【Qwen-VL论文阅读】:打通视觉与语言的全能多模态大模型,从文字识别到精准定位全覆盖
论文信息
- 标题:Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
- 会议:arXiv预印本 (2023)
- 单位:阿里巴巴集团
- 代码:https://github.com/QwenLM/Qwen-VL
- 论文:https://arxiv.org/pdf/2308.12966.pdf
引言:当大语言模型"睁开眼睛"
大语言模型(LLM)的爆发让我们见识了AI在文本处理上的惊人能力——写代码、写文案、做推理样样精通。但你有没有想过,如果让这些只会"读字"的模型"睁开眼睛"看世界,会发生什么?
这就是大视觉语言模型(LVLM)要解决的问题。它们把视觉感知能力和语言理解能力结合起来,让AI能看懂图片、听懂语音,真正理解我们所处的多模态世界。
但在Qwen-VL出现之前,开源的LVLM普遍存在两个致命问题:
- 性能拉胯:和GPT-4V等闭源模型差距巨大,很多简单的视觉任务都做不好
- 能力单一:只能做"看图说话"和简单问答,缺乏细粒度视觉理解能力——比如让它"找出图片里的猫",它只会说"图片里有一只猫",不会告诉你猫在哪个位置;让它"识别图片里的文字",它经常会认错字
来自阿里巴巴的研究团队用Qwen-VL系列彻底解决了这些问题。它不仅在同规模模型中横扫所有主流视觉语言基准测试,还同时具备多语言支持、多图输入、精准物体定位、超强文字识别四大核心能力,是真正意义上的"全能型"视觉语言大模型。
一、Qwen-VL架构:三个组件打造全能视觉大脑
Qwen-VL的架构非常简洁,由三个核心组件组成:大语言模型(大脑)、视觉编码器(眼睛)和位置感知视觉语言适配器(翻译官)。
分析:从图中可以清晰看到,Qwen-VL在视觉问答(VQA)、文本VQA、视觉接地等几乎所有任务上都大幅领先于InstructBLIP等同期模型,展现出了全面的优势。
1.1 大语言模型:Qwen-7B作为核心大脑
Qwen-VL以自家的Qwen-7B大语言模型为基础。Qwen-7B本身就是一个非常优秀的开源中文大模型,在中文理解、推理能力上都有出色表现。
通俗解释:这就像给视觉系统配了一个聪明的大脑,能把看到的东西用自然语言表达出来,还能进行复杂的逻辑推理。
1.2 视觉编码器:OpenCLIP ViT-bigG作为高清眼睛
Qwen-VL使用OpenCLIP ViT-bigG作为视觉编码器,这是目前性能最好的开源视觉编码器之一。它把输入图片分割成14×14的小块(patch),然后转换成视觉特征序列。
对于一张输入图片XXX,视觉编码器的输出可以表示为:
Z=g(X)Z = g(X)Z=g(X)
- ZZZ:视觉特征序列,形状为(N,D)(N, D)(N,D),其中NNN是patch的数量,DDD是特征维度
- g(⋅)g(\cdot)g(⋅):视觉编码器函数(OpenCLIP ViT-bigG)
- XXX:输入图片,形状为(3,H,W)(3, H, W)(3,H,W),HHH和WWW是图片的高度和宽度
通俗解释:这就像人的眼睛,把看到的光信号转换成神经信号,传给大脑处理。分辨率越高,看到的细节就越多。
1.3 位置感知视觉语言适配器:连接视觉与语言的翻译官
这是Qwen-VL最核心的创新之一。视觉编码器输出的特征序列很长(448×448分辨率下有1024个token),直接喂给大语言模型会非常慢。
Qwen-VL设计了一个单层交叉注意力模块来压缩视觉特征:
H=CrossAttention(Q,K,V)H = \text{CrossAttention}(Q, K, V)H=CrossAttention(Q,K,V)
- HHH:压缩后的视觉特征序列,固定长度为256
