Runnable 才是 LangChain 真正的骨架:一次读懂 Invoke、Batch、Stream
读完这篇,你应该会把LangChain 的理解顺序彻底倒过来,不是先有 Chain、再有Agent、最后才碰Runnable。而是恰恰相反。LangChain 先把几乎所有能力都压成Runnable,再在它上面长出 LCEL、RAG、Chain、Agent 和一整套运行时能力。
你会在这篇文章里得到什么
- 一张看清Runnable在 LangChain 里的总骨架图
- 一套读懂 invoke、batch、stream的统一协议心智模型
- 一个判断“为什么 stream 没有流起来”的源码级排障框架
适合谁
- 工程实践者、框架阅读者、需要讲清 LangChain 内核的人。
- 如果你已经会写
prompt | model | parser,但还是觉得 LangChain 的概念太散,这篇会很有用。
01
—
背景:为什么我说骨架不是 Chain,而是 Runnable
很多人第一次学 LangChain,是从LLMChain、RetrievalQA、AgentExecutor 这种“现成对象”入手的。但沿着源码往下走,你会发现这些名字更像“产品层包装”,真正稳定的执行面其实是 Runnable。一个非常强的信号是:在源码 langchain/langchain_classic/chains/llm.py 里,LLMChain已经被标记为 deprecated,替代方案直接写成 RunnableSequence, e.g: prompt | llm。
这不是小改名。这意味着官方自己的抽象重心,已经从“预制 Chain 类”转向“可组合的统一执行协议”。
一句话结论,Runnable统一了三件事:
- 统一能力对象:Prompt、Model、Retriever、Tool、Parser、History 都能落到同一执行面
- 统一组合方式:串联是RunnableSequence,并联是 RunnableParallel
- 统一运行时能力:config、tracing、retry、fallback、history、dynamic config 都跟着协议走
02
—
总骨架:LangChain 先把一切压成 Runnable
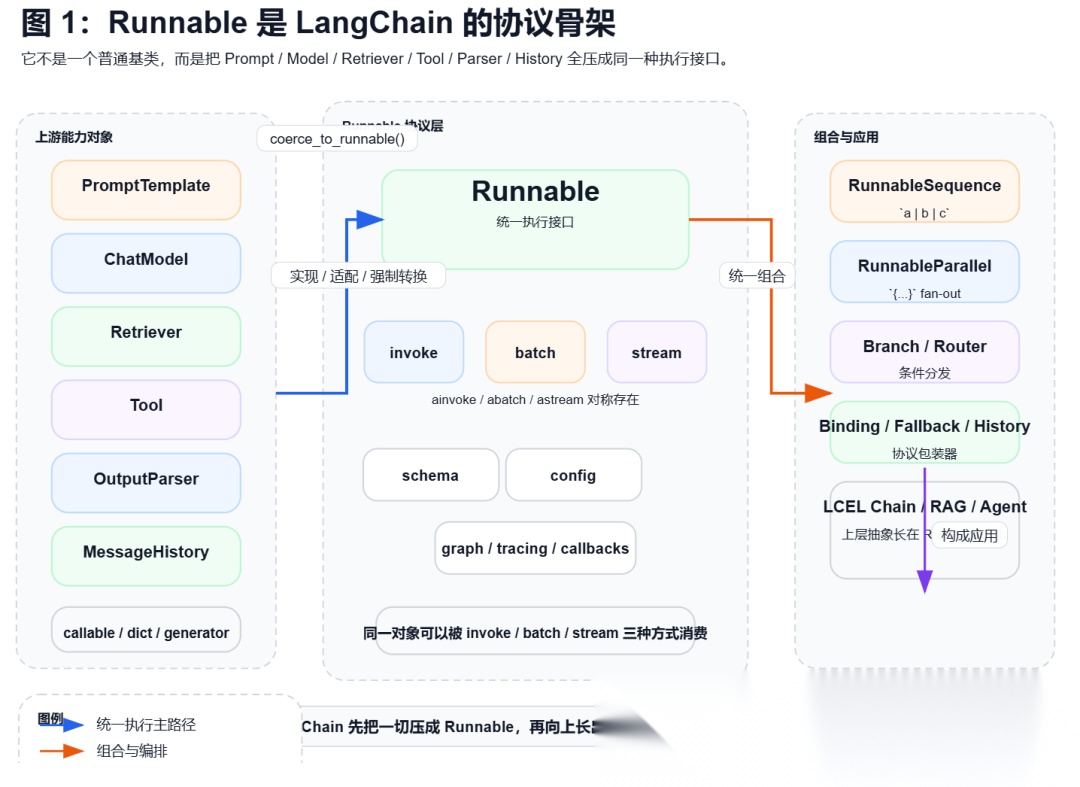
