激活函数/归一化/gate
今天学习到很有启发性的一句话,gate本身也是一种attention,只是计算的level不同。言归正传,复盘总结一下大模型中常见的激活函数和归一化函数。
1、 激活函数
Sigmoid / ReLU / Swish / GELU / SwiGLU

当然最好的还是看这样一张图片,画的更清楚,还有各个激活函数的梯度图片。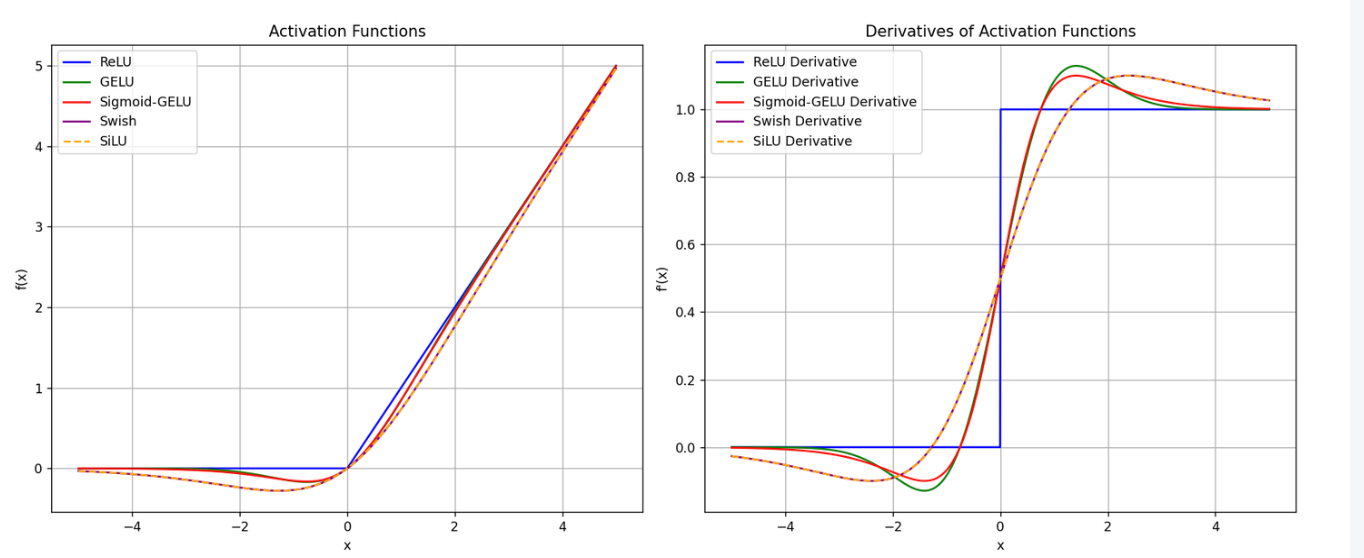
之前在cnn时代,激活函数基本用的都是Relu,进入到大语言模型时代,可以看到明显的变化,激活函数变得更为复杂多样,但是从函数形状来看,这些函数都与Relu函数的形状有很大的相似性。
-
Relu
优点:极其简单,计算快;不易梯度消失,正数区间都是1,对比Sigmoid在极大值区间梯度接近于0;稀疏激活,负数直接砍掉。
缺点:神经元长期为负数的话,会造成dying relu的现象 -
Swish
本质是特点ReLU + Sigmoid的融合。
相比 ReLU,优点是:平滑,可导,负数区域不是硬截断,梯度传播更柔和
缺点:计算比 ReLU 贵。 -
GELU
Transformer 世界真正的王者。GPT/BERT/LLaMA/Qwen 大量使用。
GELU(x)=xΦ(x) \text{GELU}(x) = x\Phi(x) GELU(x)=xΦ(x)
其中:
Φ(x)\Phi(x)Φ(x) 是高斯分布 CDF。
近似实现:
0.5x(1+tanh(2π(x+0.044715x3))) 0.5x\left(1 + \tanh\left(\sqrt{\frac{2}{\pi}}\left(x + 0.044715x^3\right)\right)\right) 0.5x(1+tanh(π2(x+0.044715x3)))
核心思想:激活更平滑,更自然,梯度更稳定。很多论文指出:GELU ≈ Swish,都属于:smooth activation -
SwiGLU
本质上属于带SiLU激活函数的FFN网络层,这一部分留在gate的部门做详细介绍。
2、 Norm
Norm也是一个老生常谈的话题,这个在刚刚入职的时候,七年前我就专门做过BN/IN/LN/GN的专题分享,不过彼时是站在cv的角度来进行norm的分享,彼时正是CNN一统江湖的年代。本次则是站在llm的监督进行总结,Transformer接过了核心网络组件的大旗。
不同于CV的batch的概念,LayerNorm / RMSNorm 通常是“单个 token 内部”的归一化。
transformer中:x.shape = [batch, seq, hidden]
CV 中 batch:x.shape = [B, C, H, W]
CNN 中 batch更多是工程上的组合, 可以视作是一堆彼此独立的样本;但是Transformer要处理的任务本质上是一个句子的时间展开,句子内部的词语之间高度相关联。
Transformer 本质:是把“时间/语义关系“映射成高维 token interaction。因此:seq 不是 batch,他是计算图的一部分。CNN normalize是希望获得图像统计特征,而Transformer normalize 是希望获得token 语义状态。这也是为什么llm引入了RMSnorm,LLM hidden是超高维 semantic vector,方向比均值更重要。所以干脆不计算均值,更加的节省算力。
当然由句子的长短不一致,还可以延伸出来Dynamic Batching,句子长短不一致的时候,Attention根据mask补齐padding的计算(padding位置 → -inf,softmax(-inf)=0),Continuous batching,这些都是flashattention等框架在工程上致力解决的问题。
3、 Gate
Transformer 里除了前置的attention计算部分,还有很大部分的 MLP,常见的网络结构组合为:Linear → Activation → Linear。这种常见的网络结构渐渐为Gated Linear Unit所取代,也就是目前LLM中越来越常见的GLU结构。
GLU(Gated Linear Unit)论文 Language Modeling with Gated Convolutional Networks 提出的激活函数 =使用Sigmoid(σ)。
公式:
GLU(x)=(xWa)⊙σ(xWb) \text{GLU}(x) = (x W_a) \odot \sigma(x W_b) GLU(x)=(xWa)⊙σ(xWb)
其中:
- σ\sigmaσ = Sigmoid
- 输出范围 0 ~ 1,做门控(开关)
目前在技术迭代之后,大模型(LLaMA、Qwen)全部用 SiLU / Swish 替代 sigmoid:
FFN=(xW1)⊙SiLU(xW2)W3 \text{FFN} = (x W_1) \odot \text{SiLU}(x W_2) W_3 FFN=(xW1)⊙SiLU(xW2)W3