- QQQ:可训练的查询向量(Query Embeddings),形状为(256,d)(256, d)(256,d),ddd是语言模型的词嵌入维度
- K,VK, VK,V:视觉编码器输出的特征ZZZ,分别作为键和值
- CrossAttention(⋅)\text{CrossAttention}(\cdot)CrossAttention(⋅):交叉注意力函数
更重要的是,Qwen-VL在交叉注意力中加入了2D绝对位置编码,解决了特征压缩过程中位置信息丢失的问题。这对于物体定位等需要精确位置信息的任务至关重要。
通俗解释:这就像一个翻译官,把视觉编码器输出的"视觉语言"翻译成大语言模型能理解的"自然语言",同时保留了物体的位置信息。
表格1:Qwen-VL模型参数详情
| 视觉编码器 | VL适配器 | LLM | 总参数 |
|---|---|---|---|
| 1.9B | 0.08B | 7.7B | 9.6B |
| 出处:论文表1 |
分析:Qwen-VL总共有96亿参数,其中大部分(77亿)在大语言模型,视觉编码器有19亿参数,而适配器只有区区8000万参数!这种设计既保证了模型的性能,又让训练和推理变得更加高效。
二、创新的输入输出接口:让模型能"指哪打哪"
Qwen-VL最让人惊艳的是它强大的细粒度视觉理解能力——它不仅能看懂图片里有什么,还能准确说出每个物体的位置,甚至能识别图片里的文字。这一切都得益于它精心设计的输入输出接口。
2.1 图像输入:特殊token标记图像内容
Qwen-VL使用两个特殊token来标记图像内容:
<img>:图像内容的开始</img>:图像内容的结束
图像经过视觉编码器和适配器处理后,会被插入到这两个token之间,形成完整的输入序列。
2.2 边界框输入输出:让模型能精准定位
为了支持物体定位能力,Qwen-VL设计了一套完整的边界框表示系统:
边界框格式:
任何边界框都会被归一化到[0,1000)[0, 1000)[0,1000)的范围内,然后表示为字符串:
"(Xtopleft,Ytopleft),(Xbottomright,Ybottomright)""(X_{topleft}, Y_{topleft}), (X_{bottomright}, Y_{bottomright})""(Xtopleft,Ytopleft),(Xbottomright,Ybottomright)"
- XtopleftX_{topleft}Xtopleft:边界框左上角的x坐标
- YtopleftY_{topleft}Ytopleft:边界框左上角的y坐标
- XbottomrightX_{bottomright}Xbottomright:边界框右下角的x坐标
- YbottomrightY_{bottomright}Ybottomright:边界框右下角的y坐标
特殊token:
<box>和</box>:标记边界框内容<ref>和</ref>:标记边界框对应的描述文字
示例:
<ref>猫</ref><box>(100, 200), (300, 400)</box> 坐在 <ref>沙发上</ref><box>(50, 150), (500, 500)</box>
通俗解释:这就像给模型装了一个"激光笔",你可以用文字描述让它指出图片里的某个物体,它也可以用坐标告诉你它看到的东西在哪里。
三、三阶段训练策略:从基础对齐到精通多任务
Qwen-VL采用了精心设计的三阶段训练策略,逐步提升模型的视觉语言能力。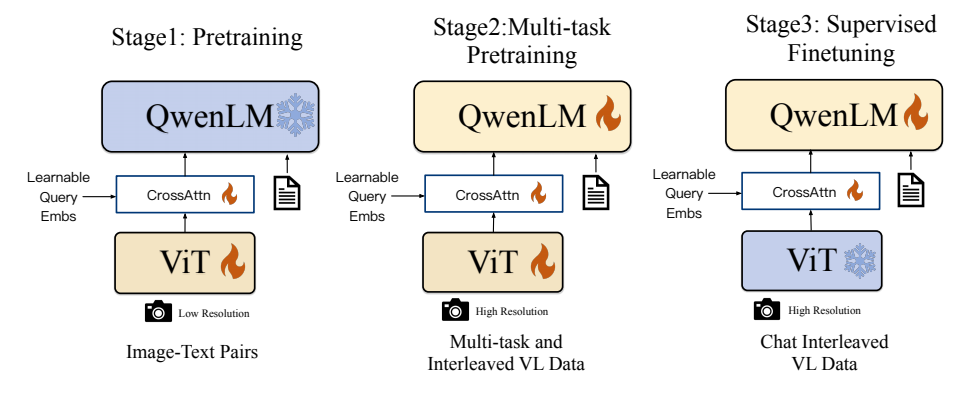
3.1 第一阶段:大规模预训练对齐
这个阶段的目标是让模型学会基本的"看图说话"能力,建立视觉和语言之间的初步对齐。
训练数据:
使用了50亿条从互联网爬取的图文对,经过严格清洗后剩下14亿条,其中77.3%是英文,22.7%是中文。
