DPDK 多核架构设计:如何构建百万 PPS 转发框架
在高性能网络系统开发中,使用 DPDK 进行收发包只是第一步。真正决定系统性能上限的,不是单纯的 API 调用,而是整体多核架构设计。
很多初学者写出的 DPDK 程序虽然能跑,但性能很快遇到瓶颈:
- 单核打满
- 延迟抖动
- 队列堆积
- 多核扩展性差
根本原因通常不是网卡能力不足,而是:多核模型设计不合理。
本文从工程实践角度,介绍如何构建一个真正可扩展的百万 PPS 转发框架。
一、为什么单核模式很快到瓶颈
最简单的 DPDK 程序通常这样写:
while (1) {
nb_rx = rte_eth_rx_burst(...);
process_packets();
rte_eth_tx_burst(...);
}单核同时负责:
- 收包
- 分类
- 查表
- 转发
- 发包
看似简单,但问题明显。
单核模型问题
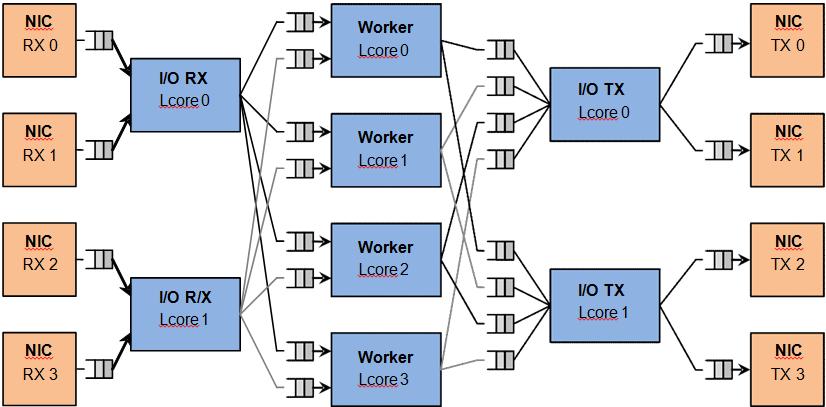
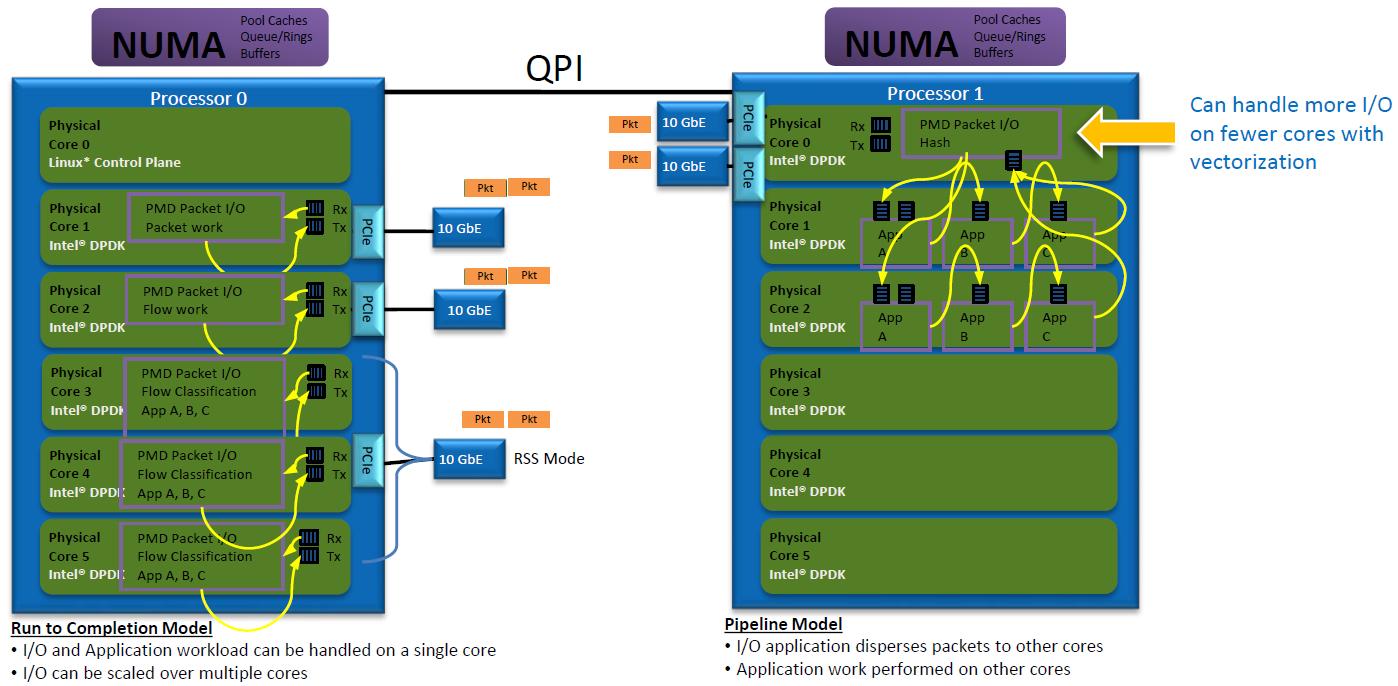
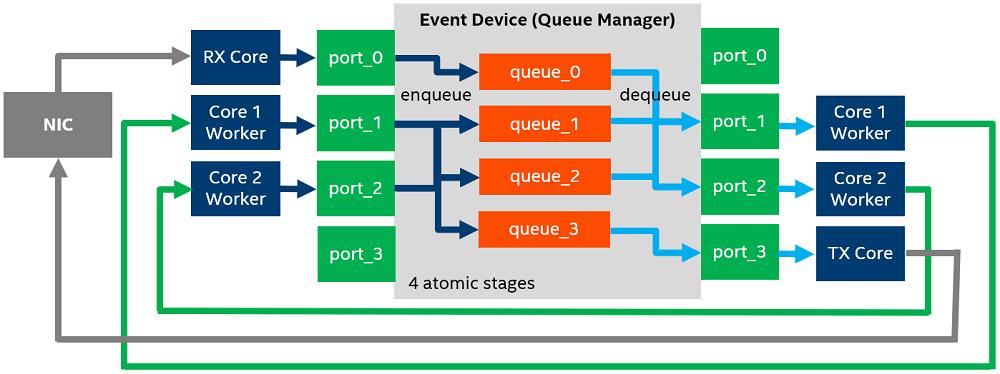
1. CPU 很快被业务逻辑占满
收发包只是很小一部分。
实际耗时在:
- ACL
- NAT
- 会话表
- 路由查找
- 策略匹配
2. cache 污染严重
业务代码复杂时:
- 指令 cache miss
- 数据 cache miss