叫:SwiGLU / SiLU-GLU
SwiGLU相比较于原始的GLU,可以看到线性层为三层,对于计算资源的消耗是增加了的。
原始FFN:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleFFN(nn.Module):
def __init__(self, hidden_size, intermediate_size):
super().__init__()
self.fc1 = nn.Linear(hidden_size, intermediate_size)
self.fc2 = nn.Linear(intermediate_size, hidden_size)
def forward(self, x):
# 激活
x = F.gelu(self.fc1(x))
# 投影回 hidden
x = self.fc2(x)
return x
SwiGLU
import torch
import torch.nn as nn
import torch.nn.functional as F
class SwiGLU(nn.Module):
def __init__(self, hidden_size, intermediate_size):
super().__init__()
# 主信息流
self.up_proj = nn.Linear(
hidden_size,
intermediate_size,
bias=False
)
# gate控制流
self.gate_proj = nn.Linear(
hidden_size,
intermediate_size,
bias=False
)
# 输出投影
self.down_proj = nn.Linear(
intermediate_size,
hidden_size,
bias=False
)
def forward(self, x):
# 1. 主路
up = self.up_proj(x)
# 2. gate路
gate = F.silu(self.gate_proj(x))
# 3. 门控
hidden = up * gate
# 4. 投影回hidden
out = self.down_proj(hidden)
return out
简明MOE
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.Module):
def __init__(self, hidden_size, intermediate_size):
super().__init__()
self.fc1 = nn.Linear(hidden_size, intermediate_size)
self.fc2 = nn.Linear(intermediate_size, hidden_size)
def forward(self, x):
return self.fc2(F.gelu(self.fc1(x)))
class MoE(nn.Module):
def __init__(
self,
hidden_size,
intermediate_size,
num_experts=4,
top_k=2,
bias=True
):
super().__init__()
self.hidden_size = hidden_size
self.num_experts = num_experts
self.top_k = top_k
# 专家
self.experts = nn.ModuleList([
Expert(hidden_size, intermediate_size)
for _ in range(num_experts)
])
# 路由
self.router = nn.Linear(hidden_size, num_experts, bias=bias)
# 负载均衡系数
self.balance_loss_coef = 0.01
def forward(self, x):
"""
x: [B, S, H]
return: output, moe_loss
"""
B, S, H = x.shape
x_flat = x.reshape(-1, H) # [B*S, H]
T = x_flat.shape[0]
# ======================
# 1. 路由打分
# ======================
router_logits = self.router(x_flat) # [T, E]
router_probs = F.softmax(router_logits, dim=-1) # [T, E]
# ======================
# 2. Top-K 选专家
# ======================
topk_weights, topk_indices = torch.topk(
router_probs, self.top_k, dim=-1
) # [T, K], [T, K]