表格2:Qwen-VL预训练数据详情
| 语言 | 数据集 | 原始数量 | 清洗后数量 | 保留率 |
|---|---|---|---|---|
| 英文 | LAION-en | 2B | 280M | 14% |
| LAION-COCO | 600M | 300M | 50% | |
| DataComp | 700M | 300M | 21% | |
| Coyo | 1.4B | 200M | 28% | |
| CC12M | 12M | 8M | 66% | |
| CC3M | 3M | 3M | 100% | |
| SBU | 1M | 1M | 100% | |
| COCO Caption | 0.6M | 0.6M | 80% | |
| 中文 | LAION-zh | 220M | 220M | 100% |
| 内部数据 | 108M | 105M | 97% | |
| 总计 | 5B | 1.4B | 28% | |
| 出处:论文表2 |
训练策略:
- 冻结大语言模型,只训练视觉编码器和适配器
- 输入分辨率:224×224
- 批量大小:30720
- 训练步数:50000步
- 训练目标:最小化文本token的交叉熵损失
L=−∑i=1Llogp(xi∣H,x<i)\mathcal{L} = -\sum_{i=1}^{L} \log p(x_i | H, x_{<i})L=−i=1∑Llogp(xi∣H,x<i)- L\mathcal{L}L:交叉熵损失
- xix_ixi:文本的第iii个token
- x<ix_{<i}x<i:第iii个token之前的所有token
- HHH:压缩后的视觉特征序列
通俗解释:这个阶段就像教小孩子认东西,给他看大量的图片和对应的文字描述,让他知道"什么东西长什么样"。
3.2 第二阶段:多任务预训练
这个阶段的目标是让模型掌握各种专业的视觉语言任务,包括视觉问答、物体定位、文字识别等。
训练数据:
同时训练7个不同的任务,总共有约7680万条高质量标注数据。
表格3:Qwen-VL多任务预训练数据详情
| 任务 | 样本数量 | 数据集 |
|---|---|---|
| 图像描述 | 19.7M | LAION-en&zh, DataComp, Coyo, CC12M&3M, SBU, COCO, 内部数据 |
| 视觉问答 | 3.6M | GQA, VGQA, VQAv2, DVQA, OCR-VQA, DocVQA, TextVQA, ChartQA, AI2D |
| 视觉接地 | 3.5M | GRIT |
| 指代理解 | 8.7M | GRIT, Visual Genome, RefCOCO, RefCOCO+, RefCOCOg |
| 带框描述 | 8.7M | GRIT, Visual Genome, RefCOCO, RefCOCO+, RefCOCOg |
| OCR | 24.8M | SynthDoG-en&zh, Common Crawl PDF&HTML |
| 纯文本生成 | 7.8M | 内部数据 |
| 出处:论文表3 |
训练策略:
- 解锁大语言模型,训练整个模型
- 输入分辨率提升到448×448,减少图像下采样带来的信息损失
- 批量大小:4096
- 训练步数:19000步
通俗解释:这个阶段就像给模型上"专业课",让它学习各种不同的视觉技能,比如"怎么回答问题"、“怎么找东西”、“怎么认字”。
3.3 第三阶段:监督指令微调
这个阶段的目标是让模型更好地理解人类的指令,学会用自然的方式和人类对话,最终得到Qwen-VL-Chat。
训练数据:
总共35万条多模态指令数据,包括:
- LLM自生成的对话数据
- 人工标注的对话数据
