众补充方案)
1. 核心原理
规则最简单:只保留概率排名前 K 个 token,其余全部丢弃,再从前 K 个里面随机选择。
- 取值:正整数 1 ~ 100;无限制时等价于关闭 top_k。
2. 取值演示
沿用上面候选:A(0.6)、B(0.2)、C(0.1)、D(0.06)、E(0.04)
top_k = 1:只选 A → 完全固定输出,等价temp=0;top_k = 3:候选池 = A、B、C;top_k = 5:全部保留,无限制。
3. 特点与使用场景
- 控制逻辑粗暴直接:按「数量」截断,而非按「概率」截断;
- 缺陷明显:
- 若前 K 个 token 概率都很低,依然会强制从中选词,容易出病句;
- 无法区分 “高质量低概率” 和 “垃圾低概率”。
- 现状:OpenAI 系列模型不推荐优先使用,仅部分开源模型(LLaMA、Qwen)作为补充参数;一般用于极端限制发散的场景,绝大多数业务可以忽略。
四、重点:为什么官方建议 temperature 与 top_p 二选一?
1. 底层冲突
两者都是对同一套概率分布做筛选 / 变换,叠加使用会互相干扰,逻辑不可控:
- 先调
temperature扭曲整体概率; - 再用
top_p做概率累加截断;最终效果无法预判,随机性、稳定性彻底失控。
2. 两套标准选型方案(二选一模板)
方案一:只用 temperature(简单直白,新手首选)
- 严谨类(代码 / 数学 / 接口输出):
temp = 0.0 ~ 0.3 - 通用对话:
temp = 0.6 ~ 0.8 - 创意类(写作 / 诗歌):
temp = 1.2 ~ 1.8 top_p = 1.0(关闭)
方案二:只用 top_p(专业优选,流畅度更高)
固定 temperature = 1.0(关闭温度调节)
- 偏严谨:
top_p = 0.6 ~ 0.7 - 通用平衡:
top_p = 0.8 ~ 0.9 - 偏创意:
top_p = 0.95 ~ 1.0
3. 叠加使用的坑(避坑)
同时设置 temp=1.5 + top_p=0.9:概率被放大 + 强制截断,输出风格混乱,极易出现语义断裂、无意义文本,生产环境严禁这样搭配。
五、三者横向对比表
| 参数 | 控制逻辑 | 核心特点 | 推荐场景 | 主流优先级 |
|---|---|---|---|---|
| temperature | 缩放全局概率分布 | 调整体随机度,上限高,易出幻觉 | 代码、数学、强创意写作 | ★★★★★(通用首选) |
| top_p | 按概率累加截断候选池 | 保留高质量 token,流畅度高、幻觉少 | 对话、文案、长文本、知识库问答 | ★★★★☆(专业场景首选) |
| top_k | 按固定数量截断候选池 | 规则简单粗暴,易引入劣质 token | 小众开源模型、极端控发散 | ★☆☆☆☆(尽量少用) |
六、可直接复用的实操配置(OpenAI API)
1. 高精度 / 代码 / 数学计算
json
{
"temperature": 0.2,
"top_p": 1.0
}
2. 日常对话 / 知识问答(平衡版)
json
{
"temperature": 0.7,
"top_p": 1.0
}
3. 文案 / 软文 / 故事创作(创意版)
json
{
"temperature": 1.4,
"top_p": 1.0
}
4. 长文本 / 翻译(top_p 方案,低幻觉)
json
{
"temperature": 1.0,
"top_p": 0.9
}
七、一句话总结
- temperature:调整体 “脑洞大小”,数值越大越放飞;
- top_p:筛选 “优质候选词”,在可控范围内增加变化,更稳更流畅;
- top_k:按数量硬筛,功能老旧,OpenAI 场景基本不用;
- 生产环境严格二选一,不要同时微调 temperature 和 top_p。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献109条内容
已为社区贡献109条内容

所有评论(0)