DPDK 与 Linux 内核协议栈对比:性能差距到底来自哪里
做高性能网络开发时,很多工程师第一次接触 DPDK 都会有一个疑问:为什么同样是收发网络报文,DPDK 的性能可以比 Linux socket 高出数倍甚至一个数量级?
有些资料简单归结为:
- DPDK 是用户态
- Linux 是内核态
但这个解释其实过于粗糙。真正的性能差距,不只是“用户态 vs 内核态”,而是整个数据路径设计理念完全不同。
本文从系统架构角度,深入分析两者性能差异的根源。
一、先看传统 Linux 网络路径
在 Linux 中,一个报文从网卡到应用程序,大致流程如下:
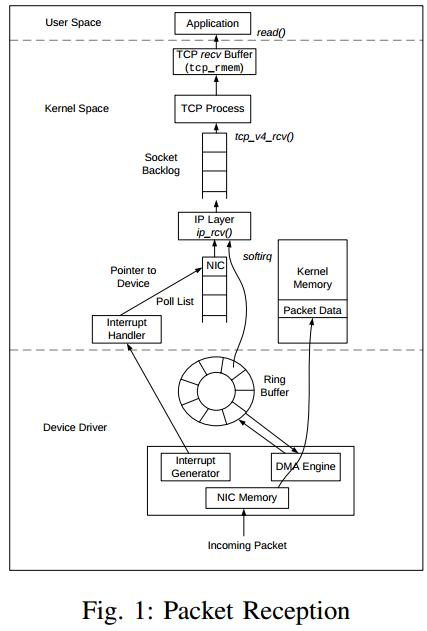
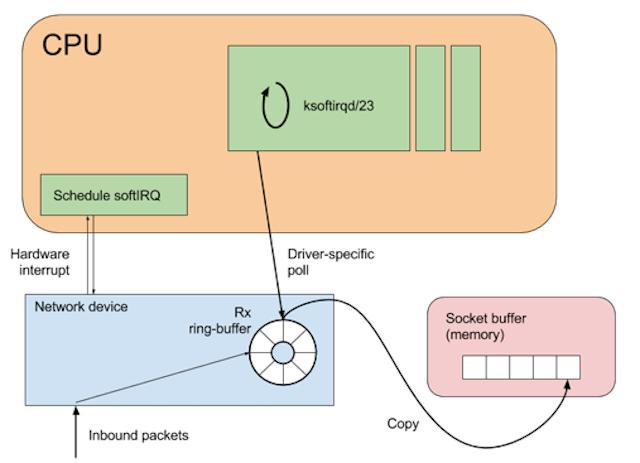
NIC
↓
DMA
↓
IRQ中断
↓
驱动
↓
NAPI poll
↓
skb分配
↓
协议栈处理
↓
socket buffer
↓
copy_to_user
↓
应用程序这条路径设计目标是:通用性优先。
Linux 要兼容所有应用:
- Web 服务
- SSH
- 数据库
- 浏览器
- RPC
- 容器网络
因此协议栈极其通用,但代价就是额外开销较多。
二、DPDK 的数据路径
DPDK 完全不同。
路径如下:
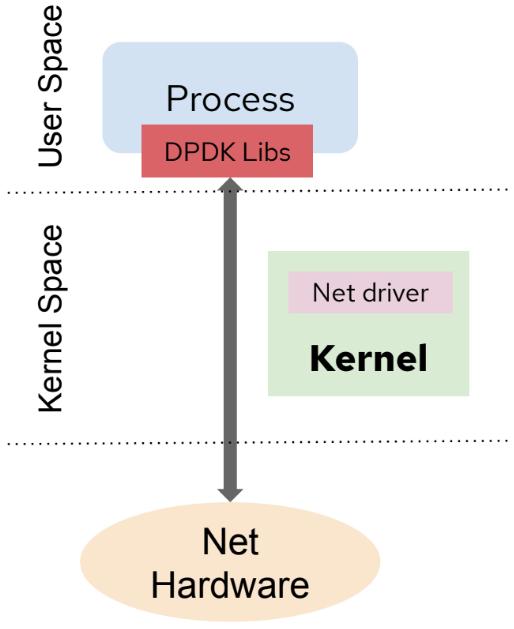
NIC
↓
DMA
↓
Hugepage
↓
用户态轮询
↓
应用程序没有:
- 中断
- skb
- socket
- 系统调用
- copy_to_user
这是根本差异。
三、性能差距的五个根源
1. 中断机制 vs 轮询机制
Linux 默认依赖:中断驱动
报文到达:CPU 被打断。
流程:
报文到达 → 中断 → 上下文切换 → 处理问题:中断频繁时开销巨大。
例如:1000 万 PPS 时:意味着每秒千万次事件。几乎不可接受。
DPDK
DPDK 使用:Poll Mode Driver(PMD)
持续轮询:
while (1) {
rte_eth_rx_burst(...);
}优点:
- 无中断
- 无上下文切换
- cache 连续
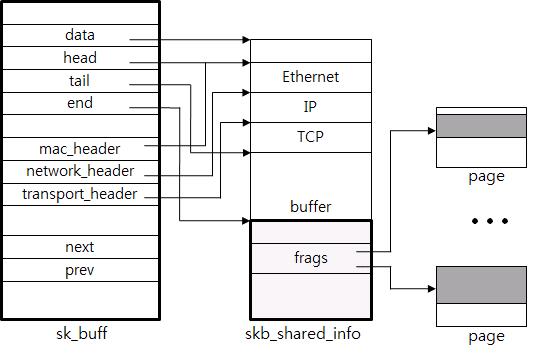
四、第二个核心差异:skb
Linux 每个报文都要构造:sk_buff
这是协议栈核心数据结构。
skb 结构复杂
包含:
- 链表
- 引用计数
- 元数据
- 时间戳
- 路由信息
- socket 信息
虽然灵活,但很重。
DPDK
对应:rte_mbuf
设计更轻量。
仅关注:
- packet data
- 长度
- offload 信息
因此缓存效率更高。
五、第三个差异:内存拷贝
Linux socket 模式通常涉及:至少一次 copy。
路径:
kernel buffer → user buffer即:
recv()本质:
copy_to_user。
DPDK
零拷贝。
直接:
NIC DMA → hugepage应用直接访问。无额外 copy。
六、第四个差异:调度模型
Linux 应用受:scheduler 调度。
线程可能在不同 CPU 漂移:
core1 -> core5 -> core2导致:
- cache miss
- TLB miss
- NUMA 跨节点
DPDK
固定绑核:
-l 2-7每个 lcore 固定。
极大优化 cache。
七、第五个差异:批量处理
Linux socket 通常:一次一个包。
recv()DPDK
一次一批:
rte_eth_rx_burst(..., 32)批量处理显著降低:
- 函数调用开销
- cache miss
- descriptor 更新次数
八、性能对比(实际工程经验)
在实际服务器上常见结果:
| 模式 | PPS |
|---|---|
| Linux socket | 0.5 ~ 1.5 Mpps |
| Linux raw socket | 1 ~ 3 Mpps |
| XDP | 5 ~ 20 Mpps |
| DPDK | 10 ~ 80 Mpps |
取决于:
- CPU
- 网卡
- 业务逻辑
九、为什么 Linux 还广泛使用
既然 DPDK 快,为什么很多系统仍然用 Linux 协议栈?
因为:快不是唯一目标。
Linux 协议栈优势:
1. 通用性强
直接支持:
- TCP
- UDP
- IPv6
- TLS
- routing
- netfilter
2. 开发简单
普通 socket:
socket()
bind()
recv()
send()即可开发。
3. 生态成熟
支持:
- epoll
- iptables
- tc
- nftables
十、DPDK 的代价
高性能是有代价的。
1. 编程复杂
需要处理:
- 网卡初始化
- hugepage
- NUMA
- queue
- ring
- core
2. CPU 占用高
busy polling:
100% CPU即使没流量也占核。
3. 调试复杂
常见问题:
- mbuf 泄漏
- 队列阻塞
- NUMA 错配
- cache false sharing
十一、实际应用场景
适合 DPDK 的场景:
非常适合
- 虚拟交换机
- 防火墙
- DPI
- NAT
- 负载均衡
- VPN 网关
- 5G UPF
不适合
- Web 服务
- 文件服务
- 普通后台服务
- 小流量应用
十二、工程上的选择建议
如果你做的是:
普通应用
使用:Linux kernel networking stack 足够。
高性能数据面
使用:
DPDK
更合理。
十三、总结
DPDK 与 Linux 的差距,不是简单一句:用户态比内核态快。
真正原因是:整体设计哲学不同。
Linux 追求:通用性、兼容性、稳定性
DPDK 追求:极致性能
核心差异体现在:
Linux
- 中断
- skb
- socket
- 调度
- copy
DPDK
- polling
- mbuf
- hugepage
- bind core
- zero copy
最终结果:
在高并发场景中,DPDK 能轻松实现:百万甚至千万 PPS
这也是现代:
- 云网络
- 运营商设备
- 网络安全设备
- SDN 数据面
大量使用它的原因。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)