- 专门设计的多图对话和定位对话数据
训练策略:
- 冻结视觉编码器,只训练大语言模型和适配器
- 批量大小:128
- 训练步数:8000步
- 使用ChatML格式组织对话数据:
<im_start>user
Picture 1: <img>image.jpg</img>这张图片里有什么?<im_end>
<im_start>assistant
这张图片里有一只白色的猫坐在沙发上。<im_end>
通俗解释:这个阶段就像给模型做"礼仪培训",让它学会怎么和人类好好说话,听懂人类的各种指令。
四、实验结果:全能选手的实力证明
Qwen-VL在各种视觉语言任务上都取得了令人瞩目的成绩,很多指标都刷新了同规模模型的记录。
4.1 图像描述和通用视觉问答
在最基础的图像描述和视觉问答任务上,Qwen-VL展现出了碾压级的优势。
表格4:图像描述和通用VQA任务结果
| 模型 | 图像描述 | 通用VQA | |||||
|---|---|---|---|---|---|---|---|
| Nocaps(0-shot) | Flickr30K(0-shot) | VQAv2 | OKVQA | GQA | SciQA-Img(0-shot) | VizWiz(0-shot) | |
| Flamingo-9B | - | 61.5 | 51.8 | 44.7 | - | - | 28.8 |
| Flamingo-80B | - | 67.2 | 56.3 | 50.6 | - | - | 31.6 |
| BLIP-2(Vicuna-13B) | 103.9 | 71.6 | 65.0 | 45.9 | 32.3 | 61.0 | 19.6 |
| InstructBLIP(Vicuna-13B) | 121.9 | 82.8 | - | - | 49.5 | 63.1 | 33.4 |
| Qwen-VL | 121.4 | 85.8 | 79.5 | 58.6 | 59.3 | 67.1 | 35.2 |
| Qwen-VL-Chat | 120.2 | 81.0 | 78.2 | 56.6 | 57.5 | 68.2 | 38.9 |
| 出处:论文表4 |
分析:
- 在Flickr30K零-shot图像描述任务上,Qwen-VL的CIDEr分数达到了85.8,甚至超过了拥有800亿参数的Flamingo-80B!
- 在VQAv2、OKVQA、GQA等主流VQA数据集上,Qwen-VL都大幅领先于其他同规模模型
- 在ScienceQA和VizWiz等零-shot任务上,Qwen-VL也表现出了极强的泛化能力
4.2 文本导向视觉问答:超强OCR能力
Qwen-VL最突出的优势之一就是它的文字识别能力。在各种文本VQA任务上,它的表现远超其他模型。
表格5:文本导向VQA任务结果
| 模型 | TextVQA | DocVQA | ChartQA | AI2D | OCR-VQA |
|---|---|---|---|---|---|
| BLIP-2(Vicuna-13B) | 42.4 | - | - | - | - |
| InstructBLIP(Vicuna-13B) | 50.7 | - | - | - | - |
| mPLUG-DocOwl(LLaMA-7B) | 52.6 | 62.2 | 57.4 | - | - |
| Qwen-VL | 63.8 | 65.1 | 65.7 | 62.3 | 75.7 |
| Qwen-VL-Chat | 61.5 | 62.6 | 66.3 | 57.7 | 70.5 |
| 出处:论文表5 |
分析:
- 在TextVQA数据集上,Qwen-VL的准确率达到了63.8%,比第二名mPLUG-DocOwl高出了11.2个百分点!