# 权重归一化(关键修复!)
topk_weights = topk_weights / topk_weights.sum(dim=-1, keepdim=True)
# ======================
# 3. 分配 token → 专家
# ======================
output = torch.zeros_like(x_flat)
# 展平成 1D,方便批量计算
flat_indices = topk_indices.reshape(-1)
flat_weights = topk_weights.reshape(-1)
token_indices = torch.arange(T, device=x.device).repeat(self.top_k)
# 按专家分组
for e in range(self.num_experts):
mask = flat_indices == e
if not mask.any():
continue
# 取出分配给专家 e 的 token
tokens = x_flat[token_indices[mask]]
weights = flat_weights[mask].unsqueeze(-1)
# 前向
y = self.experts[e](tokens)
# 加权写回
output.index_add_(
0, token_indices[mask], y * weights
)
# ======================
# 4. 负载均衡 loss
# ======================
with torch.no_grad():
# 每个专家被选的次数
expert_counts = torch.bincount(
flat_indices, minlength=self.num_experts
).float()
# 负载均匀性
load = expert_counts / expert_counts.sum()
mean_load = load.mean()
balance_loss = torch.sum(torch.square(load - mean_load))
moe_loss = balance_loss * self.balance_loss_coef
# ======================
# 输出恢复形状
# ======================
output = output.reshape(B, S, H)
return output, moe_loss
MOE内部向量的流动过程:
- 输入向量
x: [B, S, H]
例:[2, 128, 512],2个句子 × 128个token × 512维特征
- 展平所有 token(向量合并)
x_flat = x.reshape(-1, H)
→ [B*S, H] → [256, 512],把句子结构拆掉 → 变成一整堆独立token,每个token自己选专家。
- 路由层:给每个 token 分配专家分数
router_logits = self.router(x_flat)
→ [T, E] → [256, 4]
- T = token 数量,E = 专家数量(4个)
- 流向:每个 512维 token → 线性变换 → 输出 4个分数(对应4个专家)
- Softmax 变成选择概率
router_probs = F.softmax(router_logits, dim=-1)
→ [256, 4]
流向:每个token得到4个专家的选择概率,总和=1。
- Top-K 选出最合适的 2 个专家
topk_weights, topk_indices = torch.topk(router_probs, top_k=2, dim=-1)
→ topk_indices: [T, K] → [256, 2] (每个token选哪2个专家)
→ topk_weights: [T, K] → [256, 2] (对应权重)
流向:每个token从4个专家里挑最匹配的2个。
- 权重归一化
topk_weights = topk_weights / topk_weights.sum(dim=-1, keepdim=True)
流向:让2个权重加起来=1,保证输出数值稳定。
- 把 Top-K 展平(批量分发)
flat_indices = topk_indices.reshape(-1) → [T*K] → [512]
flat_weights = topk_weights.reshape(-1) → [512]
token_indices = torch.arange(T).repeat(K) → [512]
流向:
把 [256,2] 展成 [512]
→ 每条记录 = (哪个token, 分配给哪个专家, 权重多少)
- 逐个专家收集 token 并计算(核心流向)
for e in range(num_experts):
mask = flat_indices == e
tokens = x_flat[token_indices[mask]] # 取出分配给该专家的token
weights = flat_weights[mask].unsqueeze(-1)
y = self.experts[e](tokens) # 专家FFN计算
output.index_add_(0, token_indices[mask], y * weights)
这部分内容涉及到:mask 筛选:哪些 token 分配给当前专家;token 抽取:只把这些 token 送进专家;专家前向:[N, 512] → [N, 512];加权:y * weights;写回原位置:用 index_add_ 自动累加到对应 token
- 输出恢复形状(回到句子结构)
output = output.reshape(B, S, H)
→ [2, 128, 512]
- 负载均衡 loss(训练用)
expert_counts = 每个专家被选次数
balance_loss = 专家分配均匀程度
moe_loss = balance_loss * 0.01
作用:防止所有token都抢一个专家,保证4个专家都被利用。
4、总结:
门控(Gating)是深度学习极易被低估的核心思想,本质是可学习的动态信息开关,通过 y=x⊙g(x)y=x\odot g(x)y=x⊙g(x) 实现信息流的筛选与控制;现代大模型的信息调控能力,并非仅来自注意力机制,而是遍布各类门控结构:Attention 属于Token级门控,实现token间的信息路由,决定信息从哪里来;SwiGLU等门控MLP属于特征级门控,筛选隐层特征,决定信息保留多少;MoE路由是专家级门控,分配计算路径,决定信息送往哪里计算,LSTM的记忆门控、KV缓存的留存机制同样基于门控逻辑。传统普通MLP对所有特征无差别处理,而门控通过动态稀疏化激活关键信息、抑制冗余噪声,大幅提升模型表达能力,也契合大模型海量信息的处理需求;从MLP到GLU、SwiGLU再到MoE的演进,本质是动态信息路由能力的持续增强,现代Transformer本质上就是一套大规模可微分的分层门控信息路由系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)