上下文是你的 · Agent 是雇的 · 三步节省 90% Token 账单
上下文是你的 · Agent 是雇的
不重写,不压缩,90% Token billing Saving
同一块 IR 跨 Anthropic · OpenAI · DeepSeek · vLLM · SGLang 原样落地
真实 6 轮会话 −92.3% · 按"绝对 $/已解决查询"记账,比例你随便造,美元不陪你演
[https://github.com/learningCatHD/telos-sdk] · Apache 2.0
⬢ 凌晨两点,钱是怎么烧没的
凌晨两点,agent 还在跑。终端右下角的计数器爬到 2,847,103 —— 你换算成美元,倒吸一口冷气。更冷的是再上一行:cache_read: 0。一整夜,每一轮都把那 4,000 字的开头从头喂了一遍给模型,按全价收。
把同一段 6 轮真实对话扔进 openclaw,只切两种开关 ——
| 模式 | raw input tokens | cache_read | 这 6 轮花了多少 |
|---|---|---|---|
| passthrough(今天的默认) | 24,151 | 0 | $0.3623 |
| 接入 TELOS | 0 | 18,701 | $0.0281(−92.3%) |
放大到一千次会话,就是从 $362 → $26。换算到长跑的真实跑批(showcase/dashboard.html,2026-05-19):48 calls / 4 sessions,反事实账单 $5.90,接入后只花 $3.74 —— 净省 $2.16(−36.6%)。这是一次受控 A/B/C/D 对照、一台开发机一个下午的事,乘到团队规模,每月就是一张实打实的服务器账单。
别再拿"省了几倍 token"哄自己。 2026 年同模型族的档位价差已经撑到 80×~150×,谁都能把廉价档塞进分母吹一个漂亮比例 —— 真金白银的美元不会陪你演戏。

⬢ 这不是个别 case —— agent 推理的基础设施,瘸着两条腿
第一条腿:Token 烧得又快又冤。 二十轮对话里,那段 4,000 字的系统提示词被原原本本读了二十遍。Anthropic 的缓存命中只付 10%、没命中按 100% 收 —— 而你只要在系统提示词里悄悄塞一行 currentDate: 2026-05-20,整段 PIN 当晚作废,命中归零。这道闸门,从来没人替你关上。
第二条腿:上下文主权根本不在你手里。 你花一整天调出来的人设、跑通的工具链、二十轮聊到一半的进展,全都困在对方的服务器里。你想换 DeepSeek 试试,对面第一句话是:“请简单介绍一下你的项目。” 你想把任务交给更擅长那一段的家伙,做不到。账单出来,是一个被分母稀释过的百分比。你不是 agent 的主人,你是别人 agent 里的"租客"。

⬢ TELOS 只解决两件事
① 把 Token 效率推到极致。 6 轮真实对话 −92.3%;48 次调用的受控跑批 节省 36.6%(净 $2.16)。每一分钱都按"绝对 $/已解决查询"记账 —— 比例可以作弊,绝对美元不会。
② 把上下文主权交还给你。 TelosIR 是一份引擎无关、可序列化、能带走的上下文表示。你的人设、你的工具、你二十轮聊到一半的进展,统统装进同一块石板里 —— 今天递给 Claude,明天搬到 DeepSeek,晚上换本地 vLLM。上下文是你的,Agent 是雇的。
⬢ 协议本体:不是压缩,是不破前缀
大多数 agent 框架把 KV cache 当成推理引擎可能给、也可能不给的运行时彩蛋。TELOS 反过来 ——
缓存的复用,是 prompt 自身的结构性属性,不是运行时的好运气。如果你永远不去动已经提交的字节,缓存就不可能失效。
这条立场落到协议里,是三件层层叠合的事。
三色带

每一个内容块在出生时就声明它的缓存生命周期 —— 不是事后启发,不是靠 LLM 猜,是一等结构标注:
| 带 | 颜色 | 语义 | 缓存行为 |
|---|---|---|---|
| PIN | 🟢 | 工具说明 · 系统提示 · 当前问题 | 永久。永不驱逐。每次请求 prefix hash 的不可变底座 |
| FOLD | 🟡 | 历史对话 · 工具返回 · 大文档 | 可缓存可折叠。压力大时换成摘要 —— PIN 前缀字节保持不变 |
| DROP | 🔴 | 时间戳 · CWD · git 状态 · PID | 即焚。整段排除在 prefix hash 之外。必须放在所有 BP 之后,绝不污染上游字节 |
顺序铁律是绝对的:PIN* → FOLD* → DROP*。每条消息内、整段 prompt 内、所有层级。这是唯一赢得缓存的结构规则 —— 其它都是实现细节。
单调追加
prompt 是一条只追加的流。新轮次只往尾巴加块,绝不修改已经提交的字节。所谓"修改",是用新块(摘要、redaction)表达,不是原地重写。