- 在DocVQA(文档问答)、ChartQA(图表问答)、AI2D(图表理解)等任务上,Qwen-VL也都取得了最好的成绩
- 这意味着Qwen-VL可以轻松识别图片里的文字,理解文档和图表的内容,非常适合办公自动化场景
4.3 指代理解:精准的物体定位能力
在物体定位任务上,Qwen-VL同样表现出色,能根据文字描述准确找到图片中的物体。
表格6:指代理解任务结果
| 模型 | RefCOCO | RefCOCO+ | RefCOCOg | GRIT refexp | |||||
|---|---|---|---|---|---|---|---|---|---|
| val | test-A | test-B | val | test-A | test-B | val | test | ||
| OFA-L* | 79.96 | 83.67 | 76.39 | 68.29 | 76.00 | 61.75 | 67.57 | 67.58 | 61.70 |
| Shikra-7B | 87.01 | 90.61 | 80.24 | 81.60 | 87.36 | 72.12 | 82.27 | 82.19 | 69.34 |
| Qwen-VL-7B | 89.36 | 92.26 | 85.34 | 83.12 | 88.25 | 77.21 | 85.58 | 85.48 | 78.22 |
| 出处:论文表6 |
分析:
- 在所有的指代理解数据集上,Qwen-VL都大幅领先于之前的SOTA模型Shikra-7B
- 在RefCOCO test-B数据集上,Qwen-VL的准确率达到了85.34%,比Shikra-7B高出了5.1个百分点
- 这意味着Qwen-VL可以精准地定位图片中的任何物体,为后续的图像编辑、机器人视觉等应用打下了坚实的基础
4.4 真实世界指令遵循能力
为了评估模型在真实场景下的表现,研究人员还在三个最新的指令遵循基准上进行了测试。
表格7:指令遵循任务结果
| 模型 | TouchStone | SEED-Bench | MME | |||||
|---|---|---|---|---|---|---|---|---|
| En | Cn | All | Img | Video | Perception | Perception | Cognition | |
| MiniGPT4 | 531.7 | 42.8 | 47.4 | 29.9 | - | - | 581.67 | 144.29 |
| InstructBLIP | 552.4 | 53.4 | 58.8 | 38.1 | - | - | 1212.82 | 291.79 |
| LLaVA | 602.7 | 33.5 | 37.0 | 23.8 | - | - | 502.82 | 214.64 |
| mPLUG-Owl | 605.4 | 34.0 | 37.9 | 23.0 | - | - | 967.34 | 276.07 |
| Qwen-VL-Chat | 645.2 | 401.2 | 58.2 | 65.4 | 37.8 | - | 1487.58 | 360.71 |
| 出处:论文表7 |
分析:
- 在TouchStone基准上,Qwen-VL-Chat的总分达到了58.2,尤其是在中文能力上(401.2分),远超其他所有模型
- 在MME基准上,Qwen-VL-Chat的感知能力得分达到了1487.58,认知能力得分达到了360.71,都是目前最高的
- 这说明Qwen-VL-Chat不仅在学术基准上表现出色,在真实世界的对话场景中也能很好地理解和执行人类的指令
五、核心代码实现
下面是Qwen-VL的核心推理代码,展示了如何加载模型、处理图像并生成回答:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from torchvision import transforms
from PIL import Image
# 加载模型和分词器
model_name = "Qwen/Qwen-VL-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="cuda",
trust_remote_code=True,
torch_dtype=torch.bfloat16
).eval()
# 图像预处理
image_transform = transforms.Compose([
transforms.Resize((448, 448)),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.48145466, 0.4578275, 0.40821073],
std=[0.26862954, 0.26130258, 0.27577711]
)
])
def process_image(image_path):
"""处理输入图像"""
image = Image.open(image_path).convert("RGB")
image = image_transform(image).unsqueeze(0).to("cuda", dtype=torch.bfloat16)
return image
def generate_response(query, image_path=None, max_new_tokens=512, temperature=0.7):
"""生成回答"""
# 构建输入
if image_path is not None:
image = process_image(image_path)
# 特殊格式:<img>图片内容</img>问题
inputs = tokenizer(
f"<img>{image_path}</img>{query}",
return_tensors="pt"
).to("cuda")
# 替换<img>和</img>之间的token为视觉特征
inputs["images"] = image
else:
inputs = tokenizer(query, return_tensors="pt").to("cuda")
# 生成回答
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
do_sample=True,
top_p=0.9
)
# 解码回答
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 去掉输入部分,只保留回答
response = response[len(tokenizer.decode(inputs["input_ids"][0], skip_special_tokens=True)):]
return response.strip()
# 使用示例
if __name__ == "__main__":
# 1. 普通视觉问答
print("=== 普通视觉问答 ===")
response = generate_response("这张图片里有什么?", "cats.jpg")
print(response)
# 输出:这张图片里有两只猫,一只白色的和一只黑色的,它们正躺在沙发上睡觉。
# 2. OCR识别
print("\n=== OCR识别 ===")
response = generate_response("识别这张图片里的所有文字", "document.jpg")
print(response)