如果只看`libs/core/langchain\_core/runnables/\_\_init\_\_.py`和 `base.py`(langchain源码) 的导出面,你会发现一个非常清晰的世界:
- 核心抽象是
Runnable - 组合原语是
RunnableSequence和RunnableParallel - 包装器生态包括
RunnableBinding、RunnableWithFallbacks、RunnableWithMessageHistory - 结构改写工具包括
RunnableAssign、RunnablePick、RunnablePassthrough - 控制流扩展包括
RunnableBranch、RouterRunnable
也就是说,LangChain 并不是让每个高层对象都自带一套独立调用协议。它做的事更像是:先把异构对象都压扁成 Runnable,再让它们用同一种方式被调用、被组合、被追踪。这就是“骨架”的定义。
03
—
三个名字,其实是一套协议:invoke、batch、stream
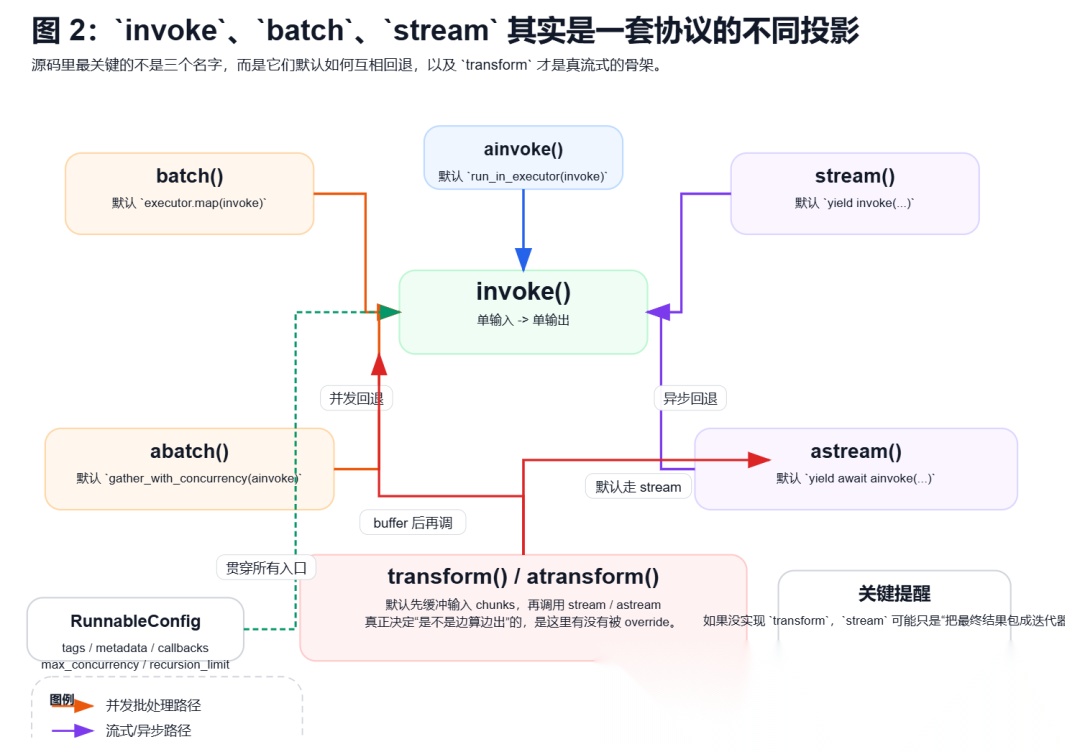
源码里最值得反复看的,其实不是某个具体子类,而是 libs/core/langchain\_core/runnables/base.py 这一层的默认实现关系。
invoke是单输入、单输出。
batch默认不是“模型厂商的原生批量接口”,而是“并发地调用很多次 invoke”。同步版本默认走线程池,异步版本默认走 gather_with_concurrency。
stream 默认也不是天然 token streaming。对于基类来说,它只是把 invoke 的最终结果 yield 出去。
最容易被忽略的一层其实是 transform:
stream面向“单个输入,输出一个迭代器”transform面向“输入本身就是 chunk 流,输出也是 chunk 流”
而基类默认的 transform 会先把输入 chunk 缓冲起来,再去调 stream。
所以从源码角度讲,真正决定“是不是边算边出”的,不是接口名里有没有 stream,而是中间节点有没有认真实现 transform。
最小伪代码其实只有这一段:
chain = prompt | model | parser
chain.invoke(x) # 单次执行
chain.batch([x1, x2]) # 并发批量
for chunk in chain.stream(x):
...