正因为更早的块不可变、跨轮字节相同,推理引擎的 prefix-matching 算法在每一次请求都能找到最长公共前缀 —— 不是靠运气,是构造而成。缓存命中率因此是会话长度的单调非递减函数:会话越长,复用越多,绝不倒退。
一份 IR,五个后端
同一份 TelosIR 落到不同引擎,由 adapter 做确定性降级:Anthropic 的显式 BP、OpenAI 的 prompt_cache_key、DeepSeek 的字节稳定前缀、vLLM 的 cooperative eviction、SGLang 的 RadixAttention —— 每家引擎都被推到它实际能到的缓存上限,而你的 agent 代码一行不改。
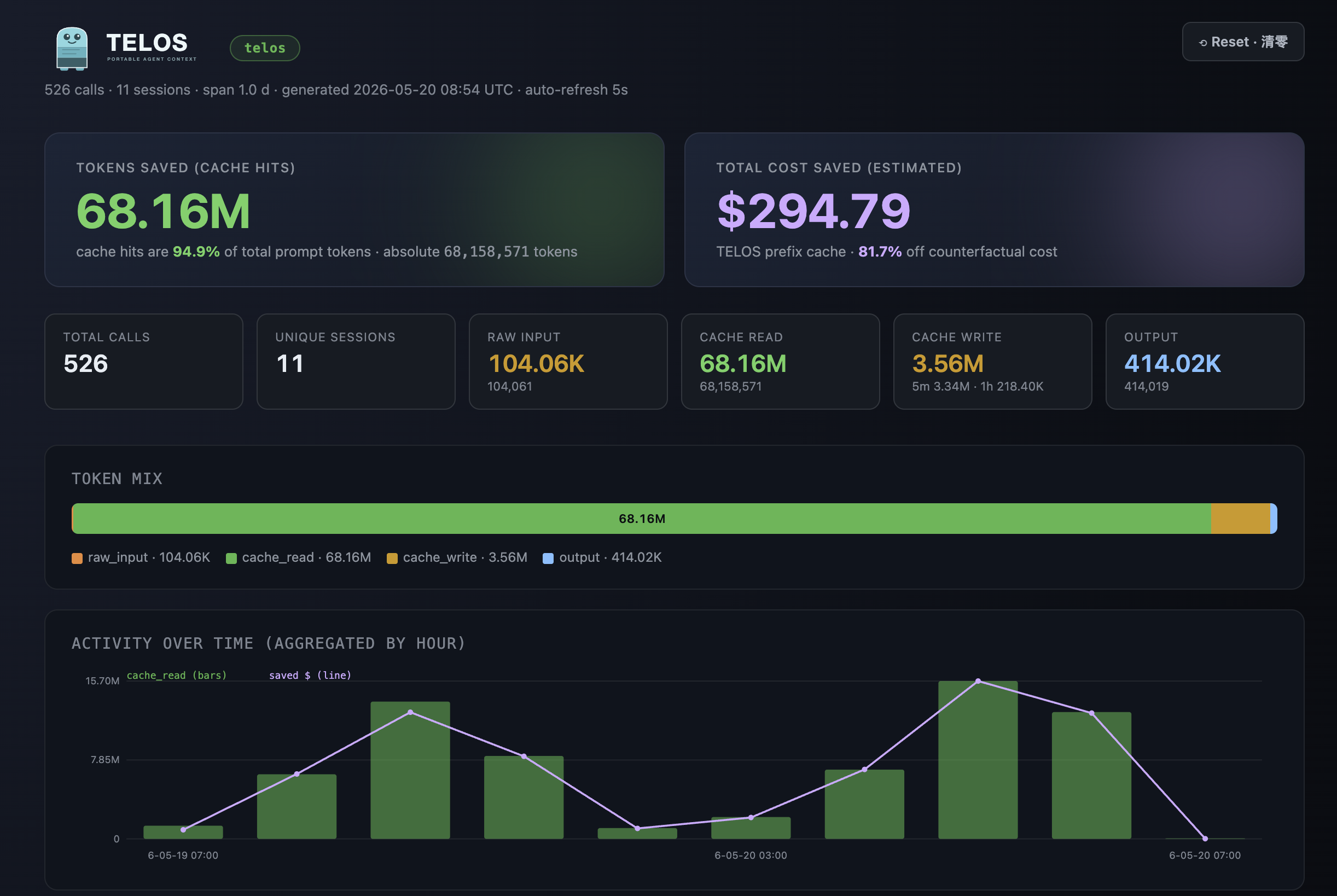
每一笔节省都被钉在绝对美元上 · 无需云端 server · 离线打开 · ~/.telos/usage.jsonl 直接喂进单页 HTML
⬢ 三步上手:零侵入,先把账单点亮
❶ 安装
pip install telos-sdk
❷ 接入
telos init
自动识别本机的 claude-code / codex / openclaw / hermes,逐个注入配置,并在后台拉起本地网关(状态写入 ~/.telos/gateway.json)。Agent 代码无需任何修改。
❸ 观测
telos dashboard
在浏览器中打开离线 HTML 看板,按绝对美元逐笔呈现节省。每一次调用自动追加至 ,实时聚合。
TELOS 已经开源。在自己的工作流上跑一遍 —— 看看那省下来的 92%,是真的,还是又一次"几倍 token"。
[https://github.com/learningCatHD/telos-sdk] · Apache 2.0
Token efficiency is not about compression — it’s about never breaking the prefix.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)