神经网络为什么要非线性?三大激活函数一次讲明白!
神经网络为什么要非线性?三大激活函数一次讲明白!
上一集聊了神经元,知道了它的计算就是 z = wx + b——加权求和,很简单。但如果你以为神经网络就是这样一层层算下去,那就踩进了一个大坑。
叠再多线性层,还是线性
说个简单的数学问题:y = 2x + 1 和 y = 3x + 2,把它们叠在一起,你猜得到什么?
还是 y = kx + d 的形式。换句话说,线性变换叠再多,本质上还是线性变换。
你可能会说:不对啊,神经网络有几十上百层,这么复杂,不可能就是线性的吧?
很遗憾,如果每层都是纯粹的加权求和(线性),那叠10000层的结果,等价于一个线性变换。这就好比你给一把直尺接上另一把直尺,接得再多也变不成曲线。
那问题来了——如果只能处理线性关系,神经网络能做到猫狗识别吗?
做不到。因为猫和狗的分类边界不是一条线性的。"体重大于10公斤就是狗"这种标签,在真实世界根本不存在。
非线性——AI的"变形能力"
要让线性变成非线性,需要一种东西——激活函数。
想象你手里有一团橡皮泥,不做任何处理的时候它就是一个圆球(线性)。但如果你想把它捏成小猫的形状(复杂决策边界),就需要给它施加不同的力。这个"力",就是激活函数提供的非线性。
更准确地说,激活函数给了神经网络一种变形能力——同样的 wx+b 结构,配上不同的数值输入,能做出完全不同的判断。
没有激活函数的神经网络,只是一堆线性变换搭起来的积木;有了它,这些积木才有了"变形"的可能。
Sigmoid:经典的S形,但有个致命问题
最早被广泛使用的激活函数叫 Sigmoid。它的形状是一条漂亮的S形曲线,能把任何输入压缩到0到1之间。
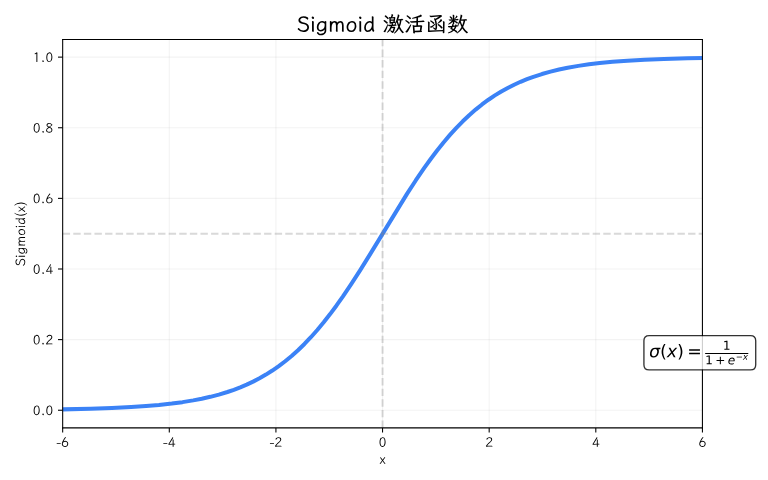
听起来很厉害对吧?因为它输出在0-1这个范围,天然适合做"概率判断"——输出0.9就代表"很可能是"。早期很多研究都用Sigmoid来做分类任务。
但Sigmoid有一个致命问题:梯度消失。
你仔细看S形曲线的两端——近乎水平的。这意味着输入很大或很小的时候,曲线几乎不动,信息传不下去了。在深度学习早期,人们发现网络叠到3层以上就不怎么起作用了,原因就在这里:传着传着,信号就"消失"了。
ReLU:简单粗暴,但有效
Sigmoid的问题怎么解决?答案是——不要两端太平滑。