对调用者来说,链没变。变的只是“消费方式”。这正是统一协议的价值。
04
—
真正的组合原语只有两个:串联和并联
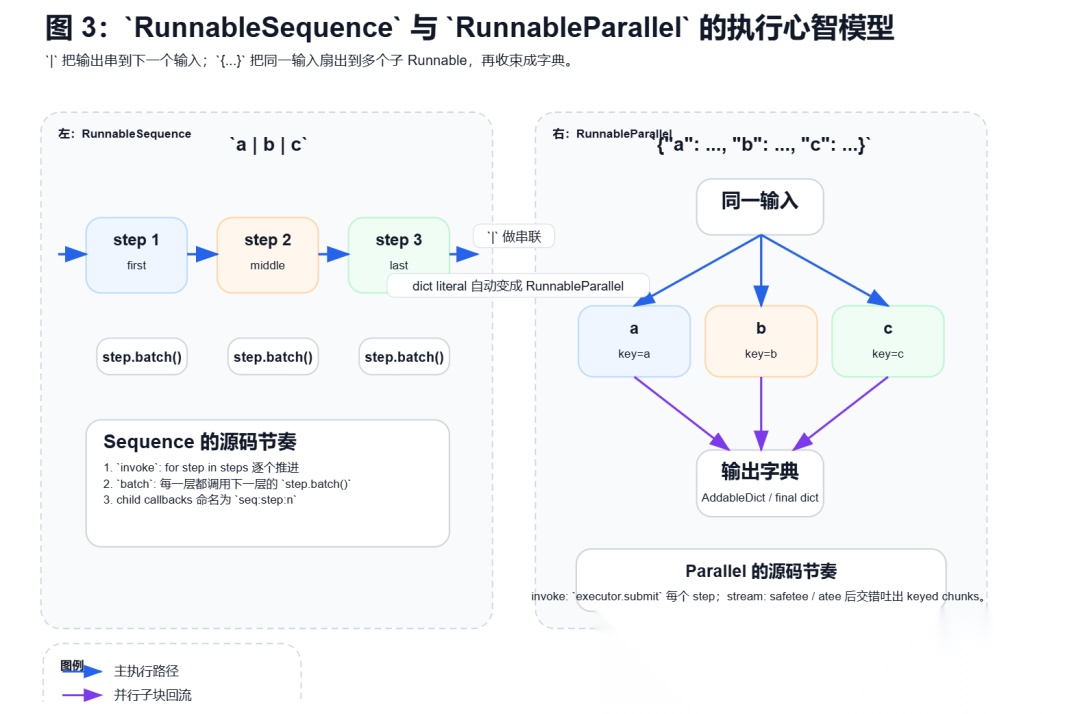
RunnableSequence 是 LangChain 里最重要的组合器,这句话甚至直接写在 base.py 的 docstring 里。
它的本质非常直接:上一个 step 的输出,就是下一个 step 的输入。
但源码里有两个细节非常关键:
-
batch不是把整条链一起批量化,而是“一层一层向前推进”,每个 step 都调用自己的step.batch() -
tracing 不是糊成一团的,子运行会被打上
seq:step:n这样的child callback
标记RunnableParallel 则是另一种完全不同的语义:
- 同一个输入,被扇出给多个子 Runnable
invoke时并发执行stream时交错吐出 keyed chunks,最后再合成字典
这也是为什么在 LCEL 里,一个普通的 Python dict 能直接成为并联节点。
因为 coerce\_to\_runnable() 会把它自动提升为 RunnableParallel。
所以从读源码的角度,LCEL 其实不是“新语言”。
它只是把两种最核心的图结构写得更顺手了:
|= 串联{...}= 扇出并联
05
—
为什么很多 stream 看起来不流?答案在 transform 边界
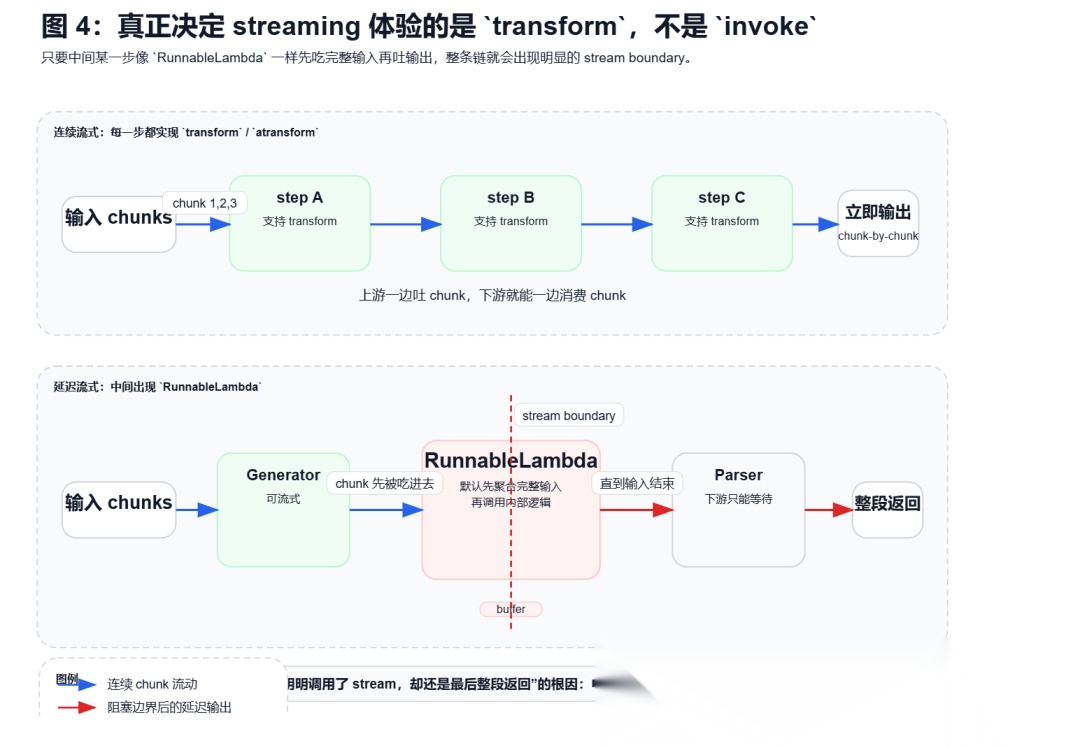
这是 Runnable 体系里最容易讲错的一点。很多人会下意识地认为:只要我调用了 stream(),系统就应该一边生成一边往下游传。源码告诉你,不一定。
在 RunnableSequence 的实现里,整条链能不能真正连续 streaming,取决于每一个组件是否都实现了 transform。只要中间有一步是阻塞型的,后面的流就会被截断。