不断增加。
3. 扩展性极差
单核上限非常明显:
通常:
| 场景 | PPS |
|---|---|
| 简单 L2 | 3~8 Mpps |
| L3 转发 | 1~5 Mpps |
| ACL/NAT | 更低 |
二、多核设计的本质
多核设计不是简单“多开几个线程”。
真正核心是:将数据面处理流水线拆分。即:不同核心负责不同职责。
三、经典流水线模型
我在实际项目中常用如下架构:
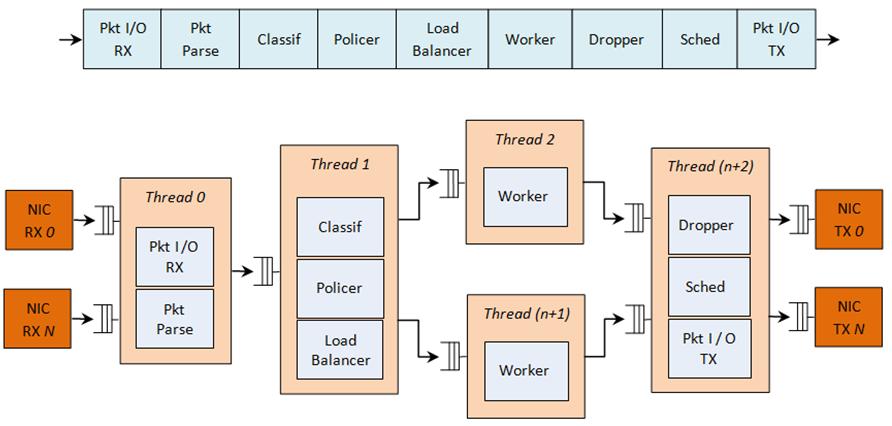
各核心职责
1. RX Core
专门负责:
- 网卡收包
- burst 拉取
- 入队
代码非常纯粹:
rx_loop()不做业务处理。
2. Worker Core
负责:
- 报文解析
- 流分类
- 会话维护
- 转发决策
核心计算都在这里。
3. TX Core
负责:
- 聚合发包
- queue 调度
- 发往 NIC
四、为什么这样设计更快
原因非常工程化。
1. cache 局部性更好
RX 核心只执行:
rte_eth_rx_burst()代码路径极短。
cache 命中率极高。
2. 降低分支预测失败
业务逻辑复杂时:
大量:
if / else
switch影响 pipeline。
拆到 worker 后:不影响 RX。
3. 易于横向扩展
例如:
从:
2 worker扩展到:
8 worker只需增加核数。
五、core 间通信方式
关键问题:不同核心如何传递报文?
