在 Claude code 中如何利用模型缓存节省 token
在上一篇文章《Agent 工程中的模型缓存优化经验分享》中,我分享了 Agent 工程中的模型缓存优化经验,但毕竟大部分读者还是 Claude Code、Reasonix 等产品的用户,而不是开发者,大家更关心的一定是"如何省 token"。因此这次我们就来分析一下:什么动作会让 cache 直接报废,怎么用才能最大化命中率。

一句话理解模型缓存
Prompt Cache 缓存的不是文字,而是 Transformer 推理过程中注意力层计算出的 KV(Key/Value)状态——这是模型内部的计算中间态,已经算过的部分下次不用重算,只需支付 1/10 的价格。
缓存的层级结构
每次请求可以想象成一根从左到右的链条:
工具定义(tools) → 系统提示(system) → 项目配置(CLAUDE.md/skills) → 消息历史(messages)
核心规则:上层变化会使下层缓存全部失效。改了工具定义,右侧全废;改了消息历史,只伤自己。越靠左越要锁死。
6 个缓存杀手及应对策略
1. 模型切换
KV cache 与模型权重强绑定,Opus、Sonnet、Haiku 之间完全隔离。切一次模型,之前的缓存全部归零,下一轮需要重新全量写入。
Claude Code 的 /model 命令处也明确提示:切换模型后,下一次响应会以无缓存状态重读全部历史。
应对策略:
- 任务开始前确定模型,之后不要动
- 需要多模型协作时,用 Subagent 隔出去跑(Claude Code 的 Explore agent 就是这么干的,用的 Haiku),主会话保持稳定
- 如果确实要换模型,在任务阶段边界切换,并主动
/compact压缩历史
2. MCP 工具列表变更
工具定义处于链条最左端,一旦变化,右侧全部失效。中途加载新 MCP Server = 全量重新计算。
但注意:MCP 工具列表只在启动时读取一次,session 内装新 MCP 不影响当前会话。真正的杀手是 /resume 或 /reload-plugins,触发重读后工具列表重组。
应对策略: 启动前把需要的 MCP 一次性配好,session 内不要动。
3. 修改 CLAUDE.md 或安装新 Skill
CLAUDE.md 注入在系统提示中,基于内容寻址,文件改动 = 缓存失配。Skills 同理。
同样,这些内容也只在启动时读一次,改完后不执行 /resume 则不影响当前 session。
应对策略:
- CLAUDE.md 只放长期有效的规则,临时说明写在对话里
- 改完文件或装完 Skill,不要
/resume,等当前任务结束再重启
4. TTL 超时
缓存条目有存活时间限制:
- API 用户默认:5 分钟
- Claude Max 用户:1 小时
去接杯水、看封邮件,回来缓存就过期了。
应对策略:
- 长任务开启 1 小时缓存:打开 Claude Code 前输入
export ENABLE_PROMPT_CACHING_1H=1 - 长时间离开前先
/compact压缩上下文,避免回来时为庞大的历史重新付费
5. Resume 会话中的缓存 Bug
GitHub Issue #27048 记录了一个问题:在 5 分钟 TTL 窗口内 resume 会话时,tool-use 内容(如文件读取结果)无法被缓存复用,导致命中率大幅下降。
应对策略: 如果需要 resume,尽量在 TTL 过期后进行,或者接受首轮的缓存重建成本。
6. 图片或 tool_choice 变化
请求中图片的存在与否发生变化,或 tool_choice 参数变更,缓存就会失效。
应对策略: 保持请求结构的一致性,避免在同一会话中频繁切换有图/无图的请求模式。
监控缓存命中率
查看 API 响应字段
Claude Code 会将每次对话的完整 API 响应(包括 usage 信息)以 JSONL 格式保存在本地。
文件路径:
~/.claude/projects/<项目目录名>/<session-id>.jsonl
其中 <项目目录名> 是将工作路径中的 / 替换为 - 后的结果。
在 JSONL 文件中,找到 type == "assistant" 的行,里面包含完整的 usage 字段:
{
"type": "assistant",
"timestamp": "2026-03-20T09:14:32.451Z",
"message": {
"model": "claude-sonnet-4-6",
"usage": {
"input_tokens": 1024,
"output_tokens": 8192,
"cache_read_input_tokens": 487321,
"cache_creation_input_tokens": 62144,
"cache_creation": {
"ephemeral_5m_input_tokens": 62144,
"ephemeral_1h_input_tokens": 0
}
}
}
}
其中包含两个关键字段:
cache_read_input_tokens:命中缓存的 token 数cache_creation_input_tokens:新写入缓存的 token 数
通过这两个值可以计算命中率:
cache_read / (cache_read + cache_creation + input_tokens)
你可以用命令行工具直接查看:
# 查看最近一个 session 的缓存 token 使用情况
cat ~/.claude/projects/$(pwd | sed 's/\//-/g')/*.jsonl | \
jq 'select(.type == "assistant") | .message.usage | {input, output, cache_read: .cache_read_input_tokens, cache_create: .cache_creation_input_tokens}'
如果你对命令行不太熟悉,有一个开源工具 claudefana 专门用于 Claude Code 的可观测性,它会自动从日志中提取缓存 token 数据并展示在 Grafana 仪表板上,这样会更加直观。

配置状态栏实时监控
在 Claude Code 中输入 /statusline,可以让状态栏显示上下文使用百分比和模型名称,随时掌握消耗情况。
这里还可以和模型对话来自定义显示效果,设置完立刻生效。


健康命中率目标
在调用的 API 官网控制台直接查看缓存命中率:
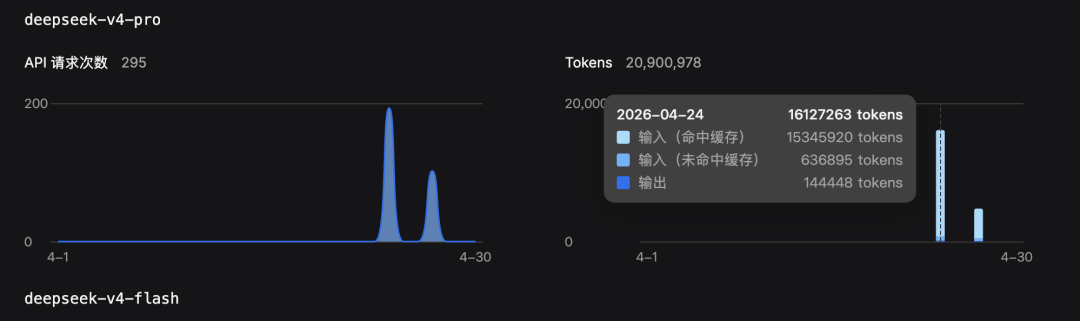
- 稳定会话:> 80%
- 新会话预热后:> 60%
如果命中率持续偏低,排查上述 6 个杀手是否在作祟。
总结
把每个请求想成链条:tools → system → CLAUDE.md/skills → messages。改哪段都会让 cache 失效,区别只在影响范围。
三条心法:
- 锁左端:工具列表、CLAUDE.md 启动前一次配好,session 内不动
- 稳模型:一个 session 不换模型,需要多模型用 Subagent
- 控超时:长任务开 1 小时缓存,离开前先
/compact
理解缓存的工作原理,才能真正用好 Claude Code——而不是在不知不觉中给自己挖了一个成本陷阱。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)