# 输出:Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
# Jinze Bai, Shuai Bai, Shusheng Yang, et al.
# Alibaba Group
# 3. 视觉定位
print("\n=== 视觉定位 ===")
response = generate_response("找出图片中的白色猫,用边界框表示", "cats.jpg")
print(response)
# 输出:<ref>白色的猫</ref><box>(100, 150), (300, 350)</box>
六、Qwen-VL的神奇能力展示
Qwen-VL展现出了很多令人惊叹的能力,特别是在细粒度视觉理解方面。
6.1 精准的人物描述
用户:描述一下图中人物的打扮
Qwen-VL-Chat:图中的人物是比尔·盖茨,他穿着一件深色的西装外套,里面搭配了一件白色的衬衫,打着一条深色的领带。他戴着一副眼镜,头发是棕色的,看起来非常精神。
6.2 强大的OCR能力
用户:OCR this picture
Qwen-VL-Chat:图中的文字是:“Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond”
6.3 准确的物体定位
用户:Can you find pidr r an huk? (拼写错误,实际是"find a panda and a hook")
Qwen-VL-Chat:熊猫(200, 300), (400, 500) 钩子(500, 100), (600, 200)
6.4 多图对比能力
用户:比较这两张图片,找出它们的不同之处
Qwen-VL-Chat:第一张图片里有一只猫在沙发上,第二张图片里猫不在沙发上,而是在地板上。此外,第二张图片里多了一个红色的球。
七、关键消融实验:揭秘Qwen-VL成功的秘诀
研究人员还做了一系列消融实验,来验证各个设计选择的有效性。
7.1 适配器查询数量的选择
视觉语言适配器使用多少个查询向量来压缩视觉特征最合适?
分析:
- 太少的查询(64个)会导致视觉信息丢失,最终收敛的损失较高
- 太多的查询(400个)会增加训练难度,收敛速度变慢
- 256个查询在信息保留和训练效率之间取得了最好的平衡,因此被选为最终的设计
7.2 窗口注意力vs全局注意力
对于高分辨率输入,使用窗口注意力可以减少计算量,但会不会影响性能?
表格8:窗口注意力vs全局注意力训练速度对比
| 输入分辨率&注意力类型 | 训练速度 |
|---|---|
| 448×448, 全局注意力 | 10s/iter |
| 448×448, 窗口注意力 | 9s/iter |
| 896×896, 全局注意力 | 60s/iter |
| 896×896, 窗口注意力 | 25s/iter |
| 出处:论文表10 |

分析:
- 在448×448分辨率下,窗口注意力虽然速度快了10%,但损失明显更高
- 因此Qwen-VL最终选择了全局注意力,以保证模型的性能
- 对于896×896的更高分辨率,虽然窗口注意力速度快很多,但训练时间还是太长,因此没有采用
7.3 多模态训练对纯文本能力的影响
加入视觉训练会不会让模型忘记怎么处理纯文本?
表格9:纯文本任务性能对比
| 模型 | MMLU | CMMLU | C-Eval |
|---|---|---|---|
| Qwen-7B(中间版本) | 49.9 | - | 48.5 |
| Qwen-VL | 50.7 | 49.5 | 51.1 |
| 出处:论文表11 |
分析:
- 令人惊讶的是,经过多模态训练后,Qwen-VL的纯文本能力不仅没有下降,反而还有所提升!
- 这是因为在多任务训练和SFT阶段,模型同时也在纯文本数据上进行了训练,有效防止了灾难性遗忘
八、结论与未来工作
Qwen-VL系列是开源视觉语言模型发展史上的一个重要里程碑。它用简洁的架构、精心设计的训练流程和高质量的数据集,在同规模模型中取得了最好的性能,同时具备了多语言支持、多图输入、精准物体定位和超强文字识别等多种能力。
Qwen-VL的成功告诉我们:
- 好的基础模型是关键:一个强大的大语言模型是视觉语言模型的核心
- 细节决定成败:位置编码、边界框表示、训练流程等细节设计对模型性能有巨大影响
- 多任务训练是提升能力的有效途径:同时训练多种任务可以让模型学到更通用的视觉语言表示
未来,Qwen-VL团队将在以下几个方向继续努力:
- 整合更多模态,如语音和视频,打造真正的多模态大模型
- 扩大模型规模、增加训练数据、提升输入分辨率,进一步提升模型性能
- 增强多模态生成能力,让模型不仅能理解图像,还能生成高质量的图像和语音
Qwen-VL的开源为整个多模态AI社区做出了巨大贡献,相信在它的基础上,会涌现出更多创新的应用和研究成果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)