一个 DMXAPIKey 调用所有 Embedding 模型,我为什么从三个平台换到一个
一个被低估的技术环节
Embedding 这个词,这两年被提到的频率越来越高。但很多人对它的理解还停留在"把文字转成向量"这个层面。实际上它是一切 AI 应用的地基:语义搜索依赖它,推荐系统依赖它,RAG 系统依赖它,跨模态检索也依赖它。Embedding 的质量,直接决定上层应用的效果。
问题在于,这个环节在实际工程中经常被忽视,直到真正跑起来才发现踩了坑。
选 Embedding 模型,为什么是个难题
Embedding 模型的选项很多:OpenAI 的 ada 系列、Cohere 的 Embed 系列、国产的 BGE、M3E、Text2Vec……每个模型的词表不同、维度不同、训练语料不同,在不同任务上的表现差异也很大。
真正的问题不是选哪个,而是:
当你需要同时在多个场景里用 Embedding 的时候,管理成本就上来了。一个项目用 OpenAI 的模型做语义检索,另一个项目用国产模型做中文知识库,第三个项目做多模态要用 CLIP。每次换模型都要改代码、对接新的 API、重新调试向量数据库的索引。账单更是一团乱麻,不同平台计费逻辑不一样,计量单位不一样,对账的时候脑袋都大。
还有个现实问题:OpenAI 和 Cohere 这类服务在国内访问不稳定,网络延迟和可用性都是变量。用到一半被平台限流,或者突然访问不了,是很影响开发节奏的事情。
聚合平台解决的不是技术问题,是管理问题
Embedding 模型的技术选型,其实没有标准答案。不同场景适合不同的模型,这个大家都知道。
但很多人在选型阶段花太多时间,在管理阶段又太被动。明明场景已经很清晰了,还在反复横跳测试不同模型的效果。或者是场景很简单,但被多平台管理搞得很疲惫。
一个聚合平台的核心价值,是把"选模型"这件事和"管模型"这件事分开。你专注于场景需要什么模型,剩下的对接、计费、切换,交给平台处理。
具体来说:
一个 Key 调用多个 Embedding 模型,OpenAI 的、Cohere 的、国产的,都可以用同一个接口访问。换模型不需要重写代码,改一个参数就行。账单统一导出,不需要在多个后台之间来回切换。
选择聚合平台,至少有三个理由
第一个理由:稳定性。
海外模型服务在国内访问,网络质量是客观变量。聚合平台通常在国内有节点,访问延迟和可用性更有保障。Embedding 这类调用频繁的基础服务,稳定性的权重其实比很多人想象的高。
第二个理由:成本结构。
直接调用 OpenAI 或 Cohere 的 Embedding 服务,按官方定价计费。聚合平台通过批量采购拿到更低的单价,最终体现在用户的调用成本上。同样的调用量,用聚合平台的价格通常比直接用官方低一到两成。这个差异在调用量大的时候,是很可观的。
第三个理由:灵活切换。
Embedding 模型的选型,本质上是一个持续优化的过程。今天用 BGE 效果好,明天出了新的开源模型想试试,后天发现某个场景用 CLIP 更合适。如果每次切换都要重新对接一个新平台,这个成本是很高的。一个统一接口,切换模型只改参数,不改代码逻辑,这个灵活度是值得拥有的。
以 DMXAPI 为例,具体是怎么做的明确可以为你们承担的
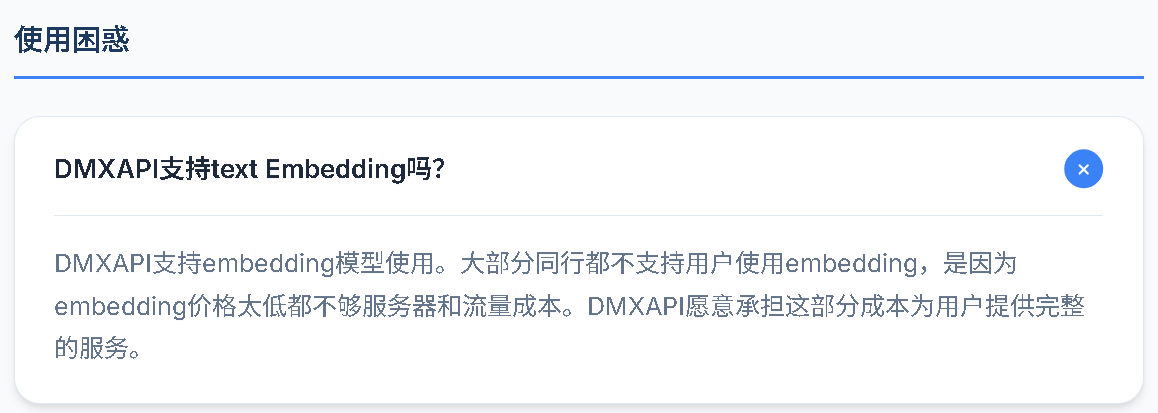
