港中深新作:MPerS架构:融合DINOv3与动态混合专家MLLM,实现遥感分割新SOTA
一、 研究背景与动机
本研究聚焦于遥感(RS)图像语义分割领域,旨在解决高分辨率、地物密集的复杂遥感场景下的精准分割难题。现有的方法,无论是仅依赖图像的单模态模型,还是已有的图文多模态模型,都存在明显的局限。单模态方法受限于图像本身有限的感知能力和高昂的像素级标注成本。而多模态方法虽然引入了文本信息,但大多侧重于优化融合架构,普遍忽略了文本描述(Caption)本身的质量问题。它们通常使用简单的类别文本或由单一模型生成的、可能包含“幻觉”或细节不足的描述,这反而会误导分割模型,限制了性能的上限。

作者的核心洞察在于:高质量、多视角的文本描述对于指导遥感场景理解至关重要。他们发现,通过精心设计多角度的提示词(Prompts),可以引导多个不同的多模态大语言模型(MLLMs)从“专家”视角生成更准确、更丰富的场景描述。基于此,论文的创新动机是构建一个能够动态评估并融合这些高质量“专家意见”(即文本描述)的框架,利用最有效的文本语义来精确引导视觉特征,从而实现更优的遥感图像分割效果。
为帮助大家更好地研究,我整理了这篇论文的完整架构图 + 核心算法和零上手复现教程
关注“遥感AI科研”,回复“B458”
二、 核心方法
1. 整体思路
该方法的核心思想是:利用多个MLLM作为专家生成多视角的高质量遥感场景描述,通过一个动态混合专家(MixExperts)模块自适应地筛选和融合最有效的文本语义,并以此指导视觉编码器进行特征增强,最终实现精确的场景分割。
2. 关键公式/步骤
该模型主要包含视觉特征提取、动态文本编码、图文融合和解码分割四个阶段。
-
视觉特征提取:模型使用一个冻结的DINOv3作为主干网络,并额外设计了一个轻量级的细节先验编码器(Lite Detail Prior Encoder),分别提取图像
I的全局和细节视觉特征f_v_dino和f_v_detail。 -
动态混合专家文本编码器 (DMTE) :
-
使用三种精心设计的多视角提示词(分析地物类别、占比、空间关系)输入给三个不同的MLLM(如LLaVA, ChatGPT, Qwen),生成三组候选文本描述。
-
将这些描述通过CLIP文本编码器转化为文本特征
Φ_t_MLLMm。 -
通过一个动态门控网络
g(·)计算每个专家文本的动态权重G_m。 -
结合可学习的专家权重
W_m和动态权重G_m,加权融合所有专家的文本特征,得到最终的混合专家文本特征T_MixExperts。
其中,
Φ_t_MLLMm是第m个MLLM专家生成的文本特征,G_m是其对应的动态门控值,W_m是一个可学习的参数,用于衡量该专家的固有重要性。 -
-
语言查询引导注意力 (LQGA) :
-
将融合后的文本特征
T_MixExperts作为查询(Query,Q_text),将视觉特征作为键(Key,K_vision)和值(Value,V_vision)。 -
通过注意力机制计算出文本引导的视觉权重
w_text。 -
用该权重来调制视觉特征
F_v,并与原始特征进行残差连接,得到增强后的视觉特征F'_v。
最终,经过进一步融合得到引导后的视觉特征
Z_v,送入解码器。 -
3. 技术实现要点
-
如何筛选有效文本信息:论文没有区分图像中的“重要”与“可变换”部分,而是通过动态混合专家文本编码器(DMTE)来区分文本描述的有效性。该模块通过门控机制和可学习权重,动态地为来自不同MLLM专家的描述分配权重,从而选出对当前分割任务最有利的文本语义组合。
-
如何保证语义一致性与多样性:
-