最典型的就是 RunnableLambda。它非常好用,但 base.py 的说明写得也很直白:它默认并不擅长 streaming;如果你要做“边接收上游 chunk,边吐下游 chunk”的逻辑,更合适的是 RunnableGenerator 或者你自己实现 transform。
所以一个特别实用的排障句式是:
不是“为什么 stream() 失效了?”而是“这条链中间哪个节点没有实现 transform,导致出现了 stream boundary?”这个判断一旦建立起来,你看 LangChain 的 streaming 问题会快很多。
06
—
Runnable 的外骨骼:为什么 retry、fallback、history 都能无缝粘上来
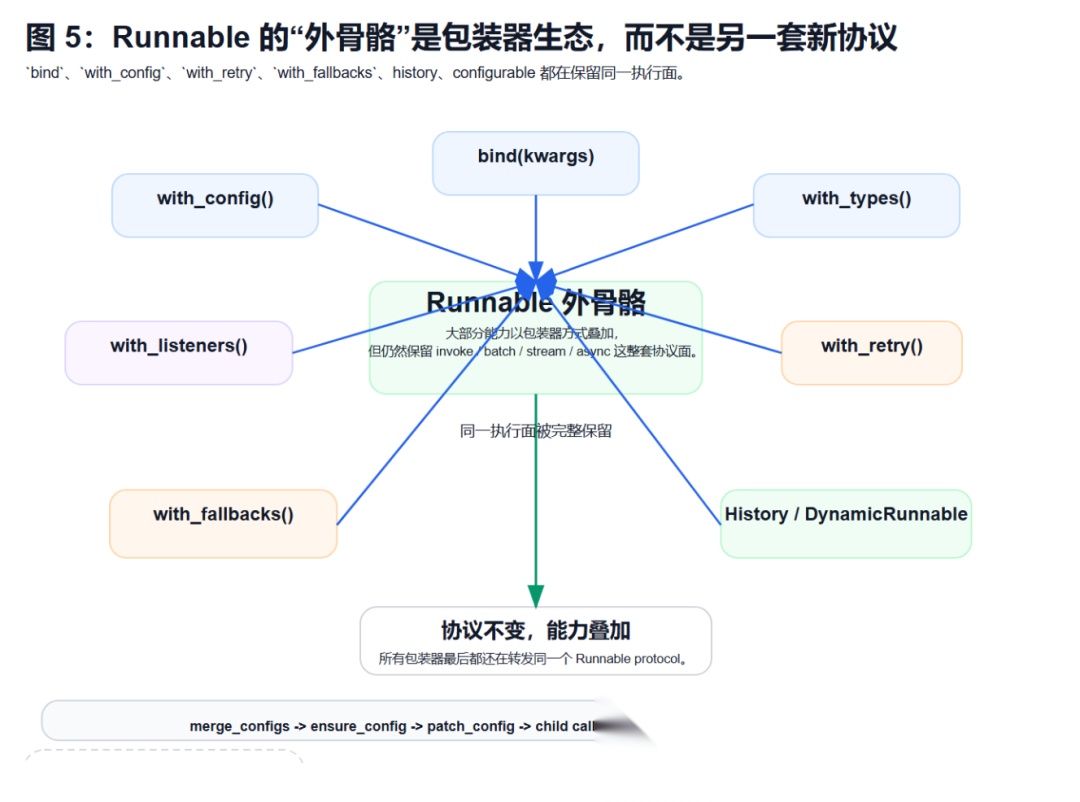
如果说 Sequence 和 Parallel 负责的是“结构”,那 Binding 和各种 wrapper 负责的就是“运行时外骨骼”。源码里这一层也非常漂亮。
你会看到很多能力都不是重写一套新协议,而是在保留 invoke / batch / stream 的前提下,包一层:
bind()负责绑定额外 kwargswith\_config()负责绑定运行配置with\_retry()负责失败重试with\_fallbacks()负责降级切换RunnableWithMessageHistory负责会话历史DynamicRunnable负责运行时可配置替换
这件事的威力在于:你不用为了 tracing 造一套新对象,也不用为了 fallback 再改一套链路。因为大家都认同同一个协议面,所以能力可以横向叠加。再往下一层看 libs/core/langchain\_core/runnables/config.py,你会发现 RunnableConfig 也不是“可选参数包”这么简单。