答案:DPDK Ring
rte_ring
这是 DPDK 最常用无锁队列。
创建:
rte_ring_create(...)收包后:
rte_ring_enqueue()worker:
rte_ring_dequeue()优势
1. lockless
无需:
- mutex
- spinlock
2. 高并发
支持:
- single producer
- multi producer
- single consumer
- multi consumer
3. cache 友好
ring 本身是连续数组。
六、核心绑定策略
这是性能关键。
很多人忽略。
错误方式
随机调度:
Linux scheduler导致:
- core 漂移
- cache 丢失
- NUMA 跨节点
正确方式
绑定 lcore。
例如:
-l 2-9表示:
绑定 CPU 2~9。
推荐模型
| 核心 | 角色 |
|---|---|
| core2 | RX |
| core3 | TX |
| core4-9 | worker |
七、RSS:让多核真正发挥作用
网卡支持:RSS(Receive Side Scaling)
作用:将不同流分配到不同 queue。
没有 RSS
所有包进一个队列:
queue0单核瓶颈。
开启 RSS
queue0 -> core2
queue1 -> core3
queue2 -> core4
queue3 -> core5并行处理。
实际效果
吞吐提升通常:
3~6 倍。
八、典型百万 PPS 架构
一个典型设计如下:
8 核配置
core0 master
core1 stats
core2 rx0
core3 rx1
core4 worker0
core5 worker1
core6 worker2
core7 tx流程
NIC RX
↓
RX core
↓
rte_ring
↓
worker
↓
rte_ring
↓
TX core九、代码框架示例
核心设计:
while (1) {
nb = rte_eth_rx_burst(...);
for (i = 0; i < nb; i++) {
dispatch_to_worker(pkts[i]);
}
}worker:
while (1) {
pkt = dequeue();
process(pkt);
enqueue_tx(pkt);
}tx:
while (1) {
pkt = tx_dequeue();
rte_eth_tx_burst(...);
}十、常见性能陷阱
1. 多核共享全局表
错误:
global_flow_table所有 worker 共用。
导致:
- cache line 冲突
- 锁竞争
正确
每核独立:
per-core table2. 队列太少
只有:
1 RX queue即使 16 核也没用。
3. worker 不均衡
某些流集中到单核。
导致:
- 单核热点
解决:
使用:
- RSS hash
- flow rebalance
十一、工程经验总结
实际项目中,推荐:
L2 转发
4 核
可达:8~15 Mpps
L3 转发
8 核
可达:10~30 Mpps
ACL/NAT
8 核
一般:5~20 Mpps
十二、架构建议
如果你自己做项目,建议直接这样设计:
第一版
实现:
- 单 RX
- 单 TX
- 单 worker
先跑通。
第二版
扩展:
- 多 worker
- ring dispatch
第三版
增加:
- RSS
- NUMA
- per-core flow table
第四版
增加:
- timer wheel
- session aging
- statistics
十三、总结
很多人认为 DPDK 性能取决于网卡。
实际上:真正决定上限的是:多核架构设计。
核心思想:不是让每个核都“做所有事情”。
而是:将网络处理拆成流水线。
这才是高性能数据面的本质。
也是:
- vSwitch
- firewall
- gateway
- DPI
- IPSec
系统普遍采用的模式。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)