多样性:通过设计三种不同视角(类别、比例、位置)的提示词,并利用多个不同的MLLM模型,来生成内容丰富且角度多样的文本描述。
-
语义一致性:设计了一个“描述检查策略”,即计算生成的文本与图像的CLIP相似度得分,只有得分高于阈值(如0.55)的描述才被采纳,确保了文本内容与图像的高度相关性。(参考图2)
-
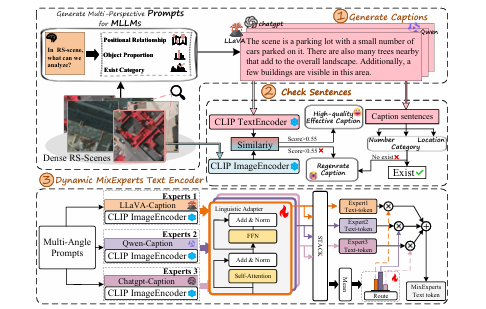
图2
-
训练策略:模型在训练时仅使用标准的交叉熵损失函数(Cross-Entropy Loss),没有引入复杂的正则化项或对比学习目标,便取得了良好效果。
三、 实验验证与效果
1. 主实验对比
该方法在三个公开的遥感数据集 Potsdam、Vaihingen 和 SynDrone 上进行了评估。实验结果(如表1、表2)显示,与MAResUnet、RS³Mamba、SegCLIP等一系列先进的单模态和多模态基线方法相比,MPerS在mIoU和mF1等关键指标上均取得了显著的性能提升。例如,在Vaihingen数据集上,其mIoU和mF1分别达到了78.42%和87.65%,大幅超越了其他方法。
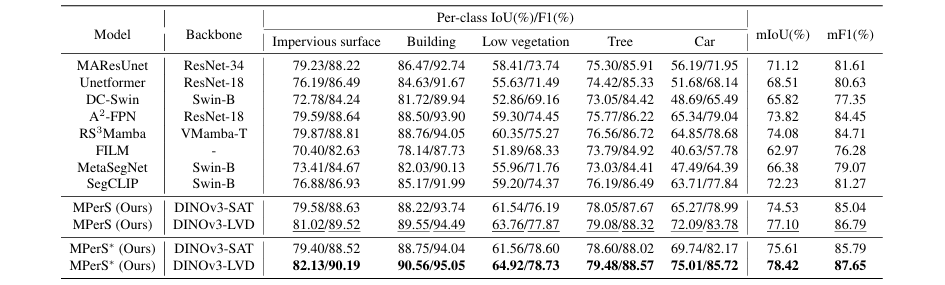
表1
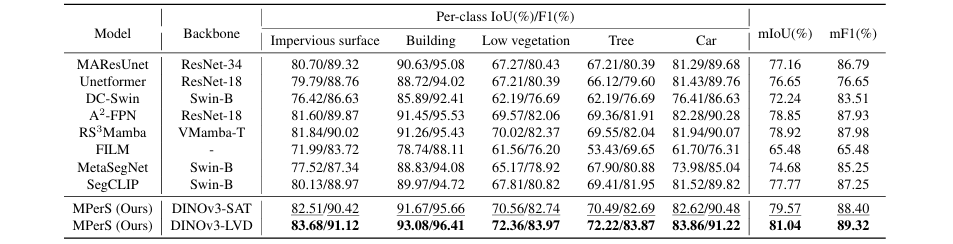
表2
2. 深入分析
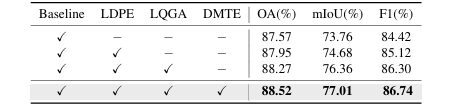
表4
论文进行了详细的消融实验(如表4),以验证各个关键模块的有效性:
-
组件消融:逐一移除了轻量级细节先验编码器(LDPE)、语言查询引导注意力(LQGA)和动态混合专家文本编码器(DMTE)。结果表明,每个模块都对最终性能有正向贡献,其中LQGA和DMTE带来的提升尤为明显,证明了高质量文本引导和动态专家选择机制的核心作用。
-
描述质量分析:实验(如表6)对比了使用简单提问、使用单个MLLM的多视角提问以及使用混合专家的效果,清晰地证明了“高质量多视角描述”优于“简单描述”,“动态混合专家”优于“单专家”的结论。

表6
-
可视化分析:分割结果的可视化图(如图5)展示了MPerS在处理复杂场景时的优势,尤其是在“汽车”等密集小目标的分割上,其边缘更清晰,错分漏分情况更少。
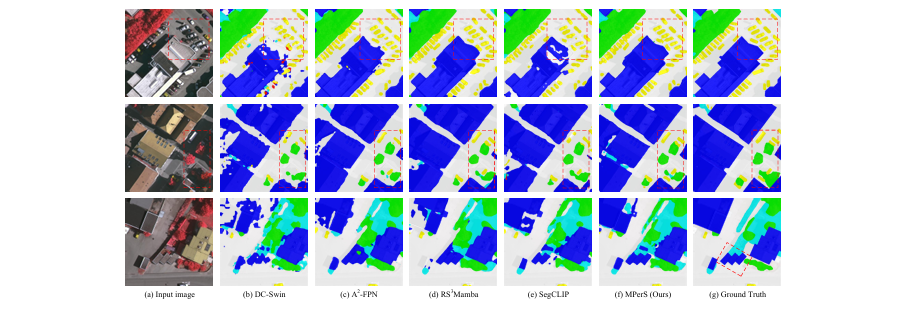
图5
3. 结论与价值
论文的主要贡献有三点:
-
首次系统性地探究了由不同MLLM生成的文本描述质量对遥感图像分割任务的有效性。
-
提出了一个动态混合专家(DMTE)文本编码器,能自适应地融合来自多个MLLM专家的语义信息。
-
设计了语言查询引导注意力(LQGA)模块,实现了文本语义对视觉特征的高效引导和融合。
该方法的各个组件(如DINOv3、CLIP、MixExperts)具有模块化特性,易于替换和升级,为未来将更强大的基础模型应用于遥感解译领域提供了新的思路和解决方案。
四、小编总结
这篇论文的核心亮点在于,它将研究重心从“如何融合图文”这一传统问题,转移到了“如何生成和筛选高质量文本”这一更前端、也更关键的问题上。它巧妙地将多个强大的多模态大模型(MLLMs)构建为一个“专家委员会”,通过精心设计的提问方式,让它们从不同角度解读遥感影像。其提出的“动态混合专家”模块就像一个聪明的仲裁者,能够判断并采纳当前场景下最有价值的“专家意见”(文本描述)。这种“先有高质量输入,再谈高效融合”的思路,使得模型能更好地理解遥感图像中的复杂语义,尤其在分割细小、密集的地物时表现突出,为多模态遥感研究开辟了一个值得探索的新方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)