它真正承担的是协议传播:
tagsmetadatacallbacksmax\_concurrencyrecursion\_limitconfigurable
ensure\_config() 负责兜底和继承,patch\_config() 负责给 child run 打补丁,ContextThreadPoolExecutor 负责把上下文拷进并发线程里。
这就是为什么 Runnable 不只是“能跑”。它还负责把运行时语义完整地带着一起跑。
07
—
读完源码后,我会这样定义 Runnable
如果让我用一句更工程化的话来下定义:
Runnable 是 LangChain 的统一执行协议。它把“单次执行、批量执行、流式执行、异步执行、结构组合、配置传播、Tracing、Fallback、History”全部压到了同一个抽象层上。所以我们平时看到的 Prompt、Model、Parser、Retriever、Tool、Agent,看起来像不同东西。但进入运行时之后,它们尽量都变成一类东西。这才是骨架。不是因为它名字底层,而是因为它承担了整个系统最稳定的“连接规则”。
三个最值得记住的坑:
- 不要把
batch()直接理解成“底层厂商真的提供了批量 API”。在Runnable基类里,它的默认含义更接近“并发地跑很多次invoke()”。 - 不要把
stream()直接理解成“天然逐 token 透传”。如果中间节点没有实现transform,你拿到的可能只是“最终结果的迭代器包装”。 - 不要把 retry、fallback、history、config 当成和主链并列的另一套系统。它们在源码里更像协议包装器,核心价值是“附着在同一执行面上”。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献227条内容
已为社区贡献227条内容

所有评论(0)