这里用 DMXAPI(https://www.dmxapi.cn/)作为具体例子来说明。
为什么选这家:
客观上,这家平台在几个维度上解决了我自己的痛点。第一,支持的模型覆盖面广,OpenAI ada 系列、Cohere Embed 系列、国产 BGE、M3E 等主流 Embedding 模型都能用,不需要分别注册多个平台。第二,国内访问有优化,接口响应速度稳定,没有遇到莫名其妙的超时或限流。第三,接入方式是标准的 OpenAI 协议,改造成本低,不需要额外学新接口。
接入方式:
from openai import OpenAI
client = OpenAI(
api_key="你的DMXAPI密钥",
base_url="https://www.dmxapi.cn/v1"
)
# 调用 Embedding
response = client.embeddings.create(
model="text-embedding-3-small",
input="要向量化的文本内容"
)
支持的 Embedding 模型:
官方的 ada-002、BGE 系列、M3E 等国产模型,在同一个接口下都可以访问。模型列表在控制台可以看到,支持的模型会根据平台更新有所调整,具体以实际接入时的情况为准。
计费方式:
按实际调用量计费,计量单位是 Token。不同模型单价不同,可以在平台的模型价格页面查到具体数据。账单在控制台统一查看,不需要分别登录多个平台核对。注册送一定额度,可以先测试再决定要不要付费。
切换模型有多简单:
# 换模型,只改这一个参数
model = "bge-large-zh" # 国产模型,中文效果好
# model = "text-embedding-3-large" # OpenAI 模型,想试就换
几个实际场景下的用法
RAG 系统是最典型的例子。
中文知识库的 RAG 场景,用国产 Embedding 模型往往比用 OpenAI 的效果更好,因为训练语料更贴合中文语义。英文场景又不一样,有些场景还是用 OpenAI 或 Cohere 更稳。分属两个平台管理,每次调参都要想半天这个场景用的是哪个模型。
用聚合平台的话,给不同项目分配不同的模型标识符,按需切换。代码层面不需要改动,改一个字符串参数就行。
多模态场景也类似。
如果你的项目同时涉及文本 Embedding 和图像 Embedding,不同模态用的模型不一样,管理成本会更高。一个统一接口能减少这部分摩擦。
什么人适合这种方式
如果你只需要一个 Embedding 模型,跑一个固定场景,直接用官方渠道没问题,没必要多一层。
但如果你在管多个项目,每个项目的 Embedding 需求不一样;或者你在做 RAG 系统,需要在不同模型之间做对比测试;或者你希望在不同阶段灵活切换模型,聚合接入的价值就出来了。
一个客观的说明
Embedding 模型的选型,核心还是看你的业务场景需要什么。不同模型在不同任务上的表现有差异,这个需要实际测试和对比,别人的经验不一定适用你的场景。聚合平台只是一个接入方式,解决了"怎么管"的问题,"用什么"还是得自己判断。
如果你对 Embedding 模型选型有具体问题,可以交流,但具体的效果对比建议自己动手测,数据最有说服力。
(全文完)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)