ReLU(线性整流单元)的思路极其简单:max(0, x)——负数的部分全变成0,正数的部分原样保留。
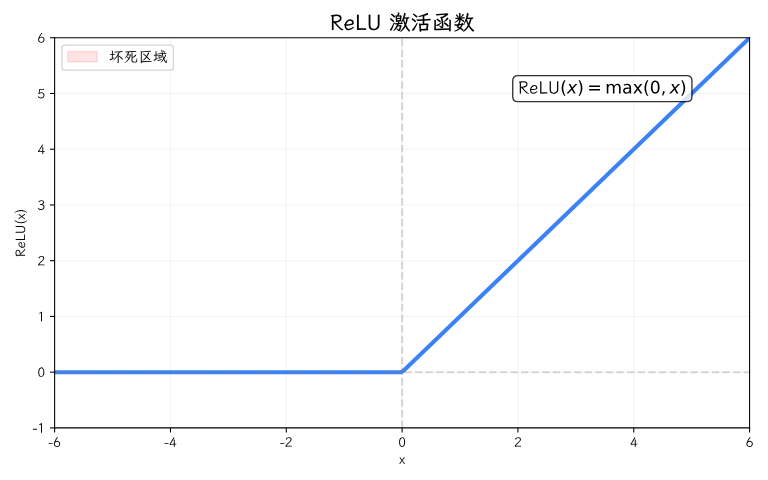
画出来就是一条折线:x < 0 时是一条水平线在0的位置,x > 0 时是一条斜线。没了S形曲线两端的平滑区,梯度永远为1。
这个改变带来的效果是革命性的:
- 计算只需要一个
max操作,不比加法慢 - 正半轴梯度恒为1,梯度消失彻底解决
- 神经网络终于可以加深了——几十层、上百层都不是问题
但 ReLU 也有它的毛病。负半轴"死了"——如果一个神经元的输出一直在负数区域,它永远不会被更新。这叫**"神经元坏死"**。就像你有一个员工,给他分配的任务他一直输出"我不行",久而久之他就被边缘化了。
GELU:大模型都在用的"进化版"
那有没有既能保留 ReLU 的优点,又能避免坏死问题的方案?
GELU(高斯误差线性单元)给出了答案。
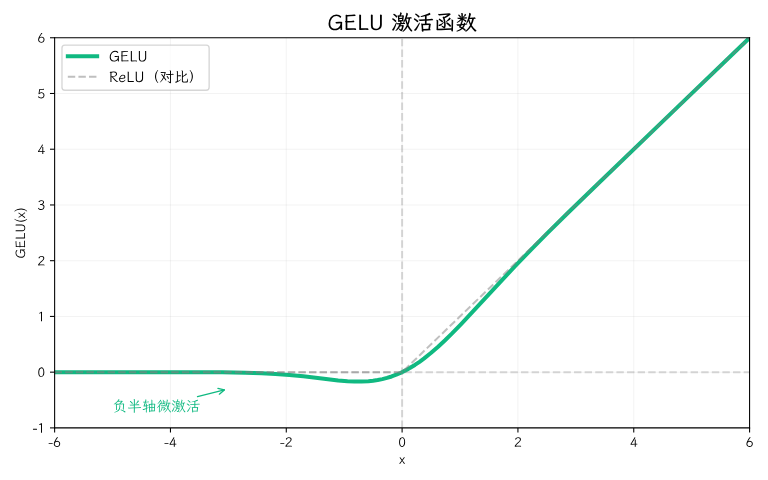
它的思路非常巧妙:不是简单地在负数区域一刀切,而是按值的大小决定"激活的概率"。值越大,越可能被激活;值越小,越可能被抑制——但保留了"万一有用"的可能性。
你可以把它想象成一个更聪明的考官:
- 不是"60分以上直接过,以下直接挂"
- 而是"95分大概率过、80分也可以试试、50分不一定但也许能行"
GPT、LLaMA、BERT——几乎所有现代大模型的背后,用的都是 GELU 或它的变体。它用微小的计算代价,换来了更好的训练稳定性和模型表现。

小结
| 激活函数 | 核心特点 | 主要问题 |
|---|---|---|
| Sigmoid | S形压缩,输出0~1适合概率 | 两端梯度消失,深层网络无法训练 |
| ReLU | max(0,x)简单高效,梯度恒为1 | 负半轴坏死,神经元不再更新 |
| GELU | 按概率激活,负半轴微激活 | 计算略复杂,但效果最好 |
三种激活函数各有特点,但它们的核心都一样——给线性变换注入非线性。同样的 wx+b 结构,配上不同的激活函数和参数,就能画出千变万化的决策边界。这才是神经网络真正强大的起点。
下一集我们看看这种"变形能力"在层层传递中是怎么工作的——前向传播:信号怎么往前走。
小默说AI,带你听懂AI。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)